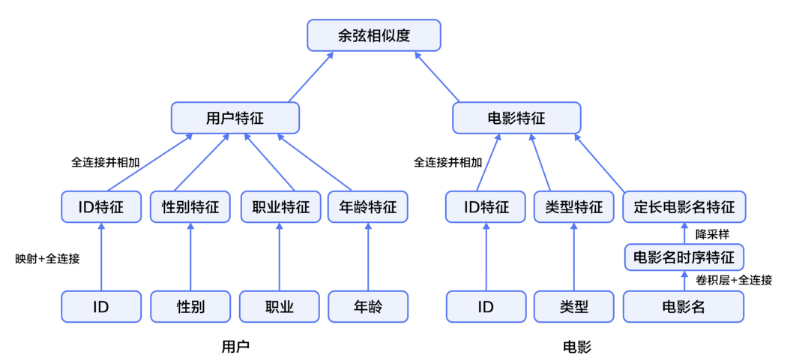
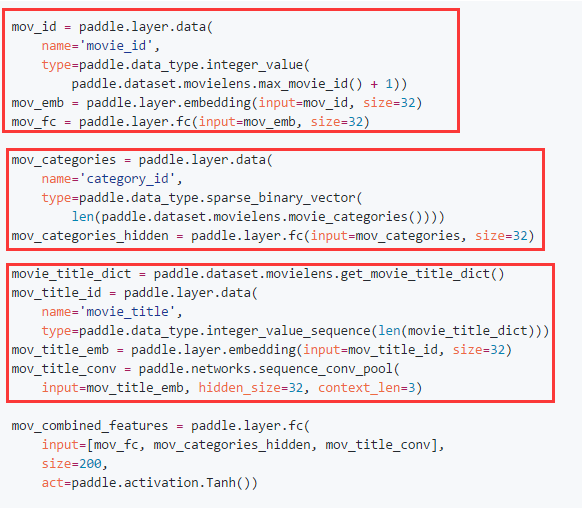
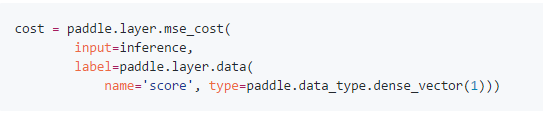
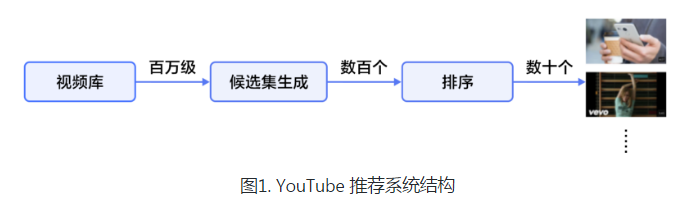
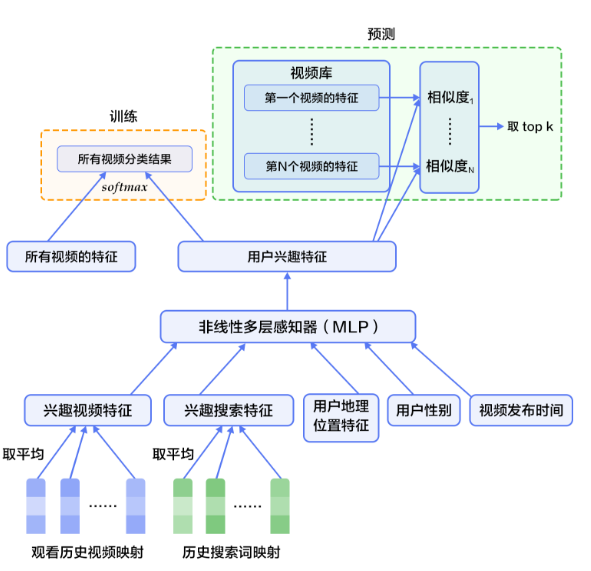
DNN个性化推荐模型



DNN个性化推荐模型的更多相关文章
- 搜索实时个性化模型——基于FTRL和个性化推荐的搜索排序优化
本文来自网易云社区 作者:穆学锋 简介:传统的搜索个性化做法是定义个性化的标签,将用户和商品通过个性化标签关联起来,在搜索时进行匹配.传统做法的用户特征基本是离线计算获得,不够实时:个性化标签虽然具有 ...
- 为什么要用深度学习来做个性化推荐 CTR 预估
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:苏博览 深度学习应该这一两年计算机圈子里最热的一个词了.基于深度学习,工程师们在图像,语音,NLP等领域都取得了令人振奋的进展.而深 ...
