Branch Prediction
Pipeline的优点
现代微处理器的pipeline中包含许多阶段,粗略地可以分成fetch、decode、execution、retirement,细分开来可以分成十多甚至二十多个阶段。在处理器处理指令时,可以像流水线一样同时处理位于不同阶段的指令。
下图,假设一个pipeline分为四个阶段,每个阶段耗费一个时钟周期。
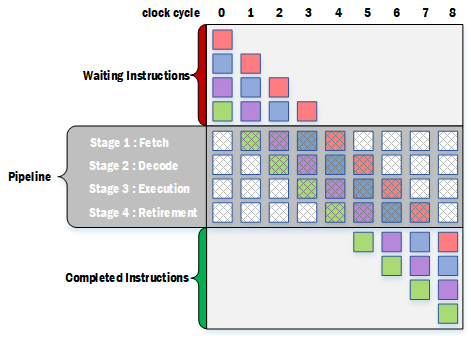
4条指令按照先后顺序进入pipeline,每间隔一个时钟周期,指令就能从pipeline的上一个阶段转移到下一个阶段,在第四个时钟周期时,4条指令全部进入pipeline内,各个阶段都含有一条指令。按照这种策略,最佳的情况就是指令源源不断地进入pipeline,pipeline中就会一直都在同时处理四条指令,那么指令的处理效率就是原来的4倍。
Pipeline在Branch上所面临的问题
由于指令之间存在依赖关系,因此需要采用各种辅助机制来保证指令的流畅执行。我们之前就已经讨论过指令间的源/目标操作数依赖,pipeline中是用in-flight机制来加速指令处理,这里讨论另外一种依赖,就是分支(branch)对比较结果(flag)的依赖。指令中经常会出现跳转指令,特别是条件跳转指令,在得到条件的结果前,我们是不知道接下来会走哪个分支的,因此按照一般的逻辑,应该需要先等待比较结果执行完毕,再根据结构去取相应的分支进入pipeline内处理。不过这会导致指令的执行效率下降,因为在等待比较指令执行完成的过程中,后续的指令无法进入pipeline,也就是执行时间几乎延迟了一整个个pipeline的时钟周期。
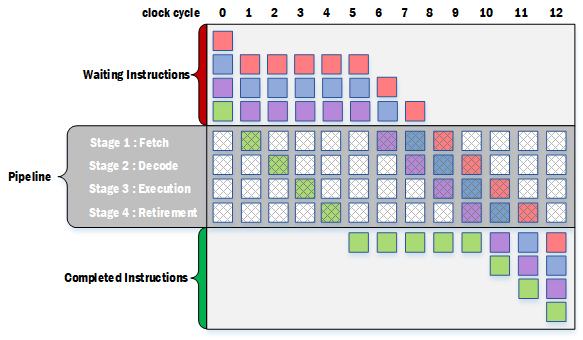
在现代微处理器中,由于pipeline的细分,长度(阶段)达到十多甚至二十多,因此如果不采取相应措施则会导致出现10~20个时钟周期的延迟。
Branch Prediction
为了克服上述问题,pipeline中引入了Branch Prediction机制。Branch Prediction就是通过预测,把接下来最有可能执行的分支获取进入pipeline,就像不存在对比较结果的依赖那样直接执行,这么一来就保持了指令的流畅执行,这也被称为Speculative Execution。不过这种通过预测获取进入pipeline的分支终究只是预测分支,实际上不一定是执行这一分支,因此这部分指令的执行结果不应该从pipeline中输出,即不应该执行retirement这一步骤。在得到比较结果后,就能知道预测的分支是否为实际应该执行的分支,如果是,pipeline中的预测分支指令就能继续执行下去,否则就需要把预测分支的指令排空,重新获取正确分支的指令进入pipeline继续执行。
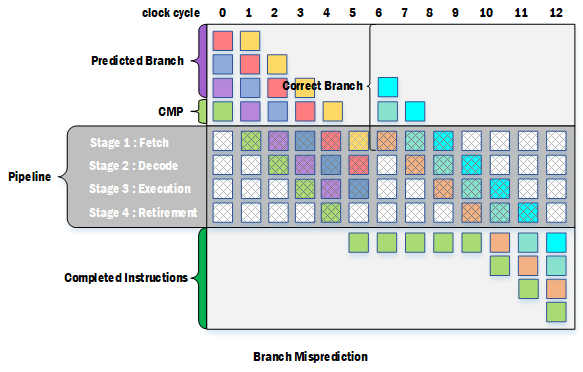
