Adaboost 卡口车辆检测训练
之前做了SVM的车脸检测,主要是针对车脸,接下来尝试利用Adaboost和Haar进行车脸的检测。我利用的主要是opencv中的cascade,其已经把Adaboost相关的算法做成了exe,直接调用就可以了,不像SVM中我们可能需要再调用。如果需要对boost源码进行修改,可以利用Cmake将生成opencv的源代码,(Cmake真是个很方便的东西,之前做交叉编译用Automake来弄,差点累的半死)。
首先我来介绍一下几个主要使用的工具。分别在opencv库路径下的,build/x64/vc10/bin目录下,你也可以选择vc11,12 或者x64,根据自己电脑的情况来使用。
主要我们使用的是opencv_createsamples.exe,opencv_traincascade.exe,其中前者主要是来创建训练的样本文件,vec文件。另外还有俩那个opencv_haartraining.exe,这个马上就要被淘汰了,主要是用c来实现的,并且仅支持haar这个特征描述子,opencv_performace,主要是用来测试模型的性能的。
级联分类器的参数设置,取自opencv官网,针对这两个exe的参数,opencv官网还有刚详细的链接
opencv官网cascade的详细参数讲解
下面是 opencv_traincascade (主要参数和haar_training还是有部分不同的)的命令行参数,以用途分组介绍:
通用参数:
-data
目录名,如不存在训练程序会创建它,用于存放训练好的分类器。
-vec
包含正样本的vec文件名(由 opencv_createsamples 程序生成)。
-bg
背景描述文件,也就是包含负样本文件名的那个描述文件。
-numPos
每级分类器训练时所用的正样本数目。
-numNeg
每级分类器训练时所用的负样本数目,可以大于 -bg 指定的图片数目。
-numStages
训练的分类器的级数。
-precalcValBufSize
缓存大小,用于存储预先计算的特征值(feature values),单位为MB。
-precalcIdxBufSize
缓存大小,用于存储预先计算的特征索引(feature indices),单位为MB。内存越大,训练时间越短。
-baseFormatSave
这个参数仅在使用Haar特征时有效。如果指定这个参数,那么级联分类器将以老的格式存储。
级联参数:
-stageType
级别(stage)参数。目前只支持将BOOST分类器作为级别的类型。
-featureType<{HAAR(default), LBP}>
特征的类型: HAAR - 类Haar特征; LBP - 局部纹理模式特征。
-w
-h
训练样本的尺寸(单位为像素)。必须跟训练样本创建(使用 opencv_createsamples 程序创建)时的尺寸保持一致。这里需要注意的是w,h不要乱写啊,计算负责度开销很大,否则会严重影响训练速度,根据实际的需求来填写,我选择的是32×32,之前用了50×50很慢很慢
Boosted分类器参数:****
-bt <{DAB, RAB, LB, GAB(default)}>
Boosted分类器的类型: DAB - Discrete AdaBoost, RAB - Real AdaBoost, LB - LogitBoost, GAB - Gentle AdaBoost。
-minHitRate
分类器的每一级希望得到的最小检测率。总的检测率大约为 min_hit_rate^number_of_stages。
-maxFalseAlarmRate
分类器的每一级希望得到的最大误检率。总的误检率大约为 max_false_alarm_rate^number_of_stages.
-weightTrimRate
Specifies whether trimming should be used and its weight. 一个还不错的数值是0.95。
-maxDepth
弱分类器树最大的深度。一个还不错的数值是1,是二叉树(stumps)。
-maxWeakCount
每一级中的弱分类器的最大数目。The boosted classifier (stage) will have so many weak trees (<=maxWeakCount), as needed to achieve the given -maxFalseAlarmRate.
类Haar特征参数:
-mode
选择训练过程中使用的Haar特征的类型。 BASIC 只使用右上特征, ALL 使用所有右上特征和45度旋转特征。
当opencv_traincascade 程序训练结束以后,训练好的级联分类器将存储于文件cascade.xml中,这个文件位于 -data 指定的目录中。这个目录中的其他文件是训练的中间结果,当训练程序被中断后,再重新运行训练程序将读入之前的训练结果,而不需从头重新训练。训练结束后,你可以删除这些中间文件。
注意事项,我训练时碰到的诸多问题!!!!!这里说的都是训练的关键!!!
