在Caffe添加Python layer详细步骤
本文主要讨论的是在caffe中添加python layer的一般流程,自己设计的test_python_layer.py层只是起到演示作用,没有实际的功能。
1) Python layer 在caffe目录结构中放哪?
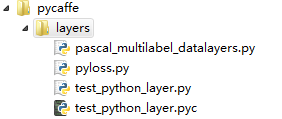
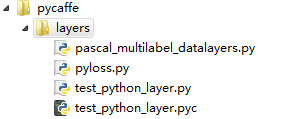
下图是caffe的目录结构,在本文中我是将python layer防止examples/pycaffe/layers/下
2)Python layer内容
我给这一个python layer取名为test_python_layer.py,其内容为
import caffe
import numpy as np class TestPythonLayer(caffe.Layer):
"""
Compute the Euclidean Loss in the same manner as the C++ EuclideanLossLayer
to demonstrate the class interface for developing layers in Python.
""" def setup(self, bottom, top):
# check input pair
if len(bottom) != 1:
raise Exception("Need two inputs to compute distance.") def reshape(self, bottom, top):
# loss output is scalar
top[0].reshape(1) def forward(self, bottom, top):
top[0].data[...] = np.sum(bottom[0].data**2) / bottom[0].num / 2.;print('Test passed!') def backward(self, top, propagate_down, bottom):
pass
大家一定要注意,我这样设计这个层(包括代码、代码所放位置)是有一个前提的,那就是我导出了相应的环境变量,如下图所示(红色部分遮住的是具体的路径,大家可以根据自己的实际情况进行调整)。如果没有设置环境变量,可能会出现模块找不到问题。

3)如何测试这个python layer的可行性
设计一个网络结构prototxt文件
name: "CIFAR10_quick"
layer {
name: "cifar"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mean_file: "examples/cifar10/mean.binaryproto"
}
data_param {
source: "examples/cifar10/cifar10_train_lmdb"
batch_size:
backend: LMDB
}
}
layer {
name: "cifar"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mean_file: "examples/cifar10/mean.binaryproto"
}
data_param {
source: "examples/cifar10/cifar10_test_lmdb"
batch_size:
backend: LMDB
}
}
layer {
name: "test"
type: "Python"
bottom: "data"
top: "loss"
python_param {
module: "test_python_layer"
layer: "TestPythonLayer"
}
}
及其对应solver文件
net: "examples/cifar10/test_python_layer.prototxt" base_lr: 0.001 lr_policy: "fixed" max_iter: solver_mode: CPU
通过下面命令即可测试其效果
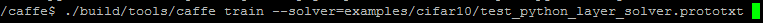
其输出为
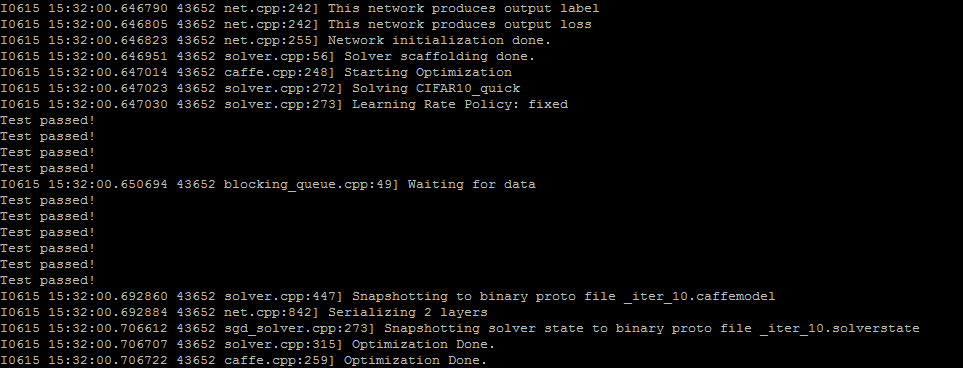
我是在cifar10样例的基础上设计上述python layer的,这点请大家注意。可以看出,“test passed!”一共出现了10次,这符合我们的预期。
4)下面是问题的重点,在测试的时候我们可能会遇到如下问题
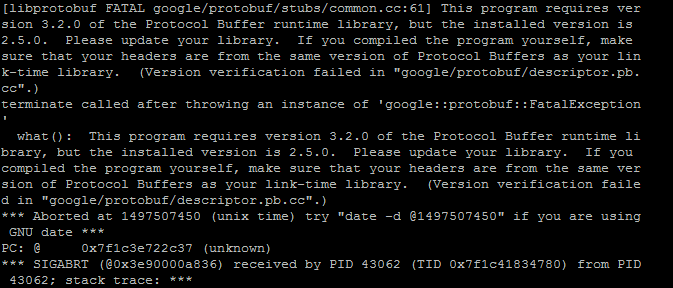
我自己在这个问题上摸索了一个上午(查了很多资料,始终没有解决这个问题),最后索性按照自己的理解来处理了。我的思路大致如下:在没有添加python layer的时候,我的caffe版本能够正常运行;protobuf版本不匹配问题,应该不是caffe C++部分引起的;这样问题就定位到python protobuf的版本问题,我发现自己python的protobuf版本为3.2.0,这样问题就可以轻而易举的按照如下方式解决了
先卸载已有的protobuf

然后按照2.5.0版本的protobuf(这个版本好应该根据自己的错误提示确定)

