Python面试题之Super函数
这是个高大上的函数,在python装13手册里面介绍过多使用可显得自己是高手 23333. 但其实他还是很重要的. 简单说, super函数是调用下一个父类(超类)并返回该父类实例的方法. 这里的下一个的概念参考后面的MRO表介绍.
help介绍如下:
super(type, obj) -> bound super object; requires isinstance(obj, type)
super(type) -> unbound super object
super(type, type2) -> bound super object; requires issubclass(type2, type)
Typical use to call a cooperative superclass method:
class C(B):
def meth(self, arg):
super(C, self).meth(arg)
由此可知, super有三种用法, 第一参数总是召唤父类的那个类, 第二参数可缺(返回非绑定父类对象),也可以是实例对象或该类的子类. 最终返回的都是父类的实例(绑定或非绑定). 在Python3中,super函数多了一种用法是直接super(),相当于super(type,首参), 这个首参就是一般的传入的self实例本身啦. 因为在py2里面常用也是这种写法.
另外, 在py2中, super只支持新类( new-style class, 就是继承自object的).
为什么要调用父类?
在类继承时, 要是重定义某个方法, 这个方法就会覆盖掉父类的相应同名方法. 通过调用父类实例, 可以在子类中同时实现父类的功能.例如:
# Should be new-class based on object in python2.
class A(object):
def __init__(self):
print "enter A"
print "leave A" class B(A):
def __init__(self):
print "enter B"
super(B, self).__init__()
print "leave B" >>> b = B()
enter B
enter A
leave A
leave B
通过调用super获得父类实例从而可以实现该实例的初始化函数. 这在实践中太常用了 (因为要继承父类的功能, 又要有新的功能).
直接使用父类来调用的差异
事实上, 上面的super函数方法还可以这么写:
class A(object):
def __init__(self):
print "enter A"
print "leave A" class B(A):
def __init__(self):
print "enter B"
A.__init__(self)
print "leave B"
通过直接使用父类类名来调用父类的方法, 实际也是可行的. 起码在上面的例子中效果上他们现在是一样的. 这种方法在老式类中也是唯一的调用父类的方法 (老式类没有super).
通过父类类名调用方法很常用, 比较直观. 但其效果和super还是有差异的. 例如:
class A(object):
def __init__(self):
print "enter A"
print "leave A" class B(A):
def __init__(self):
print "enter B"
A.__init__(self)
print "leave B" class C(A):
def __init__(self):
print "enter C"
A.__init__(self)
print "leave C" class D(B,C):
def __init__(self):
print "enter D"
B.__init__(self)
C.__init__(self)
print "leave D"
>>> d=D()
enter D
enter B
enter A
leave A
leave B
enter C
enter A
leave A
leave C
leave D
可以发现, 这里面A的初始化函数被执行了两次. 因为我们同时要实现B和C的初始化函数, 所以分开调用两次, 这是必然的结果.
但如果改写成super呢?
class A(object):
def __init__(self):
print "enter A"
print "leave A" class B(A):
def __init__(self):
print "enter B"
super(B,self).__init__()
print "leave B" class C(A):
def __init__(self):
print "enter C"
super(C,self).__init__()
print "leave C" class D(B,C):
def __init__(self):
print "enter D"
super(D,self).__init__()
print "leave D"
>>> d=D()
enter D
enter B
enter C
enter A
leave A
leave C
leave B
leave D
会发现所有父类ABC只执行了一次, 并不像之前那样执行了两次A的初始化.
然后, 又发现一个很奇怪的: 父类的执行是 BCA 的顺序并且是全进入后再统一出去. 这是MRO表问题, 后面继续讨论.
如果没有多继承, super其实和通过父类来调用方法差不多. 但, super还有个好处: 当B继承自A, 写成了A.__init__, 如果根据需要进行重构全部要改成继承自 E,那么全部都得改一次! 这样很麻烦而且容易出错! 而使用super()就不用一个一个改了(只需类定义中改一改就好了)
Anyway, 可以发现, super并不是那么简单.
