machine learning 之 Neural Network 3
整理自Andrew Ng的machine learning课程week6.
目录:
- Advice for applying machine learning (Decide what to do next)
- Debugging a learning algorithm
- machine learning diagnostic
- Evaluating a hypothesis
- Model selection and Train / validation / test set
- Bias and Variance
- Diagnosing bias and variance
- Regularization and bias / variance
- learning curve
- High bias
- High variance
- summary of decide what to do next
- diagnosing neural network
- Model complexity effects
- Build a spam classifier
- Prioritzing what to work on
- Error analysis
- Error matric for skewed classes
- precision / recall
- trade off precision and recall
- Data for machine learning
1、Advice for applying machine learning (Decide what to do next)
1.1、debugging a learning algorithm
假设你用regularized linear regression去解决预测房价的问题,但是,当你用模型去预测新的房价数据时,发现预测的误差很大,那么接下来你会怎么办呢?
- 获取更多的训练数据?
- 尝试使用更小的特征集合?
- 尝试使用更多的特征?
- 尝试增大$\lambda$?
- 尝试减小$\lambda$?
对于以上的一些做法,你会怎么做呢?依靠直觉吗?
现实中常常有人仅仅依靠直觉去选取某一种做法,比如说获取更多的训练数据,但是当他们耗费了大量的时间去完成这件事之后,却发现模型性能并没有什么提升,依靠直觉显然是一种不划算的做法
1.2、machine learning diagnostic
A test that you can run to gain insight what is/isn't working with a learning algorithm, and gain guidance as to how best to improve its performance.
machine learning diagnostic是一个test,它可以让我们知道一个特定的算法是否是有用的,并且可以指导我们,怎么做才可以最大的提升模型的性能。
Diagnostic可能会耗费你的时间,但是相比于在实战中耗费大量的时间却发现结果不好而言,这点时间是值得的。
1.3、Evaluating a hypothesis
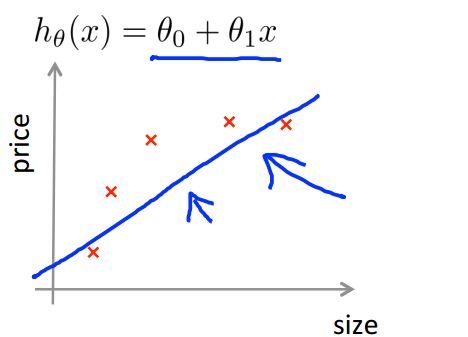
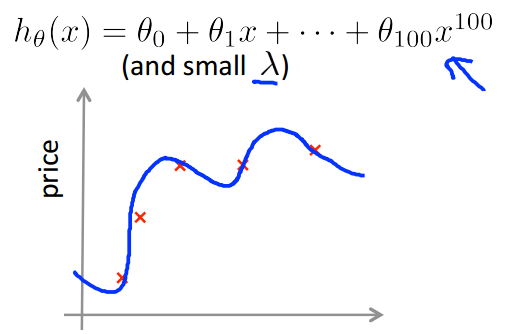
如何去评估一个模型的好坏?就像之前一直说过的,训练模型做得好,并不一定说明这个模型就是好的,这个模型很有可能是过拟合的(如下图),那么对新的数据集而言,这个模型可能做的并不好。
所以用训练数据集上的误差评估模型的好坏是不可以的。
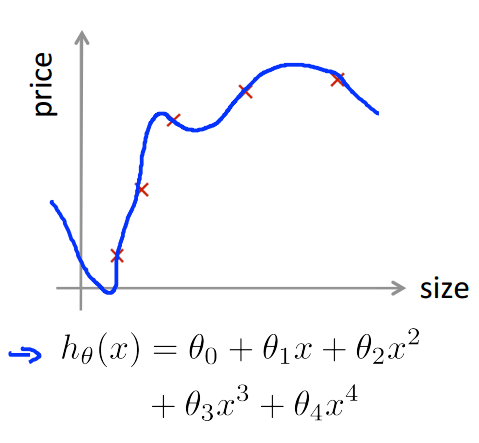
通常的做法是,将数据集分为训练数据(70%)和测试数据(30%),然后:
- 用训练数据去训练模型,得到模型参数
- 用上面的模型去预测测试数据集上的数据,计算测试集上的误差error
用测试集上的error去评估模型的好坏
对于linear regression:error是($\frac{平方和}{m_{test}}$)
对于logistic regression:
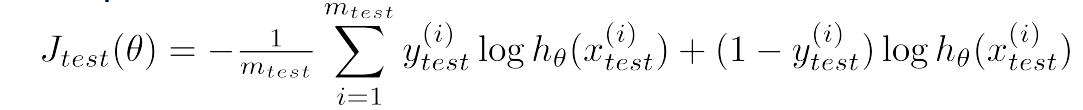
1.4、Model selection and Train / validation / test set
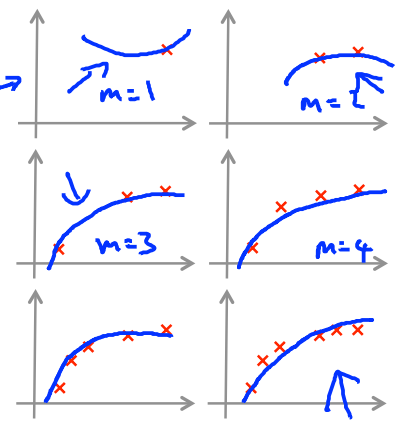
如果现在有多个模型alg1,alg2,alg3......,如下所示,10个不同阶的模型(代表着不同的模型复杂度),我们需要选择最好的一个模型,那么如何去选择呢(依照怎样的标准去选择)?
