Paper Reading - CNN+CNN: Convolutional Decoders for Image Captioning
Link of the Paper: https://arxiv.org/abs/1805.09019
Innovations:
- The authors propose a CNN + CNN framework for image captioning. There are four modules in the framework: vision module ( VGG-16 ), which is adopted to "watch" images; language module, which is to model sentences; attention module, which connects the vision module with the language module; prediction module, which takes the visual features from the attention module and concepts from the language module as input and predicts the next word.
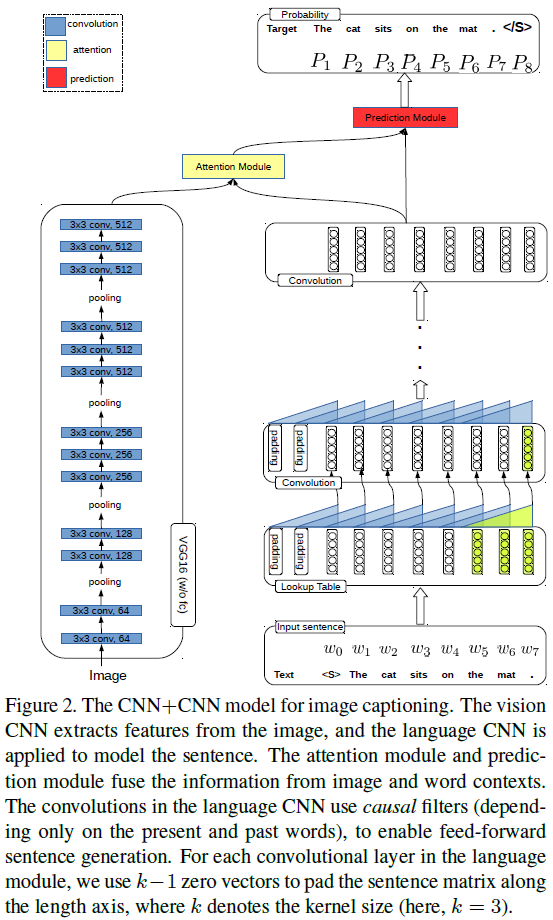
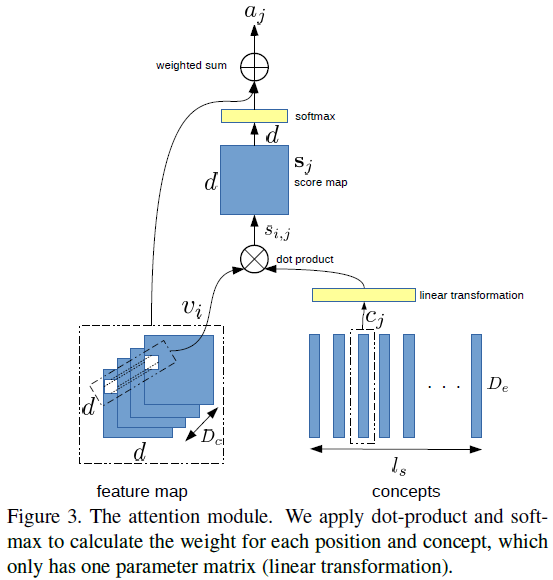
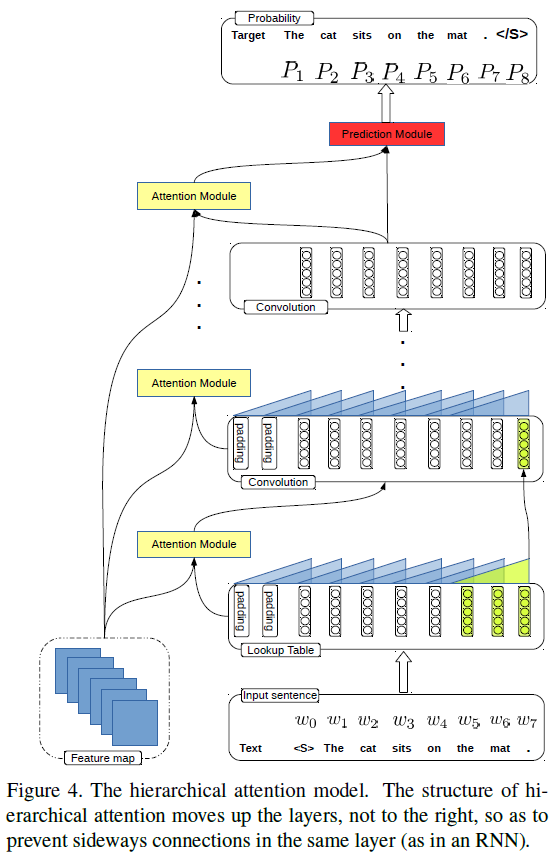
General Points:
- RNNs or LSTMs cannot be calculated in parallel and ignore the underlying hierarchical structure of a sentence.
- Directly feeding the output of the CNN into the RNN treats objects in an image the same and ignores the salient objects when generating one word.