MRO 表
MRO是什么? 可以通过以下方式调出来:
>>> D.mro() # or d.__class__.mro() or D.__class__.mro(D)
[D, B, C, A, object] >>> B.mro()
[B, A, object] >>> help(D.mro)
#Docstring:
#mro() -> list
#return a type's method resolution order
#Type: method_descriptor
MRO就是类的方法解析顺序表, 其实也就是继承父类方法时的顺序表 (类继承顺序表去理解也行) 啦.
这个表有啥用? 首先了解实际super做了啥:
def super(cls, inst):
mro = inst.__class__.mro()
return mro[mro.index(cls) + 1]
换而言之, super方法实际是调用了cls的在MRO表中的下一个类. 如果是简单一条线的单继承, 那就是父类->父类一个一个地下去罗. 但对于多继承, 就要遵循MRO表中的顺序了. 以上面的D的调用为例:
d的初始化
-> D (进入D) super(D,self)
-> 父类B (进入B) super(B,self)
-> 父类C (进入C) super(C,self)
-> 父父类A (进入A) (退出A) # 如有继续super(A,self) -> object (停了)
-> (退出C)
-> (退出B)
-> (退出D)
所以, 在MRO表中的超类初始化函数只执行了一次!
那么, MRO的顺序究竟是怎么定的呢? 这个可以参考官方说明The Python 2.3 Method Resolution Order. 基本就是, 计算出每个类(从父类到子类的顺序)的MRO, 再merge 成一条线. 遵循以下规则:
在 MRO 中,基类永远出现在派生类后面,如果有多个基类,基类的相对顺序保持不变。 这个原则包括两点:
- 基类永远在派生类后面
- 类定义时的继承顺序影响相对顺序.
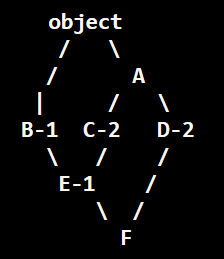
那么MRO是: F -> E -> B -> C -> D -> A -> object
怎么解释呢?
根据官方的方法, 是:
L(O) = O
L(B) = B O
L(A) = A O
L(C) = C A O
L(D) = D A O
L(E) = E + merge(L(B),L(C))
= E + merge(BO,CAO)
= E + B + merge(O,CAO)
= E + B + C + merge(O,AO)
= E + B + C + A + merge(O,O)
= E B C A O
L(F) = F + merge(L(E),L(D))
= F + merge(EBCAO,DAO)
= F + EBC + merge(AO,DAO)
= F + EBC + D + merge(AO,AO)
= F EBC D AO
看起来很复杂..但还是遵循在 MRO 中,基类永远出现在派生类后面,如果有多个基类,基类的相对顺序保持不变。所以, 我个人认为可以这么想:
- 先找出最长深度最深的继承路线
F->E->C->A->object. (因为必然基类永远出现在派生类后面) - 类似深度优先, 定出其余顺序:
F->E->B->obj,F->D->A-object - 如果有多个基类,基类的相对顺序保持不变, 类似于merge时优先提前面的项. 所以排好这些路线: (FEBO, FECAO, FDAO)
F->E->B->obj且E(B,C)决定B在C前面.所以F->E->B->C->A->obj(相当于F+merge(EBO,ECAO)).F->D->A-object且F(E,D)决定了D在E后, 所以D在E后A前. 因为相对顺序, 相当于FE+merge(BCAO, DAO), 所以FE BC D AO
super 是个类
当我们调用 super() 的时候,实际上是实例化了一个 super 类。你没看错, super 是个类,既不是关键字也不是函数等其他数据结构:
>>> class A: pass
...