- CSDDN特约专稿:个性化推荐技术漫谈
本文引自http://i.cnblogs.com/EditPosts.aspx?opt=1 如果说过去的十年是搜索技术大行其道的十年,那么个性化推荐技术将成为未来十年中最重要的革新之一.目前几乎所有大 ...
- 从0开始做垂直O2O个性化推荐-以58到家美甲为例
从0开始做垂直O2O个性化推荐 上次以58转转为例,介绍了如何从0开始如何做互联网推荐产品(回复"推荐"阅读),58转转的宝贝为闲置物品,品类多种多样,要做统一的宝贝画像比较难,而 ...
- TensorFlow实战——个性化推荐
原创文章,转载请注明出处: http://blog.csdn.net/chengcheng1394/article/details/78820529 请安装TensorFlow1.0,Python3. ...
- 闲聊DNN CTR预估模型
原文:http://www.52cs.org/?p=1046 闲聊DNN CTR预估模型 Written by b manongb 作者:Kintocai, 北京大学硕士, 现就职于腾讯. 伦敦大学张 ...
- Machine Learning With Spark学习笔记(在10万电影数据上训练、使用推荐模型)
我们如今開始训练模型,还输入參数例如以下: rank:ALS中因子的个数.通常来说越大越好,可是对内存占用率有直接影响,通常rank在10到200之间. iterations:迭代次数,每次迭代都会降 ...
- Python个人项目--豆瓣图书个性化推荐
项目名称: 豆瓣图书个性化推荐 需求简述:从给定的豆瓣用户名中,获取该用户所有豆瓣好友列表,从豆瓣好友中找出他们读过的且评分5星的图书,如果同一本书被不同的好友评5星,评分人数越多推荐度越高. 输入: ...
- 个性化推荐调优:重写spark推荐api
最近用spark的mlib模块中的协同过滤库做个性化推荐.spark里面用的是als算法,本质上是矩阵分解svd降维,把一个M*N的用户商品评分矩阵分解为M*K的userFeature(用户特征矩阵) ...
随机推荐
- 《Django By Example》第十二章 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者注:第十二章,全书最后一章,终于到这章 ...
- response.sendRedirect 报 java.lang.IllegalStateException 异常的解决思路
今天在进行代码开发的时候,出现了 java.lang.IllegalStateException异常,response.sendRedirect("./DEFAULT.html") ...
- js实现哈希表(HashTable)
在算法中,尤其是有关数组的算法中,哈希表的使用可以很好的解决问题,所以这篇文章会记录一些有关js实现哈希表并给出解决实际问题的例子. 第一部分:相关知识点 属性的枚举: var person = { ...
- 自动化利器-Zabbix
1.1为何需要监控系统 在一个IT环境中会存在各种各样的设备,例如:硬件设备.软件设备.其系统的构成也是非常复杂的. 多种应用构成负载的IT业务系统,保证这些资源的正常运转,是一个公司IT部门的职责. ...
- Fragment深入解析
写在顶部表示这点很重要: 本文转载自博客:http://blog.csdn.net/lmj623565791/article/details/37970961 欢迎访问原文 自从Fragment ...
- myeclipse2017破解失败解决办法
最近,笔者安装的myeclipse2017破解出了问题,破解本来是很简单的事,就是几步而已,但是一直出问题,现在安利一波myeclipse2017版破解失败解决办法.诸如下图:()因为笔者已经破解好了 ...
- 《Algorithms Unlocked》读书笔记1——循环和递归
<Algorithms Unlocked>是 <算法导论>的合著者之一 Thomas H. Cormen 写的一本算法基础. 书中没有涉及编程语言,直接用文字描述算法,我用 J ...
- Java转型(向上转型和向下转型)
在Java编程中经常碰到类型转换,对象类型转换主要包括向上转型和向下转型. 5.13.1 向上转型 我们在现实中常常这样说:这个人会唱歌.在这里,我们并不关心这个人是黑人还是白人,是成人还是小孩,也就 ...
- 恢复oracle数据库误删除数据的方法汇总
学习数据库时,我们只是以学习的态度,考虑如何使用数据库命令语句,并未想过工作中,如果误操作一下,都可能导致无可挽回的损失.当我在工作中真正遇到这些问题时,我开始寻找答案.今天主要以oracle数据库为 ...
- key-value存储Redis
Key-value数据库是一种以键值对存储数据的一种数据库,(类似java中的HashMap)每个键都会对应一个唯一的值. Redis与其他 key - value 数据库相比还有如下特点: Redi ...