采用Branch Prediction机制后,条件跳转的延迟将取决于预测的成功率。成功率越高,则能保证指令流畅执行,提升指令处理效率;成功率低,则会导致Branch Misprediction经常发生,这需要把预测分支排空,重新获取指令执行,因此会降低指令处理效率。
Branch Predictor
我们把进行分支预测的硬件称为Branch Predictor,也称之为Branch Prediction Unit(BPU)。如前文所述,BPU的主要作用是预测接下来执行的指令分支,也就是说BPU作用于pipeline的前端(front-end)。
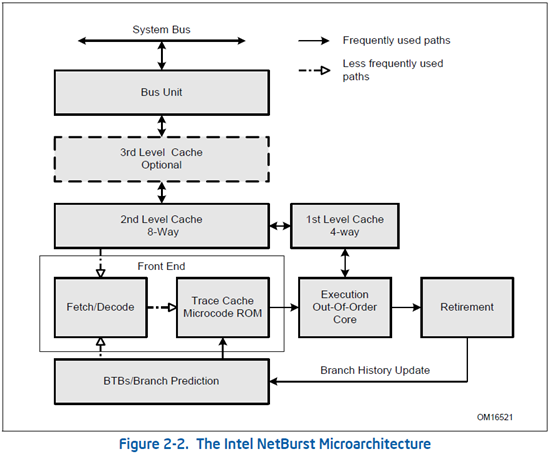
如上图为一个NetBurst(Pentium 4)微处理器的粗略pipeline。如果所预测的分支还没进入pipeline内,则需要从cache中读取,BPU会在Fetch阶段去控制读取所预测的指令分支。所预测的分支也有可能已经在pipeline内,如以前执行过该分支,而该分支的指令在被解码成μops后会存储在Trace Cache,BPU可以通过控制Trace Cache向EU发送预测分支的μops。在确定了实际上所走的分支之后,retirement会向BPU进行反馈,更新BPU中的信息并用于下一次分支预测。
Implementation
Branch Prediction早在1950s末就引入了到了IBM Stretch处理器中,经过几十年的发展,Branch Prediction进化出了多种实现方式。现代的处理器中往往包含其中的多个实现,以应用在不同的指令环境。。
Static Branch Prediction
Static Branch Prediction是最简单的分支预测,因为它不依赖于历史的分支选择。Static Branch Prediction可以细分为三类:
- Early Static Branch Prediction,总是预测接下来的指令不走跳转分支,即执行位于跳转指令前方相邻(比当前指令晚执行)的指令。
- Advanced Static Branch Prediction,如果所跳转的目标地址位于跳转指令的前方(比当前指令晚执行),则不跳转;如果所跳转的目标地址位图跳转指令的后方(比当前指令早执行)则跳转。这种方法可以很有效地应用在循环的跳转中。
- Hints Static Branch Prediction,可以在指令中插入提示,用于指示是否进行跳转。x86架构中只有Pentium 4用过这种预测方式。

目前的Intel处理器会在缺少历史分支信息的时候采用Advanced Static Branch Prediction来进行分支预测,也就是说如果某分支在第一次执行时会采用该预测方式。因此我们在进行编码是需要进行注意,以便优化代码的执行效率。
//Forward condition branches not taken (fall through)
IF<condition> {....
↓
} //Backward conditional branches are taken
LOOP {...
