web scraper 抓取分页数据和二级页面内容
如果是刚接触 web scraper 的,可以看第一篇文章。
web scraper 是一款免费的,适用于普通用户(不需要专业 IT 技术的)的爬虫工具,可以方便的通过鼠标和简单配置获取你所想要数据。例如知乎回答列表、微博热门、微博评论、淘宝、天猫、亚马逊等电商网站商品信息、博客文章列表等等。
如果你已经用过这个工具,想必已经用它抓取过一些数据了,是不是很好用呢。也有一些同学在看完文章后,发现有一些需求是文章中没有说到的,比如分页抓取、二级页面的抓取、以及有些页面元素选择总是不能按照预期的进行等等问题。
本篇就对前一篇文章做一个补充,解决上面所提到的问题。
分页抓取
上一篇文章提到了像知乎这种下拉加载更多的网站,只要使用 Element scroll down 类型就可以了,但是没有提到那些传统分页式的网站。
其实分页式的网站更加简单,不用什么过多的设置,只需要在 Start URL 上做设置就可以了,拿这个豆瓣小组举例,链接地址为 https://www.douban.com/group/135641/discussion。我们进去后点一点页面下方的页码,就可以看到地址栏上的变化,点击第 2 页的时候,在后面的地址栏多了参数 start=25 ,再点击第 1 页的时候,参数变为了 start=0 ,这是比较特殊的一种情况,它的分页是按照 25 递增的,向后递增依次为 [0,25,50,75...]。大多数的网站的递增还是1,即[0,1,2,3...]。
而 web scraper 中提供了一种写法,可以设置页码范围及递增步长。写法是这样的: [开始值-结束值:步长],举几个例子来说明一下:
1、获取前10页,步长为1的页面 :[1-10] 或者 [1-10:1]
2、获取前10页,步长为10的页面:[1-100:10]
3、获取前10页,步长为25的页面:[1-250:25]
