(python功能定制)复杂的xml文件对比,产生HTML展示区别
功能的设计初衷:
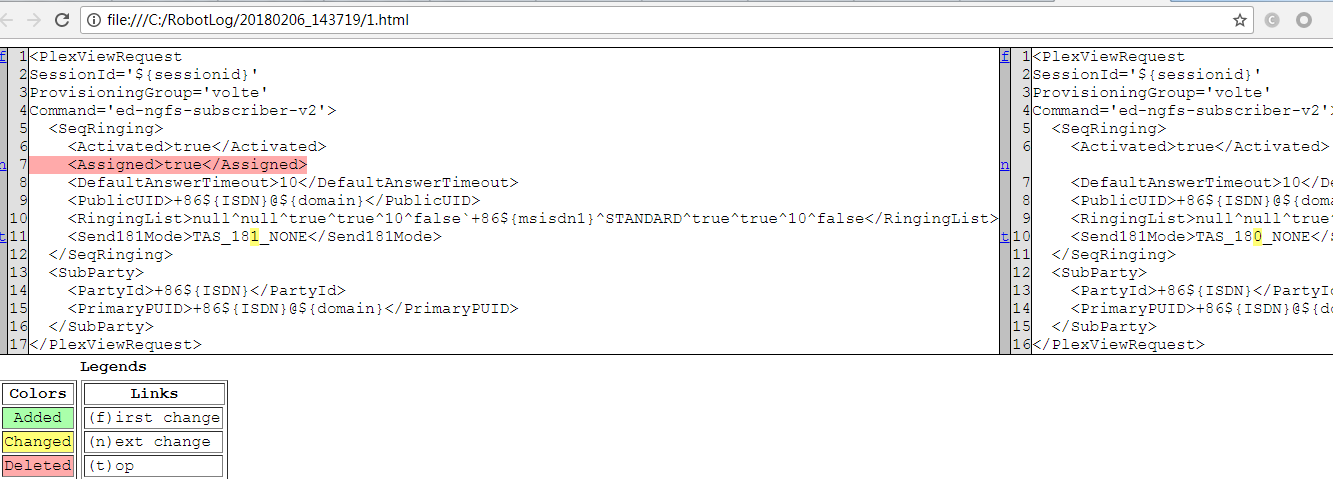
处理复杂的xml对比,屏蔽同节点先后顺序的影响
主要涉及知识点:
1、ElementTree库 ------- xml解析:
- 导入ElementTree,
import xml.etree.ElementTree as ET - 解析Xml文件找到根节点:
- 直接解析XML文件并获得根节点,
tree = ET.parse('country_data.xml') root = tree.getroot() - 解析字符串,
root = ET.fromstring(country_data_as_string) - 遍历根节点可以获得子节点,然后就可以根据需求拿到需要的字段了,如:<APP_KEY channel = 'CSDN'> hello123456789 </APP_KEY>
- 导入ElementTree,
- tag,即标签,用于标识该元素表示哪种数据,即APP_KEY
- attrib,即属性,用Dictionary形式保存,即{'channel' = 'CSDN'}
- text,文本字符串,可以用来存储一些数据,即hello123456789
- tail,尾字符串,并不是必须的,例子中没有包含。
2、difflib库 ------- 提供的类和方法用来进行序列的差异化比较,它能够比对文件并生成差异结果文本或者html格式的差异化比较页面
这里使用了类difflib.HtmlDiff,用来创建一个html表格展示文件差异,他既可以进行全文本展示,也可以只展示上下文不同。
其构造函数如下:
__init__(tabsize=8, wrapcolumn=None, linejunk=None, charjunk=IS_CHARACTER_JUNK)
- tabsize表示制表符代表的空格个数,默认为8
- wrapcolumn,可选参数,用来设置多少个字符时自动换行,默认None,为None时表示不自动换行(重点:可以让html显示更美观)
- linejunk 和 charjunk,可选参数,在ndiff()中使用,
公共方法(生成一个包含表格的html文件,其内容是用来展示差异):
make_file(fromlines, tolines [, fromdesc][, todesc][, context][, numlines])
- fromlines 和tolines,用于比较的内容,格式为字符串组成的列表
- fromdesc 和 todesc,可选参数,对应的fromlines,tolines的差异化文件的标题,默认为空字符串
- context 和 numlines,可选参数,context 为True时,只显示差异的上下文,为false,显示全文,numlines默认为5,当context为True时,控制展示上下文的行数,当context为false时,控制不同差异的高亮之间移动时“next”的开始位置(如果设置为0,当移动懂顶端时,超链接会丢失引用地址)
3、platform库 -------- 获取当前系统
4、logger库 -------- 如果使用robot framework,可以看到明显区别,可以定制日志log显示
robot framework的体验还不错,大概是因为其测试报告已经可以满足正常需要,很少有人会想去修改或者增加自己想要展示的内容,比如增加一个超链接,展示更多的内容,所以这部分花了很长时间均没有在网上找到相关资料,最后只能阅读源码。
遗憾与待优化:
其中有一部分内容,原先准备采用自循环的方式处理,但是过程中的数据传输逻辑容易错乱,以后会考虑把这部分优化一下。
##############################以下是代码部分,附件文件可以拖到本地执行并查看结果##################################################
# coding=utf-8
import re
import xml.etree.ElementTree as ET #解析xml的库
import difflib #文件对比库
import datetime #时间库
import platform #获取系统的库window、linux...
import os
from robot.api import logger #不需要的话可以注释掉:robot framework框架脚本运行时会产生日志,可以利用这个库定制log # listafter:将解析后的xml,转换成按序排列的list:(tag,attrib,(tag,attrib,text))
# 此方法是被下面一个方法xmltolist()调用的,想知道具体结果,可以使用下面的方法打印解析后的结果
def listafter(listcom1):
listcomarr1 = []
text1 = []
listcomarr1.append(listcom1.tag)
listcomarr1.append(listcom1.attrib)
if len(listcom1) > 0:
for listcom2 in listcom1:
listcomarr2 = []
text2 = []
listcomarr2.append(listcom2.tag)
