Learning to Rank算法介绍:GBRank
之前的博客:http://www.cnblogs.com/bentuwuying/p/6681943.html中简单介绍了Learning to Rank的基本原理,也讲到了Learning to Rank的几类常用的方法:pointwise,pairwise,listwise。前面已经介绍了pairwise方法中的 RankSVM 和 IR SVM,这篇博客主要是介绍另一种pairwise的方法:GBRank。
GBRank的基本思想是,对两个具有relative relevance judgment的Documents,利用pairwise的方式构造一个特殊的 loss function,再使用GBDT的方法来对此loss function进行优化,求解其极小值。
1. 构造loss function
GBRank的创新点之一就在于构造一个特殊的loss function。首先,我们需要构造pair,即在同一个query下有两个doc,我们可以通过人工标注或者搜索日志中获取的方法,来对这两个doc与该query的相关程度进行判断,得到一个相关关系,即其中一个doc的相关程度要比另一个doc的相关程度更高,这就是relative relevance judgment。一旦我们有了这个pairwise的相对关系,问题就成了如何利用这些doc pair学习出一个排序模型。
假设我们有以下的preference pairs 作为training data:
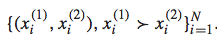
我们构造出以下的loss function:
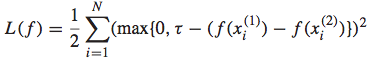
我个人觉得,这个loss function有些受SVM中的hinge loss的启发,是在hinge loss的基础上,将原来为1的参数改成了 。即当
。即当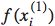 与
与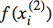 的差距达到以上的时候,loss才为0,否则loss为
的差距达到以上的时候,loss才为0,否则loss为 。
。
然后问题就变成了怎样对这个loss function进行优化求解极小值。这里使用了GBDT的思想,即Functional Gradient Descent的方法。
2. Functional Gradient Descent
首先我们来回顾一下Functional Gradient Descent在GBDT中的使用,具体可见之前的博客:http://www.cnblogs.com/bentuwuying/p/6667267.html。
在GBDT中,Functional Gradient Descent的使用为:将需要求解的F(x)表示成一个additive model,即将一个函数分解为若干个小函数的加和形式,而这每个小函数的产生过程是串行生成的,即每个小函数都是在拟合 loss function在已有的F(x)上的梯度方向(由于训练数据是有限个数的,所以F(x)是离散值的向量,而此梯度方向也表示成一个离散值的向量),然后将拟合的结果函数进一步更新到F(x)中,形成一个新的F(x)。
再回到我们现在面对的问题,对loss function,利用Functional Gradient Descent的方法优化为极小值。即将f(x)表示成additive model,每次迭代的时候,用一个regression tree来拟合loss function在当前f(x)上的梯度方向。此时由于训练数据是有限个数的,f(x)同样只是一系列离散值,梯度向量也是一系列离散值,而我们就是使用regression tree来拟合这一系列离散值。但不一样的地方在于,这里的loss function中,有两个不一样的f(x)的离散值与,所以每次我们需要对f(x)在这两个点上的值都进行更新,即需要对一个training instance计算两个梯度方向。
首先,我们将

看做两个未知变量,然后求解loss function对这两个未知变量的梯度,如下:
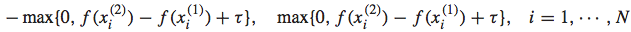
如果 ,则此时对应的loss为0,我们无需对f(x)进行迭代更新;而如果
,则此时对应的loss为0,我们无需对f(x)进行迭代更新;而如果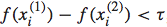 ,则此时的loss不为0,我们需要对f(x)进行迭代更新,即使得新的f(x)在这个instance上的两个点的预测值能够更接近真实值。
,则此时的loss不为0,我们需要对f(x)进行迭代更新,即使得新的f(x)在这个instance上的两个点的预测值能够更接近真实值。

具体为:

当学习速率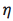 等于1的时候,更新公式即为:
等于1的时候,更新公式即为:

此时需要注意的是,有些feature vector x可能会出现多次,关键在不同instance中对其的更新值还可能不相同。
一种方法是对同一个feature vector x,将其不同的更新值求平均,作为其最终需要更新到的目标值,再进行拟合。
另一种更好的方法是,将所有的instance都加入到regression拟合过程中,不论这些feature vector是否会出现多次且不同次的拟合目标还不一样。我们需要做的就是让regression拟合过程,结合所有instance的全局信息,自己决定该怎么样拟合,怎样解决同一个feature vector有不同目标值得问题。
3. 模型学习步骤
当我们收集到所有loss值不为0的training instance后,我们便得到了其对应的更新值:
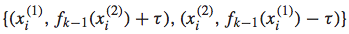
接着,我们便使用一棵regression tree对这些数据进行拟合,生成一个拟合函数gk(x),然后将这次迭代更新的拟合函数更新到f(x)中,此处采用线性叠加的方式:
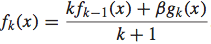
其中,ß即为shrinking系数。
在这里大家或许会有疑问,为什么在每次迭代更新的时候,新的regression tree不像GBDT中那样,纯粹地去拟合梯度方向(一个离散值的向量),而是去拟合这样一个 原始预测值+梯度更新值 后的新预测值向量呢?我自己的理解是这样的(不知道对不对?欢迎大家指正):因为在每次迭代更新的时候,只是取了部分训练数据(即所有loss值不为0的training instance中的doc pair),所以每次拟合的时候,都只是对这部分数据进行训练,得到一个regression tree,然后把这个新的拟合函数(即regression tree)添加到总的预测函数f(x)中去,即这个regression tree在预测时候是需要对所有训练数据,而不是部分数据,进行预测的。所以如果每次迭代是去拟合梯度的话(梯度方向完全有可能与当前的f(x)向量方向相差很大),在预测的时候,这个regression tree对其余数据(并没有参与这个regression tree训练的数据)的预测值会偏离它们原始值较多,而且这个偏离是不在期望之中的,因为这些数据的当前预测值已经相对靠谱了(不会对loss function有贡献)。所以,当每次拟合的目标是 原始f(x)向量 + 梯度向量 的时候,这个新的向量不会跑的太偏(即跟原始向量相差较小),这时候拟合出来的结果regression tree在对整体数据进行预测的时候,也不会跑的太偏,只是会根据梯度方向稍微有所改变,对其它并不需要更新的数据的影响也相对较小。但同时也在逐渐朝着整体的优化方向上去尝试,所以才会这么去做。
总结来看,GBRank的整体学习步骤总结如下:

