论文笔记(1):Deep Learning.
论文笔记1:Deep Learning
2015年,深度学习三位大牛(Yann LeCun,Yoshua Bengio & Geoffrey Hinton),合作在Nature上发表深度学习的综述性论文,介绍了什么是监督学习、反向传播来训练多层神经网络、卷积神经网络、使用深度卷积网络进行图像理解、分布式特征表示与语言处理、递归神经网络,并对深度学习技术的未来发展进行展望。
原文摘要:
1,深度学习可以让那些拥有多个处理层的计算模型来学习具有多层次抽象的数据的表示。
2,这些方法在许多方面都带来了显著的改善,包括最先进的语音识别、视觉对象识别、对象检测和许多其它领域,例如药物发现和基因组学等等。
3,深度学习能够发现大数据中的复杂结构。它是利用BP算法来完成这个发现过程的。BP算法能够指导机器如何从前一层获取误差而改变本层的内部参数,这些内部参数可以用于计算表示。
4,深度卷积网络在处理图像、视频、语音和音频方面带来了突破,递归网络在处理序列数据,比如文本和语音方面表现出了闪亮的一面。
机器学习:被用来识别图片中的目标,将语音转换成文本,匹配新闻元素,根据用户兴趣提供职位或产品,选择相关的搜索结果。
传统的机器学习技术在处理未加工过的数据时,体现出来的能力是有限的。几十年来,想要构建一个模式识别系统或者机器学习系统,需要一个精致的引擎和相当专业的知识来设计一个特征提取器,把原始数据(如图像的像素值)转换成一个适当的内部特征表示或特征向量,子学习系统,通常是一个分类器,对输入的样本进行检测或分类。特征表示学习是一套给机器灌入原始数据,然后能自动发现需要进行检测和分类的表达的方法。
深度学习:就是一种特征学习方法,把原始数据通过一些简单的但是非线性的模型转变成为更高层次的,更加抽象的表达。通过足够多的转换的组合,非常复杂的函数也可以被学习。
深度学习的核心方面:各层的特征都不是利用人工工程来设计的,而是使用一种通用的学习过程从数据中学到的。
一,监督学习
1,机器学习中,不论是否是深层,最常见的形式是监督学习。
2,在典型的深学习系统中,有可能有数以百万计的样本和权值,和带有标签的样本,用来训练机器。
3,在实际应用中,大部分从业者都使用一种称作随机梯度下降的算法(SGD)。
随机梯度下降的算法(SGD):它包含了提供一些输入向量样本,计算输出和误差,计算这些样本的平均梯度,然后相应的调整权值。通过提供小的样本集合来重复这个过程用以训练网络,直到目标函数停止增长。它被称为随机的是因为小的样本集对于全体样本的平均梯度来说会有噪声估计。