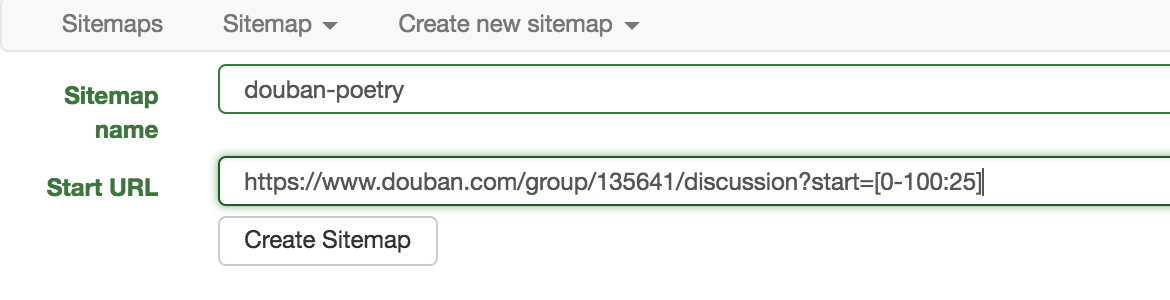
现在我们要抓取的豆瓣小组的规则就是第三中情况,所以设置 sitemap 的 Start URL 为:https://www.douban.com/group/135641/discussion?start=[0-100:25] 。
还有一些网站的页面,比如淘宝店铺的商品列表页,它的 url 里有好多参数,有点参数会随机变化,有些同学这时候就蒙了,这怎么设置啊。其实有些参数并不会影响显示内容,任意设置甚至去掉都没有关系,只要找对了表示页码的参数并按照上面的做法设置就可以了。
二级页面抓取
这种情况也是比较多的,好多网站的一级页面都是列表页,只会显示一些比较常用和必要的字段,但是我们做数据抓取的时候,这些字段往往不够用,还想获取二级详情页的一些内容。下面我用虎嗅网来演示一下这种情况下的抓取方式。
目标页面:https://www.huxiu.com/channel/104.html