listcomarr2.append(listcom2.attrib)
if len(listcom2) > 0:
for listcom3 in listcom2:
listcomarr3 = []
text3 = []
listcomarr3.append(listcom3.tag)
listcomarr3.append(listcom3.attrib)
if len(listcom3) > 0:
for listcom4 in listcom3:
listcomarr4 = []
text4 = []
listcomarr4.append(listcom4.tag)
listcomarr4.append(listcom4.attrib)
if len(listcom4) > 0:
for listcom5 in listcom4:
listcomarr5 = []
text5 = []
listcomarr5.append(listcom5.tag)
listcomarr5.append(listcom5.attrib)
if len(listcom5) > 0:
for listcom6 in listcom5:
listcomarr6 = []
text6 = []
listcomarr6.append(listcom6.tag)
listcomarr6.append(listcom6.attrib)
if len(listcom6) > 0:
for listcom7 in listcom6:
listcomarr7 = []
text7 = []
listcomarr7.append(listcom7.tag)
listcomarr7.append(listcom7.attrib)
if len(listcom7) > 0:
for listcom8 in listcom7:
listcomarr8 = []
text8 = []
listcomarr8.append(listcom8.tag)
listcomarr8.append(listcom8.attrib)
if len(listcom8) > 0:
for listcom9 in listcom8:
listcomarr9 = []
text9 = []
listcomarr9.append(listcom9.tag)
listcomarr9.append(listcom9.attrib)
# Start:判断是否需要继续递归
if len(listcom9) > 0:
for listcom10 in listcom9:
listcomarr10 = []
text10 = []
listcomarr10.append(listcom10.tag)
listcomarr10.append(listcom10.attrib)
listcomarr10.append([listcom10.text])
text9.append(listcomarr10)
else:
text9.append(listcom9.text)
# End:判断是否需要继续递归
# list二维数组排序
text9 = sorted(text9)
listcomarr9.append(text9)
text8.append(listcomarr9)
else:
text8.append(listcom8.text)
text8 = sorted(text8)
listcomarr8.append(text8)
text7.append(listcomarr8)
else:
text7.append(listcom7.text)
text7 = sorted(text7)
listcomarr7.append(text7)
text6.append(listcomarr7)
else:
text6.append(listcom6.text)
text6 = sorted(text6)
listcomarr6.append(text6)
text5.append(listcomarr6)
else:
text5.append(listcom5.text)
text5 = sorted(text5)
listcomarr5.append(text5)
text4.append(listcomarr5)
else:
text4.append(listcom4.text)
text4 = sorted(text4)
listcomarr4.append(text4)
text3.append(listcomarr4)
else:
text3.append(listcom3.text)
text3 = sorted(text3)
listcomarr3.append(text3)
text2.append(listcomarr3)
else:
text2.append(listcom2.text)
text2 = sorted(text2)
listcomarr2.append(text2)
text1.append(listcomarr2)
else:
text1.append(listcom1.text)
text1 = sorted(text1)
listcomarr1.append(text1)
return listcomarr1 # 将xml内容转换成按序排列的list,返回值有3个:处理后的spmlxmllist、不需要处理的头部spmlstart、不需要处理的尾部spmlend