4,传统的方法是手工设计良好的特征提取器,这需要大量的工程技术和专业领域知识。但是如果通过使用通用学习过程而得到良好的特征,那么这些都是可以避免的了。这就是深度学习的关键优势。
5,深度学习的体系结构是简单模块的多层栈,所有(或大部分)模块的目标是学习,还有许多计算非线性输入输出的映射。栈中的每个模块将其输入进行转换,以增加表达的可选择性和不变性。
二,反向传播来训练多层神经网络
1,在最早期的模式识别任务中,研究者的目标一直是使用可以训练的多层网络来替代经过人工选择的特征,虽然使用多层神经网络很简单,但是得出来的解很糟糕。
2,直到20世纪80年代,使用简单的随机梯度下降来训练多层神经网络,这种糟糕的情况才有所改变。只要网络的输入和内部权值之间的函数相对平滑,使用梯度下降就凑效。
3,用来求解目标函数关于多层神经网络权值梯度的反向传播算法(BP)只是一个用来求导的链式法则的具体应用而已。
反向传播算法的核心思想是:目标函数对于某层输入的导数(或者梯度)可以通过向后传播对该层输出(或者下一层输入)的导数求得(如图1)。
4,深度学习的应用很多都是使用前馈式神经网络(如图1)。
该神经网络学习一个从固定大小输入(比如输入是一张图)到固定大小输出(例如,到不同类别的概率)的映射。从第一层到下一层,计算前一层神经元输入数据的权值的和,然后把这个和传给一个非线性激活函数。
5,人们普遍认为,学习有用的、多级层次结构的、使用较少先验知识进行特征提取的这些方法都不靠谱。确切的说是因为简单的梯度下降会让整个优化陷入到不好的局部最小解。
6,2006年前后,CIFAR(加拿大高级研究院)研究者们提出了一种非监督的学习方法。
这种方法可以创建一些网络层来检测特征而不使用带标签的数据,这些网络层可以用来重构或者对特征检测器的活动进行建模。通过预训练过程,深度网络的权值可以被初始化为有意思的值。然后一个输出层被添加到该网络的顶部,并且使用标准的反向传播算法进行微调。
7,然后,还有一种深度前馈式神经网络,这种网络更易于训练并且比那种全连接的神经网络的泛化性能更好。这就是卷积神经网络(CNN)。
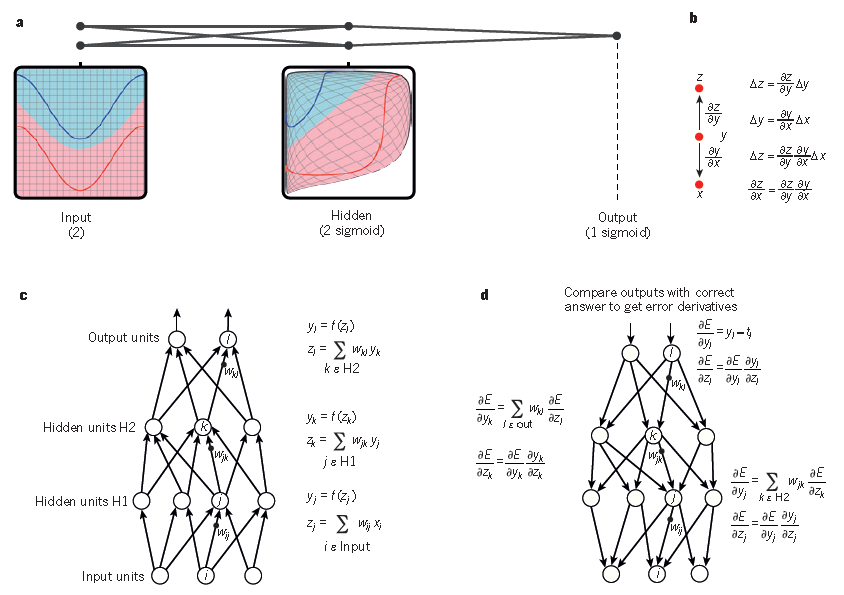
图1 多层神经网络和BP算法
a.多层神经网络(用连接点表示)可以对输入空间进行整合,使得数据(红色和蓝色线表示的样本)线性可分。注意输入空间中的规则网格(左侧)是如何被隐藏层转换的(转换后的在右侧)。这个例子中只用了两个输入节点,两个隐藏节点和一个输出节点,但是用于目标识别或自然语言处理的网络通常包含数十个或者数百个这样的节点。获得C.Olah 的许可后重新构建的这个图。