>>> s = super(A)
>>> type(s)
<class 'super'>
>>>
在大多数情况下, super 包含了两个非常重要的信息: 一个 MRO 以及 MRO 中的一个类。当以如下方式调用 super 时:
super(a_type, obj)
MRO 指的是 type(obj) 的 MRO, MRO 中的那个类就是 a_type , 同时 isinstance(obj, a_type) == True 。
当这样调用时:
super(type1, type2)
MRO 指的是 type2 的 MRO, MRO 中的那个类就是 type1 ,同时 issubclass(type2, type1) == True 。
那么, super() 实际上做了啥呢?简单来说就是:提供一个 MRO 以及一个 MRO 中的类 C , super() 将返回一个从 MRO 中 C 之后的类中查找方法的对象。
也就是说,查找方式时不是像常规方法一样从所有的 MRO 类中查找,而是从 MRO 的 tail 中查找。
举个栗子, 有个 MRO:
[A, B, C, D, E, object]
下面的调用:
super(C, A).foo()
super 只会从 C 之后查找,即: 只会在 D 或 E 或 object 中查找 foo 方法。
多继承中 super 的工作方式
再回到前面的
d = D()
d.add(2)
print(d.n)
现在你可能已经有点眉目,为什么输出会是
self is <__main__.D object at 0x10ce10e48> @D.add
self is <__main__.D object at 0x10ce10e48> @B.add
self is <__main__.D object at 0x10ce10e48> @C.add
self is <__main__.D object at 0x10ce10e48> @A.add
19
下面我们来具体分析一下:
- D 的 MRO 是: [D, B, C, A, object] 。 备注: 可以通过 D.mro() (Python 2 使用 D.__mro__ ) 来查看 D 的 MRO 信息)
- 详细的代码分析如下:
class A:
def __init__(self):
self.n = 2 def add(self, m):
# 第四步
# 来自 D.add 中的 super
# self == d, self.n == d.n == 5
print('self is {0} @A.add'.format(self))
self.n += m
# d.n == 7 class B(A):
def __init__(self):
self.n = 3 def add(self, m):
# 第二步
# 来自 D.add 中的 super
# self == d, self.n == d.n == 5
print('self is {0} @B.add'.format(self))
# 等价于 suepr(B, self).add(m)
# self 的 MRO 是 [D, B, C, A, object]
# 从 B 之后的 [C, A, object] 中查找 add 方法
super().add(m) # 第六步
# d.n = 11
self.n += 3
# d.n = 14 class C(A):
def __init__(self):
self.n = 4 def add(self, m):
# 第三步
# 来自 B.add 中的 super
# self == d, self.n == d.n == 5
print('self is {0} @C.add'.format(self))
# 等价于 suepr(C, self).add(m)
# self 的 MRO 是 [D, B, C, A, object]
# 从 C 之后的 [A, object] 中查找 add 方法
super().add(m) # 第五步
# d.n = 7
self.n += 4
# d.n = 11 class D(B, C):
def __init__(self):
self.n = 5 def add(self, m):
# 第一步
print('self is {0} @D.add'.format(self))
# 等价于 super(D, self).add(m)
# self 的 MRO 是 [D, B, C, A, object]
# 从 D 之后的 [B, C, A, object] 中查找 add 方法
super().add(m) # 第七步
# d.n = 14
self.n += 5
# self.n = 19 d = D()
d.add(2)
print(d.n)
调用过程图如下:
D.mro() == [D, B, C, A, object]
d = D()
d.n == 5
d.add(2) class D(B, C): class B(A): class C(A): class A:
def add(self, m): def add(self, m): def add(self, m): def add(self, m):
super().add(m) 1.---> super().add(m) 2.---> super().add(m) 3.---> self.n += m
self.n += 5 <------6. self.n += 3 <----5. self.n += 4 <----4. <--|
(14+5=19) (11+3=14) (7+4=11) (5+2=7)

现在你知道为什么 d.add(2) 后 d.n 的值是 19 了吧 ;)
参考
Python面试题之Super函数的更多相关文章
- python之类中的super函数
作用 实现代码重用 思考:super真的只是调用父类么? super函数是按照mro算法去调用的,不bb上代码: class A: def __init__(self): print('A') cla ...