# spmlstart、spmlend是为了控制不需要处理的头部和尾部,提高处理效率
def xmltolist(spml):
if spml.find("<spml:") != -1:
startnum = re.search(r'<spml:[^>]*>', spml).span()[1]
endnum = spml.rfind("</spml:")
spmlstart = spml[:startnum].strip()
spmlend = spml[endnum:].strip()
spmlxml = '''<spml:modifyRequest xmlns:spml='{spml}' xmlns:subscriber="{subscriber}" xmlns:xsi="{xsi}">\n%s</spml:modifyRequest>''' % (
spml[startnum:endnum].strip())
elif spml.find("<PlexViewRequest") != -1:
startnum = re.search(r'<PlexViewRequest[^>]*>', spml).span()[1]
endnum = spml.rfind("</PlexViewRequest>")
spmlstart = spml[:startnum].strip()
spmlend = spml[endnum:].strip()
spmlxml = '''<PlexViewRequest>\n%s</PlexViewRequest>''' % (spml[startnum:endnum].strip())
else:
spmlstart = ""
spmlend = ""
spmlxml = spml
# print spmlstart
# print endspml
# print spmlxml
tree = ET.fromstring(spmlxml)
spmlxmllist = listafter(tree)
return spmlxmllist, spmlstart, spmlend # 将xmltolist处理形成的spmlxmllist再回头变成xml(xml中,同节点的内容已被按需排列)
def listtoxml(spmllist1):
kong = " "
spmltag1 = spmllist1[0]
spmlattrib1 = ""
bodyxml1 = ""
if spmllist1[1] != {}:
for key, value in spmllist1[1].items():
spmlattrib1 += " %s='%s'" % (key, value)
startxml1 = "<%s%s>" % (spmltag1, spmlattrib1)
endxml1 = "</%s>" % (spmltag1)
spmlxml1 = ""
if isinstance(spmllist1[2][0], list):
spmlxml2 = ""
for spmllist2 in spmllist1[2]:
spmltag2 = spmllist2[0]
spmlattrib2 = ""
bodyxml2 = ""
if spmllist2[1] != {}:
for key, value in spmllist2[1].items():
spmlattrib2 += " %s='%s'" % (key, value)
startxml2 = "<%s%s>" % (spmltag2, spmlattrib2)
endxml2 = "</%s>" % (spmltag2)
if isinstance(spmllist2[2][0], list):
spmlxml3 = ""
for spmllist3 in spmllist2[2]:
spmltag3 = spmllist3[0]
spmlattrib3 = ""
bodyxml3 = ""
if spmllist3[1] != {}:
for key, value in spmllist3[1].items():
spmlattrib3 += " %s='%s'" % (key, value)
startxml3 = "<%s%s>" % (spmltag3, spmlattrib3)
endxml3 = "</%s>" % (spmltag3)
if isinstance(spmllist3[2][0], list):
spmlxml4 = ""
for spmllist4 in spmllist3[2]:
spmltag4 = spmllist4[0]
spmlattrib4 = ""
bodyxml4 = ""
if spmllist4[1] != {}:
for key, value in spmllist4[1].items():
spmlattrib4 += " %s='%s'" % (key, value)
startxml4 = "<%s%s>" % (spmltag4, spmlattrib4)
endxml4 = "</%s>" % (spmltag4)
if isinstance(spmllist4[2][0], list):
spmlxml5 = ""