b.链式法则告诉我们两个小的变化(x和y的微小变化,以及y和z的微小变化)是怎样组织到一起的。x的微小变化量Δx首先会通过乘以∂y/∂x(偏导数)转变成y的变化量Δy。类似的,Δy会给z带来改变Δz。通过链式法则可以将一个方程转化到另外的一个——也就是Δx通过乘以∂y/∂x和∂z/∂y(英文原文为∂z/∂x,系笔误——编辑注)得到Δz的过程。当x,y,z是向量的时候,可以同样处理(使用雅克比矩阵)。
c.具有两个隐层一个输出层的神经网络中计算前向传播的公式。每个都有一个模块构成,用于反向传播梯度。在每一层上,我们首先计算每个节点的总输入z,z是前一层输出的加权和。然后利用一个非线性函数f(.)来计算节点的输出。简单期间,我们忽略掉了阈值项。神经网络中常用的非线性函数包括了最近几年常用的校正线性单元(ReLU)f(z) = max(0,z),和更多传统sigmoid函数,比如双曲线正切函数f(z) = (exp(z) − exp(−z))/(exp(z) + exp(−z)) 和logistic函数f(z) = 1/(1 + exp(−z))。
d.计算反向传播的公式。在隐层,我们计算每个输出单元产生的误差,这是由上一层产生的误差的加权和。然后我们将输出层的误差通过乘以梯度f(z)转换到输入层。在输出层上,每个节点的误差会用成本函数的微分来计算。如果节点l的成本函数是0.5*(yl-tl)^2, 那么节点的误差就是yl-tl,其中tl是期望值。一旦知道了∂E/∂zk的值,节点j的内星权向量wjk就可以通过yj ∂E/∂zk来进行调整。
三,卷积神经网络
1,卷积神经网络被设计用来处理到多维数组数据的。很多数据形态都是这种多维数组的:1D用来表示信号和序列包括语言,2D用来表示图像或者声音,3D用来表示视频或者有声音的图像。卷积神经网络使用4个关键的想法来利用自然信号的属性:局部连接、权值共享、池化以及多网络层的使用。
2,一个典型的卷积神经网络结构(如图2)是由一系列的过程组成的。 最初的几个阶段是由卷积层和池化层组成,卷积层的单元被组织在特征图中,在特征图中,每一个单元通过一组叫做滤波器的权值被连接到上一层的特征图的一个局部块,然后这个局部加权和被传给一个非线性函数,比如ReLU。在一个特征图中的全部单元享用相同的过滤器,不同层的特征图使用不同的过滤器。使用这种结构处于两方面的原因。
(1)在数组数据中,比如图像数据,一个值的附近的值经常是高度相关的,可以形成比较容易被探测到的有区分性的局部特征。
(2)不同位置局部统计特征不太相关的,也就是说,在一个地方出现的某个特征,也可能出现在别的地方,所以不同位置的单元可以共享权值以及可以探测相同的样本。在数学上,这种由一个特征图执行的过滤操作是一个离线的卷积,卷积神经网络也是这么得名来的。
