MYSQL开发性能研究——批量插入的优化措施
一、我们遇到了什么问题
在标准SQL里面,我们通常会写下如下的SQL insert语句。
INSERT INTO TBL_TEST (id) VALUES(1);
很显然,在MYSQL中,这样的方式也是可行的。但是当我们需要批量插入数据的时候,这样的语句却会出现性能问题。例如说,如果有需要插入100000条数据,那么就需要有100000条insert语句,每一句都需要提交到关系引擎那里去解析,优化,然后才能够到达存储引擎做真的插入工作。
正是由于性能的瓶颈问题,MYSQL官方文档也就提到了使用批量化插入的方式,也就是在一句INSERT语句里面插入多个值。即,
INSERT INTO TBL_TEST (id) VALUES (1), (2), (3)
这样的做法确实也可以起到加速批量插入的功效,原因也不难理解,由于提交到服务器的INSERT语句少了,网络负载少了,最主要的是解析和优化的时间看似增多,但是实际上作用的数据行却实打实地多了。所以整体性能得以提高。根据网上的一些说法,这种方法可以提高几十倍。
然而,我在网上也看到过另外的几种方法,比如说预处理SQL,比如说批量提交。那么这些方法的性能到底如何?本文就会对这些方法做一个比较。
二、比较环境和方法
我的环境比较苦逼,基本上就是一个落后的虚拟机。只有2核,内存为6G。操作系统是SUSI Linux,MYSQL版本是5.6.15。
可以想见,这个机子的性能导致了我的TPS一定非常低,所以下面的所有数据都是没有意义的,但是趋势却不同,它可以看出整个插入的性能走向。
由于业务特点,我们所使用的表非常大,共有195个字段,且写满(每个字段全部填满,包括varchar)大致会有略小于4KB的大小,而通常来说,一条记录的大小也有3KB。
由于根据我们的实际经验,我们很肯定的是,通过在一个事务中提交大量INSERT语句可以大幅度提高性能。所以下面的所有测试都是建立在每插入5000条记录提交一次的做法之上。
最后需要说明的是,下面所有的测试都是通过使用MYSQL C API进行的,并且使用的是INNODB存储引擎。
三、比较方法
理想型测试(一)——方法比较
目的:找出理想情况下最合适的插入机制
关键方法:
1. 每个进/线程按主键顺序插入
2. 比较不同的插入方法
3. 比较不同进/线程数量对插入的影响
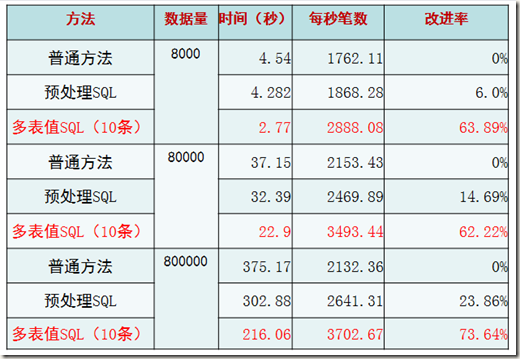
*“普通方法”指的是一句INSERT只插入一个VALUE的情况。
*“预处理SQL”指的是使用预处理MYSQL C API的情况。
* “多表值SQL(10条)”是使用一句INSERT语句插入10条记录的情况。为什么是10条?后面的验证告诉了我们这样做性能最高。
结论,很显然,从三种方法的趋势上来看,多表值SQL(10条)的方式最为高效。
理想型测试(二)——多表值SQL条数比较
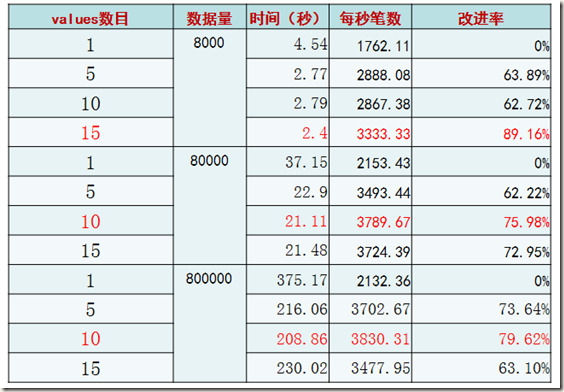
很显然,在数据量提高的情况下,每条INSERT语句插入10条记录的做法最为高效。
理想型测试(三)——连接数比较
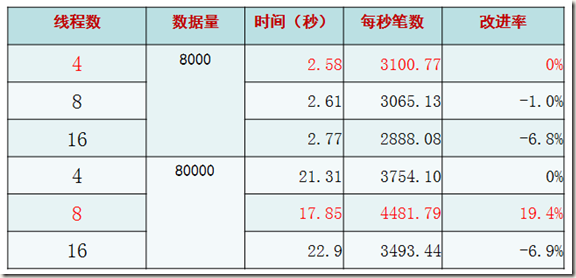
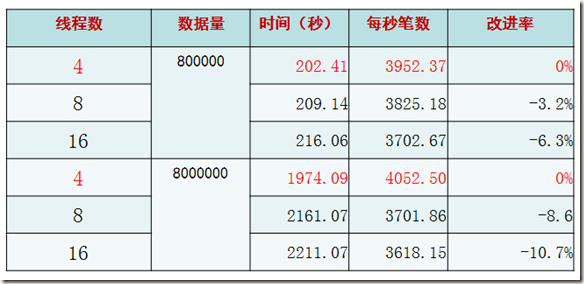
结论:在2倍与CPU核数的连接和操作的时候,性能最高
一般性测试—— 根据我们的业务量进行测试
目的:最佳插入机制适合普通交易情况?