for spmllist5 in spmllist4[2]:
spmltag5 = spmllist5[0]
spmlattrib5 = ""
bodyxml5 = ""
if spmllist5[1] != {}:
for key, value in spmllist5[1].items():
spmlattrib5 += " %s='%s'" % (key, value)
startxml5 = "<%s%s>" % (spmltag5, spmlattrib5)
endxml5 = "</%s>" % (spmltag5)
if isinstance(spmllist5[2][0], list):
spmlxml6 = ""
for spmllist6 in spmllist5[2]:
spmltag6 = spmllist6[0]
spmlattrib6 = ""
bodyxml6 = ""
if spmllist6[1] != {}:
for key, value in spmllist6[1].items():
spmlattrib6 += " %s='%s'" % (key, value)
startxml6 = "<%s%s>" % (spmltag6, spmlattrib6)
endxml6 = "</%s>" % (spmltag6)
if isinstance(spmllist6[2][0], list):
spmlxml7 = ""
for spmllist7 in spmllist6[2]:
spmltag7 = spmllist7[0]
spmlattrib7 = ""
bodyxml7 = ""
if spmllist7[1] != {}:
for key, value in spmllist7[1].items():
spmlattrib7 += " %s='%s'" % (key, value)
startxml7 = "<%s%s>" % (spmltag7, spmlattrib7)
endxml7 = "</%s>" % (spmltag7)
if isinstance(spmllist7[2][0], list):
spmlxml8 = ""
for spmllist8 in spmllist7[2]:
spmltag8 = spmllist8[0]
spmlattrib8 = ""
bodyxml8 = ""
if spmllist8[1] != {}:
for key, value in spmllist8[1].items():
spmlattrib8 += " %s='%s'" % (key, value)
startxml8 = "<%s%s>" % (spmltag8, spmlattrib8)
endxml8 = "</%s>" % (spmltag8)
if isinstance(spmllist8[2][0], list):
spmlxml9 = ""
for spmllist9 in spmllist8[2]:
spmltag9 = spmllist9[0]
spmlattrib9 = ""
bodyxml9 = ""
if spmllist9[1] != {}:
for key, value in spmllist9[1].items():
spmlattrib9 += " %s='%s'" % (key, value)
startxml9 = "<%s%s>" % (spmltag9, spmlattrib9)
endxml9 = "</%s>" % (spmltag9)
if isinstance(spmllist9[2][0], list):
spmlxml10 = ""
for spmllist10 in spmllist9[2]:
spmltag10 = spmllist10[0]
spmlattrib10 = ""
bodyxml10 = ""
if spmllist10[1] != {}:
for key, value in spmllist10[1].items():
spmlattrib10 += " %s='%s'" % (
key, value)
startxml10 = "<%s%s>" % (
spmltag10, spmlattrib10)
endxml10 = "</%s>" % (spmltag10)
bodyxml10 = spmllist10[2][0]
spmlxml10 += "\n%s%s%s%s" % (
kong * 9, startxml10, bodyxml10,
endxml10)
spmlxml9 += "\n%s%s%s\n%s%s" % (
kong * 8, startxml9, spmlxml10, kong * 8,
endxml9)
else:
bodyxml9 = spmllist9[2][0]
spmlxml9 += "\n%s%s%s%s" % (
kong * 8, startxml9, bodyxml9, endxml9)
spmlxml8 += "\n%s%s%s\n%s%s" % (
kong * 7, startxml8, spmlxml9, kong * 7, endxml8)
else:
bodyxml8 = spmllist8[2][0]
spmlxml8 += "\n%s%s%s%s" % (