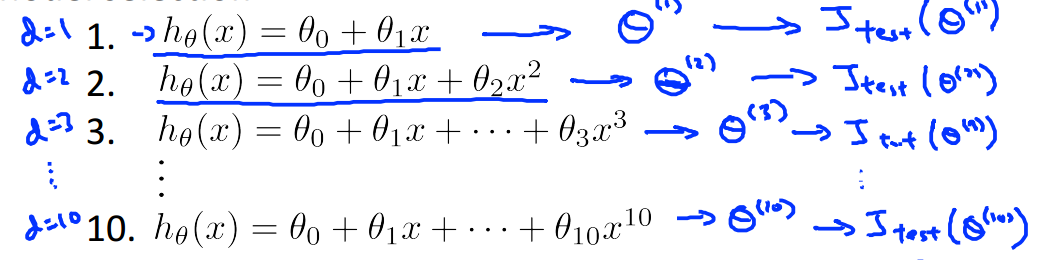
如果仿照1.3的做法,先用训练数据训练出来模型,再用测试数据去计算误差,选择在测试数据集上误差最小的模型作为我们最终选定的模型;
思考一下,如果这么做的话,其实是和仅用训练数据误差评估模型好坏是一个道理,此时选择出的只是在我们所用的测试集上误差最小的模型,但是用其他的测试集的话,可能并不是当前的模型误差最小,那么这个误差并不能真正反映模型的好坏;
通常的做法是,将数据集分成train set / 训练集(60%),cross validation set / 验证集(20%),test set / 测试集(20%),然后:
- 用训练集去训练多个模型,获取每个模型的参数
- 用训练好的这些模型去预测验证集,计算验证集上的误差,选择出其中误差最小的模型
- 计算测试集在误差最小的模型上的误差,作为此模型的评估标准
各个集合的误差计算如下:

2、Bias and Variance
在之前的文章中就接触过bias和variance的概念,这里回顾一下:

训练集和验证集和误差计算如下:

2.1、Diagnosing bias and variance
随着d(多项式的阶数)的增大,training error和cross validation error的变化如下:
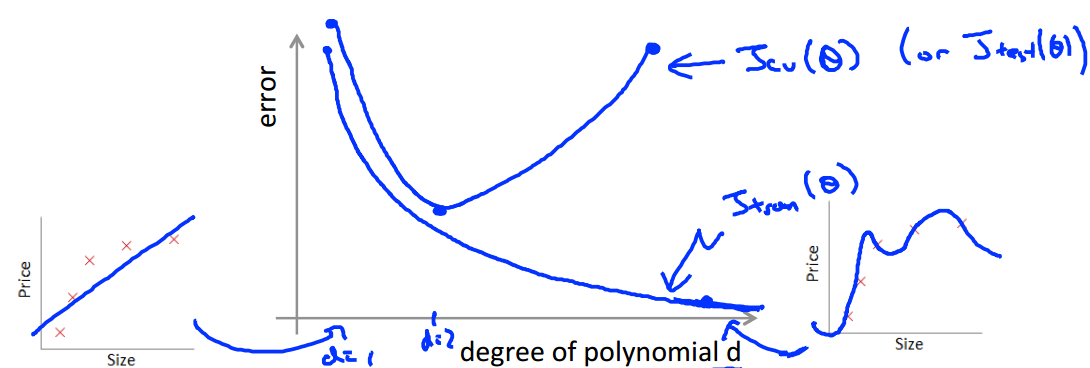
当模型比较简单的时候,训练的程度低,有欠拟合的现象(high bias),此时训练误差和测试误差(或者验证误差)都比较大,当d越来越大,训练的程度越来越高,训练误差和测试误差都在减小,到达一个点之后,模型过于复杂,训练误差在继续减小,但是此时已经出现了过拟合现象(high variance),测试误差越来越大,即:
- Bias(underfit):训练误差和测试误差都高,两者差不多
- Variance(overfit):训练误差小,测试误差很大,远大于训练误差
2.2、Regulization and bias / variance
$\lambda$是惩罚因子,如下图所示:
- 当$\lambda$十分大时,模型相当于只有是常数估计,图像近似为一条横线,欠拟合(high bias)
- 当$\lambda$十分小时,惩罚项的作用不大,模型出现过拟合(high variance)
- 我们需要选取一个恰当的$\lambda$,使得模型刚刚好
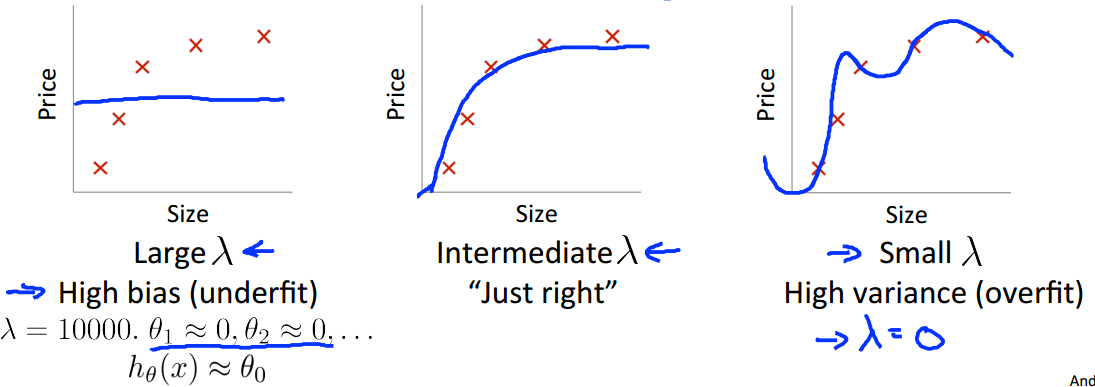
那么问题来了,如何选择一个恰当的$\lambda$呢?我们可以尝试:
- 设定一系列的$\lambda$=[0, 0.01, 0.02, 0.04, 0.08, ......., 10.24],比如说这12个$\lambda$;
- 构造一组不同的模型(with different degrees or other variants)