3,卷积层的作用是探测上一层特征的局部连接,然而池化层的作用是在语义上把相似的特征合并起来,这是因为形成一个主题的特征的相对位置不太一样。
4,深度神经网络利用的很多自然信号是层级组成的属性,在这种属性中高级的特征是通过对低级特征的组合来实现的。
5,2012年ImageNet的Alex模型:这个成功来自有效地利用了GPU、ReLU、一个新的被称为dropout的正则技术,以及通过分解现有样本产生更多训练样本的技术。
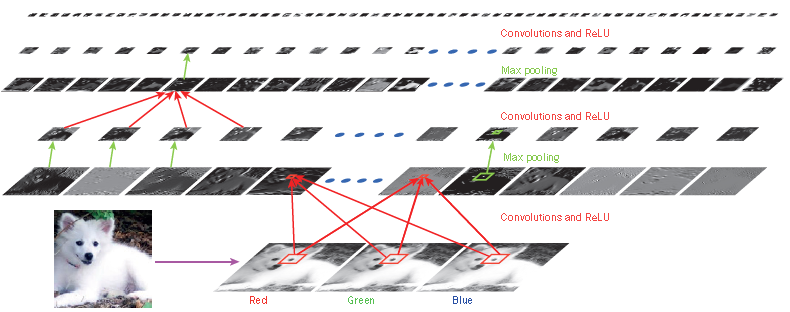
图2 卷积神经网络内部
典型的卷积网络结构的每一层(水平)的输出(而不是过滤器)应用于Samoyed狗的图像(左下角;RGB(红,绿,蓝)输入,右下角)。每个矩形图像是一个特征映射,对应于一个学习特征的输出,在每个图像位置检测到。信息在底部向上流动,底层的特性充当面向边缘的检测器,并且在输出的每个图像类中计算一个分数。ReLU,纠正线性单元。
四,使用深度卷积网络进行图像理解
1,这个成功来自有效地利用了GPU、ReLU、一个新的被称为dropout的正则技术,以及通过分解现有样本产生更多训练样本的技术。
2,如今,卷积神经网络用于几乎全部的识别和探测任务中。最近一个更好的成果是,利用卷积神经网络结合回馈神经网络用来产生图像标题。
3,卷积神经网络很容易在芯片或者现场可编程门阵列(FPGA)中高效实现。
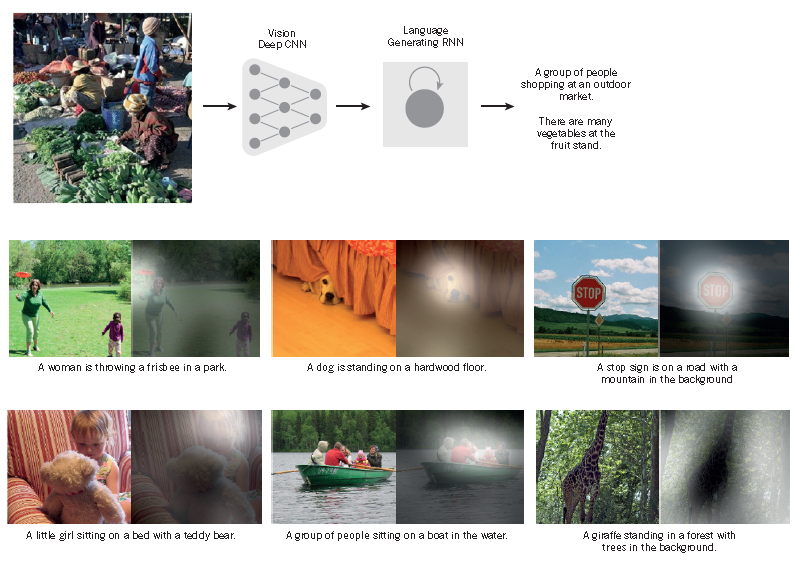
图3 从图像到文字
由一个递归神经网络(RNN)所生成的字幕,作为额外的输入,由一个深度卷积神经网络(CNN)从一个测试图像中提取出来,RNN经过训练,将图像的高级别表示转化为标题(top)。当RNN有能力将注意力集中在输入图像(中、底)的不同位置时,RNN获得了许可。当它生成每个单词(粗体)时,我们发现它利用了这一点,从而更好地将图像翻译成字幕。
五,分布式特征表示与语言处理
1,与不使用分布式特征表示(distributed representations )的经典学习算法相比,深度学习理论表明深度网络具有两个不同的巨大的优势。这些优势来源于网络中各节点的权值,并取决于具有合理结构的底层生成数据的分布。首先,学习分布式特征表示能够泛化适应新学习到的特征值的组合(比如,n元特征就有2n种可能的组合)。其次,深度网络中组合表示层带来了另一个指数级的优势潜能(指数级的深度)。
2,多层神经网络中的隐层利用网络中输入的数据进行特征学习,使之更加容易预测目标输出。在第一层中,每个单词创建不同的激活状态,或单词向量(如图4)。
