1.4 正则化 regularization
如果你怀疑神经网络过度拟合的数据,即存在高方差的问题,那么最先想到的方法可能是正则化,另一个解决高方差的方法就是准备更多数据,但是你可能无法时时准备足够多的训练数据,或者获取更多数据的代价很高。但正则化通常有助于避免过拟合或者减少网络误差,下面介绍正则化的作用原理。
我们用逻辑回归来实现这些设想。
逻辑回归的损失函数为
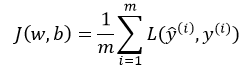
然后求损失函数J的最小值

其中, 分别表示预测值与真实值,w,b是逻辑回归的两个参数,
分别表示预测值与真实值,w,b是逻辑回归的两个参数,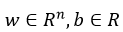 。
。
在逻辑回归中加入正则化,只需要添加参数λ,也就是正则化参数,式子如下:
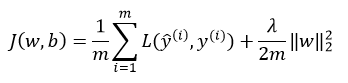
其中,向量参数w的欧几里得(L2)范数平方为:
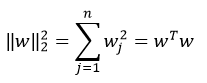
以上方法称为L2正则化。
为什么只有正则化参数w,而不加上参数b呢?其实,也可以加上,但是一般情况下可以省略不写,因为w通常是一个高维的参数矢量,已经可以表达高偏差问题,w可能含有很多参数,我们不可能拟合所以参数,而b只是单个数字,所以w几乎涵盖所有参数,而不是b。如果加了参数b,其实也没什么太大影响,因为b只是众多参数中的一个。
L2正则化是最常见的正则化类型,你们可能听说过L1正则化,L1正则项如下:

如果用的是L1正则化,w最终会是稀疏的,也就是说w向量中有很多0,有人时这样有利于压缩模型,因为集合中参数均为0,存储该模型所占的内存更少。实际上,虽然L1正则化使得模型变得稀疏,却没有降低太多存储内存,所以Angrew NG认为这并不是L1正则化的目的,至少不是为了压缩模型。人们在训练神经网络时,越来越倾向于使用L2正则化。
最后一个细节,λ是正则化参数,我们通常使用验证集或者交叉验证来配置这个参数,尝试寻找各种各样的数据,寻找最好的参数,我们要考虑训练集之间的权衡,把参数正常值设置为较小值,这样可以避免过拟合。因此λ是另外一个需要调整的超参数。顺便说一下,为了方便编写代码,在Python中,lambda是一个保留关键字。
以上就是在逻辑回归函数中实现L2正则化的过程。
-----------------------------------------------------------------
如何在神经网络中实现呢?
神经网络中损失函数如下:
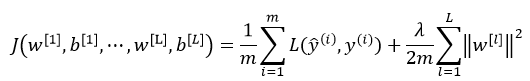
其中,L表示神经网络的层数,w是一个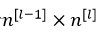 的多维矩阵,
的多维矩阵,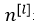 表示第l层神经元个数。
表示第l层神经元个数。
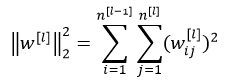
该矩阵范数被称为“弗罗贝尼乌斯范数(Frobenius norm)”,(矩阵中不称为L2范数),表示一个矩阵中所有元素的平方和。
如何使用该范数实现梯度下降呢?
用backprop计算出dw,backprop会给出j对w的偏导数,方法如下图:
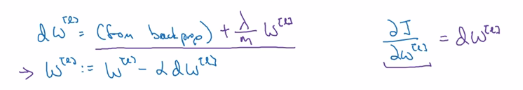
由上面可知,L2正则化有时被称为权重衰减(weight decay)
即,不加L2正则项时, 的更新方式为:
的更新方式为:
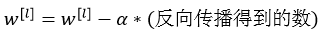
加上L2正则项之后,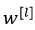 的更新方式变为:
的更新方式变为:


