ansj原子切分和全切分
ansj第一步会进行原子切分和全切分,并且是在同时进行的。
所谓原子,是指短句中不可分割的最小语素单位。例如,一个汉字就是一个原子。
全切分,就是把一句话中的所有词都找出来,只要是字典中有的就找出来。例如,“提高中国人生活水平”包含的词有:提高、高中、中国、国人、人生、生活、活水、水平。
接着以“提高中国人生活水平”为例,调用ansj标准分词:
String str = "提高中国人生活水平" ;
Result result = ToAnalysis.parse(str);
System.out.println(result.getTerms());
Analysis类的analysisStr(String temp)会对几句话进行分词。先不考虑用户自定义词典,直接看这两几代码:
if (startOffe < gp.chars.length ) {
analysis(gp, startOffe, gp.chars.length);
}
经过这里的analysis处理后,就完成了原子切分和全切分,如下图所示:
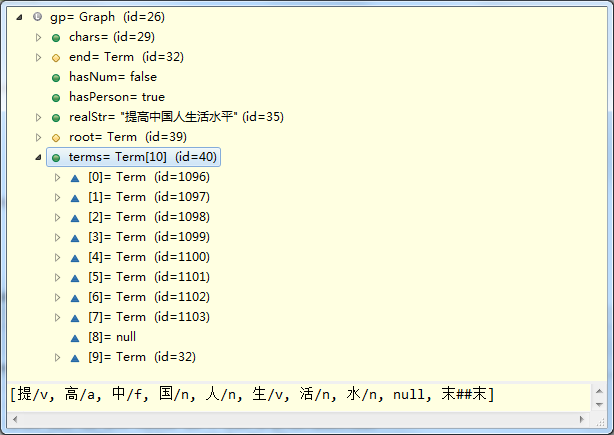
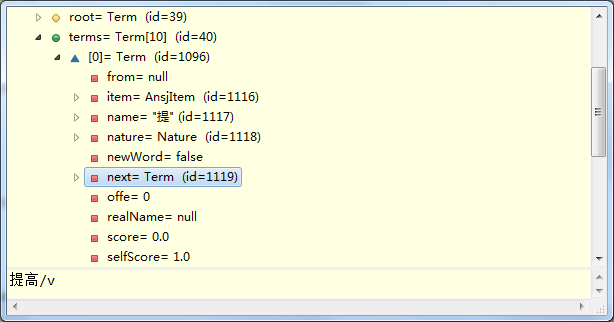
其中,terms[0]是“提”,terms[0].next是“提高”。由于“提高中”不再是个词,所以terms[0].next.next是null。
类似的,terms[1]是“高”,terms[1].next是“高中”,terms[1].next.next是null。
至于terms[9]为什么是null,这是因为“水平”是个词,但可以继续,比如“水平面”、“水平线”;而且,“平”也可以继续,比如“评价”、“平凡”。如果把例句换成“提高中国人民生活水平啊”,就不会出现null。这里先不做深入讨论。
看着一行行代码,挺多挺复杂的。真正debug一遍,发现很多代码都执行不到。看来有大量的代码,是用来处理少数特殊情况的。
涉及到的几个类及基本介绍(只看与本节内容相关的属性和方法,不然太多了):
1、Analysis
基本分词+人名识别的一个抽象类。
(1)、analysis(Graph gp, int startOffe, int endOffe)
该方法用于对一句话进行分词。
对于switch语句switch (status(chars[i])),
case 4:英文字母
case 5:阿拉伯数字或者小数点
以上两种情况,处理逻辑都比较简单,重头戏是default。
在default中,start是本轮分词的起始位置,end是本轮分词的终止位置。start和end之间只能是汉子或者标点符号。先下面这几行核心代码:
gwi.setChars(chars, start, end);
while ((str = gwi.allWords()) != null) {
Term term = new Term(str, gwi.offe, gwi.getItem());
gp.addTerm(term);
}
这几行代码就实现了将一句汉语,一个一个地分词。每分出一个词,就实例化一个Term,并加入到图(也就是变量gp)中。实例化Term的参数,str是该词的汉字表示;gwi.offe是该词在句子中起始位置的偏移量(这个参数很重要,保证了新的Term可以被插入正确的位置。);gwi.getItem()是该词在字典中的一些信息。
ansj的早期版本,只有上面这几行代码。目前的版本(5.1.2)多了下面这几行代码:
int len = term.getOffe() - max;
if (len > 0) {
for (; max < term.getOffe();) {
gp.addTerm(new Term(String.valueOf(chars[max]), max, TermNatures.NULL));
max++;
}
}
这是为了强行将不能为词的单字,插入到terms。
我们可以把上面几行代码注释,然后以“深圳市碧荔花园”为例进行切分,analysis处理后结果如下:
