爬虫模块BeautifulSoup
中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#
1.1 安装BeautifulSoup模块和解析器
1) 安装BeautifulSoup
pip install beautifulsoup4
2) 安装解析器
pip install lxml
pip install html5lib
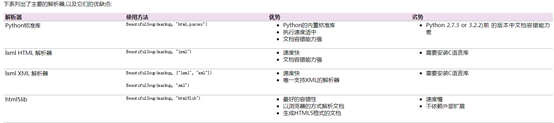
1.2 对象种类
- Tag : 标签对象,如:<p class="title"><b>yoyoketang</b></p>,这就是一个标签
- NavigableString :字符对象,如:这里是我的微信公众号:yoyoketang
- BeautifulSoup :就是整个html对象
- Comment :注释对象,如:!-- for HTML5 --,它其实就是一个特殊NavigableString
1.3 常用方法
# coding:utf-8
__author__ = 'Helen'
'''
description:爬虫模块BeautifulSoup学习
'''
import requests
from bs4 import BeautifulSoup r = requests.get("https://www.baidu.com/")
soup = BeautifulSoup(r.content,'html5lib')
print soup.a # 根据tab名输出,只输出第一个
print soup.find('a') # 同上
print soup.find_all('a') # 输出所有a元素
# 找出对应的tag,再根据元素属性找内容
print soup.find_all('a',{'href':'https://www.hao123.com','name':'tj_trhao123'})
# .contents(tag对象contents可以获取所有的子节点,返回的是list,获取该元素的直接子节点)
print soup.find('a').contents[0] # 输出第一个节点
print soup.find('div',id='u1').contents[1] # 输出第二个节点
# .children(点children这个生成的是list对象,跟上面的点contents功能一样,但是不能通过下标读,只能for循环读)
for i in soup.find('div',id='u1').children:
print i
# .descendants(获取所有的子孙节点)
for i in soup.find(class_='head_wrapper').descendants:
print i
爬虫模块BeautifulSoup的更多相关文章
- python-网络安全编程第五天(爬虫模块BeautifulSoup)
前言 昨晚学的有点晚 睡得很晚了,今天早上10点多起来吃完饭看了会电视剧就瞌睡了一直睡到12.50多起来洗漱给我弟去开家长会 开到快4点多才回家.耽搁了不少学习时间,现在就把今天所学的内容总结下吧. ...
- Python 爬虫三 beautifulsoup模块
beautifulsoup模块 BeautifulSoup模块 BeautifulSoup是一个模块,该模块用于接收一个HTML或XML字符串,然后将其进行格式化,之后遍可以使用他提供的方法进行快速查 ...
- 爬虫模块介绍--request(发送请求模块)
爬虫:可见即可爬 # 每个网站都有爬虫协议 基础爬虫需要使用到的三个模块 requests 模块 # 模拟发请求的模块 PS:python原来有两个模块urllib和urllib的升级urlli ...
- Python爬虫之BeautifulSoup的用法
之前看静觅博客,关于BeautifulSoup的用法不太熟练,所以趁机在网上搜索相关的视频,其中一个讲的还是挺清楚的:python爬虫小白入门之BeautifulSoup库,有空做了一下笔记: 一.爬 ...
- python爬虫---单线程+多任务的异步协程,selenium爬虫模块的使用
python爬虫---单线程+多任务的异步协程,selenium爬虫模块的使用 一丶单线程+多任务的异步协程 特殊函数 # 如果一个函数的定义被async修饰后,则该函数就是一个特殊的函数 async ...
- 使用Python爬虫库BeautifulSoup遍历文档树并对标签进行操作详解(新手必学)
为大家介绍下Python爬虫库BeautifulSoup遍历文档树并对标签进行操作的详细方法与函数下面就是使用Python爬虫库BeautifulSoup对文档树进行遍历并对标签进行操作的实例,都是最 ...
- Python网络爬虫之BeautifulSoup模块
一.介绍: Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮 ...
- 爬虫利器BeautifulSoup模块使用
一.简介 BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式,同时应用场景也是非常丰富,你可以使用 ...
- 爬虫模块介绍--Beautifulsoup (解析库模块,正则)
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时 ...
随机推荐
- mycat操作MySQL第一篇:全局表
1.安装mycat,点击bin下面startup_nowrap.bat启动 2.客户端连接mycat:server.xml里面的 <!--连接mycat用户名和密码.数据库--> < ...
- 4.2 js没有块级作用域
JavaScript没有块级作用域.在其他语言上,比如C语言中,有花括号封闭的代码块都有自己的作用域,(如果用ECMAScript的话来讲,就是他们自己的执行环境),因而支持根据条件来定义变量.例如, ...
- 大三小学期 Android开发的一些经验
1.同一个TextView几种颜色的设置: build=(TextView)findViewById(R.id.building); SpannableStringBuilder style = ne ...
- JAVA面向对象思想
1.面向对象的基本特征 面向对象具有三个基本特征:封装.多态.继承. 1)封装 封装指的是将对象的实现细节隐藏起来,然后通过一些公用方法来暴露该对象的功能. ...
- mysql 数据库基本命令语句
mysql mariadb 客户端连接 mysql -uroot -p; 客户端退出exit 或 \q 显示所有数据库show databases;show schemas; 创建数据库create ...
- Win7硬盘的AHCI模式
1.什么是硬盘的AHCI模式? AHCI是串行ATA高级主控接口的英文缩写,它是Intel所主导的一项技术,它允许存储驱动程序启用高级SATA功能,如本机命令队列(NCQ)和热插拔.开启AHCI之后可 ...
- 1-1 struts2 基本配置 struts.xml配置文件详解
详见http://www.cnblogs.com/dooor/p/5323716.html 一. struts2工作原理(网友总结,千遍一律) 1 客户端初始化一个指向Servlet容器(例如Tomc ...
- Mac下使用终端连接远程使用ssh协议的git服务器
最近换了台新电脑, MacBook pro,拿到新电脑之后小小心喜了一下(终于解脱windows的束缚拥抱mac啦), 然后就开始苦逼的安装各种开发环境了. 之前在windows上使用tortoise ...
- Gradle-----搭建简单的Gradle项目
GroupId 项目所在组信息 ArtifactId 项目名称 Version 项目的版本信息
- 笔记:MyBatis XML配置-typeHandlers 默认类型处理器
类型处理器 Java 类型 JDBC 类型 BooleanTypeHandler java.lang.Boolean, boolean 数据库兼容的 BOOLEAN ByteTypeHandler j ...