吴恩达深度学习笔记(deeplearning.ai)之卷积神经网络(一)
Padding
在卷积操作中,过滤器(又称核)的大小通常为奇数,如3x3,5x5。这样的好处有两点:
在特征图(二维卷积)中就会存在一个中心像素点。有一个中心像素点会十分方便,便于指出过滤器的位置。
- 在没有padding的情况下,经过卷积操作,输出的数据维度会减少。以二维卷积为例,输入大小 \(n\times n\),过滤器大小\(f\times f\),卷积后输出的大小为\((n-f+1)\times(n-f+1)\)。
- 为了避免这种情况发生,可以采取padding操作,padding的长度为\(p\),由于在二维情况下,上下左右都“添加”长度为\(p\)的数据。构造新的输入大小为\((n+2p)\times(n+2p)\) , 卷积后的输出变为\((n+2p-f+1)\times(n+2p-f+1)\)。
如果想使卷积操作不缩减数据的维度,那么\(p\)的大小应为\((f-1)/2\),其中\(f\)是过滤器的大小,该值如果为奇数,会在原始数据上对称padding,否则,就会出现向上padding 1个,向下padding 2个,向左padding 1个,向右padding 2个的情况,破坏原始数据结构。
Stride
卷积中的步长大小为\(s\),指过滤器在输入数据上,水平/竖直方向上每次移动的步长,在Padding 公式的基础上,最终卷积输出的维度大小为:
\[\left \lfloor \frac{n+2p-f}{s}+1 \right \rfloor \times \left \lfloor \frac{n+2p-f}{s}+1 \right \rfloor\]
\(\left \lfloor \right\rfloor\)符号指向下取整,在python 中为floor地板除操作。
Channel
通道,通常指数据的最后一个维度(三维),在计算机视觉中,RGB代表着3个通道(channel)。
- 举例说明:现在有一张图片的大小为\(6\times 6\times 3\),过滤器的大小为\(3\times 3\times n_c\), 这里\(n_c\)指过滤器的channel大小,该数值必须与输入的channel大小相同,即\(n_c=3\)。