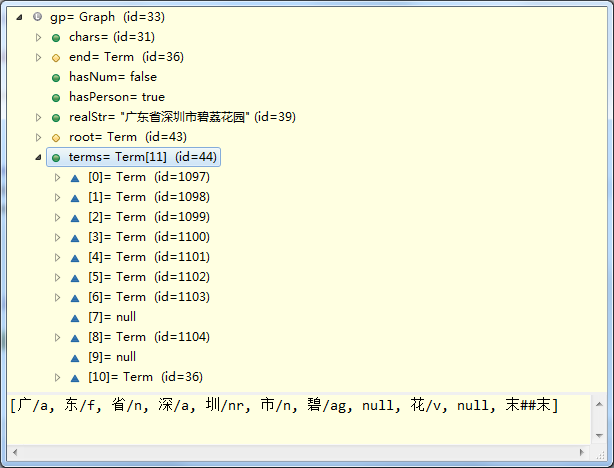
注意上图中,terms[7]是null。正常情况下,terms[7]应该是荔。荔在核心字典中的信息如下:
33620 荔 122986 -1 1 null
state是1,也就是说,“荔”不能单字为词(比如可以组成“荔枝”这个词)。但是“碧荔花园”是个小区名,“荔”不能为词,“荔花”根本就不是个词。这会导致while ((str = gwi.allWords()) != null)这里获取分出的词时,直接跳过“荔”。
上面列出的那几行代码,就是为了解决这种歌特殊情况,解决terms[7]是null的问题。
而在后面这段代码:
int len = end - max;
if (len > 0) {
for (; max < end;) {
gp.addTerm(new Term(String.valueOf(chars[max]), max, TermNatures.NULL));
max++;
}
}
解决的是“荔”这种不能为词的单字,位于句尾的情况。例如“深圳市碧荔花园荔荔荔荔荔”这句话。
这印证了我上面说过的那句话吧,有大量的代码,是用来处理少数特殊情况的。
2、GetWordsImpl
该类用于从核心字典(core.dic)中获取词语。
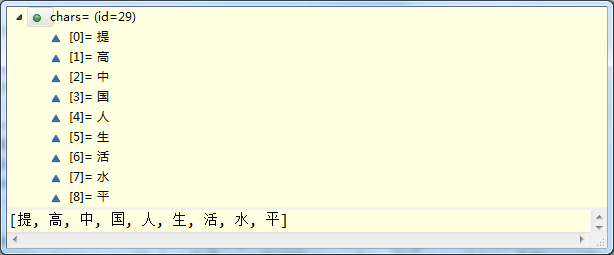
(1)、chars
该属性是一个char型数组,存储了待分词的句子,如下所示:
(2)、offe
该属性表示当前词起始位置的偏移量,是public类型的,可用于外部访问。
例如“深圳市人民政府。”这句话,“深”、“深圳”、“深圳市”三个词的offe都是0。
与offe对于的,还有可以private类型的start,也是当前词起始位置的偏移量。当一个词语结束时,start会比offe多1。
(3)、getStatement()
实现了对双数组前缀树的查询。查询某字或词在核心字典(core.dic)中的状态。
0代表这个字不在词典中。
1代表这还不是个词,需要继续。例如:102029 如日中 79205 140442 1 null
2表示这是个词,但是还可以继续。例如:96274 囫囵 74746 22251 2 {d=0}
3表示这已经是个词了,后面不能继续了。例如:102819 姗姗来迟 65536 102815 3 {i=2}
其中,标点符号的状态也是3。
(4)、allWords()
根据待分词的句子(也就是上面提到的chars属性),一个一个地返回分出的词语。
for (; i < charsLength; i++)这个for循环的i是这个类的属性,并不是一个临时变量,从而实现一个一个地返回分出的词语。
注意这个switch语句:switch (getStatement())
case 0:表示字典中没有这个词。这有两种情况:
1、这是个单字,直接返回这个单子即可,从下一个位置为起点继续分词。
2、这不是个单子,例如“人生活”这个词,在字典中是没有的。这时什么也不返回,从下一个位置为起点去分词。
至于遇到“如日中”这种词,getStatement()返回的是1,switch语句不对这种情况做任何处理,需要接着向后查找。
3、Graph
该类实现了一个图(大学时没好好学图论,没想到应用在这里的)。后面学习最短路径的构建过程时,再来详细讨论这里吧。
ansj原子切分和全切分的更多相关文章
- 基于MyBatis的数据库切分框架,可实现数据的水平切分和垂直切分。 http://www.makersoft.org
https://github.com/makersoft/mybatis-shards MyBatis-Shards 专业的MyBatis数据库切分框架 MyBatis Shards简介 MyBati ...
- ansj构造最短路径
一.前言 上节介绍了ansj的原子切分和全切分.切分完成之后,就要构建最短路径,得到分词结果. 以"商品和服务"为例,调用ansj的标准分词: String str = " ...
