HDFS 详解
HDFS 概述
基于2.7.3
HDFS 优点:
1、高容错性
数据自动保存多个副本,默认是三个副本
副本丢失后,会自动恢复
2、适合批处理
移动计算而非移动数据,批处理的时候,数据量很大,移动数据是不合适的,好的方式是分布式的移动计算
数据位置暴露给计算框架,数据被切分为 block list,block list 存放在哪些node list 上,在 namenode 上,是有这两个维度的记录的
3、适合大数据处理
GB、TB、甚至 PB 级数据,当然小数据也是可以的,有相应方法
百万规模以上的文件数量
10K + 节点规模
4、流式文件访问
一次性写入,多次读取
保证数据一致性
5、可构建在廉价机器上
通过多副本提高可靠性
提供了容错和恢复机制
二、HDFS 缺点
1、不适合低延迟的数据访问
比如毫秒级,这个 HDFS 是做不到的
HDFS 不适合低延迟的处理场景,适合需要高吞吐率的场景
2、不适合小文件存取
每个文件存入 HDFS 都会被切分为一些 blocks ,namenode 中保存了二个维度的映射,1亿个1k 的小文件,文件大小一共 1G,可能占用10G 的内存,这是不合适的(数据仅为假设)
寻道时间超过读取时间,我们知道,在计算机里面寻找文件,是先要寻道(找到文件存在的扇区),再去读取文件,这两步,时间花费主要在寻道,而不是文件读取
3、不适合并发写入、文件随机修改
HDFS 中,一个文件只能有一个写者
仅支持 append,不支持或者不建议文件修改,这里解释下,HDFS 对于文件的修改方式,先读取数据,修改数据,最后再重新写入一个文件
HDFS 基本架构与原理
HDFS 设计思想
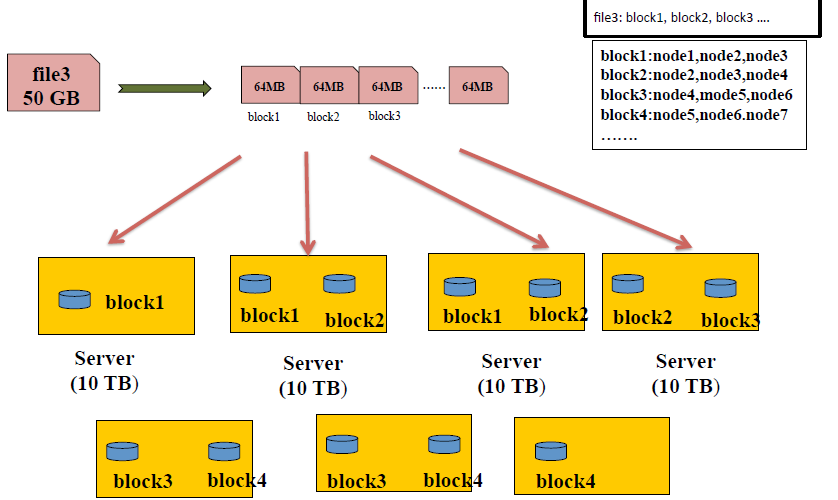
文件写入 HDFS 的时候,file 会被 client 按128M(可自定义,hadoop1 的时候默认是64M)的大小,被分为很多 blocks ,每个block 会被分配存储到一些 node 上,同时每个 block 会有三个副本按照一定规则被存储在一些 nodes 上
一个129M 的文件,会被存储为一个 128M的文件和一个1M的文件
Q&A:一个1TB的文件,被切分为n 个 blocks ,公司是刚开始使用hadoop 集群,集群中只有三台服务器,这些blocks 放在遍布这三台服务器,会不会出现什么问题?三台服务器会不会太少了?