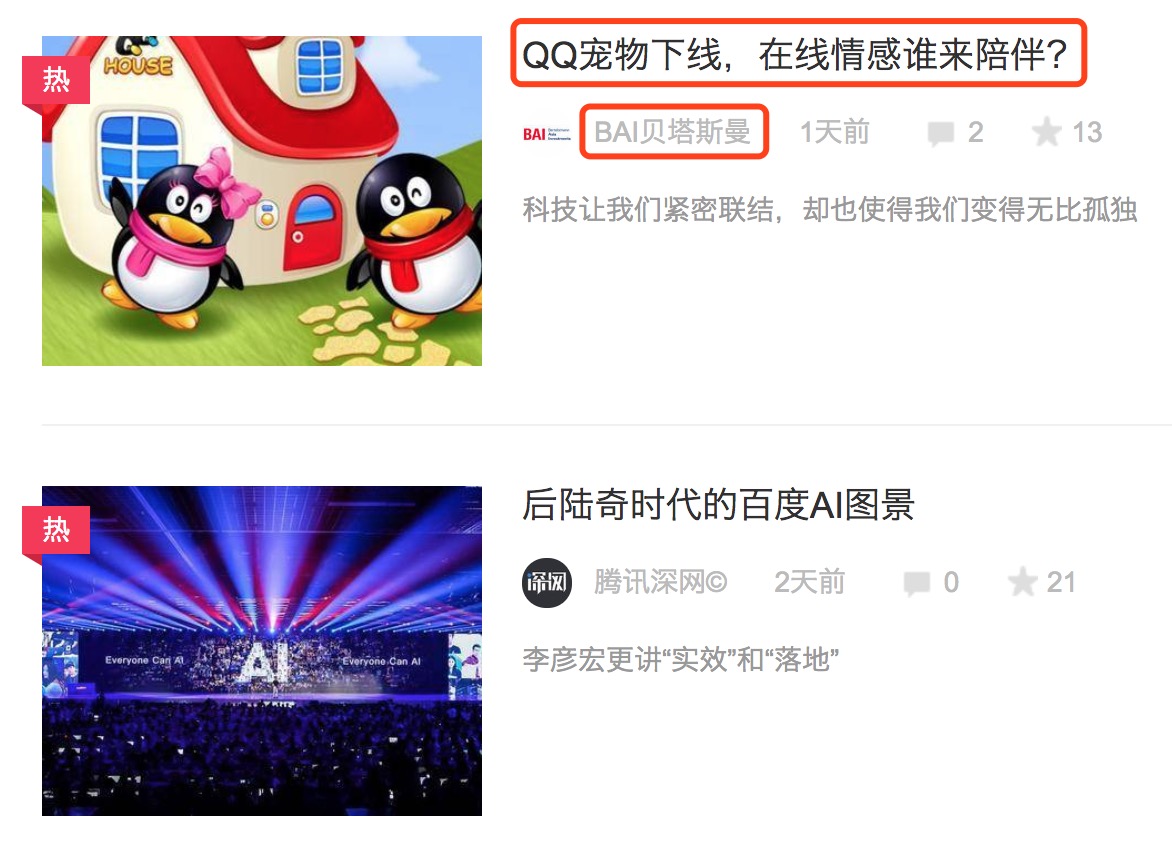
只做简单演示,这个页面本身是下拉下载更多的页面,这里只获取默认加载的内容以及二级页面的一些属性。下面的两张图中标红的部分分别为列表页的标题、作者以及详情页的发布时间,点击列表页的标题链接会跳转到详情页面。

现在开始从头到尾介绍一下整个步骤,其实很简单:
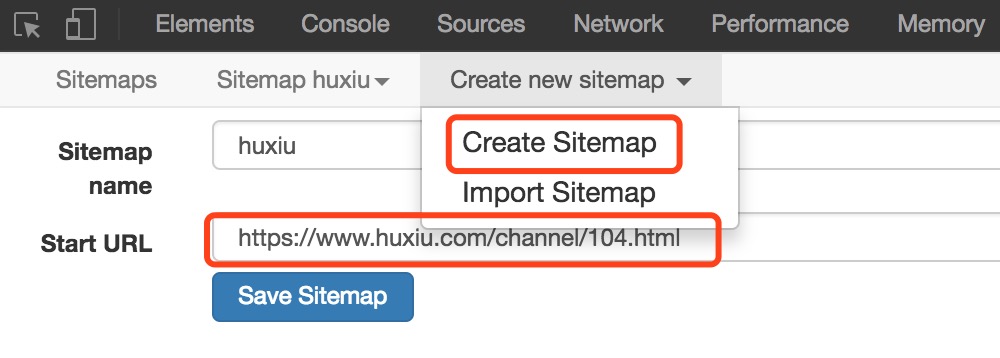
1、在浏览器访问上面说的这个地址,然后调出 Web Scraper ,Create Sitemap ,输入一个名称和 Start URL,然后保存。
2、之后打开这个 sitemap ,点击 Add new selector。
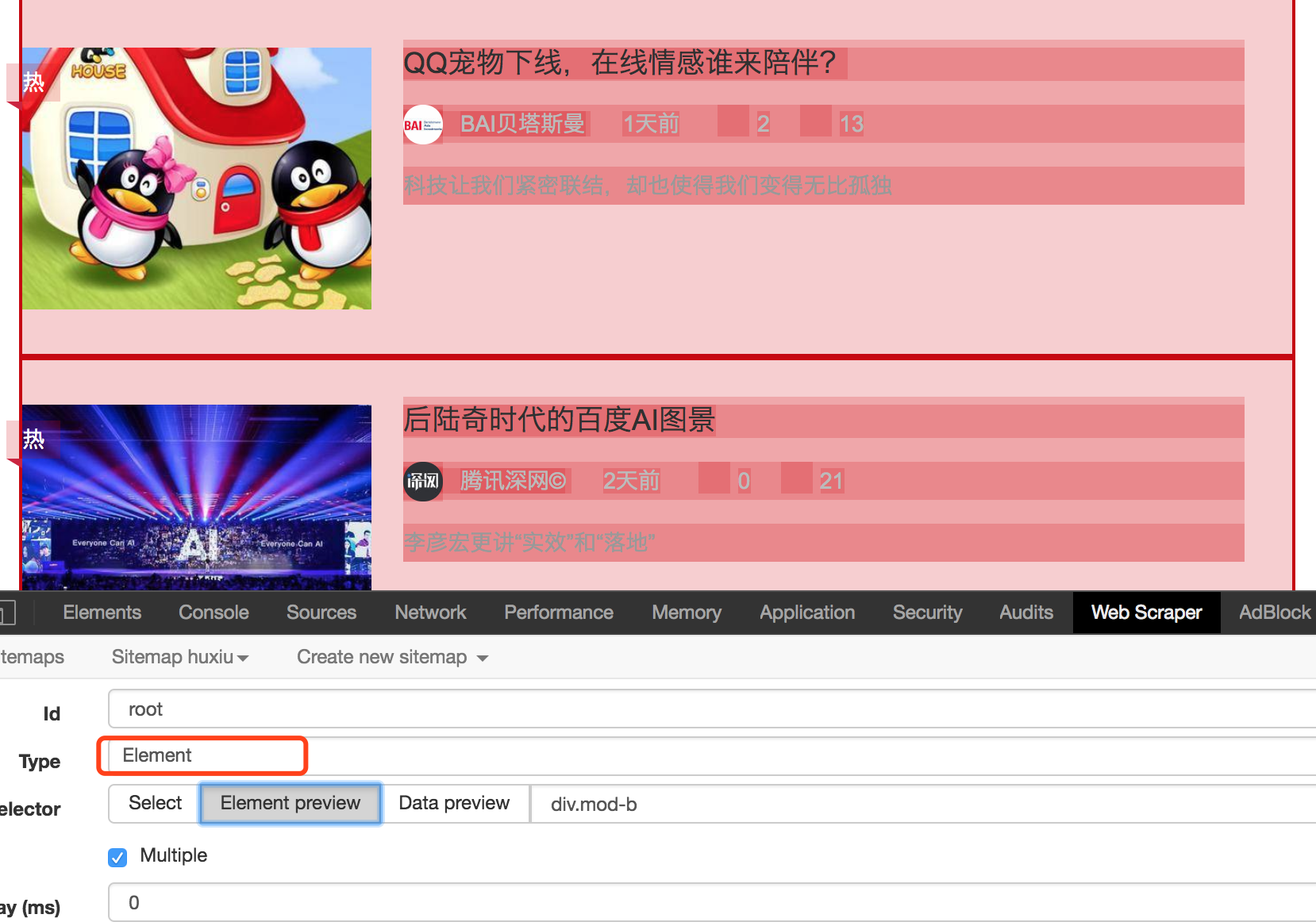
3、输入 Id,Type 选择为 Element,点击 Select 在页面中选择列表区域,并勾选 Multiple ,保存。最后预览效果如下:
4、回到刚刚创建的 root selector,点击进入子 selector 页面,添加子 selector。
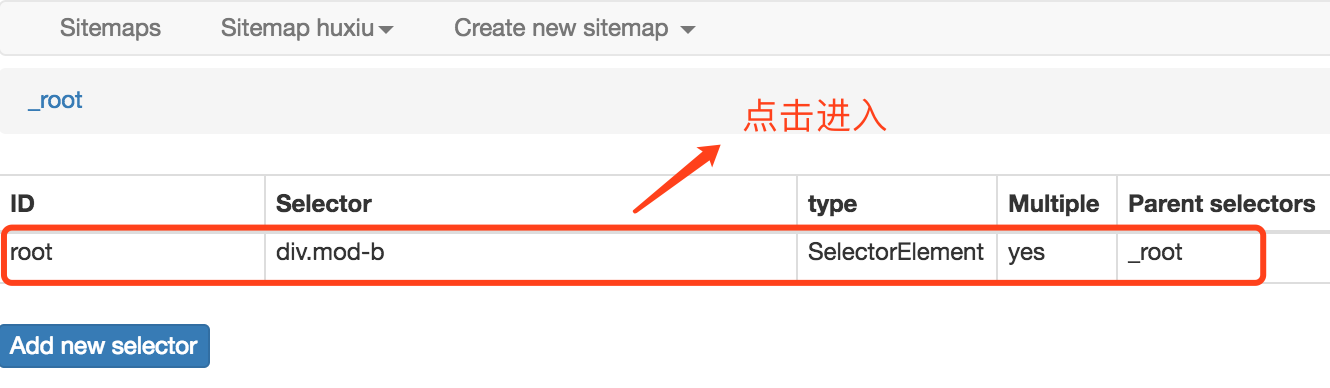
5、进入子 selector 页面后,点击 Add new selector,这一步是为了加一个跳转 selector ,为之后到详情页面搭个桥。依然是填写 Id,Type 选择为 Link 类型,点击 selector ,选择点击跳转的链接,这里就是标题,之后预览效果如下:
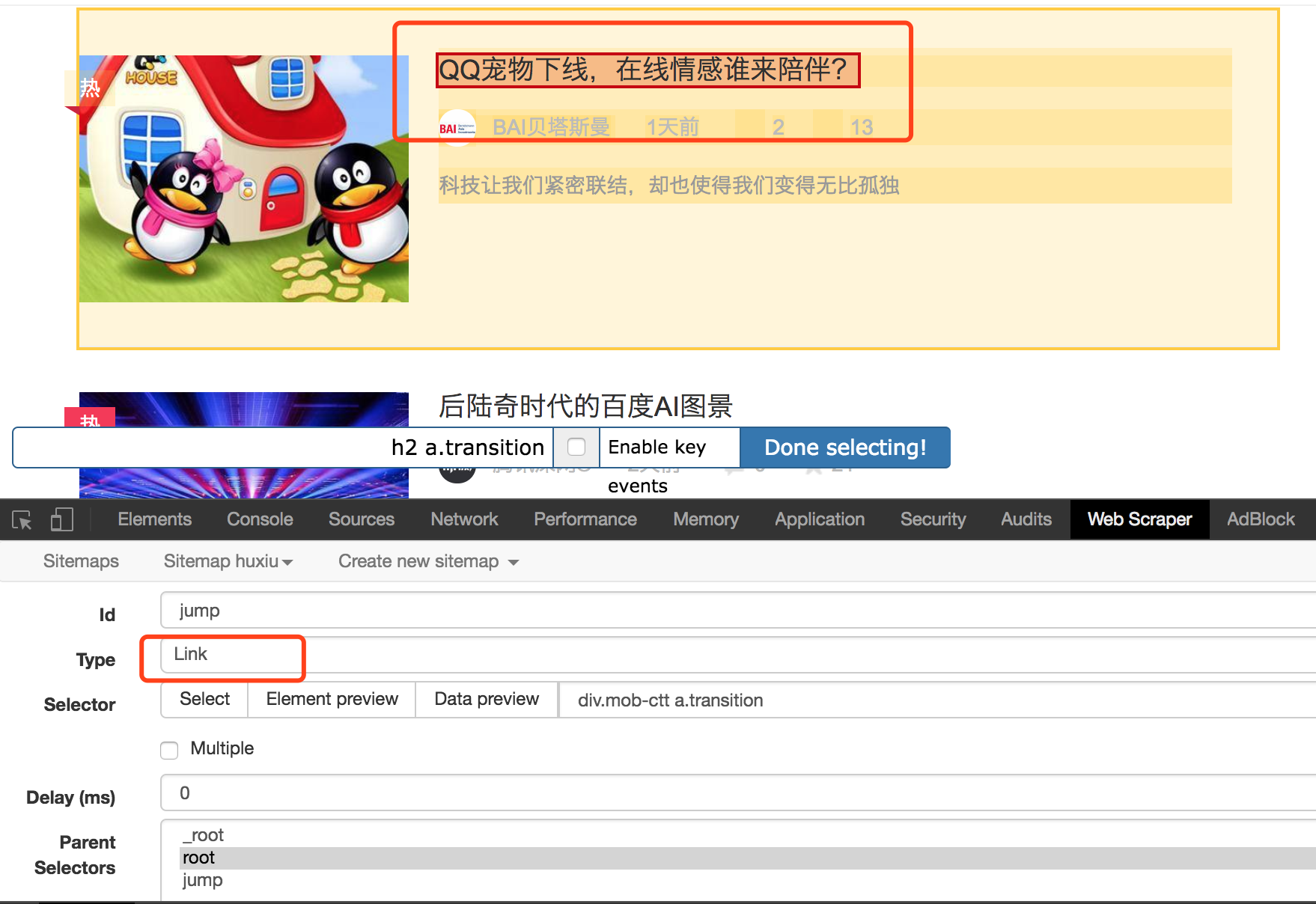
6、这一步完成后,下面就要到详情页选择我们需要的内容了。点击刚刚创建的 jump 跳转 selector,点击进入它的下一级 selector 界面。这一步好多同学不知道怎么操作了,好多同学也就卡在了这一步,其实很简单。就在当前页面,把地址栏的地址变为任意一个详情页的地址。