- 如果有\(k\)个\(3\times 3\times n_c\)的过滤器,那么卷积后的输出维度为\(4\times 4\times k\)。注意此时\(p=0, s=1\),\(k\)表示输出数据的channel大小。一般情况下,\(k\)代表\(k\)个过滤器提取的k个特征,如\(k=128\),代表128个\(3\times 3\)大小的过滤器,提取了128个特征,且卷积后的输出维度为\(4\times 4\times 128\)。
在多层卷积网络中,以计算机视觉为例,通常情况下,图像的长和宽会逐渐缩小,channel数量会逐渐增加。
Pooling
- 除了卷积层,卷积网络使用池化层来缩减数据的大小,提高计算的速度 ,同时提高所提取特征的鲁棒性。 池化操作不需要对参数进行学习,只是神经网络中的静态属性。
- 池化层中,数据的维度变化与卷积操作类似。池化后的channel数量与输入的channel数量相同,因为在每个channel上单独执行最大池化操作。
- f=2, s=2,相当于对数据维度的减半操作,f指池化层过滤器大小,s指池化步长。
卷积神经网络示例
一个用于手写数字识别的CNN结构如下图所示:
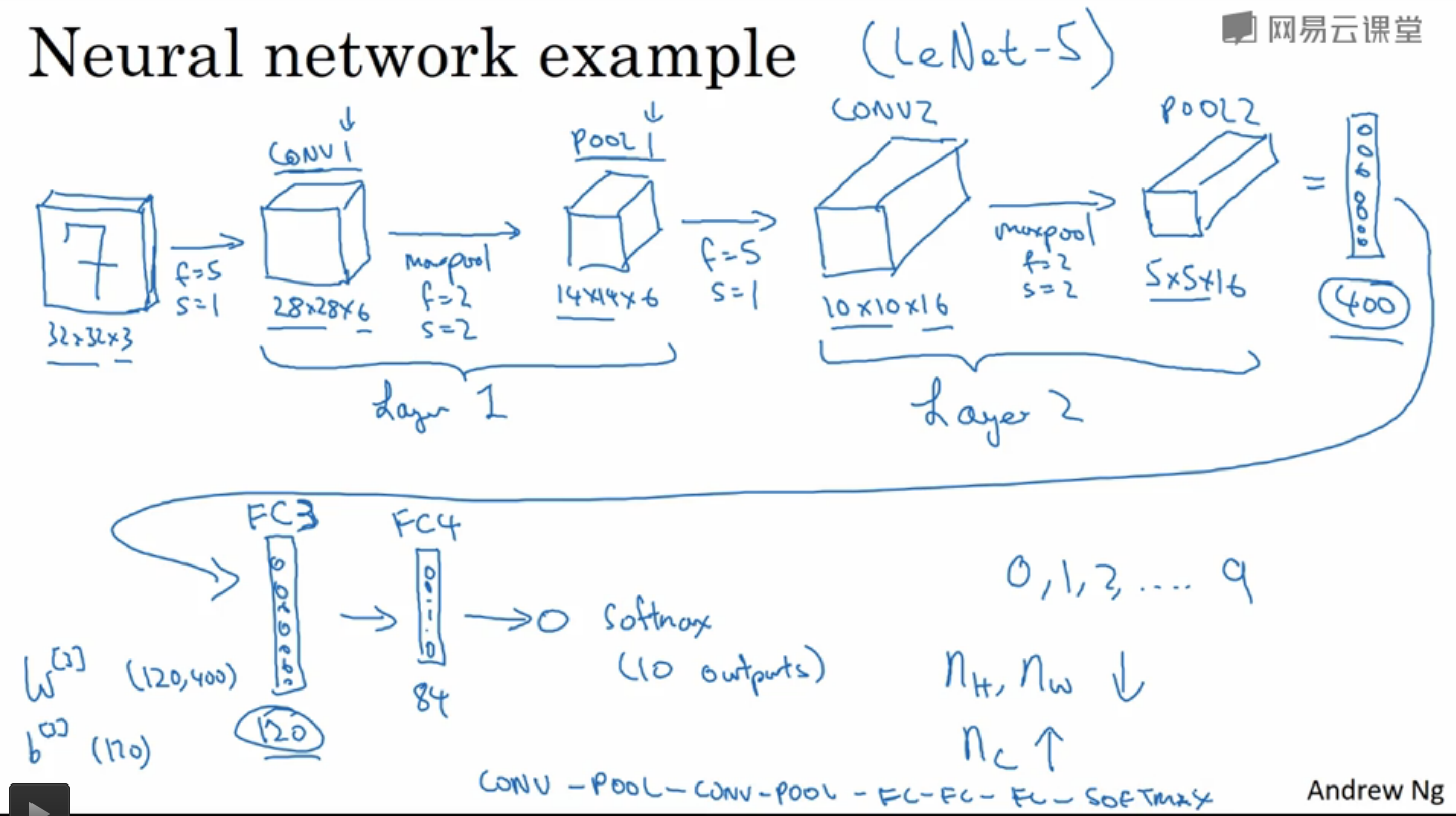
该网络应用了两层卷积,并且在第二个池化层之后又接了几个全连接层,这样做的目的是避免某一层的激活值数量减少的太快,具体原因后文解释。
具体参数数量可视化如下所示:
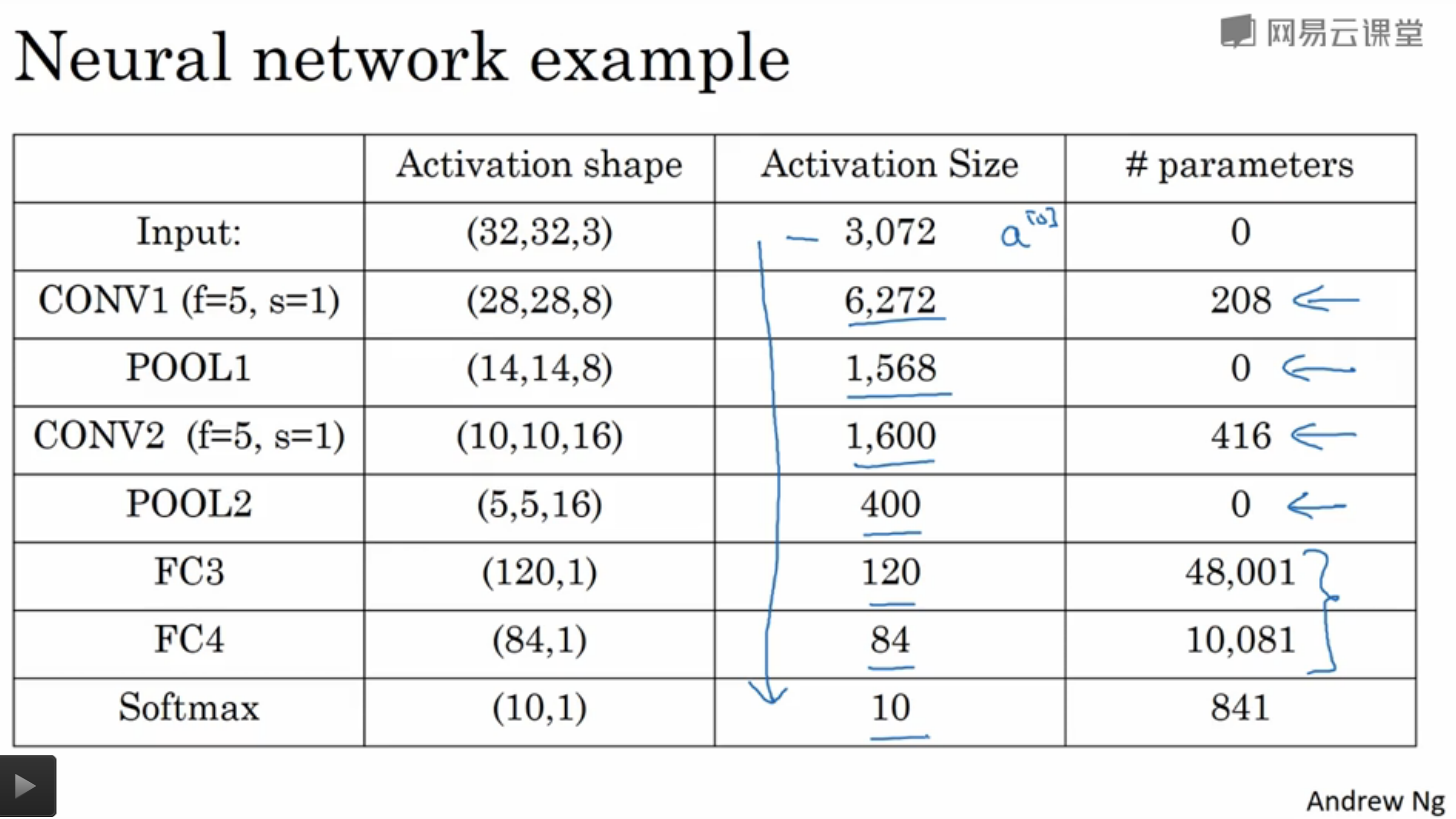
从图中可以发现,卷积层的参数数量较小,大部分参数集中在全连接层。而且随着网络层的加深,激活值数量逐渐减少,如果激活值数量下降太快,会影响网络的性能。因此需要构建多个全连接层,而不是一个全连接层一步到位。
卷积层的好处
与只用全连接层相比,卷积层的主要优点是参数共享和稀疏连接,这使得卷积操作所需要学习的参数数量大大减少。
吴恩达深度学习笔记(deeplearning.ai)之卷积神经网络(一)的更多相关文章
- 【Deeplearning.ai 】吴恩达深度学习笔记及课后作业目录
吴恩达深度学习课程的课堂笔记以及课后作业 代码下载:https://github.com/douzujun/Deep-Learning-Coursera 吴恩达推荐笔记:https://mp.weix ...
- 吴恩达深度学习笔记(deeplearning.ai)之卷积神经网络(CNN)(上)