版权声明:
本文由笨兔勿应所有,发布于http://www.cnblogs.com/bentuwuying。如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任。
Learning to Rank算法介绍:GBRank的更多相关文章
- [笔记]Learning to Rank算法介绍:RankNet,LambdaRank,LambdaMart
之前的博客:http://www.cnblogs.com/bentuwuying/p/6681943.html中简单介绍了Learning to Rank的基本原理,也讲到了Learning to R ...
- Learning to Rank算法介绍:RankNet,LambdaRank,LambdaMart
之前的博客:http://www.cnblogs.com/bentuwuying/p/6681943.html中简单介绍了Learning to Rank的基本原理,也讲到了Learning to R ...
- Learning to Rank算法介绍:RankSVM 和 IR SVM
之前的博客:http://www.cnblogs.com/bentuwuying/p/6681943.html中简单介绍了Learning to Rank的基本原理,也讲到了Learning to R ...
- [Machine Learning] Learning to rank算法简介
声明:以下内容根据潘的博客和crackcell's dustbin进行整理,尊重原著,向两位作者致谢! 1 现有的排序模型 排序(Ranking)一直是信息检索的核心研究问题,有大量的成熟的方法,主要 ...
- Learning to rank基本算法
搜索排序相关的方法,包括 Learning to rank 基本方法 Learning to rank 指标介绍 LambdaMART 模型原理 FTRL 模型原理 Learning to rank ...
- Learning to Rank之RankNet算法简介
排序一直是信息检索的核心问题之一, Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning to Rank的简介请见我的博文Learning to Rank ...
- Learning to Rank简介
Learning to Rank是采用机器学习算法,通过训练模型来解决排序问题,在Information Retrieval,Natural Language Processing,Data Mini ...
- Learning To Rank之LambdaMART前世今生
1. 前言 我们知道排序在非常多应用场景中属于一个非常核心的模块.最直接的应用就是搜索引擎.当用户提交一个query.搜索引擎会召回非常多文档,然后依据文档与query以及用户的相关程度对 ...
- Learning to rank 介绍
PS:文章主要转载自CSDN大神hguisu的文章"机器学习排序": http://blog.csdn.net/hguisu/article/details/79 ...
随机推荐
- 字符函数 php
strrchr( '123456789.xls' , '.' ); //程序从后面开始查找 '.' 的位置,并返回从 '.' 开始到字符串结尾的所有字符
- C#中的DBNull、Null、""和String.Empty
1.对DBNull的解释: 该类用于指示不存在某个已知值(通常在数据库应用程序中). 在数据库应用程序中,空对象是字段的有效值.该类区分空值(空对象)和未初始化值(DBNull.Va ...
- border-sizing属性
box-sizing属性可以为三个值之一:content-box(default),border-box,padding-box. content-box,border和padding不计算入widt ...
- P3092 [USACO13NOV]没有找零No Change
题目描述 Farmer John is at the market to purchase supplies for his farm. He has in his pocket K coins (1 ...
- SQL SERVER 2012 SEQUENCE
一.Sequence简介 Sequence对象对于Oracle用户来说是最熟悉不过的数据库对象了, 在SQL SERVER2012终于也可以看到这个对象了.Sequence是SQL Server201 ...
- Web登录敲门砖之sql注入
声明:文本原创,转载请说明出处,若因本文而产生任何违法违纪行为将与本人无关.在百度.博客园.oschina.github .SegmentFault.上面都关于sql注入的文章和工具.看过很多sql注 ...
- Grafana+Prometheus系统监控之webhook
概述 Webhook是一个API概念,并且变得越来越流行.我们能用事件描述的事物越多,webhook的作用范围也就越大.Webhook作为一个轻量的事件处理应用,正变得越来越有用. 准确的说webho ...
- 《java.util.concurrent 包源码阅读》16 一种特别的BlockingQueue:SynchronousQueue
SynchronousQueue是一种很特别的BlockingQueue,任何一个添加元素的操作都必须等到另外一个线程拿走元素才会结束.也就是SynchronousQueue本身不会存储任何元素,相当 ...
- ajax处理级联访问数据库显示
首先创建简单的html页面,写出如下代码: 静态页相关代码: js代码:
- 项目实战5—企业级缓存系统varnish应用与实战
企业级缓存系统varnish应用与实战 环境背景:随着公司业务快速发展,公司的电子商务平台已经聚集了很多的忠实粉丝,公司也拿到了投资,这时老板想通过一场类似双十一的活动,进行一场大的促销,届时会有非常 ...