Dinic算法详解及实现
预备知识:
残留网络:设有容量网络G(V,E)及其上的网络流f,G关于f的残留网络即为G(V',E'),其中G’的顶点集V'和G的顶点集V相同,即V'=V,对于G中任何一条弧<u,v>,如果f(u,v)<c(u,v),那么在G'中有一条弧<u,v>∈E',其容量为c'(u,v)=c(u,v)-f(u,v),如果f(u,v)>0,则在G'中有一条弧<v,u>∈E',其容量为c’(v,u)=f(u,v).
从残留网络的定义来看,原容量网络中的每条弧在残留网络中都化为一条或者两条弧。在残留网络中,从源点到汇点的任意一条简单路径都对应一条增光路,路径上每条弧容量的最小值即为能够一次增广的最大流量。
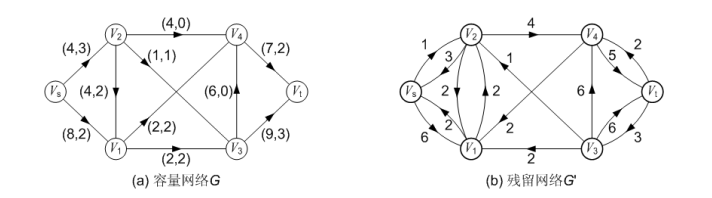
顶点的层次:在残留网络中,把从源点到顶点u的最短路径长度,称为顶点u的层次。源点 Vs的层次为0.例如下图就是一个分层的过程。
注意:
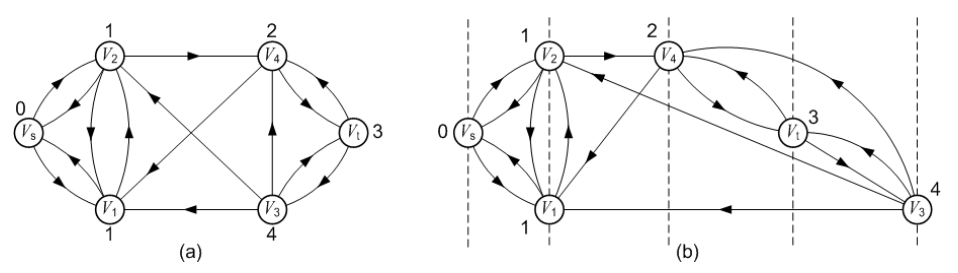
(1)对残留网路进行分层后,弧可能有3种可能的情况。
1、从第i层顶点指向第i+1层顶点。
2、从第i层顶点指向第i层顶点。
3、从第i层顶点指向第j层顶点(j < i)。
(2)不存在从第i层顶点指向第i+k层顶点的弧(k>=2)。
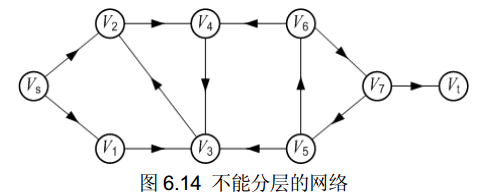
(3)并非所有的网络都能分层。
2、最短路增广路径的算法思想
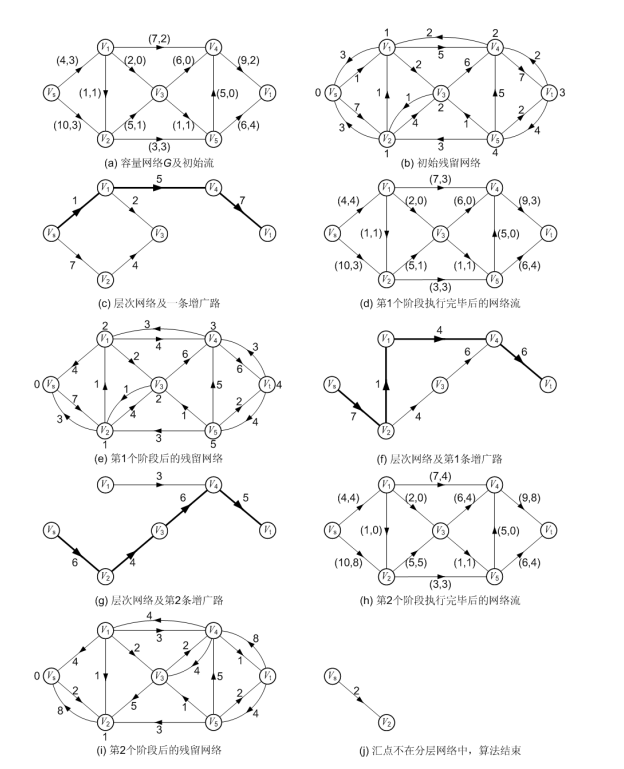
最短增广路的算法思想是:每次在层次网络中找一条含弧数最少的增广路进行增广。最短增广路算法的具体步骤如下:
(1)初始化容量网络和网络流。
(2)构造残留网络和层次网络,若汇点不在层次网络中,则算法结束。
(3)在层次网络中不断用BFS增广,直到层次网络中没有增广路为止;每次增广完毕,在层次网络中要去掉因改进流量而导致饱和的弧。
(4)转步骤(2)。
在最短增广路算法中,第(2)、(3)步被循环执行,将执行(2)、(3)步的一次循环称为一个阶段。在每个阶段中,首先根据残留网络建立层次网络,然后不断用BFS在层次网络中增广,直到出现阻塞流。注意每次增广后,在层次网络中要去掉因改进流量而饱和的弧。该阶段的增广完毕后,进入下一阶段。这样的不断重复,直到汇点不在层次网络中为止。汇点不在层次网络中意味着在残留网络中不存在一条从源点到汇点的路径,即没有增广路。
在程序实现的时候,并不需要真正“构造”层次网络,只需要对每个顶点标记层次,增广的时候,判断边是否满足level(v) = level(u)+1这一约束条件即可。
3、最短增广路算法复杂度分析
最短增广路的复杂度包括建立层次网络和寻找增广路两部分。
在最短增广路中,最多建立n个层次网络,每个层次网络用BFS一次遍历即可得到。一次BFS的复杂度为O(m),所以建层次图的总复杂度为O(n*m)。
每增广一次,层次网络中必定有一条边会被删除。层次网络中最多有m条边,所以认为最多可以增广m次。在最短增广路算法中,用BFS来增广,一次增广的复杂度为O(n+m),其中O(m)为BFS的花费,O(n)为修改流量的花费。所以在每一阶段寻找增广路的复杂度为O(m*(m+n)) = O(m*m)。因此n个阶段寻找增广路的算法总复杂度为O(n*m*m)。