3,这些语义特征在输入中并没有明确的表征。而是在利用“微规则”学习过程中被发掘,并作为一个分解输入与输出符号之间关系结构的好的方式。
4,特征表示问题争论的中心介于对基于逻辑启发和基于神经网络的认识。
5,在介绍神经语言模型前,简述下标准方法,其是基于统计的语言模型,该模型没有使用分布式特征表示。而是基于统计简短符号序列出现的频率增长到N(N-grams,N元文法)。
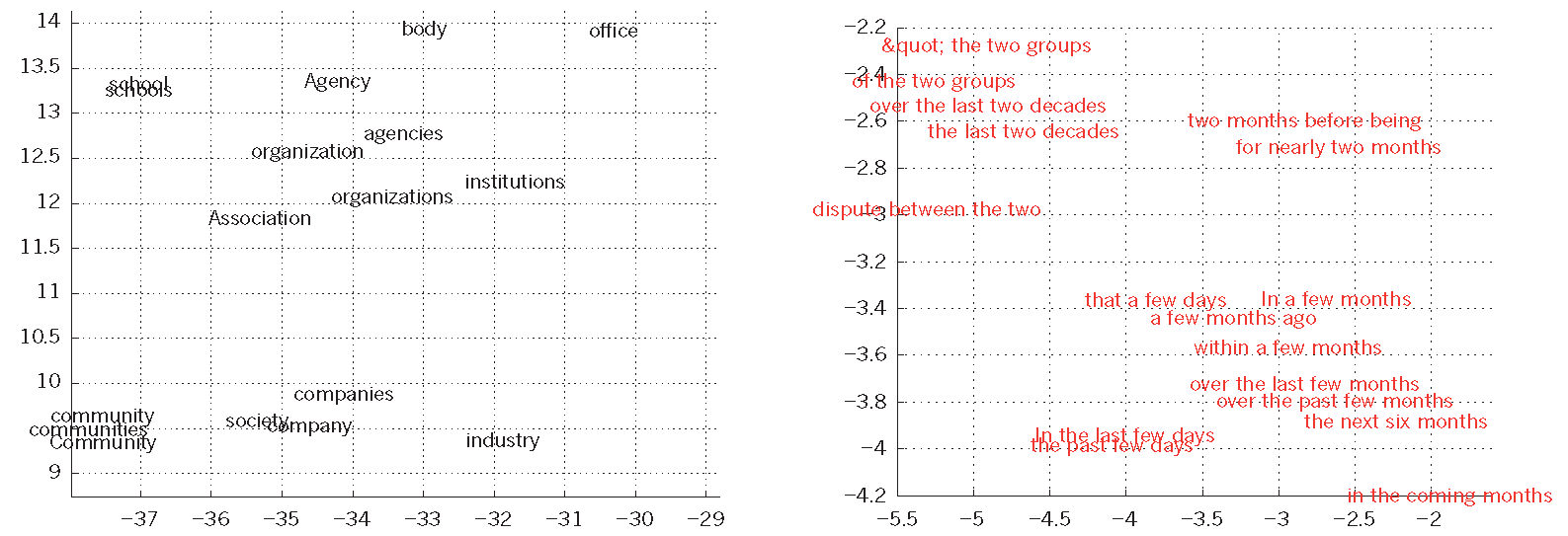
图4 词向量学习可视化
在左边是一个用建模语言学习的单词表示的图解,用t-SNE算法将非线性投影到2D。右边是由一个英语到法语的编码器-解码递归神经网络学习的短语的二维表示。可以观察到,语义相似的单词或单词序列被映射到附近的表示。通过反向传播,获得单词的分布表示法,共同学习每个单词的表示和一个函数,该函数预测一个目标数量,如序列中的下一个单词(用于语言建模)或一个完整的翻译单词序列(用于机器翻译)。
六,递归神经网络
1,首次引入反向传播算法时,最令人兴奋的便是使用递归神经网络(recurrent neural networks,下文简称RNNs)训练。对于涉及到序列输入的任务,比如语音和语言,利用RNNs能获得更好的效果。RNNs一次处理一个输入序列元素,同时维护网络中隐式单元中隐式的包含过去时刻序列元素的历史信息的“状态向量”。如果是深度多层网络不同神经元的输出,我们就会考虑这种在不同离散时间步长的隐式单元的输出,这将会使我们更加清晰怎么利用反向传播来训练RNNs(如图5)。
2,RNNs是非常强大的动态系统,但是训练它们被证实存在问题的,因为反向传播的梯度在每个时间间隔内是增长或下降的,所以经过一段时间后将导致结果的激增或者降为零。
3,RNNs一旦展开(如图5),可以将之视为一个所有层共享同样权值的深度前馈神经网络。虽然它们的目的是学习长期的依赖性,但理论的和经验的证据表明很难学习并长期保存信息。
4,为了解决这个问题,一个增大网络存储的想法随之产生。采用了特殊隐式单元的LSTM(long short-termmemory networks)被首先提出,其自然行为便是长期的保存输入。一种称作记忆细胞的特殊单元类似累加器和门控神经元:它在下一个时间步长将拥有一个权值并联接到自身,拷贝自身状态的真实值和累积的外部信号,但这种自联接是由另一个单元学习并决定何时清除记忆内容的乘法门控制的。
5,LSTM网络随后被证明比传统的RNNs更加有效,尤其当每一个时间步长内有若干层时,整个语音识别系统能够完全一致的将声学转录为字符序列。目前LSTM网络或者相关的门控单元同样用于编码和解码网络,并且在机器翻译中表现良好。