HDFS 架构

DN 会向 NN 每隔几秒钟发一次心跳,来告诉 NN 自己的状态,当一个 DN 挂掉,NN 没有收到该 DN 的心跳,该 DN 上的数据会被再次备份到其他 node 上,但这会有一个问题,不同的机器,负载情况,记录的数据量不均衡,此时,可以通过 balance 组件,来进行负载均衡,当集群扩容的时候,同样可以调用 banance 组件来处理
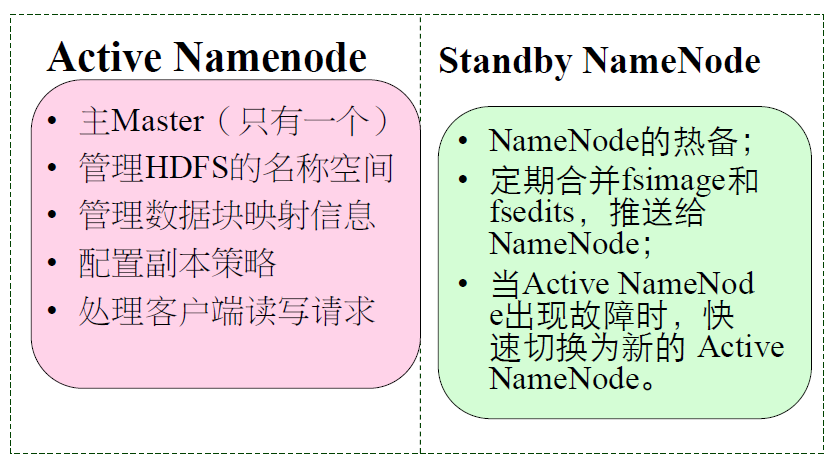
先介绍下左侧的 NN,它在内存中记录了两个维度(文件结构就是一棵树)的信息
file —> block list,这一维度会保存在内存,并被序列化到磁盘,这个树(元信息或者这一维度的记录或者文件镜像)被称之为 fsimage(file system image)
block —> node list,这一维度不会被存到磁盘仅保存在内存,其关系的维持,主要靠 DN 周期性的向 NN 汇报自身的 block list ,当调用 balance 的时候,dn 上面的 node list 会发生变化,dn 同样会告知 nn 自身现在的情况
NN 可以配置副本策略,每个 block 及其副本存放在哪些 node 上,可以处理客户端的读写请求,但是具体执行处理请求是 dn 来做
再说右边 Standby NN,这是 hadoop2 之后提出的一个概念 HA,为了解决 NN 的单点故障,之前一直都是 Second NN
Standby NN 会去监控NN 的健康状态,当发现 NN 挂掉以后,Standby NN 会自动切换为 NN
fsimage 因为是被序列化到磁盘,所以当 NN 挂掉或者重启,这部分数据不会丢失,但机器上的 block 信息,如果正好碰到有写入发生,该 node 挂掉,那么数据是不是会丢失呢?答案是不会,原理是:
client 每次有写入或者增加一个文件等请求,这时候是会把这些这些操作都会记录到一个 log,也就是fsedit,而不是立马更新到 NN 的 fsimage,重启时,会先加载 fsimage,再去读取 editlog ,这样,NN 中的文件数就是最新的,详细介绍:
这个树(fsimage)是写到磁盘了,但是现在有一个对这个树的修改,比如说创建了一个文件,这个时候怎么办,这时候可以引入log,如果重启的时候,我先载入 fsimage ,然后我的log记录了我对文件树的整个修改,我对 fsimage 依次的执行 log,就可以把文件树恢复到最新,但是我如果每次都把修改或者改动记录到log,也不行,因为当log越来越大,重启的时候,会越来越慢,这时候就出现了Second NN,他定期的合并fsimage和editlog,然后将最新的 fsimage 发送给 NN,告诉 NN 可以把旧的 fsimage 删掉,用我这个新的替换
Second NN,一个较老的名字,Second 没有热备的功能,后来发展发展成为 HA 的 Standby,Standby 承载了一部分 Second 的功能(合并 fsimage 和 editlog),并成为热备
HA 与 Federation (这个大公司一般才可能遇到,再说吧)

HDFS内部机制—写流程
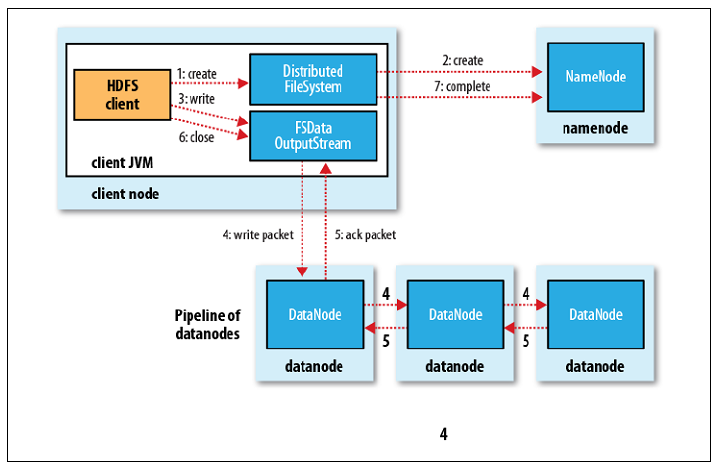
HDFS client 创建一个file,会向 NN 申请空间资源,比如写入哪些机器,这些 128M 的块会再次切分成 512字节的package(包含了CRC32的校验,在三个 node 之间验证,来确保数据完整性),因为客户端一次性缓存128M 是比较可怕的事情,会占用大量内存,按照这样的方式依次、流式、串行的写数据
这里为什么不选择同时向三个 DN 写入呢,因为这样会占用更多的带宽,不如串行、流式的写好
写的时候,NN 会生成由三个 DN 构成的一个list,并告诉第一个 DN 要写入的数据以及后面两个 DN 的信息,三个 DN 依次写的时候,有一个 DN 挂掉,则会跳过他,将它从 list 中移除,然后继续入写其余两个 DN
当三个 DN 都遍历写完,DN 才会告知 NN,而不是写完一个 DN 该 DN 就告知 NN
如果一次写入,有两个 DN 都正好挂掉,那么 HDFS 会认为这次写入是失败的,因为这个时候也可能出现唯一写入成功的 DN 挂掉,这违背了 HDFS 高可用高容错性,NN 会重新分配,重新写,这是默认是实现
HDFS内部机制—读流程

HDFS client 读取文件的时候,会向 NN 去获取一个 block locations ,然后打开输入流,按照就近原则,在相应 DN 上读取数据
就近原则是,本地 > 同机架 >同交换机 > 同机房
同一个机架任意两个节点之间共享 1Gbps 带宽,机架之间带宽为 2-10 Gbps,每个机架通常有16-64 个节点
HDFS内部机制—副本放置策略

HDFS 访问方式
主要分为 Shell 命令和 API 这两种方式
HDFS 详解的更多相关文章
- HDFS详解
HDFS详解大纲 Hadoop HDFS 分布式文件系统DFS简介 HDFS的系统组成介绍 HDFS的组成部分详解 副本存放策略及路由规则 命令行接口 Java接口 客户端与HDFS的数据流讲解 目标 ...