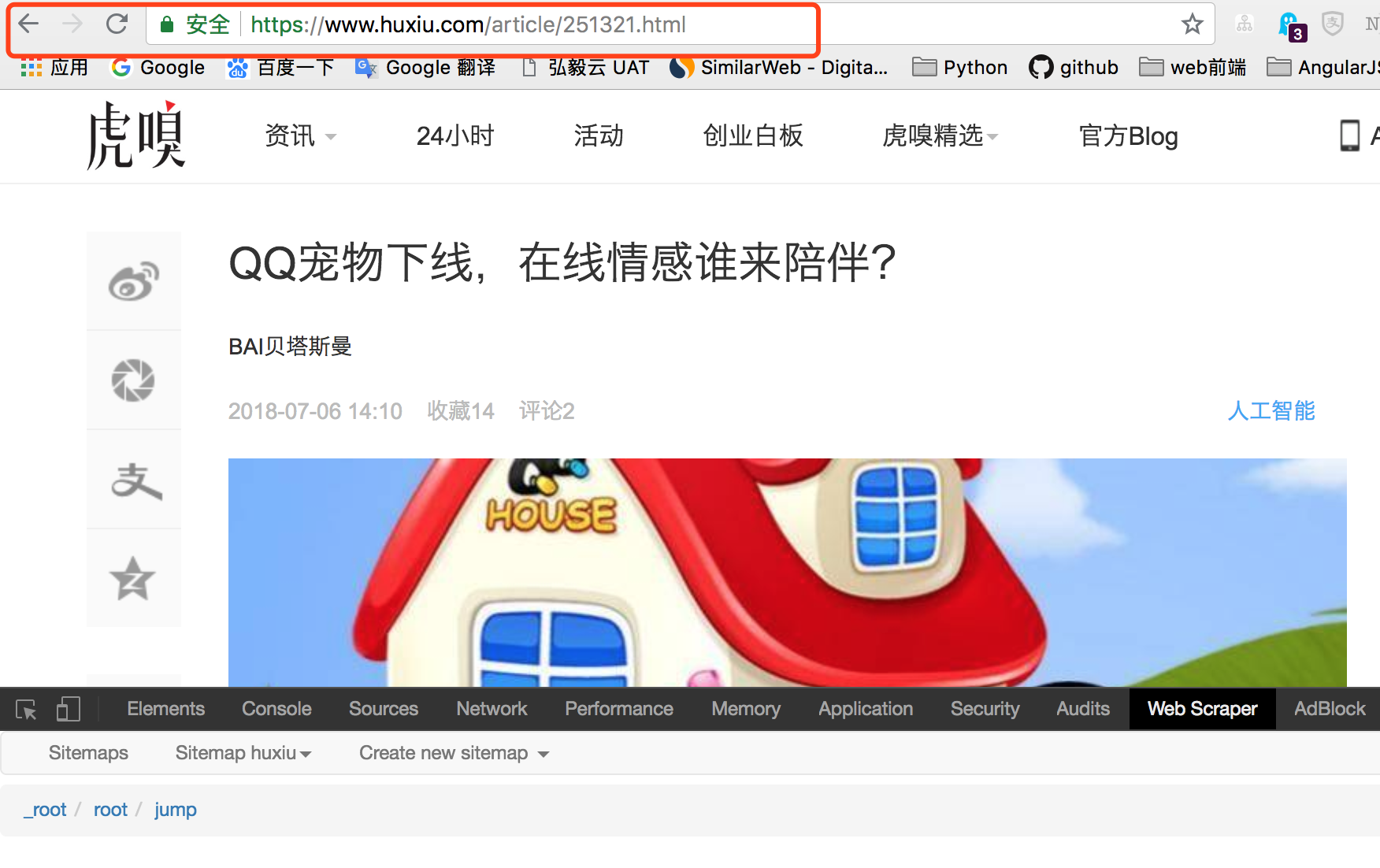
7、继续 Add new selector ,输入Id,类型选择 text 即可,点击 select ,选择日期部分,最后保存。如果需要其他信息,依次添加 selector 即可。
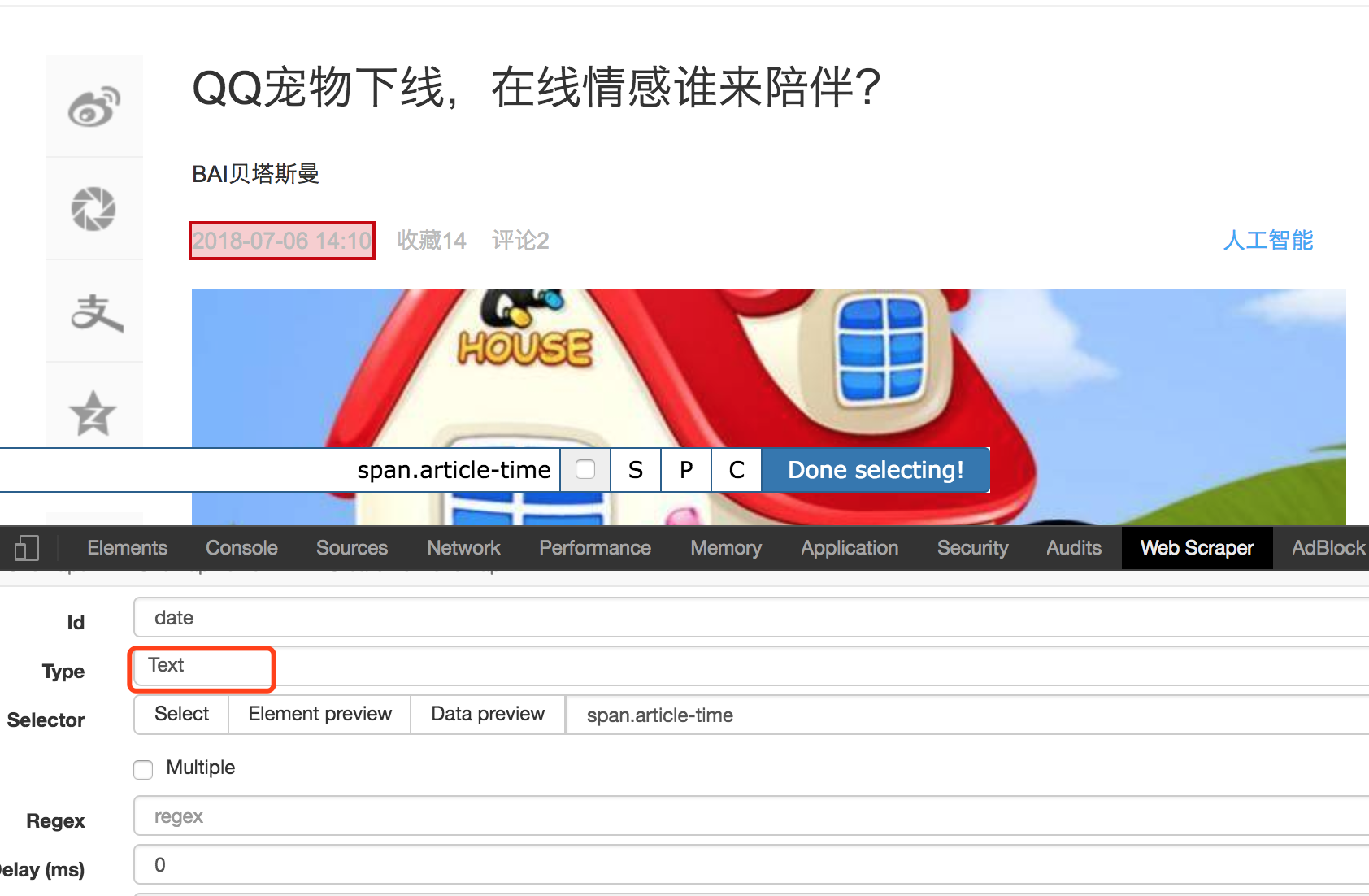
8、最后运行,抓出来的结果是这样的。

最后,关注公众号 古时的风筝 回复关键词 「二级页面」获取本例 sitemap

web scraper 抓取分页数据和二级页面内容的更多相关文章
- web scraper 抓取网页数据的几个常见问题
如果你想抓取数据,又懒得写代码了,可以试试 web scraper 抓取数据. 相关文章: 最简单的数据抓取教程,人人都用得上 web scraper 进阶教程,人人都用得上 如果你在使用 web s ...
- 简易数据分析 11 | Web Scraper 抓取表格数据
这是简易数据分析系列的第 11 篇文章. 今天我们讲讲如何抓取网页表格里的数据.首先我们分析一下,网页里的经典表格是怎么构成的. First Name 所在的行比较特殊,是一个表格的表头,表示信息分类 ...
- web scraper 抓取数据并做简单数据分析
其实 web scraper 说到底就是那点儿东西,所有的网站都是大同小异,但是都还不同.这也是好多同学总是遇到问题的原因.因为没有统一的模板可用,需要理解了 web scraper 的原理并且对目标 ...
- 简易数据分析 13 | Web Scraper 抓取二级页面
这是简易数据分析系列的第 13 篇文章. 不知不觉,web scraper 系列教程我已经写了 10 篇了,这 10 篇内容,基本上覆盖了 Web Scraper 大部分功能.今天的内容算这个系列的最 ...