至此,问题得到解决!
5)关于python层,我谈谈自己的一些看法
- 可以用python layer实现on-the-fly的数据增强!
- GPU模式下,用python layer的时候应该牢记“数据是不是来回在GPU、CPU直接copy”!这样有助于你定位在什么地方应该用python layer!
在Caffe添加Python layer详细步骤的更多相关文章
- caffe添加python数据层
caffe添加python数据层(ImageData) 在caffe中添加自定义层时,必须要实现这四个函数,在C++中是(LayerSetUp,Reshape,Forward_cpu,Backward ...
- 小白安装Python环境详细步骤!
昨天,有小伙伴向我反映,他对我说“你好像还没教过我安装Python的吧?”听到这句话,我不禁汗颜起来,我的确好像没太注意Python学习的基础了,一直发各种爬虫与初学者看不懂的代码,在此我要向我的读者 ...
- Linux-Centos 用crontab定时运行python脚本详细步骤
服务器总是要定时运行某个程序,而我在解决这个问题的时候遇到很多困难, 特此记录下来. 1.编辑crontab配置 crontab -e 服务器一般会安装好crontab,若没有安装请按命令安装 yum ...
- 【RAC】10grac添加节点,详细步骤
RAC物理结构 现在的RAC环境是二个节点: dbp,dbs, 这个实验就是添加节点dbi. dbp,dbs和dbi节点的信息规划如下: 服务器主机名 dbp dbs dbi 公共IP地址(eth0) ...
- PyCharm自定义代码块设置方法-添加-删除【详细步骤】
原文:https://blog.csdn.net/chichu261/article/details/82887108 在做项目的时候,有些代码会需要频繁的码.如果去已有的项目中去复制,又需要找很久. ...
- Ubuntu16.04下caffe CPU版的详细安装步骤
一.caffe简介 Caffe,是一个兼具表达性.速度和思维模块化的深度学习框架. 由伯克利人工智能研究小组和伯克利视觉和学习中心开发. 虽然其内核是用C++编写的,但Caffe有Python和Mat ...
- Caffe 单独测试添加的layer
转载请注明出处,楼燚(yì)航的blog,http://home.cnblogs.com/louyihang-loves-baiyan/ 一般我们在使用Caffe的时候,可能需要根据自己的任务需求添加 ...
- 如何给caffe添加新的layer ?
如何给caffe添加新的layer ? 初学caffe难免会遇到这个问题,网上搜来一段看似经典的话, 但是问题来了,貌似新版的caffe并没有上面提到的vision_layer:
- caffe添加自己编写的Python层
由于Python的灵活性,我们在caffe中添加自己定义的层时使用python层会更加方便,开发速速也会比C++更快,现在我就在这儿简单说一下如何在caffe中添加自定义的python层(使用的原网络 ...
随机推荐
- 关联分析:FP-Growth算法
关联分析又称关联挖掘,就是在交易数据.关系数据或其他信息载体中,查找存在于项目集合或对象集合之间的频繁模式.关联.相关性或因果结构.关联分析的一个典型例子是购物篮分析.通过发现顾客放入购物篮中不同商品 ...
- MySQL常见建表选项以约束
一.CREATE TABLE 选项 1.在定义列的时候,指定列选项 1)DEFAULT <literal>:定义列的默认值 当插入一个新行到表中并且没有给该列明确赋值时,如果定义了列的默认 ...
- [Git]03 如何查看提交历史
在提交了若干更新之后,又或者克隆了某个项目,想回顾下提交历史,可以使用 gitlog 命令查看. 常用命令 1.查看提交历史 $ git log 2.查看某个文件或者某个目录的递交历史 $ gi ...
- 阿里云主机试用之自建站点和ftp上传所遇的2个问题
1.Access to the requested object is only available from the local network 其实我并没有自建站点,只是使用了XAMPP来建了ap ...
- Python库的安装方法
Python库的安装方法 Python的解释器CPython是开源的,我们可以下载查看其源代码,同时,Python语言的各种库也都是开源的.利用Python语言编程,可用的库有很多,在Python官方 ...
- jQuery生成元素(table)并绑定样式和事件
L略有重复
- 使用 onpropertychange 和 oninput 检测 input、textarea输入改变
检测input.textarea输入改变事件有以下几种: 1.onkeyup/onkeydown 捕获用户键盘输入事件. 缺陷:复制粘贴时无法检测 2.onchenge 缺陷:要满足触发条件:当前对象 ...
- [笔记]ACM笔记 - 排序小技巧
Description 一个数组,要求先对前n个数字排序(以方便后续操作):又要求对前n+i个数字排序:又要求对前n+j - 前n+k个数字排序(i.j.k的大小远小于n,且i.j.k间没有大小关系) ...
- 【持续集成】GIT+jenkins+snoar——GIT
一.GIT基础 1.1 git简介 linux用C语言编写 2005年诞生 分布式管理系统 速度快.适合大规模.跨地区多人协同开发 1.2 本地管理.集中式.分布式 1.3 git安装 #CentOS ...
- React入门---JSX内置表达式-6
个人理解:接触的JSX就是在React中render方法里面的js,因为里面只能有一个节点,所以你写的东西都在一个div中,要有js所以通过JSX来表达.(个人菜鸟理解,欢迎指正) React 使用 ...