- 对于每个模型遍历每个$\lambda$,用训练数据去训练这些组合确定的模型,得到最终的模型参数;
- 计算验证集上的误差;
- 选取模型中使得验证集误差最小的模型;
- 计算选出的模型在测试集上的误差,评估得到的模型的好坏;
利用一系列的$\lambda$我们可以看到随着$\lambda$的增大,training error和cv(cross validation) error的变化:
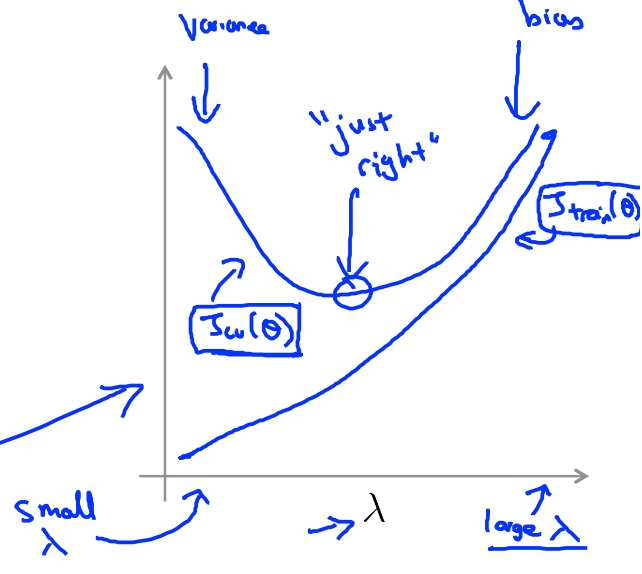
- 当$\lambda$非常小时,train error很小,test error很大,此时训练程度高,模型过拟合;
- 随着$\lambda$的增大,train error越来越大,test error在减小,模型过拟合现象在缓和;
- 当$\lambda$增大到某个点之后,train error和test error都开始变大,因为此时模型是欠拟合的;
3、learning curves
这一部分主要是来评估训练数据集的大小和模型误差之间的关系,对于训练误差而言:
- 当training set非常小(1,2,3个训练数据),train error就会接近0,因为如果点少的话,当然可以找到一个曲线几乎完美的拟合这几个点;
- 当training set变大,train error也会相应的变大;
- 当training set的数据量达到一个值后,train error会趋于不变;
3.1、High bias

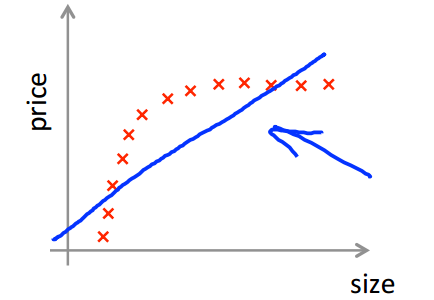
红线处是理应达到的误差下限,训练误差和测试误差都远高于理想的误差
对此可以用下图来解释,此时出现的问题是模型太过于简单,这个时候获取更多的训练数据对模型是没什么帮助的
3.2、High variance
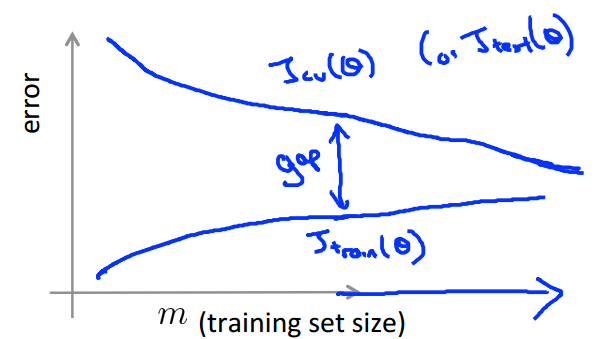
测试误差远大于训练误差,此时出现了过拟合现象;
可用下图来解释这个现象,模型太过于复杂,惩罚也不大到位,所以模型出现了过拟合现象,此时如果可以增大训练数据的数目,对模型应该是有帮助的;

4、summary of decide what to do next
针对文章一开始提出的问题,经过一系列的梳理,有了答案:
- 获取更多的训练数据? 解决high variance问题(overfitting)
- 尝试使用更小的特征集合? 解决high variance问题(overfitting)
- 尝试使用更多的特征? 解决high bias问题(underfitting)
- 尝试增大$\lambda$? 解决high variance问题(overfitting)
- 尝试减小$\lambda$? 解决high bias问题(underfitting)
5、Diagnosing neural network
- 具有较少的参数的neural network容易underfitting,同时也computationally cheaper;