- ansj分词原理
ansj第一步会进行原子切分和全切分,并且是在同时进行的.所谓原子,是指短句中不可分割的最小语素单位.例如,一个汉字就是一个原子.全切分,就是把一句话中的所有词都找出来,只要是字典中有的就找出来.例如 ...
- 【NLP】中文分词:原理及分词算法
一.中文分词 词是最小的能够独立活动的有意义的语言成分,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,因此,中文词语分析是中文信息处理的基础与关键. ...
- 数据库Sharding的基本思想和切分策略
一.基本思想 Sharding的基本思想就要把一个数据库切分成多个部分放到不同的数据库(server)上,从而缓解单一数据库的性能问题.不太严格的讲,对于海量数据的数据库,如果是因为表多而数据多,这时 ...
- 转关于垂直切分Vertical Sharding的粒度
垂直切分的粒度指的是在做垂直切分时允许几级的关联表放在一个shard里.这个问题对应用程序和sharding实现有着很大的影响. 关联打断地越多,则受影响的join操作越多,应用程序为此做出的妥协就越 ...
- 转数据库Sharding的基本思想和切分策略
本文着重介绍sharding的基本思想和理论上的切分策略,关于更加细致的实施策略和参考事例请参考我的另一篇博文:数据库分库分表(sharding)系列(一) 拆分实施策略和示例演示 一.基本思想 Sh ...
- Amoeba For MySQL入门:实现数据库水平切分
当系统数据量发展到一定程度后,往往需要进行数据库的垂直切分和水平切分,以实现负载均衡和性能提升,而数据切分后随之会带来多数据源整合等等问题.如果仅仅从应用程序的角度去解决这类问题,无疑会加重应用程度的 ...
- mycat分布式mysql中间件(数据库切分概述)[转]
mysql数据库切分 前言 通 过MySQLReplication功能所实现的扩展总是会受到数据库大小的限制,一旦数据库过于庞大,尤其是当写入过于频繁,很难由一台主机支撑的时 候,我们还是会面临到扩展 ...
随机推荐
- java 编程性能调优
一.避免在循环条件中使用复杂表达式 在不做编译优化的情况下,在循环中,循环条件会被反复计算,如果不使用复杂表达式,而使循环条件值不变的话,程序将会运行的更快. 例子: import java.util ...
- OpenCV矩阵运算
矩阵处理 1.矩阵的内存分配与释放 (1) 总体上: OpenCV 使用C语言来进行矩阵操作.不过实际上有很多C++语言的替代方案可以更高效地完成. 在OpenCV中向量被当做是有一个维数为1的N维矩 ...
- Android NFC技术(三)——初次开发Android NFC你须知道NdefMessage和NdefRecord
Android NFC技术(三)--初次开发Android NFC你须知道NdefMessage和NdefRecord 这最近也是有好多天没写博客了,除了到处张罗着搬家之外,依旧还是许许多多的琐事阻碍 ...
- 苹果新的编程语言 Swift 语言进阶(十)--类的继承
一.类的继承 类能够从其它类继承方法.属性以及其它特性,当一个类从另外的类继承时,继承的类称为子类,它继承的类称为超类.在Swift中,继承是类区别与其它类型(结构.枚举)的基础行为. 1.1 .类的 ...
- ruby TkPackage can't find package BWidget 之解决办法
一个特别短的ruby/tk代码: require 'tkextlib\iwidgets' require 'tkextlib\bwidget' x = 0 101.times {|i| x+=i} T ...
- Mac 下安装安卓 apk 文件
Mac 下安装安卓 apk 文件 在windows上有比较多的第三方软件可以使用,双击就可以将apk文件安装到手机上. 在Mac 上要实现这样还是挺难得,目前还没有像Windows那样的第三方软件可以 ...
- Loader转换器
一.简介 webpack本身只能处理js模块,Loader可以理解为模块和资源的转换器,它本身是一个函数,接受文件作为参数,返回转换的结果.因此,我们就能通过require来加载任何类型的模块和文件. ...
- andorid下从相册选取/拍照选取一张相片并剪切
http://www.2cto.com/kf/201401/270144.html 在Android编程中,从相册选取或是拍照选取一张照片然后对其进行剪切的需求非常的多 之前的一篇文章只说到如何从相册 ...
- 绕过校园网WEB认证_iodine实现
这篇文章是对我的上一篇文章"绕过校园网WEB认证_dns2tcp实现"的补充,在那篇文章中,我讲述了绕过校园网WEB认证的原理,并介绍了如何在windows系统下绕过校园网WEB认 ...
- 建站记录:设置apache .htaccess文件给网站添加404错误处理页面
有些空间服务商会在后台设置中,提供这个选项,可以直观地设置404错误指向的页面,这一点很方便,比如我之前用的阿里云虚拟主机就可以在控制台直接设置. 新租用的香港主机后台没有找到选取文件的地方,只是可以 ...