6,除了简单的记忆化,神经图灵机和记忆网络正在被用于那些通常需要推理和符号操作的任务,还可以教神经图灵机“算法”。
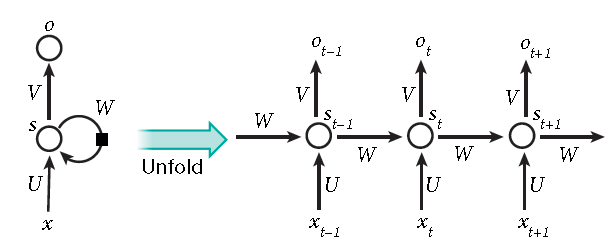
图5 一种递归神经网络,在其前向计算中所涉及的时间逐渐展开。
人工神经元(例如,在时间t时,在节点s下分组的隐藏单元)从其他神经元上得到输入(这是用黑色方块表示的,表示在左边的一个时间步的延迟)。通过这种方式,一个递归神经网络可以将输入序列与元素xt映射到一个带有元素ot的输出序列中,每个元素都依赖于前一个xt(t. t)。每一步都使用相同的参数(矩阵U,V,W)。许多其他的体系结构都是可能的,包括网络可以生成一系列输出的变体(例如,单词),每个输出都被用作下一个时间步骤的输入。反向传播算法(图1)可以直接应用于右侧展开网络的计算图,计算出总误差的导数(例如,生成正确输出序列的对数概率),以及所有的状态st和所有参数。
七,深度学习的未来展望
无监督学习对于重新点燃深度学习的热潮起到了促进的作用,但是纯粹的有监督学习的成功盖过了无监督学习。在本篇综述中虽然这不是我们的重点,我们还是期望无监督学习在长期内越来越重要。无监督学习在人类和动物的学习中占据主导地位:我们通过观察能够发现世界的内在结构,而不是被告知每一个客观事物的名称。
作者:hangliu 出处:http://www.cnblogs.com/hangliu/ 欢迎转载或分享,但请务必声明文章出处。
论文笔记(1):Deep Learning.的更多相关文章
- 论文笔记 — L2-Net: Deep Learning of Discriminative Patch Descriptor in Euclidean Space
论文: 本文主要贡献: 1.提出了一种新的采样策略,使网络在少数的epoch迭代中,接触百万量级的训练样本: 2.基于局部图像块匹配问题,强调度量描述子的相对距离: 3.在中间特征图上加入额外的监督: ...
- 论文笔记——A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding
论文<A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding> Prunin ...
- 转:UFLDL_Tutorial 笔记(deep learning绝佳的入门资料 )
http://blog.csdn.net/dinosoft/article/details/50103503 推荐一个deep learning绝佳的入门资料 * UFLDL(Unsupervised ...