- 简易数据分析 07 | Web Scraper 抓取多条内容
这是简易数据分析系列的第 7 篇文章. 在第 4 篇文章里,我讲解了如何抓取单个网页里的单类信息: 在第 5 篇文章里,我讲解了如何抓取多个网页里的单类信息: 今天我们要讲的是,如何抓取多个网页里的多 ...
- java抓取网页数据,登录之后抓取数据。
最近做了一个从网络上抓取数据的一个小程序.主要关于信贷方面,收集的一些黑名单网站,从该网站上抓取到自己系统中. 也找了一些资料,觉得没有一个很好的,全面的例子.因此在这里做个笔记提醒自己. 首先需要一 ...
- Fiddler:在PC和移动设备上抓取HTTPS数据包
Fiddler是一个免费的Web调试代理,支持任何浏览器.系统以及平台.这个工具是进行Web和App网络开发的必备工具,戳此处下载. 根据Fiddler官网的描述,具有以下六大特点: Web调试 性能 ...
- Fiddler基础用法-抓取浏览器数据包
Fiddler基础知识 Fiddler是强大的抓包工具,它的原理是以web代理服务器的形式进行工作的,使用的代理地址是:127.0.0.1,端口默认为8888,我们也可以通过设置进行修改. 代理就是在 ...
- Charles 如何抓取https数据包
Charles可以正常抓取http数据包,但是如果没有经过进一步设置的话,无法正常抓取https的数据包,通常会出现乱码.举个例子,如果没有做更多设置,Charles抓取https://www.bai ...
随机推荐
- PCB设计流程
一般PCB基本设计流程如下:前期准备->PCB结构设计->PCB布局->布线->布线优化和丝印->网络和DRC检查和结构检查->制版. 第一.前期准备. 这包括准备 ...
- validatebox相关验证
$(document).ready( function(){ $.extend($.fn.validatebox.defaults.rules, { minLength: { validator: f ...
- [Android]自己动手做个拼图游戏
目标 在做这个游戏之前,我们先定一些小目标列出来,一个一个的解决,这样,一个小游戏就不知不觉的完成啦.我们的目标如下: 游戏全屏,将图片拉伸成屏幕大小,并将其切成若干块. 将拼图块随机打乱,并保证其能 ...
- Linux上删除大量文件几种方式对比
目录 Linux上删除大量文件几种方式对比 1. rm删除:因为文件数量太多,rm无法删除(报错) 2. find查找删除:-exec 3. find查找删除:xargs 4. find调用-dele ...
- ssm框架搭建和整合流程
Spring + SpringMVC + Mybatis整合流程 1 需求 1.1 客户列表查询 1.2 根据客户姓名模糊查询 2 整合思路 第一步:整合dao层 ...
- itest 开源测试管理项目中封装的下拉列表小组件:实现下拉列表使用者前后端0行代码
导读: 主要从4个方面来阐述,1:背景:2:思路:3:代码实现:4:使用 一:封装背景 像easy ui 之类的纯前端组件,也有下拉列表组件,但是使用的时候,每个下拉列表,要配一个URL ...
- 什么是TensorBoard?
前言 只有光头才能变强. 文本已收录至我的GitHub仓库,欢迎Star:https://github.com/ZhongFuCheng3y/3y 回顾前面: 从零开始学TensorFlow[01-搭 ...
- 面试前必须要知道的Redis面试题
前言 只有光头才能变强. 文本已收录至我的GitHub仓库,欢迎Star:https://github.com/ZhongFuCheng3y/3y 回顾前面: 从零单排学Redis[青铜] 从零单排学 ...
- pfSense配置基于时间的防火墙规则
基于时间的规则允许防火墙规则在指定的日期和/或时间范围内激活.基于时间的规则与任何其他规则的功能相同,只是它们在预定时间之外的规则集中实际上不存在. 基于时间的规则逻辑处理基于时间的规则时,调度计划确 ...
- [目录]搭建一个简单的WebGIS应用程序
“如果一件事情超过自己的能力,自己很难达到,那就像是婴儿跳高,不但没有好处,反而拔苗助长”. 4月份时报名参加了2018年ESRI杯GIS应用开发比赛,到前几天提交了作品.作品很简单,没有那么多复杂深 ...