该正则项说明,不论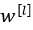 是什么,我们都试图让它变得更小,实际上,相当于我们给矩阵W乘以了
是什么,我们都试图让它变得更小,实际上,相当于我们给矩阵W乘以了 倍的权重,该倍数小于1,因此L2正则化也被称为权重衰减(weight decay)。
倍的权重,该倍数小于1,因此L2正则化也被称为权重衰减(weight decay)。
以上就是神经网络中实现L2正则化的过程。
为什么正则化可以预防过拟合?请看下一节。
1.4 正则化 regularization的更多相关文章
- [DeeplearningAI笔记]改善深层神经网络1.4_1.8深度学习实用层面_正则化Regularization与改善过拟合
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.4 正则化(regularization) 如果你的神经网络出现了过拟合(训练集与验证集得到的结果方差较大),最先想到的方法就是正则化(re ...
- zzL1和L2正则化regularization
最优化方法:L1和L2正则化regularization http://blog.csdn.net/pipisorry/article/details/52108040 机器学习和深度学习常用的规则化 ...
- 7、 正则化(Regularization)
7.1 过拟合的问题 到现在为止,我们已经学习了几种不同的学习算法,包括线性回归和逻辑回归,它们能够有效地解决许多问题,但是当将它们应用到某些特定的机器学习应用时,会遇到过拟合(over-fittin ...
- 斯坦福第七课:正则化(Regularization)
7.1 过拟合的问题 7.2 代价函数 7.3 正则化线性回归 7.4 正则化的逻辑回归模型 7.1 过拟合的问题 如果我们有非常多的特征,我们通过学习得到的假设可能能够非常好地适应训练集( ...
- (五)用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- [笔记]机器学习(Machine Learning) - 03.正则化(Regularization)
欠拟合(Underfitting)与过拟合(Overfitting) 上面两张图分别是回归问题和分类问题的欠拟合和过度拟合的例子.可以看到,如果使用直线(两组图的第一张)来拟合训,并不能很好地适应我们 ...
- CS229 5.用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- [C3] 正则化(Regularization)
正则化(Regularization - Solving the Problem of Overfitting) 欠拟合(高偏差) VS 过度拟合(高方差) Underfitting, or high ...
- 机器学习(五)--------正则化(Regularization)
过拟合(over-fitting) 欠拟合 正好 过拟合 怎么解决 1.丢弃一些不能帮助我们正确预测的特征.可以是手工选择保留哪些特征,或者使用一 些模型选择的算法来帮忙(例如 PCA) 2.正则化. ...
随机推荐
- FFmpeg视频处理
FFmpeg是一个用于音视频处理的自由软件,被广泛用于音视频开发.FFmpeg功能强大,本文主要介绍如何使用FFmpeg命令行工具进行简单的视频处理. 安装FFmpeg可以在官网下载各平台软件包或者静 ...
- 【Python】 list & dict & str
list & dict & str 这三种类型是python中最常用的几种数据类型.他们都是序列的一种 ■ 序列通用操作 1. 分片 s[a:b] 返回序列s中从s[a]到s[b- ...
- js和jquery实现显示隐藏
(选择的重要性) 当点击同一个按钮的时候实现显示影藏 <a id="link" class="b-btn-four task-resolve add-sub-tas ...
- 后台返回null iOS
1.第一种解决方案 就是在每一个 可能传回null 的地方 使用 if([object isEqual:[NSNUll null]]) 去判断 2.第二种解决方案 网上传说老外写了一个Categor ...
- NSRC技术分享——自制Linux Rootkit检测工具
### 前言 Linux系统中存在用户态与内核态,当用户态的进程需要申请某些系统资源时便会发起系统调用.而内核态如何将系统的相关信息实时反馈给用户态呢,便是通过proc文件系统.如此便营造了一个相对隔 ...
- 2017-2018-1 Java演绎法 第八周 作业
团队任务:UML设计 团队组长:袁逸灏 本次编辑:刘伟康 团队分工 第一次使用泳道图,感觉非常方便,从图中的箭头和各个活动框中可以清晰地看出分工流程: 不过既然是博客园,分工就不能只贴图,markdo ...
- Java作业-多线程
未完成,占位以后补 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多线程相关内容. 书面作业 本次PTA作业题集多线程 源代码阅读:多线程程序BounceThread 1.1 Ball ...
- Android Studio使用过程中遇到的错误
> 错误1 1. This fragment should provide a default constructor (a public constructor wit 代码不规范,这个错误是 ...
- RAID6三块硬盘离线导致的数据丢失恢复过程
小编我最近参与了一例非常成功的数据恢复的案例,在这里分享给大家.用户是一组6块750G磁盘的 RAID6,先后有两块磁盘离线,但维护人员在此情况下依然没有更换磁盘,所以在第三块硬盘离线后raid直接崩 ...
- Browser Object Model
BOM:浏览器提供的一系列对象 window对象是BOM最顶层对象 * 计时器setInterval(函数,时间)设置计时器 时间以毫秒为单位 clearInterval(timer) 暂停计时器se ...