- In both m-RNN and NIC, an image is represented by a single vector, which ignores different areas and objects in the image. A spatial attention mechanism is introduced into image captioning model in Show, attend and tell: Neural image caption generation with visual attention, which allows the model to pay attention to different areas at each time step.
Paper Reading - CNN+CNN: Convolutional Decoders for Image Captioning的更多相关文章
- Paper Reading - Long-term Recurrent Convolutional Networks for Visual Recognition and Description ( CVPR 2015 )
Link of the Paper: https://arxiv.org/abs/1411.4389 Main Points: A novel Recurrent Convolutional Arch ...
- 使用CNN(convolutional neural nets)关键的一点是检测到的面部教程(四):学习率,学习潜能,dropout
第七部分 让 学习率 和 学习潜能 随时间的变化 光训练就花了一个小时的时间.等结果并非一个令人心情愉快的事情.这一部分.我们将讨论将两个技巧结合让网络训练的更快! 直觉上的解决的方法是,開始训练时取 ...
- Paper Reading: Stereo DSO
开篇第一篇就写一个paper reading吧,用markdown+vim写东西切换中英文挺麻烦的,有些就偷懒都用英文写了. Stereo DSO: Large-Scale Direct Sparse ...
- SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning
题目:SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning 作者: Lo ...
- Paper Reading - Convolutional Image Captioning ( CVPR 2018 )
Link of the Paper: https://arxiv.org/abs/1711.09151 Motivation: LSTM units are complex and inherentl ...
- Deep Learning 学习随记(八)CNN(Convolutional neural network)理解
前面Andrew Ng的讲义基本看完了.Andrew讲的真是通俗易懂,只是不过瘾啊,讲的太少了.趁着看完那章convolution and pooling, 自己又去翻了翻CNN的相关东西. 当时看讲 ...
- Paper Reading - Convolutional Sequence to Sequence Learning ( CoRR 2017 ) ★
Link of the Paper: https://arxiv.org/abs/1705.03122 Motivation: Compared to recurrent layers, convol ...
- About CNN(convolutional neural network)
NO.1卷积神经网络基本概念 CNN是第一个被成功训练的多层深度神经网络结构,具有较强的容错.自学习及并行处理能力.最初是为识别二维图像而设计的多层感知器,局部连接和权值共享网络结构 类似于生物神经网 ...
- paper 158:CNN(卷积神经网络):Dropout Layer
Dropout作用 在hinton的论文Improving neural networks by preventing coadaptation提出的,主要作用就是为了防止模型过拟合.当模型参数较多, ...
随机推荐
- RockBrain USB Server- 云计算虚拟化USB设备集中管理、远程共享解决方案(涉及银企直联)
RockBrain USB Server- 云计算虚拟化USB设备集中管理.远程共享解决方案(涉及银企直联) 技术需求: 1.企业员工的大量USB Key,需要将key接入USB Server虚拟池, ...
- 获取DOM
<template> <div> <header-vue :msg="msg" ref="header">heheh< ...
- 前端优化:css雪碧图实践应用详解
一 为什么需要使用雪碧图 二CSS雪碧图原理及应用 前端是接近用户体验的一个项目组成部分,合适的优化能够大大减少网页响应时间,合理的资源加载自然成为了工作中的要务,现在就结合实例讲解到底什么是css雪 ...
- web开发问题汇总
Meta基础知识: H5页面窗口自动调整到设备宽度,并禁止用户缩放页面 //一.HTML页面结构 <meta name="viewport" content="wi ...
- Spark在实际项目中分配更多资源
Spark在实际项目中分配更多资源 Spark在实际项目中分配更多资源 性能调优概述 分配更多资源 性能调优问题 解决思路 为什么调节了资源以后,性能可以提升? 性能调优概述 分配更多资源 性能调优的 ...
- 应用性能管理(APM, Application Performance Management)
当下成熟的互联网公司都建立有从基础设施到应用程序的全方位监控系统,力求及时发现故障进行处理并为优化程序提供性能数据支持,降低整体运维成本.国内外商业的APM有Compuware.iMaster.博睿B ...
- 第七篇:gcc和arm-linux-gcc常用选项
目录 一.gcc和arm-linux-gcc的常用选项 二.从.c文件到可执行文件过程 一.gcc和arm-linux-gcc的常用选项 常用选型 -v 查看gcc编译器的版本,显示gcc执行时的详细 ...
- [BZOJ4552][Tjoi2016&Heoi2016]排序(二分答案+线段树)
二分答案mid,将>=mid的设为1,<mid的设为0,这样排序就变成了区间修改的操作,维护一下区间和即可 然后询问第q个位置的值,为1说明>=mid,以上 时间复杂度O(nlog2 ...
- 【blockly教程】第五章 循环结构
在这里,我们将介绍一个新游戏--Pond Tutor 在Pond Tutor(https://blockly-games.appspot.com/pond-tutor)这个游戏中,我们将扮演黄色的鸭子 ...
- MySql——查看数据库性能基本参数
使用show status可以查看数据库性能的参数,基本语法:show status like 'value'; 例如: show status like 'Connections';/*连接mysq ...