- ZH奶酪:【阅读笔记】Deep Learning, NLP, and Representations
中文译文:深度学习.自然语言处理和表征方法 http://blog.jobbole.com/77709/ 英文原文:Deep Learning, NLP, and Representations ht ...
- 论文笔记:Deep feature learning with relative distance comparison for person re-identification
这篇论文是要解决 person re-identification 的问题.所谓 person re-identification,指的是在不同的场景下识别同一个人(如下图所示).这里的难点是,由于不 ...
- 论文笔记:Deep Residual Learning
之前提到,深度神经网络在训练中容易遇到梯度消失/爆炸的问题,这个问题产生的根源详见之前的读书笔记.在 Batch Normalization 中,我们将输入数据由激活函数的收敛区调整到梯度较大的区域, ...
- 论文笔记:Deep Attentive Tracking via Reciprocative Learning
Deep Attentive Tracking via Reciprocative Learning NIPS18_tracking Type:Tracking-By-Detection 本篇论文地主 ...
- 论文笔记之:Learning Cross-Modal Deep Representations for Robust Pedestrian Detection
Learning Cross-Modal Deep Representations for Robust Pedestrian Detection 2017-04-11 19:40:22 Moti ...
- 论文笔记之:Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
Learning Multi-Domain Convolutional Neural Networks for Visual Tracking CVPR 2016 本文提出了一种新的CNN 框架来处理 ...
- 【论文笔记】Federated Learning for Wireless Communications: Motivation, Opportunities, and Challenges(综述)
Federated Learning for Wireless Communications: Motivation, Opportunities, and Challenges Authors So ...
随机推荐
- 安装mysql到服务器的linux环境下
1·安装mysql 命令:yum -y install httpd php mysql mysql-server 2·配置mysql 配置开机启动服务 /sbin/chkconfig --add my ...
- javascript之prototype原型属性案例
练习: 给字符串对象添加一个toCharArray的方法,然后再添加一个reverse(翻转)的 方法 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML ...
- (NO.00003)iOS游戏简单的机器人投射游戏成形记(十二)
回到Xcode,新建Level1类,继承于CCNode. 打开Level1.m在初始化方法中添加如下方法: -(void)didLoadFromCCB{ [self initBasket]; [sel ...
- spring2.5与hibernate3升级后的bug
手头有一个项目,使用的是struts2 hibernate3 spring2.5 是之前的老项目了,spring与hibernate的版本都比较低 自己看了最新的spring4与hibernate4, ...
- 小强的HTML5移动开发之路(20)——HTML5 Web SQL Database
来自:http://blog.csdn.net/dawanganban/article/details/18220761 一.Web Database介绍 WebSQL数据库API实际上不是HTML5 ...
- 【leetcode81】Product of Array Except Self
题目描述: 给定一个长度为n的整数数组Array[],输出一个等长的数组result[],这个输出数组,对应位置i是除了Array[i]之外,其他的所有元素的乘积 例如: given [1,2,3,4 ...
- 【Android 应用开发】 Ubuntu 安装 Android Studio (旧版本|仅作参考)
. 果断换Ubuntu了, Ubuntu的截图效果不好, 不能设置阴影 ... 作者 : 万境绝尘 转载请注明出处 : http://blog.csdn.net/shulianghan/article ...
- uGUI使用代码动态添加Button.OnClick()事件(Unity3D开发之十二)
猴子原创,欢迎转载.转载请注明: 转载自Cocos2Der-CSDN,谢谢! 原文地址: http://blog.csdn.net/cocos2der/article/details/42705885 ...
- Linux 用户打开进程数的调整
Linux 用户打开进程数的调整 参考文章: 关于RHEL6中ulimit的nproc限制(http://www.cnblogs.com/kumulinux/archive/2012/12/16/28 ...
- Android应用---基于NDK的samples例程hello-jni学习NDK开发
Android应用---基于NDK的samples例程hello-jni学习NDK开发 NDK下载地址:http://developer.android.com/tools/sdk/ndk/index ...