↑ −− }<condition> //Unconditional branches taken
JMP
------→
碰到IF条件语句时会预测走不命中分支,碰到循环(while在循环首部除外)时默认进入循环,碰到无条件跳转则必然走跳转分支了。
One-level Branch Prediction/Saturating Counter
Saturating Counter可以当作一个状态机,这类型的Branch Prediction就是记录该分支的状态,并根据这个状态来预测走哪一条分支。
1-bit saturating counter记录的就是分支上一次的走向,并预测这次的分支会走同一方向。
2-bit saturating counter有如下状态转换:
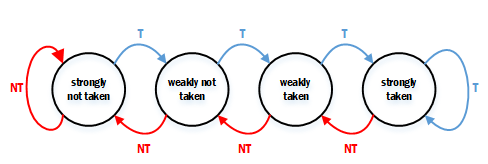
即分支有四种状态:strongly not taken、weakly not taken、weakly taken、strongly taken。其中not taken的状态会预测走非跳转分支,而taken状态会预测走跳转分支,并且会根据实际分支为跳转(T)或者非跳转(NT)进行状态的调整。
Two-level adaptive predictor with local history tables
上述的One-level Branch Prediction有个缺陷,以2-bit为例,假设目前某个分钟的状态为strongly taken,然后该分支的实际走向为0011-0011-0011(0表示NT,1表示T),但是预测的走向为1100-1100-1100,也就是说该2-bit预测的准确率将为0%。为了改善这个问题,引入了Two-level adaptive predictor with local history tables。
Two-level adaptive predictor如其名字所述,分为两级:Branch history以及Pattern history table。
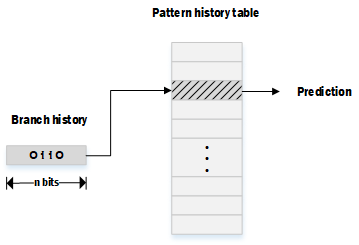
Branch history的长度为n bit,用于记录某个branch上n次的分支走向。
Pattern history table共有2n个项,每个项记录一个Suturating Counter的状态。
某个分支在进行分支预测时,会根据该分支上n次历史分支走向来选择对应的Pattern history table entry,然后依据其中的状态来进行预测。在得出实际的分支走向后,也会按照该路线去修改对应table entry中的状态,然后更新Branch history。
回到上面的例子,如果Branch history的n=2,那么Pattern history table会有四项:00、01、10、11。而0011-0011-0011这种分支选择方式有规律:00后为1、01后为1、11后为0、10后为0。因此在经过三个周期的分支选择后,Pattern history table存储的状态就能完美预测该分支的下一次走向,也就是说这种n=2的Two-level adaptive predictor就能完美解决上面提出的问题。
不过如果实际的分支走向为0001-0001-0001,那么n=2就显得不够了,因为00后可能为0或者1。此时就需要n=3,有000后为1、001后为0、010后为0、100后为0,此时table中的011、101、110、111项为空闲项。
实际上我们可以总结出以下规律:如果某分支的实际走向有固定的周期规律,周期内部有p项,并且该p项内的任意连续n项没有重复(并且满足n+1<p<=2n),则n bit的Two-level adaptive predictor就能完美得预测这类型的分支。
Two-level adaptive predictor with global history table
上一小节描述的是local history table,即branch history中存储的是单个branch的历史走向,而global history table中存储的是位于当前branch后方(比当前指令早执行)的n个branches的走向。在local history table实现中,需要为每一个branch维护独立的Branch history以及Pattern history table,这导致需要大容量的Branch Target Buffer(BTB)来存储这些数据,不过实际上BTB的容量是有限的。而在global history table中,仅保留一个Branch history以及Pattern history table,能很大程度地节约BTB空间。
不过这种实现的缺点也很明显,由于只有一个Branch history,也就是说每个分支都是以这个Branch history为基础来选择Pattern history table,不过不同的分支也有可能出现相同的Branch history值,这就很难保证一个独立的分支对应一个独立Pattern history table entry,也就是说需要较长的Branch history(较大的n,很多现代的微处理器为n=16),以降低不同分支间由于定位到了相同entry带来的交叉影响。而且也不是每次执行到某个分支时它的Branch history都一样,Branch history也会改变,这就使得无法定位到所需的entry。另外,由于采用的是不久前执行过的历史分支来预测当前分支,也就是认为相邻分支间具有相关性,不过实际上也不一定如此。所以说global history table预测的准确程度是不如local history table的。