1.首先是,train的bat文件和create_sample的bat文件中,大小宽高一定要一致,否则会报错。
2.run_train.bat中,对于缓冲区的大小的设置-precalcValBufSize, -precalcIdxBufSize当时我为了训练的快一点,在服务器上设置的是5000,5000,换到另一台服务器上之后总报错,设置为4000MB就不报错了,可能是内存设置的过大,原则上是尽可能设置的较大,训练的速度会更快,其可以把计算的特征值存在内存中,不用虚拟内存。
3.在这里-numPos和-numNeg的设置,这里设置的是在每一级训练中参与训练的正样本和负样本个数,千万不要和训练的样本数一样,应该设置为80%左右适宜,否则容易陷入死循环,就是训练程序一直不动了,不走向下一级的训练。
4.有时会显示中途terminated,原因是每一级分配的numPos,numNeg太少,已经达到设定的精度需求,就不再继续下一级,此时加大numPos即可。
5.在样本数据集的准备上,首先至少要多点吧,最好是几千个,这才叫机器学习嘛。此外,负样本的数量一定要比正样本多,这样才能突出正样本,最好在1:2 1:3左右吧,根据训练的结果。其实,大家不要小看训练样本,其实这些都是固定的,算法形成基本就那样了,更关键的是在样本的准备上,对于最终的模型性能至关重要,不要小看样本。
首先我使用的是opencv下自带的opencv_createsamples.exe和opencv_opencv_traincascade.exe。
这个在opencv 的库目录bin下面可以找到。
由于这里使用的是编译好的工具exe,因此传入的参数我们通常通过写批处理文件bat文件来实现。
以下是run_createssamples.bat,需要自己建立
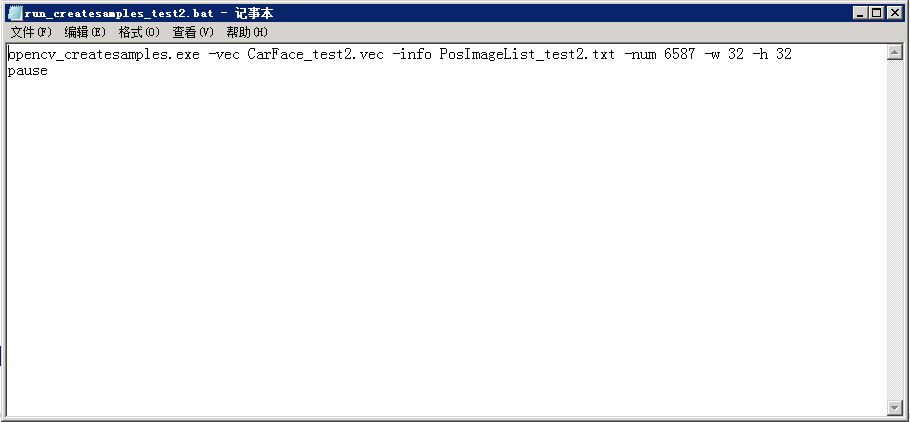
这里说明一下这个文件,-vec 制定生成的vec文件,-info指定正样本文件列表,-num指定样本数量,-w,-h指定样本的大小,需要主要的是样本的数量最后不要留有空行。
我这次训练的数据集正样本个数为6587,负样本个数为6584。这里对于负样本的讨论暂不展开,读者可以自己设置,我这里大致是1:1,看到一些别的人说1:2,1:3的效果比较好,读者可以自己控制个数作比较,但是训练的样本数至少在两三千以上才会有比较好的效果。
PosImageList32_32.txt内部是这样的,行中第一个参数是图片的路径,第二个参数是正样本个数,之后跟着的正样本的坐标,由于我这里已经将样本截取了出来车脸就是32*32,因此这里是直接给出0 0 32 32。

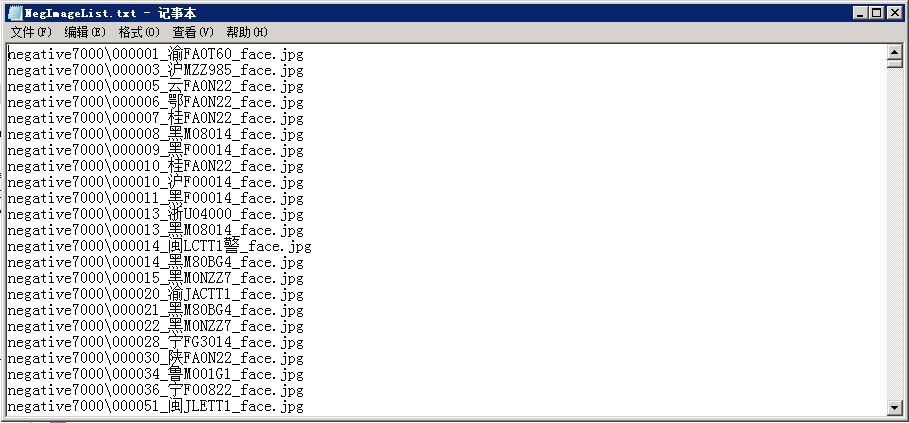
NegImageList.txt内部是这样的,直接给出负样本的文件路径即可,我这里负样本文件名中还有face,但已经是负样本不包含车脸,负样本一般最后跟实际的应用场景一致,在这里可以选取为卡口马路上的景象,杂物,行人,自行车等。
以下是run_traincascade_test2.bat,需要自己建立 !