- Python API 操作Hadoop hdfs详解
1:安装 由于是windows环境(linux其实也一样),只要有pip或者setup_install安装起来都是很方便的 >pip install hdfs 2:Client——创建集群连接 ...
- Hadoop之HDFS详解
1.HDFS的概念和特性 它是一个文件系统,其次是分布式的 重要特性: 1).HDFS中的文件在物理上是分块存储(block),新版默认128M 2).客户端通过路径来访问文件,形如:hdfs://n ...
- Hadoop分布式文件系统HDFS详解
Hadoop分布式文件系统即Hadoop Distributed FileSystem. 当数据集的大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分区(Partition)并 ...
- Java+大数据开发——HDFS详解
1. HDFS 介绍 • 什么是HDFS 首先,它是一个文件系统,用于存储文件,通过统一的命名空间--目录树来定位文件. 其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角 ...
- Logstash读取Kafka数据写入HDFS详解
强大的功能,丰富的插件,让logstash在数据处理的行列中出类拔萃 通常日志数据除了要入ES提供实时展示和简单统计外,还需要写入大数据集群来提供更为深入的逻辑处理,前边几篇ELK的文章介绍过利用lo ...
- 大数据入门第六天——HDFS详解
一.概述 1.HDFS中的角色 Block数据: HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是 ...
- Hive(3)-meta store和hdfs详解,以及JDBC连接Hive
一. Meta Store 使用mysql客户端登录hadoop100的mysql,可以看到库中多了一个metastore 现在尤其要关注这三个表 DBS表,存储的是Hive的数据库 TBLS表,存储 ...
- Hadoop- Hadoop详解
首先所有知识以官网为准,所有的内容在官网上都有展示,所有的变动与改进,新增内容都以官网为准.hadoop.apache.org Hadoop是一个开源的可拓展的分布式并行处理计算平台,利用服务器集群根 ...
随机推荐
- 使用BestSync同步软件与坚果云同步
坚果云的免费用户可以享受每个月的1G上传与3G下载流量,同时号称是国内唯一支持WebDAV的云.我的工作备份的文档不多,正好手头有BestSync同步软件可以用.决定试试BestSync的与WebDA ...
- poj 1419(图的着色问题,搜索)
题目链接:http://poj.org/problem?id=1419 思路:只怪数据太弱!直接爆搜,按顺序搜索即可. #include<iostream> #include<cst ...
- java三大框架SSH(Struts2 Spring Hibernate)
http://www.cnblogs.com/qiuzhongyang/p/3874149.html
- MAMP下配置虚拟主机域名
第一步:修改虚拟主机地址: /Applications/MAMP/conf/apache/extra/httpd-vhosts.conf 第二步:
- 在ubuntu机器上部署php测试环境
在ubuntu机器上部署php测试环境 一.部署环境 Ubuntu11.10_X86_32,编译安装相应的软件:nginx+mysql+php. 二.软件安装 2.1 软件下载 libiconv-1. ...
- tfs+git
TFS+GIT 一:背景介绍 技术团队的代码管理工具原来使用的是纯TFS方案,使用两年后发现一些问题:体积太大,每次新建一个分支需要本地下载一份代码:操作不便,功能分支的建立.合并不方便,本地有很多同 ...
- Leetcode-Convert Sorted List to BST.
Given a singly linked list where elements are sorted in ascending order, convert it to a height bala ...
- 几种常见数据库查询判断表和字段是否存在sql
1.MSSQL Server 表:select COUNT(*) from dbo.sysobjectsWHEREname= 'table_name': 字段:select COUNT(*) ...
- :nohlsearch
vim 编辑器 ——黄色阴影的消除问题 - leikun153的博客 - CSDN博客 https://blog.csdn.net/leikun153/article/details/78903597 ...
- 微信公众号 待发货-物流中-已收货 foreach break continue
w <?php $warr = array(1,2,3); $w_break = 0; foreach($warr AS $w){ if($w==2)break; $w_break += $w; ...