Agree Predictor
上面在讨论global history table时说到不同分支可能会由于有同一Branch history而定位到同一Pattern history entry,导致不同分支间交叉影响,Agree Predictor为这种情形提供了解决方法。
Agree Predictor采用了global以及local混合的方法。global仍然是采用较长的Branch history以及2-bit Saturating Counter,预测的是某一分支是否与其上次走向相同;local则只用1bit为每个Branch存储其上一次的分支走向。global的输出与local的输出进行异或则能得到分支预测。
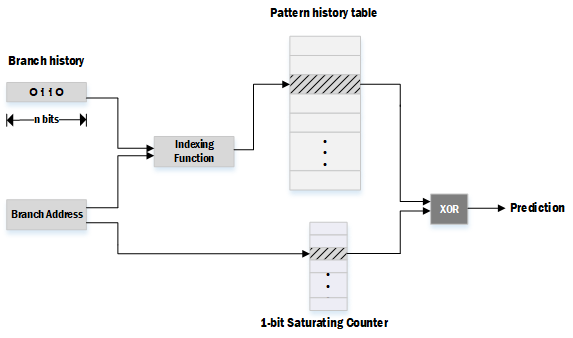
上图中加入了Branch Address用于定位分支,Branch Address也能用于与Branch history经过某种方式的混合(Indexing function)使得定位的Pattern history table entry更准确。
Loop Predictor
一个周期为n的循环在进行分支选择的时候,会走n-1次跳转/不跳转以及1次不跳转/跳转,假设n=6,则会形成如111110-111110的形式。因此循环的分支预测算是一种比较容易预测的分支,不过如果循环判断的次数n非常大,并且体内部有多个分支,那么在Branch history长度有限的情况下,单靠前面所述的global/Agree的预测方式会很难达到较好的预测效果,所以需要一个独立的Loop Predictor来对循环分支进行预测。
Loop Predictor在第一次对循环分支进行预测时能记录下该分支的循环周期为n,那么在下一次碰到该循环分支的时候就会预测走n-1次taken/not taken然后走一次not taken/taken。BTB中则需要记录某个Branch的跳转目标地址、Branch是否为循环、循环的周期n以及循环在退出的时候是taken还是not taken。
Indirect Branch Predictor
我们前面所讨论的分支都是以二叉分支为基础展开讨论,不过分支不总是二叉的。switch以及多态的虚函数在编译时可能(编译器相关)会被编译成 jmp eax/call eax 这类需要通过计算才能得到目标地址的跳转,这种分支就不是二叉的,而是会有多个候选的目标地址,这就是所谓的Indirect Branch。而前面所述的Branch history是1个bit代表一个分支,这种predictor在碰Indirect Branch的时候只能固定地指定一个跳转地址,因此是不够合适的。
在Indirect Branch Predictor中,Branch history用多个bit代表一个分支,如此一来则能很好地适配Indirect Branch。
Prediction of function returns
在函数返回时,会用到 ret/leave 等指令进行跳转,这些指令是需要从栈中读取跳回地址后再进行跳转的,因此也算是一种比较另类Indirect Branch。不过由于这种返回指令总是与 call/enter 成对出现,因此一种较好的处理方法就是在每次进入函数的时候都去读取其返回地址入栈(这里的栈不是程序的栈,而是Predictor维护的,专门用于返回跳转),在碰到返回指令时从栈内取出目标地址直接用于Branch Prediction。这就是所谓的return stack buffer机制。
由于这种预测机制用到了stack,也就是说需要 call/enter 跟 ret/leave 成对出现,因此为了保证指令的执行效率,尽量不要用 jmp 来代替函数的跳入跳出指令。
Hybrid Predictor
Hybrid Predictor就是采用多种predictor混合预测,然后从中选择出对当前branch来说较优的Predictor,以其输出结果进行分支预测。
Neural branch predictor
采用机器学习来进行分支预测,好处是相比其他predictor预测更为准确,不过相应地需要消耗更多的时间,延迟较大,不过这是早期的说法了。目前AMD Ryzen最新的处理器就是基于神经网络来进行分支预测。
Reference:
Agner Fog : The microarchitecture of Intel, AMD and VIA CPUs
Intel® 64 and IA-32 Architectures Optimization Reference Manual
Intel 64 and IA-32 Architectures Software Developer's Manual
Branch Prediction的更多相关文章
- 分支预测(branch prediction)
记录一个在StackOverflow上看到一个十分有趣的问题:问题. 高票答案的优化方法: 首先找到罪魁祸首: if (data[c] >= 128) sum += data[c]; 优化方案使 ...
- 计算机系统结构总结_Branch prediction
Textbook:<计算机组成与设计——硬件/软件接口> HI<计算机体系结构——量化研究方法> QR Branch Prediction 对于下面的指令: ...
- 跟Unity3D学代码优化
今天我们来聊聊如何跟Unity学代码优化,准确地说,是通过学习Unity的IL2CPP技术的优化策略,应用到我们的日常逻辑开发中. 做过Unity开发的同学想必对IL2CPP都很清楚,简单地说,IL2 ...