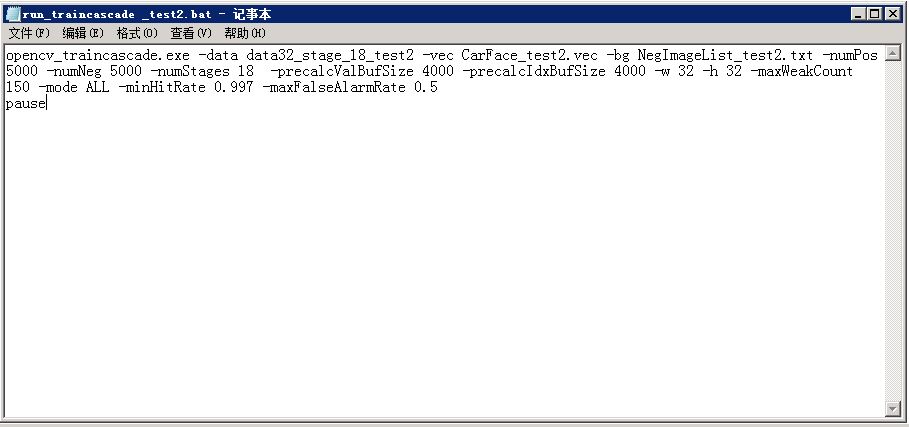
详细说明一下这几个参数 -data 是用来存放模型的路径以及每一级生成的相关参数注意!!,在这里-data的路径必须自己手动设置,要不然会报错,说找不到这个路径,重要的事情说3遍!! -vec用来指定正样本生成的向量文件,-bg是指定负样本文件文件,-numPos这里说明是每一级使用的正样本个数,一般为正样本数总量的80%左右,如果跟总样本数一致会导致无法收敛,也就是训练一致不结束,如果太少,训练的效果较差。 -numNeg同理, -numStages指定训练的级数,一般15-20级可以达到较好的效果,-precalcValBufSize 和 -precalcIdxBufSize 指定的是存储计算过程中特征和特征索引的缓存大小,在内存足够的情况下,这两个值设置的大一点可以加速训练过程,但是千万不要设置的太大,电脑内存不够,训练会报错的!!! -maxWeakCount 设置每一级中弱分类器的最大个数,这里设置为150,-mode 指定使用harr特征中右上特征和旋转特征,-miniHitRate 每一级的最低的命中率,默认为0.995,这里设置为0,997, -maxFalseAlarmRate 最大误报率设置为0.5
OK设置好这些参数,就可以开启训练啦!!!!
训练过程,当可以中断训练,重新运行批处理文件,他会载入之前生成的中间文件,所以不影响。如果发现长时间一级下不去的话,可能是没收敛,需要重新调整参数,参见我上面说的。我运行了这个大概32*32的规模,运行了18级,每次取5000个样本计算,总共是花了3天时间才训练完。仅供参考

训练结束后生成18个过程的中间文件,以及最后的模型文件cascade.xml,我将在下一讲中介绍怎么使用这个模型文件。
这是我在应用过程中的一些见解和心得,网上也看了零零碎碎不少资料,希望能帮到你。如有错误,敬请指出。谢谢。
Adaboost 卡口车辆检测训练的更多相关文章
- 转一篇 adaboost 的好文 AdaBoost简介及训练误差分析
AdaBoost简介及训练误差分析 http://wenku.baidu.com/link?url=y9Q2qjrJr6IShyY5EQEmvkPZmmP4t3HOdHUgMWaIffI9W0uzTr ...