关键方法:
1. 模拟生产数据(每条记录约3KB)
2. 每个线程主键乱序插入
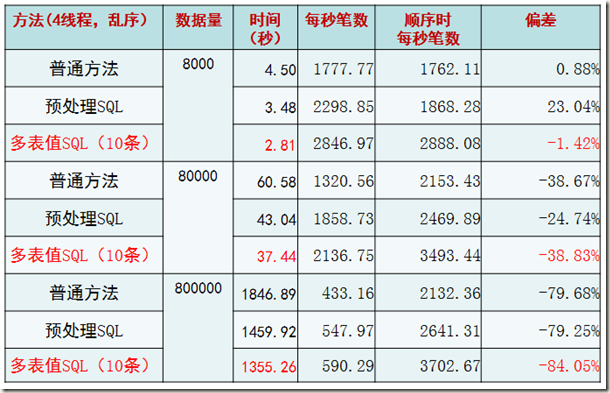
很显然,如果是根据主键乱序插入的话,性能会有直线下降的情况。这一点其实和INNODB的内部实现原理所展现出来的现象一致。但是仍然可以肯定的是,多表值SQL(10条)的情况是最佳的。
压力测试
目的:最佳插入机制适合极端交易情况?
关键方法:
1. 将数据行的每一个字段填满(每条记录约为4KB)
2. 每个线程主键乱序插入
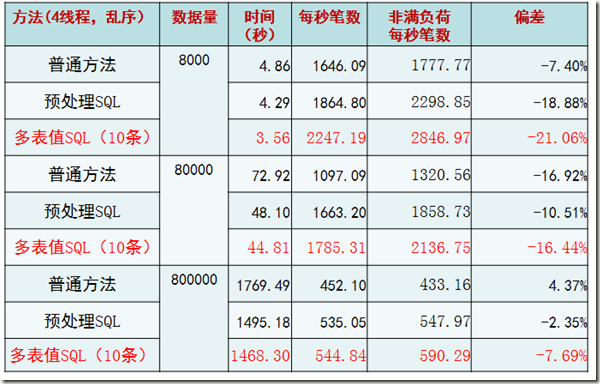
结果和我们之前的规律类似,性能出现了极端下降。并且这里验证了随着记录的增大(可能已经超过了一个page的大小,毕竟还有slot和page head信息占据空间),会有page split等现象,性能会下降。
四、结论
根据上面的测试,以及我们对INNODB的了解,我们可以得到如下的结论。
•采用顺序主键策略(例如自增主键,或者修改业务逻辑,让插入的记录尽可能顺序主键)
•采用多值表(10条)插入方式最为合适
•将进程/线程数控制在2倍CPU数目相对合适
五、附录
我发现网上很少有完整的针对MYSQL 预处理SQL语句的例子。这里给出一个简单的例子。
--建表语句
CREATE TABLE tbl_test
(
pri_key varchar(30),
nor_char char(30),
max_num DECIMAL(8,0),
long_num DECIMAL(12, 0),
rec_upd_ts TIMESTAMP
);
/*====================================================*/
#include <string.h>
#include <iostream>
#include <mysql.h>
#include <sys/time.h>
#include <sstream>
#include <vector> using namespace std; #define STRING_LEN 30 char pri_key [STRING_LEN]= "123456";
char nor_char [STRING_LEN]= "abcabc";
char rec_upd_ts [STRING_LEN]= "NOW()"; bool SubTimeval(timeval &result, timeval &begin, timeval &end)
{
if ( begin.tv_sec>end.tv_sec ) return false; if ( (begin.tv_sec == end.tv_sec) && (begin.tv_usec > end.tv_usec) )
return false; result.tv_sec = ( end.tv_sec - begin.tv_sec );
result.tv_usec = ( end.tv_usec - begin.tv_usec ); if (result.tv_usec<0) {
result.tv_sec--;
result.tv_usec+=1000000;}
return true;
} int main(int argc, char ** argv)
{
INT32 ret = 0;
char errmsg[200] = {0};
int sqlCode = 0; timeval tBegin, tEnd, tDiff; const char* precompile_statment2 = "INSERT INTO `tbl_test`( pri_key, nor_char, max_num, long_num, rec_upd_ts) VALUES(?, ?, ?, ?, ?)"; MYSQL conn;
mysql_init(&conn); if (mysql_real_connect(&conn, "127.0.0.1", "dba", "abcdefg", "TESTDB", 3306, NULL, 0) == NULL)
{
fprintf(stderr, " mysql_real_connect, 2 failed\n");
exit(0);
} MYSQL_STMT *stmt = mysql_stmt_init(&conn);
if (!stmt)
{
fprintf(stderr, " mysql_stmt_init, 2 failed\n");
fprintf(stderr, " %s\n", mysql_stmt_error(stmt));