- gcc/linux内核中likely、unlikely和__attribute__(section(""))属性
查看linux内核源码,你会发现有很多if (likely(""))...及if (unlikely(""))...语句,这些语句其实是编译器的一种优化方式,具 ...
- (转)CPU Cache与内存对齐
转自:http://blog.csdn.net/zhang_shuai_2011/article/details/38119657 原文如下: 一. CacheCache一般来说,需要关心以下几个方面 ...
- sandy bridge
SANDY BRIDGE SPANS GENERATIONS Intel Focuses on Graphics, Multimedia in New Processor Design By Li ...
- JVM参数(一)JVM类型以及编译器模式
现在的JVM运行Java程序(和其它的兼容性语言)时在高效性和稳定性方面做的非常出色.自适应内存管理.垃圾收集.及时编译.动态类加载.锁优化——这里仅仅列举了某些场景下会发生的神奇的事情,但他们几乎不 ...
- Why is processing a sorted array faster than an unsorted array?
这是我在逛 Stack Overflow 时遇见的一个高分问题:Why is processing a sorted array faster than an unsorted array?,我觉得这 ...
- [ZZ] Cache
http://blog.sina.com.cn/s/blog_6472c4cc0102duzr.html 处理器微架构访问Cache的方法与访问主存储器有类似之处.主存储器使用地址编码方式,微架构可以 ...
随机推荐
- 【个人笔记】《知了堂》MySQL三种关系:一对一,一对多,多对多。
一对一:比如一个学生对应一个身份证号.学生档案: 一对多:一个班可以有很多学生,但是一个学生只能在一个班: 多对多:一个班可以有很多学生,学生也可以有很多课程: 一对多关系处理: 我们以学生和班级之间 ...
- 【Python练习1】统计一串字符中英文字母、空格、数字和其他字符的个数
练习思路: 1.输入一串字符 2.筛选出字符中的英文字母并统计 3.筛选出字符中的空格并统计 4.筛选出字符中的数字并统计 5.筛选出字符中的其他字符并统计 代码实现: def msg(s): abc ...
- appium启动运行log分析
1.手动启动appium 服务 > Launching Appium server with command: C:\Program Files (x86)\Appium\node.exe ...
- vue-chat项目之重构与体验优化
前言 vue-chat 也就是我的几个月之前写的一个基于vue的实时聊天项目,到目前为止已经快满400star了,注册量也已经超过了1700+,消息量达2000+,由于一直在实习,没有时间对它频繁地更 ...
- 【bzoj2761】[JLOI2011]不重复数字
给出N个数,要求把其中重复的去掉,只保留第一次出现的数. 例如,给出的数为1 2 18 3 3 19 2 3 6 5 4,其中2和3有重复,去除后的结果为1 2 18 3 19 6 5 4. Inpu ...
- bzoj4198 荷马史诗 哈夫曼编码
逐影子的人,自己就是影子. --荷马 Allison 最近迷上了文学.她喜欢在一个慵懒的午后,细细地品上一杯卡布奇诺,静静地阅读她爱不释手的<荷马史诗>.但是由<奥德赛>和&l ...
- eclipse安装lombok插件问题解决
在 java平台上,lombok 提供了简单的注解的形式来帮助我们消除一些必须有但看起来很臃肿的代码, 比如属性的get/set,及对象的toString等方法,特别是相对于 POJO.简单的说,就是 ...
- Fiddler屏蔽某些url的抓取方法
在用Fiddler调试网页的时候,可能某些频繁的ajax轮询请求会干扰我们,可以通过以下方法屏蔽某些url的抓取. 在需要屏蔽的url行上右键---->“Filter Now”-----> ...
- JFrame的层次结构以及背景颜色设置问题
JFrame的层次结构: JFrame:窗体,也就是窗口的框架.默认为不可见.不透明的(可以使用isVisible和isOpaque来验证).创建窗口时,最后一步需要调用setVisible(true ...
- Python实战之Selenium自动化测试web刷新FW
需求:将手工登录,手工刷新服务器的FW转化为Python+Selenium实现自动化操作. 1.创建用户表,实现数据与脚本分离.需要读取模块. 2.自动化刷新FW. 不说话,直接上代码: 1userd ...