kong * 7, startxml8, bodyxml8, endxml8)
spmlxml7 += "\n%s%s%s\n%s%s" % (
kong * 6, startxml7, spmlxml8, kong * 6, endxml7)
else:
bodyxml7 = spmllist7[2][0]
spmlxml7 += "\n%s%s%s%s" % (
kong * 6, startxml7, bodyxml7, endxml7)
spmlxml6 += "\n%s%s%s\n%s%s" % (
kong * 5, startxml6, spmlxml7, kong * 5, endxml6)
else:
bodyxml6 = spmllist6[2][0]
spmlxml6 += "\n%s%s%s%s" % (kong * 5, startxml6, bodyxml6, endxml6)
spmlxml5 += "\n%s%s%s\n%s%s" % (
kong * 4, startxml5, spmlxml6, kong * 4, endxml5)
else:
bodyxml5 = spmllist5[2][0]
spmlxml5 += "\n%s%s%s%s" % (kong * 4, startxml5, bodyxml5, endxml5)
spmlxml4 += "\n%s%s%s\n%s%s" % (kong * 3, startxml4, spmlxml5, kong * 3, endxml4)
else:
bodyxml4 = spmllist4[2][0]
spmlxml4 += "\n%s%s%s%s" % (kong * 3, startxml4, bodyxml4, endxml4)
spmlxml3 += "\n%s%s%s\n%s%s" % (kong * 2, startxml3, spmlxml4, kong * 2, endxml3)
else:
bodyxml3 = spmllist3[2][0]
spmlxml3 += "\n%s%s%s%s" % (kong * 2, startxml3, bodyxml3, endxml3)
spmlxml2 += "\n%s%s%s\n%s%s" % (kong * 1, startxml2, spmlxml3, kong * 1, endxml2)
else:
bodyxml2 = spmllist2[2][0]
spmlxml2 += "\n%s%s%s%s" % (kong * 1, startxml2, bodyxml2, endxml2)
spmlxml1 += "\n%s%s\n%s" % (startxml1, spmlxml2, endxml1)
else:
bodyxml1 = spmllist1[2][0]
spmlxml1 += "\n%s%s%s" % (startxml1, bodyxml1, endxml1)
return spmlxml1 # 将startspml, xmlspml, endspml组合起来,其中有一部分内容需要根据实际情况处理
def regroupspml(startspml, xmlspml, endspml):
xmlspml = str(xmlspml).replace("{{", "").replace("}}", ":").strip().splitlines()
if endspml != "":
startspml = str(startspml.strip()).replace("\"", "\'")
startspml = re.sub(" +>", ">", startspml)
startspml = startspml.splitlines()
endspml = str(endspml.strip()).splitlines()
spmlxmlcom = startspml + xmlspml[1:-1] + endspml
else:
spmlxmlcom = xmlspml
return spmlxmlcom # 对按序排列的xml进行内容比对,生成html文件,可以很直接的看出内容区别
def diffspml(spmlxml1, spmlxml2):
spmlxmllist1, spmlstart1, spmlend1 = xmltolist(spmlxml1)
spmlxmllist2, spmlstart2, spmlend2 = xmltolist(spmlxml2)
spmlxmlcom1 = listtoxml(spmlxmllist1)
spmlxmlcom2 = listtoxml(spmlxmllist2)
spmlxmlcom1 = regroupspml(spmlstart1, spmlxmlcom1, spmlend1)
spmlxmlcom2 = regroupspml(spmlstart2, spmlxmlcom2, spmlend2)
# print spmlstart1
# print spmlend1
if spmlxmlcom1 == spmlxmlcom2:
return 0
else:
global diffspmNum
global outputhtml_dir
try:
diffspmNum += 1
except:
diffspmNum = 1