exit(0);
} if (mysql_stmt_prepare(stmt, precompile_statment2, strlen(precompile_statment2)))
{
fprintf(stderr, " mysql_stmt_prepare, 2 failed\n");
fprintf(stderr, " %s\n", mysql_stmt_error(stmt));
exit(0);
} int i = 0;
int max_num = 3;
const int FIELD_NUM = 5;
while (i < max_num)
{
//MYSQL_BIND bind[196] = {0};
MYSQL_BIND bind[FIELD_NUM];
memset(bind, 0, FIELD_NUM * sizeof(MYSQL_BIND)); unsigned long str_length = strlen(pri_key);
bind[0].buffer_type = MYSQL_TYPE_STRING;
bind[0].buffer = (char *)pri_key;
bind[0].buffer_length = STRING_LEN;
bind[0].is_null = 0;
bind[0].length = &str_length; unsigned long str_length_nor = strlen(nor_char);
bind[1].buffer_type = MYSQL_TYPE_STRING;
bind[1].buffer = (char *)nor_char;
bind[1].buffer_length = STRING_LEN;
bind[1].is_null = 0;
bind[1].length = &str_length_nor; bind[2].buffer_type = MYSQL_TYPE_LONG;
bind[2].buffer = (char*)&max_num;
bind[2].is_null = 0;
bind[2].length = 0; bind[3].buffer_type = MYSQL_TYPE_LONG;
bind[3].buffer = (char*)&max_num;
bind[3].is_null = 0;
bind[3].length = 0; MYSQL_TIME ts;
ts.year= 2002;
ts.month= 02;
ts.day= 03;
ts.hour= 10;
ts.minute= 45;
ts.second= 20; unsigned long str_length_time = strlen(rec_upd_ts);
bind[4].buffer_type = MYSQL_TYPE_TIMESTAMP;
bind[4].buffer = (char *)&ts;
bind[4].is_null = 0;
bind[4].length = 0; if (mysql_stmt_bind_param(stmt, bind))
{
fprintf(stderr, " mysql_stmt_bind_param, 2 failed\n");
fprintf(stderr, " %s\n", mysql_stmt_error(stmt));
exit(0);
} cout << "before execute\n";
if (mysql_stmt_execute(stmt))
{
fprintf(stderr, " mysql_stmt_execute, 2 failed\n");
fprintf(stderr, " %s\n", mysql_stmt_error(stmt));
exit(0);
}
cout << "after execute\n"; i++;
} mysql_commit(&conn); mysql_stmt_close(stmt); return 0;
}
MYSQL开发性能研究——批量插入的优化措施的更多相关文章
- MYSQL开发性能研究——INSERT,REPLACE,INSERT-UPDATE性能比较
一.为什么要有这个实验 我们的系统是批处理系统,类似于管道的架构.而各个数据表就是管道的两端,而我们的程序就类似于管道本身.我们所需要做的事情无非就是从A表抽取数据,经过一定过滤.汇总等操作放置到B表 ...
- 深入理解MySQL开发性能优化.pptx
深入理解MySQL开发性能优化.pptx,依旧上传baidu pan http://pan.baidu.com/s/1jIwGslS,视频暂未出,培训完成后会更新.