两者之和为O(n*m*m)。
以上介绍最短增广路算法只是为下面介绍Dinic算法而提供给大家一个铺垫,有了以上的基础,接下来我们来介绍Dinic算法,Dinic其实是最短增广路算法的优化版。
连续最短增广路算法----Dinic算法
1、Dinic算法思路
Dinic算法的思想也是分阶段地在层次网络中增广。它与最短增广路算法不同之处是:最短增广路每个阶段执行完一次BFS增广后,要重新启动BFS从源点Vs开始寻找另一条增广路;而在Dinic算法中,只需一次DFS过程就可以实现多次增广,这是Dinic算法的巧妙之处。Dinic算法具体步骤如下:
(1)初始化容量网络和网络流。
(2)构造残留网络和层次网络,若汇点不再层次网络中,则算法结束。
(3)在层次网络中用一次DFS过程进行增广,DFS执行完毕,该阶段的增广也执行完毕。
(4)转步骤(2)。
在Dinic的算法步骤中,只有第(3)步与最短增广路相同。在下面实例中,将会发现DFS过程将会使算法的效率有非常大的提高。
Dinic算法复杂度分析
与最短增广路算法一样,Dinic算法最多被分为n个阶段,每个阶段包括建层次网络和寻找增广路两部分,其中建立层次网络的复杂度仍是O(n*m)。
现在来分析DFS过程的总复杂度。在每一阶段,将DFS分成两部分分析。
(1)修改增广路的流量并后退的花费。在每一阶段,最多增广m次,每次修改流量的费用为O(n)。而一次增广后在增广路中后退的费用也为O(n)。所以在每一阶段中,修改增广路以及后退的复杂度为O(m*n)。
(2)DFS遍历时的前进与后退。在DFS遍历时,如果当前路径的最后一个顶点能够继续扩展,则一定是沿着第i层的顶点指向第i+1层顶点的边向汇点前进了一步。因为增广路经长度最长为n,所以最坏的情况下前进n步就会遇到汇点。在前进的过程中,可能会遇到没有边能够沿着继续前进的情况,这时将路径中的最后一个点在层次图中删除。
注意到每后退一次必定会删除一个顶点,所以后退的次数最多为n次。在每一阶段中,后退的复杂度为O(n)。
假设在最坏的情况下,所有的点最后均被退了回来,一共共后退了n次,这也就意味着,有n次的前进被“无情”地退了回来,这n次前进操作都没有起到“寻找增广路”的作用。除去这n次前进和n次后退,其余的前进都对最后找到增广路做了贡献。增广路最多找到m次。每次最多前进n个点。所以所有前进操作最多为n+m*n次,复杂度为O(n*m)。
于是得到,在每一阶段中,DFS遍历时前进与后退的花费为O(m*n)。
综合以上两点,一次DFS的复杂度为O(n*m)。因此,Dinic算法的总复杂度即O(m*n*n)。

下面的实现,有借鉴别人的方法。主要是利用BFS构建层次网络,这里用level数组来存储每个顶点的层数。
然后利用dfs进行增广,默认M个节点,第M个节点就是汇点。然后当第M个节点不在分层网络时,就结束。
#include <iostream>
#include <queue>
using namespace std; const int INF = 0x7fffffff;
int V, E;
int level[];
int Si, Ei, Ci; struct Dinic
{
int c;