system = platform.system()
if ('Windows' in system):
outputhtml_dir = "c:/RobotLog"
else:
outputhtml_dir = "/tmp/RobotLog"
outputhtml_dir = "%s/%s" % (outputhtml_dir, datetime.datetime.now().strftime('%Y%m%d_%H%M%S'))
os.makedirs(outputhtml_dir)
Loghtmldir = "%s/%s.html" % (outputhtml_dir, diffspmNum)
# logger.write("<a href=\"%s\">%s</a>" % (Loghtmldir, Loghtmldir), "HTML")
hd = difflib.HtmlDiff(8,65)
with open(Loghtmldir, 'w') as fo:
fo.write(hd.make_file(spmlxmlcom1, spmlxmlcom2))
fo.close()
return Loghtmldir
#############################################以上是代码部分#################################################################
spmlxml1='''
<PlexViewRequest SessionId="${sessionid}" ProvisioningGroup="volte" Command="ed-ngfs-subscriber-v2"><SubParty><PrimaryPUID>+86${ISDN}@${domain}</PrimaryPUID><PartyId>+86${ISDN}</PartyId></SubParty><SeqRinging><RingingList>null^null^true^true^10^false`+86${msisdn1}^STANDARD^true^true^10^false</RingingList><DefaultAnswerTimeout>10</DefaultAnswerTimeout><Send181Mode>TAS_181_NONE</Send181Mode><Activated>true</Activated><PublicUID>+86${ISDN}@${domain}</PublicUID><Assigned>true</Assigned></SeqRinging></PlexViewRequest>
'''
spmlxml2='''
<PlexViewRequest SessionId="${sessionid}" ProvisioningGroup="volte" Command="ed-ngfs-subscriber-v2">
<SubParty>
<PrimaryPUID>+86${ISDN}@${domain}</PrimaryPUID>
<PartyId>+86${ISDN}</PartyId>
</SubParty>
<SeqRinging>
<RingingList>null^null^true^true^10^false`+86${msisdn1}^STANDARD^true^true^10^false</RingingList>
<DefaultAnswerTimeout>10</DefaultAnswerTimeout>
<Send181Mode>TAS_180_NONE</Send181Mode>
<Activated>true</Activated>
<PublicUID>+86${ISDN}@${domain}</PublicUID>
</SeqRinging>
</PlexViewRequest>
'''
print diffspml(spmlxml1, spmlxml2)
#####################################以上列出来了本公司使用的xml格式(还可以更复杂),方法中有部分内容是根据本身需要,特别处理的####################################
(python功能定制)复杂的xml文件对比,产生HTML展示区别的更多相关文章
- python中用ElementTree.iterparse()读取xml文件中的多层节点
我在使用Python解析比较大型的xml文件时,为了提高效率,决定使用iterparse()方法,但是发现根据网上的例子:每次if event == 'end':之后elem.clear()或者是每次 ...
- [python小记]使用lxml修改xml文件,并遍历目录
这次的目的是遍历目录,把目标文件及相应的目录信息更新到xml文件中.在经过痛苦的摸索之后,从python自带的ElementTree投奔向了lxml.而弃用自带的ElementTree的原因就是,na ...
- Python—使用xm.dom解析xml文件
什么是DOM? 文件对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展置标语言的标准编程接口. 一个 DOM 的解析器在解析一个 XML 文档时,一次性读 ...