- 具有较多的参数的neural network容易overfitting,同时也computationally expensive(此时可用regulization去处理过拟合问题);
- 默认是一层的hidden layer,但是也可以用cv set去选择最合适的hidden layer数目;
6、Model complexity effects
- 低阶多项式(简单模型)有high bias和low variance,训练集和测试集的误差都大;
- 高阶多项式(复杂模型)有high variance和low bias,训练集误差小,测试集误差大;
- 我们最终想要得到的是一个中和的模型,拟合数据能力不错,泛化能力也不错;
7、Build a spam classifier
7.1、proritizing what to work on
系统设计:对于给定的邮件数据,可以给每个邮件设计一个vector,向量中每个元素代表了一个word,word在邮件中就设为1,不在就设为0,搜索邮件中最常出现的words。
如下图所示:

那么,如何去提升分类器的精度呢?
- 收集更多的数据?
- 加入更加经验性的特征?(header data in spam)
- 处理输入数据?(reprocessing miss-spelling)
7.2、Error analysis
推荐的解决机器学习问题的方法是:
- start with a simple algorithm,implement it quickly, and test it on cv data
- 画出learning curve去决定一些策略是否是有用的,比如more data,more features
- 手动检测cv的误差,找出最常出错的那些点,分析它
比如说,5000封邮件,有100封被错分了,此时思考:
- 这100封邮件属于邮件里面的什么类别(如大多是steal password、miss-spelling)
- 用什么办法可以把这个类型的邮件分对(比如加入新的特征),然后把新的策略加入到模型中去;
得到了新的策略之后,就将其加入到模型中看一看结果是否更好,此时需要一个评判标准,一个简单粗暴的评判标准;
在评估模型的时候我们要得到一个real error number,如果新的策略加入之后,这个error减小了,那就值得继续做下去,否则就不需要再做下去了;
8、Error metrics for skewed classes
对于癌症判别的问题,训练出来的分类器在测试集上达到了1%的error rate,乍一看觉得结果很好啊;
但是,实际上测试集中只有0.5%的病人患有癌症,也就是说,即时我们的分类器只是简单的将所有人都认为不患癌症,也可以达到0.5%的error rate,那我们能说这个分类器比之前的那个1% error rate的分类器好吗?显然不能啊,因为这根本就不是一个分类器啊!