- SIGAI机器学习第二十二集 AdaBoost算法3
讲授Boosting算法的原理,AdaBoost算法的基本概念,训练算法,与随机森林的比较,训练误差分析,广义加法模型,指数损失函数,训练算法的推导,弱分类器的选择,样本权重削减,实际应用. AdaB ...
- AdaBoost 和 Real Adaboost 总结
AdaBoost 和 Real Adaboost 总结 AdaBoost Real AdaBoost AdaBoost AdaBoost, Adaptive Boosting(自适应增强), 是一种集 ...
- 统计学习方法 AdaBoost
提升方法的基本思路 在概率近似正确(probably approximately correct,PAC)学习的框架中, 一个概念(一个类),如果存在一个多项式的学习算法能够学习它,并且正确率很高,那 ...
- Adaboost算法结合Haar-like特征
Adaboost算法结合Haar-like特征 一.Haar-like特征 目前通常使用的Haar-like特征主要包括Paul Viola和Michal Jones在人脸检测中使用的由Papageo ...
- Real Adaboost总结
Real Adaboost分类器是对经典Adaboost分类器的扩展和提升,经典Adaboost分类器的每个弱分类器仅输出{1,0}或{+1,-1},分类能力较弱,Real Adaboost的每个弱分 ...
- Adaboost原理及目标检测中的应用
Adaboost原理及目标检测中的应用 whowhoha@outlook.com Adaboost原理 Adaboost(AdaptiveBoosting)是一种迭代算法,通过对训练集不断训练弱分类器 ...
- AdaBoost原理,算法实现
前言: 当做重要决定时,大家可能综合考虑多个专家而不是一个人的意见.机器学习处理问题也是如此,这就是元算法背后的思路.元算法是对其他算法进行组合的一种方式,前几天看了一个称作adaboost方法的介绍 ...
- Adaboost的几个人脸检测网站
[1]基础学习笔记之opencv(1):opencv中facedetect例子浅析 http://www.cnblogs.com/tornadomeet/archive/2012/03/22/2411 ...
随机推荐
- Python Import 详解
http://blog.csdn.net/appleheshuang/article/details/7602499 一 module通常模块为一个文件,直接使用import来导入就好了.可以作为mo ...
- 互联网产品团队中Web前端工程师的重要性
国内外各大互联网公司,都有UEx/d|UCD|CDC(Customer Research & User Experience Design Center)团队. 在很多公司会认为,合格的产品经 ...
- 小白学Linux(四)--系统常用命令
这里记录一下基础的系统常用命令,都是日常可能用到的,需要记住的一些命令.主要分为5个模块:关于时间,输出/查看,关机/重启,压缩归档和查找. 时间: date :查看设置当前系统时间,dat ...
- C#中的接口实现多态
我们都知道虚方法实现多态,抽象方法实现多态等,我们今天来看看如何使用接口实现多态 1.首先我们先要来了解了解什么是接口,它存在的意识 01.接口就是为了约束方法的格式(参数和返回值类型)而存在的 02 ...
- linux shell 编程
1,获取命令执行的结果,字符串拼接(脚本最常使用的功能) cmd_result=$(date +%Y%b%d) //使用变量获取命令执行的结果 或者 cmd_result=`date ...
- [下载] MultiBeast 6.2.1版,支持10.9 Mavericks。Mac上的驱动精灵,最简单安装驱动的方式。
下载地址1:http://pan.baidu.com/s/1i3ier9F 下载地址2:http://www.tonymacx86.com/downloads.php?do=cat&id=3 ...
- 什么是CSR证书申请文件?
CSR是Cerificate Signing Request的英文缩写,即证书请求文件,在多方之间在互联网上安全分享数据的公钥基础架构PKI系统中,CSR文件必须在申请和购买SSL证书之前创建.也 ...
- XML的文档声明
1.XML的文档声明 <?xml version="1.0" encoding="utf-8"?> 文档声明必须写在第一行第一列 属性: versi ...
- java多线程系列7-停止线程
本文主要总结在java中停止线程的方法 在java中有以下三种方法可以终止正在运行的线程: 1.使用退出标志 2.使用stop方法强行终止线程,但是不推荐,因为stop和suspend.resume一 ...
- C语言柔性数组
结构中最后一个元素允许是未知大小的数组,这个数组就是柔性数组.但结构中的柔性数组前面必须至少一个其他成员,柔性数组成员允许结构中包含一个大小可变的数组,sizeof返回的这种结构大小不包括柔性数组的内 ...