- mybatis.xml文件中#与$符号的区别以及数学符号的处理
1.#{}表示一个占位符号,通过#{}可以实现preparedStatement向占位符中设置值,自动进行java类型和jdbc类型转换,#{}可以有效防止sql注入. #{}可以接收简单类型值或po ...
- python文件目录遍历保存成xml文件代码
Linux服务器有CentOS.Fedora等,都预先安装了Python,版本从2.4到2.5不等,而Windows类型的服务器也多数安装了Python,因此只要在本机写好一个脚本,上传到对应机器,在 ...
- python自定义模块导入方法,文件夹,包的区别
python模块导入,网上介绍的资料很多,方法也众说纷纭.根据自己的实践,感觉这个方法最简单直接,而且可以与主流的python ide生成的工程是一样的. 规则只有三条 1. 严格区分包和文 ...
- WebAPI使用多个xml文件生成帮助文档
一.前言 上篇有提到在WebAPI项目内,通过在Nuget里安装(Microsoft.AspNet.WebApi.HelpPage)可以根据注释生成帮助文档,查看代码实现会发现是基于解析项目生成的xm ...
- WebAPI使用多个xml文件生成帮助文档(转)
http://www.cnblogs.com/idoudou/p/xmldocumentation-for-web-api-include-documentation-from-beyond-the- ...
- 【转】WebAPI使用多个xml文件生成帮助文档
来自:http://www.it165.net/pro/html/201505/42504.html 一.前言 上篇有提到在WebAPI项目内,通过在Nuget里安装(Microsoft.AspNet ...
随机推荐
- 转:C++与JAVA语言区别
转自:http://club.topsage.com/thread-265349-1-1.html Java并不仅仅是C++语言的一个变种,它们在某些本质问题上有根本的不同: (1)Java比C++程 ...
- destoon框架二次开发【整理】
=========================================================== destoon使用中的一些心得 ====================== ...
- MYsql优化where子句
该部分讨论where子句的优化,不仅select之中,相同的优化同样试用与delete 和update语句中的where子句: 1: 移去不必要的括号: ((a AND b) AND c OR ((( ...
- python判断两个list包含关系
a = [1,2] b = [1,2,3] c = [0, 1] set(b) > set(a) set(b) > set(c)
- 腾讯工程师带你深入解析 MySQL binlog
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 本文由 腾讯云数据库内核团队 发布在云+社区 1.概述 binlog是Mysql sever层维护的一种二进制日志,与innodb引擎中的red ...
- Asp.net core 2.0.1 Razor 的使用学习笔记(三)
ASP.net core 2.0.0 中 asp.net identity 2.0.0 的基本使用(二)—用户账户及cookie配置 修改用户账户及cookie配置 一.修改密码强度和用户邮箱验证规则 ...
- iOS 组件化 —— 路由设计思路分析
原文 前言 随着用户的需求越来越多,对App的用户体验也变的要求越来越高.为了更好的应对各种需求,开发人员从软件工程的角度,将App架构由原来简单的MVC变成MVVM,VIPER等复杂架构.更换适合业 ...
- 【转】nagios使用带url的check_http检测主机
前一段时间在Cu论坛发现一个提问,问题是nagios关于检测主机http服务的.原帖地址http://bbs.chinaunix.net /forum.php?mod=viewthread&t ...
- 关于Linux的常忘命令积累
1.在vim中显示行号 在/etc/vimrc里加上一行 set nu! 2./etc/sysconfig/network-scripts/ifcfg-eth0 (DNS1=192.168.1 ...
- OSSEC初探
OSSEC初探 概念: OSSEC是一款开源的基于主机的入侵检测系统(HIDS),它可以执行日志分析.完整性检验.windows注册表监控.隐匿性检测和实时告警.它可以运行在各种不同的操作系统上,包括 ...