- JDBC批量插入数据优化,使用addBatch和executeBatch
JDBC批量插入数据优化,使用addBatch和executeBatch SQL的批量插入的问题,如果来个for循环,执行上万次,肯定会很慢,那么,如何去优化呢? 解决方案:用 preparedSta ...
- mysql 开发进阶篇系列 4 SQL 优化(各种优化方法点)
1 通过handler_read 查看索引使用情况 如果索引经常被用到 那么handler_read_key的值将很高,这个值代表了一个行被索引值读的次数, 很低的值表明增加索引得到的性能改善不高,索 ...
- 聊聊编程开发的数据库批量插入(sql)
这里的批量插入,主要是支持SQL的大型存储数据库,本文以Mysql,Oracle,SqlServer,postgresql4类来说明,这大概是国内应用比较多的了.其余的应该可以按照这些去找.提到编程的 ...
- mysql 开发进阶篇系列 1 SQL优化(show status命令)
一.概述 随着上线后,数据越来越多,很多sql语句开始显露出性能问题,本章介绍在mysql中优化sql语句的方法. 1. 通过show status 命令了解各种sql的执行频率 通过show [ ...
- mysql 开发进阶篇系列 2 SQL优化(explain分析)
接着上一篇sql优化来说 1. 定位执行效率较低的sql 语句 通过两种方式可以定位出效率较低的sql 语句. (1) 通过上篇讲的慢日志定位,在mysqld里写一个包含所有执行时间超过 long_q ...
- mysql 开发进阶篇系列 23 应用层优化与查询缓存
一.概述 前面章节介绍了很多数据库的优化措施,但在实际生产环境中,由于数据库服务器本身的性能局限,就必须要对前台的应用来进行优化,使得前台访问数据库的压力能够减到最小. 1. 使用连接池 对于访问数据 ...
- 什么影响了mysql的性能-硬件资源及系统方面优化
随着数据量的增大,数据库的性能问题也是个值得关注的问题,很多公司对mysql性能方面没有太过重视,导致服务浪费过多资源.mysql服务性能差从而直接影响用户体验,这里我们简单的先来聊聊什么影响了mys ...
随机推荐
- atitit.提升开发效率---mda 软件开发方式的革命--(2)
atitit.提升开发效率---mda 软件开发方式的革命--(2) 1. 一个完整的MDA规范包含: 1 2. 一个完整的MDA应用程序包含: 1 3. MDA能够带来的最大的三个好处是什么? 2 ...
- Eclipse连接到My sql数据库的操作总结/配置数据库驱动
Eclipse连接到MYSQL数据库的操作 (自己亲测,开始学习Eclipse(我的Eclipse版本是4.5.2,Jdbc驱动器的jar包版本是5.1.7,亲测可以使用)连接到数据库的时候,发现网上 ...
- javascript实例——时间日期篇(包含5个实例)
本来想在网上找一些js实例来练练手,结果发现一本书<突破JavaScript编程实例五十讲>,看了下内容还不错,就下了下来: 后面又下了该书籍的源码,一看才发现这本书编的日期是2002年的 ...
- JQuery快速入门
Write less, do more, I like jQuery. jQuery是最常用的js库,整体来说非常轻量并易于扩展,对于移动应用可以使用其更轻量的孪生兄弟Zepto代替.其是由John ...
- Android BitmapShader 实战 实现圆形、圆角图片
转载自:http://blog.csdn.net/lmj623565791/article/details/41967509 1.概述 记得初学那会写过一篇博客Android 完美实现图片圆角和圆形( ...
- android ormlite queryBuilder.where() 多条件
QueryBuilder<VideoTagInfo, Integer> queryBuilder = videoTagInfoIntegerDao.queryBuilder();try { ...
- nmap端口状态解析
nmap端口状态解析 状态 说明 open 应用程序在该端口接收 TCP 连接或者 UDP 报文 closed 关闭的端口对于nmap也是可访问的, 它接收nmap探测报文并作出响应.但没有应用程序在 ...
- FPGA4U FPGA SDRAM Controller
-- https://fpga4u.epfl.ch/wiki/FPGA4U_Description -- The SDRAM bits data ..> signals, -- one ..&g ...
- Oracle的sqlnet.ora与password文件试验
先看有没有sqlnet.ora [oracle@localhost ~]$ cd $ORACLE_HOME[oracle@localhost dbhome_1]$ cd network[oracle@ ...
- mycat初探
1:安装客户端 yum install mysql 2:安装服务端 yum install mysql-server 3:mycat要求不区分大小写 my.cnf(/etc/my.cnf)的[mysq ...