这种类别分布的情况就称为skewed classes,此时用error rate来评估模型是不是进步了就不准确了
8.1、precision / recall
对于skewed classes,常用的误差分析方法是precision / recall
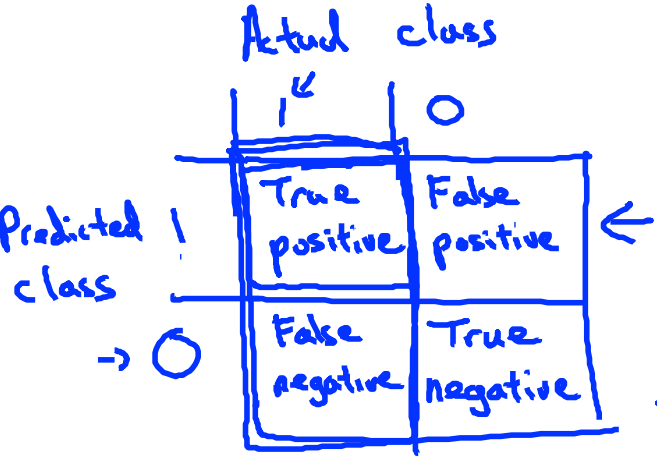
$precision=\frac{True positive}{number of predicted positive}=\frac{True positive}{Ture positive + False positive}$
代表了在所有的预测为患癌症的病人中,实际患癌症的比例
$recall=\frac{True positive}{number of actural positive}=\frac{True positive}{Ture positive + False negative}$
代表在实际患有癌症的病人中,被预测出来的比例
8.2、trade off precision and recall
precision和recall是一个需要与实际情况相结合的量;
比如在癌症问题上,使用logistic regression,
如果为了安抚病人的心理,只有在非常确定(概率大)病人得了癌症时才会判定为得了癌症(y=1),那么就会把分类中的阈值设置的很大,比如0.7,0.9,此时,我们有higher precision,lower recall
如果为了病人的健康,那么只有有一些可能性,就判定为癌症,以便于他可以去治疗,那么就会把分类中的阈值设置的很大,比如0.3,此时,我们有higher recall,lower precision
precision和recall的图像类似如下,曲线不确定:
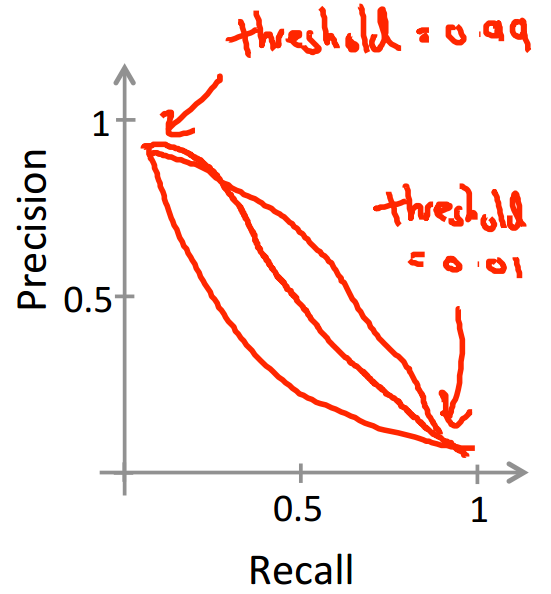
现在这里有两个值,我们如何去选择模型呢,如何指导一些策略对模型是否有改善的作用呢?
这里就有了$F_1 score=2\frac{PR}{P+R}$,F1 score是一个同时考虑到了precision和recall的值:
- 当P=0 or R=0,则F1 score=0
- 当P=1 and R=1,则F1 score=1
9、Data for machine learning
有人曾说过:it‘s not who has the best algorithm that wins, it's who has the most data.,这句话对吗?看两个例子:
- 有可以提供足够多的信息的features,$x \in R_n$,此时去预测y;
如:for breakfast I ate _____ eggs.(two,too,to)
- 在只有房屋面积信息时,预测房价;
思考:对于一个专家(针对指定问题)而言,她们可以解答吗?对于第1个问题,可以;对于第二个问题而言,显然是不可以的;
那么回到最初的问题,big data一定会赢吗?