int f;
}edge[][]; bool dinic_bfs() //bfs方法构造层次网络
{
queue<int> q;
memset(level, , sizeof(level));
q.push();
level[] = ;
int u, v;
while (!q.empty()) {
u = q.front();
q.pop();
for (v = ; v <= E; v++) {
if (!level[v] && edge[u][v].c>edge[u][v].f) {
level[v] = level[u] + ;
q.push(v);
}
}
}
return level[E] != ; //question: so it must let the sink node is the Mth?/the way of yj is give the sink node's id
} int dinic_dfs(int u, int cp) { //use dfs to augment the flow
int tmp = cp;
int v, t;
if (u == E)
return cp;
for (v = ; v <= E&&tmp; v++) {
if (level[u] + == level[v]) {
if (edge[u][v].c>edge[u][v].f) {
t = dinic_dfs(v, min(tmp, edge[u][v].c - edge[u][v].f));
edge[u][v].f += t;
edge[v][u].f -= t;
tmp -= t;
}
}
}
return cp - tmp;
}
int dinic() {
int sum=, tf=;
while (dinic_bfs()) {
while (tf = dinic_dfs(, INF))
sum += tf;
}
return sum;
} int main() {
while (scanf("%d%d", &V, &E)) {
memset(edge, , sizeof(edge));
while (V--) {
scanf("%d%d%d", &Si, &Ei, &Ci);
edge[Si][Ei].c += Ci;
}
int ans = dinic();
printf("%d\n", ans);
}
return ;
}
Dinic算法详解及实现的更多相关文章
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- kmp算法详解
转自:http://blog.csdn.net/ddupd/article/details/19899263 KMP算法详解 KMP算法简介: KMP算法是一种高效的字符串匹配算法,关于字符串匹配最简 ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- [转] KMP算法详解
转载自:http://www.matrix67.com/blog/archives/115 KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的K ...