- Python面试题之回调函数
0x00 概述 编程分为两类:系统编程(system programming)和应用编程(application programming).所谓系统编程,简单来说,就是编写库:而应用编程就是利用写好的 ...
- python面试题&练习题之函数
1.写函数,接收两个数字参数,返回最大值例如:传入:10,20返回:20 def res_max(number1,number2): l1 = [] l1.append(number1) l1.app ...
- python学习之路---day20--面向对象--多继承和super() 函数
一:python多继承 python多继承中,当一个类继承了多个父类时候,这个类拥有多个父类的所欲非私有的属性 l例子: class A: pass class B(A): pass class C( ...
- Python中super函数的用法
之前看python文档的时候发现许多单继承类也用了super()来申明父类,那么这样做有何意义? 从python官网文档对于super的介绍来看,其作用为返回一个代理对象作为代表调用父类或亲类方法.( ...
- python之super()函数
python之super()函数 python的构造器奇特, 使用魔方. 构造器内对基类对象的初始化同样也很奇特, 奇特到没有半点优雅! 在构造器中使用super(class, instance)返回 ...
- 由Python的super()函数想到的
python-super *:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: 0 !im ...
- Python super() 函数的概念和例子
概念: super() 函数是用于调用父类(超类)的一个方法. super 是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO).重 ...
- Python super() 函数
super() 函数是用于调用父类(超类)的一个方法. super 是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果重定义某个方法,该方法会覆盖父类的同名方法,但有时 ...
随机推荐
- wireshark in text mode: tshark
tshark -i <interface> -w "output.data" 抓到的数据可用wireshark打开查看.
- html5 webwork
在Web开发的时候经常会遇到浏览器不响应事件进入假死状态,甚至弹出“脚本运行时间过长“的提示框,如果出现这种情况说明你的脚本已经失控了. 一个浏览器至少存在三个线程:js引擎线程(处理js).GUI渲 ...
- Java反射基础(二)
获取域 1. 通过反射API可以获取到类中公开的静态域和对象中的实例域.得到表示域的java.lang.reflect.Field类的对象之后,就可以获取和设置域的值. 与获取构造方法类似,Cla ...
- VC++ Debug显示指针所指的array内容
If you expand a pointer and you only get a single item, just add ",n" to the entry in the ...
- Android开发:《Gradle Recipes for Android》阅读笔记(翻译)5.1——单元测试
问题: 你想要测试app中的非android部分. 解决方案: 可以使用Android Studio1.1里面增加的单元测支持和Android的Gradle插件. 讨论: ADT插件只支持集成测试,并 ...
- 第一次使用Xamarin就上手 - 安裝Xamarin
http://xamarintech.blogspot.tw/2013/06/xamarin-xamarin-step-by-step-part1.html http://xamarintech.bl ...
- jQuery 对象访问 index([selector|element])
搜索匹配的元素,并返回相应元素的索引值,从0开始计数. 如果不给 .index() 方法传递参数,那么返回值就是这个jQuery对象集合中第一个元素相对于其同辈元素的位置. 如果参数是一组DOM元素或 ...
- 联想打字必须按FN+数字-fn打字
对于联想G40.14英寸系列的本本,好多时候无意间可能把数字键锁定了. 这时候要做的是:打开运行--输入OSK--打开虚拟屏幕键盘.这时候可以找到 选项---打开数字键盘. 有时候某些电脑上没有NUM ...
- android studio 运行是,app标题栏不显示
解决办法:让所有的活动都继承 AppCompatActivity就行了,如: public class FirstActivity extends AppCompatActivity{ ... }
- mysql中修改字段的类型
修改表字段的类型: ALTER TABLE 表名 MODIFY COLUMN 字段名 字段类型定义 如:将movie_mark修改为浮点型 alter table new_playing_video ...