不一定,如果信息不够的话,再多的数据也没有用
machine learning 之 Neural Network 3的更多相关文章
- Python -- machine learning, neural network -- PyBrain 机器学习 神经网络
I am using pybrain on my Linuxmint 13 x86_64 PC. As what it is described: PyBrain is a modular Machi ...
- machine learning 之 Neural Network 1
整理自Andrew Ng的machine learning课程week 4. 目录: 为什么要用神经网络 神经网络的模型表示 1 神经网络的模型表示 2 实例1 实例2 多分类问题 1.为什么要用神经 ...
- machine learning 之 Neural Network 2
整理自Andrew Ng的machine learning 课程 week5. 目录: Neural network and classification Cost function Backprop ...
- Machine Learning:Neural Network---Representation
Machine Learning:Neural Network---Representation 1.Non-Linear Classification 假设还採取简单的线性分类手段.那么会面临着过拟 ...
- Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.1
3.Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.1 http://blog.csdn.net/sunbow0 ...
- Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.2
3.Spark MLlib Deep Learning Convolution Neural Network(深度学习-卷积神经网络)3.2 http://blog.csdn.net/sunbow0 ...
- Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.3
3.Spark MLlib Deep Learning Convolution Neural Network(深度学习-卷积神经网络)3.3 http://blog.csdn.net/sunbow0 ...
- 《MATLAB Deep Learning:With Machine Learning,Neural Networks and Artificial Intelligence》选记
一.Training of a Single-Layer Neural Network 1 Delta Rule Consider a single-layer neural network, as ...
- Deep learning与Neural Network
深度学习是机器学习研究中的一个新的领域,其动机在于建立.模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本.深度学习是无监督学习的一种. 深度学习的概念源于人工神经网络的 ...
随机推荐
- (NO.00005)iOS实现炸弹人游戏(九):游戏主角(二)
大熊猫猪·侯佩原创或翻译作品.欢迎转载,转载请注明出处. 如果觉得写的不好请多提意见,如果觉得不错请多多支持点赞.谢谢! hopy ;) 上篇介绍了游戏主角的初始化方法,下面我们一次来实现主角的其他方 ...
- 1052. Linked List Sorting (25)
题目如下: A linked list consists of a series of structures, which are not necessarily adjacent in memory ...
- Http协议处理器——Http11Processor
Http11Processor组件提供了对Http协议通信的处理,包括对套接字的读取过滤.对http协议的解析并封装成请求对象.http响应对象的生成.套接字的过滤写入等等操作. 喜欢研究java的同 ...
- 安装配置Kafka
1,下载kafka安装包,解压缩,tar -zxvf kafka_2.10-0.8.2.1.tgz 2,修改/etc/profile文件,增加KAFKA_HOME变量 3,进入KAFKA_HOME/c ...
- Deep Learning with Torch
原文地址:https://github.com/soumith/cvpr2015/blob/master/Deep%20Learning%20with%20Torch.ipynb Deep Learn ...
- Java编写的接口测试工具
这几天由于要频繁地使用一些天气数据接口,但是每次都要频繁的打开网页,略显繁琐,故就自己做了两个json数据获取的小工具. 第一个 先来看看第一个吧,思路是使用一个网络流的处理,将返回的json字符串数 ...
- kafka原理简介并且与RabbitMQ的选择
kafka原理简介并且与RabbitMQ的选择 kafka原理简介,rabbitMQ介绍,大致说一下区别 Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和 ...
- H5学习之旅-H5的块标签的使用(9)
块元素的基本语法 1. Html块元素 ,块元素在开始时候通常以新行开始,比如h1,p,ul 2.内联元素,通常不会以新行开始,比如a,b,img 3.html的div元素,div也被称为块元素,其主 ...
- Ionic APP-Web SPA开发进阶(二)Ionic进阶之路由去哪了
Ionic进阶之路由去哪了 项目需求 在查看药品时,从药品列表中可以通过点击药品列表获取某一药品详情.提交订单时,同样可以查看药品详情.两种情形下,从药品详情返回后,应分别返回至原来的页面.如下图所示 ...
- OpenCV特征点检测------Surf(特征点篇)
Surf(Speed Up Robust Feature) Surf算法的原理 ...