- 【转】AC算法详解
原文转自:http://blog.csdn.net/joylnwang/article/details/6793192 AC算法是Alfred V.Aho(<编译原理>(龙书)的作者),和 ...
- KMP算法详解(转自中学生OI写的。。ORZ!)
KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的KMP不是拿来放电影的(虽然我很喜欢这个软件),而是一种算法.KMP算法是拿来处理字符串匹配的.换句 ...
- EM算法详解
EM算法详解 1 极大似然估计 假设有如图1的X所示的抽取的n个学生某门课程的成绩,又知学生的成绩符合高斯分布f(x|μ,σ2),求学生的成绩最符合哪种高斯分布,即μ和σ2最优值是什么? 图1 学生成 ...
- Tarjan算法详解
Tarjan算法详解 今天偶然发现了这个算法,看了好久,终于明白了一些表层的知识....在这里和大家分享一下... Tarjan算法是一个求解极大强联通子图的算法,相信这些东西大家都在网络上百度过了, ...
- 安全体系(二)——RSA算法详解
本文主要讲述RSA算法使用的基本数学知识.秘钥的计算过程以及加密和解密的过程. 安全体系(零)—— 加解密算法.消息摘要.消息认证技术.数字签名与公钥证书 安全体系(一)—— DES算法详解 1.概述 ...
随机推荐
- Dubbo高级特性实践-泛化调用
引言 当后端Java服务用Dubbo协议作为RPC方案的基础,但部分消费方是前端Restful的PHP服务,不能直接调用,于是在中间架设了Router服务提供统一的基于HTTP的后端调用入口. 而Ro ...
- android源码、博文2
每周精选 第 54 期 精品源码 仿网易新闻app下拉标签选择菜单 仿网易新闻app下拉标签选择菜单,长按拖动排序,点击增删标签控件##示例 https://github.com/we ...
- JavaWeb 后端 <六> 之 EL & JSTL 学习笔记
一.EL表达式(特别重要)
- vue--指令中值得随笔的地方
v-model-- 双向数据绑定 number修饰指令 <!DOCTYPE html> <html lang="en"> <head> < ...
- JavaScript实现淡入淡出
<!DOCTYPE html> <html> <head> <title>css动画</title> </head> <b ...
- 浅谈Notepad++选中行操作+快捷键+使用技巧【超详解】
Notepad++选中行操作 快捷键 使用技巧 用Notepad++写代码,要是有一些重复的代码想copy一下,还真不容易,又得动用鼠标,巨烦人.... 有木有简单的方法呢,确实还是有的不过也不算太好 ...
- SSO(单点登录)与旅游年卡
SSO(单点登录)与旅游年卡 SSO英文全称Single Sign On,单点登录.SSO是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统.它包括可以将这次主要的登录映射到其他应 ...
- nyoj_6:喷水装置(一)
要让总的使用到的装置数尽可能少,则可以贪心每次选取未使用的半径最大的装置 题目链接: http://acm.nyist.net/JudgeOnline/problem.php?pid=6 #inclu ...
- (转)log4j(四)——如何控制不同风格的日志信息的输出?
一:测试环境与log4j(一)——为什么要使用log4j?一样,这里不再重述 1 老规矩,先来个栗子,然后再聊聊感受 import org.apache.log4j.*; //by godtrue p ...
- (转)递归算法的时间复杂度终结篇与Master method
开篇前言:为什么写这篇文章?笔者目前在学习各种各样的算法,在这个过程中,频繁地碰到到递归思想和分治思想,惊讶于这两种的思想的伟大与奇妙的同时,经常要面对的一个问题就是,对于一个给定的递归算法或者用分治 ...