作者:szx_spark 1. Padding 在卷积操作中,过滤器(又称核)的大小通常为奇数,如3x3,5x5.这样的好处有两点: 在特征图(二维卷积)中就会存在一个中心像素点.有一个中心像素点会十 ...
- 吴恩达深度学习笔记(deeplearning.ai)之卷积神经网络(二)
经典网络 LeNet-5 AlexNet VGG Ng介绍了上述三个在计算机视觉中的经典网络.网络深度逐渐增加,训练的参数数量也骤增.AlexNet大约6000万参数,VGG大约上亿参数. 从中我们可 ...
- 吴恩达深度学习笔记(deeplearning.ai)之循环神经网络(RNN)(三)
1. 导读 本节内容介绍普通RNN的弊端,从而引入各种变体RNN,主要讲述GRU与LSTM的工作原理. 事先声明,本人采用ng在课堂上所使用的符号系统,与某些学术文献上的命名有所不同,不过核心思想都是 ...
- 吴恩达深度学习笔记(八) —— ResNets残差网络
(很好的博客:残差网络ResNet笔记) 主要内容: 一.深层神经网络的优点和缺陷 二.残差网络的引入 三.残差网络的可行性 四.identity block 和 convolutional bloc ...
- 吴恩达深度学习笔记(十二)—— Batch Normalization
主要内容: 一.Normalizing activations in a network 二.Fitting Batch Norm in a neural network 三.Why does ...
- 吴恩达深度学习笔记(七) —— Batch Normalization
主要内容: 一.Batch Norm简介 二.归一化网络的激活函数 三.Batch Norm拟合进神经网络 四.测试时的Batch Norm 一.Batch Norm简介 1.在机器学习中,我们一般会 ...
- 吴恩达深度学习笔记1-神经网络的编程基础(Basics of Neural Network programming)
一:二分类(Binary Classification) 逻辑回归是一个用于二分类(binary classification)的算法.在二分类问题中,我们的目标就是习得一个分类器,它以对象的特征向量 ...
- 吴恩达深度学习笔记(十一)—— dropout正则化
主要内容: 一.dropout正则化的思想 二.dropout算法流程 三.dropout的优缺点 一.dropout正则化的思想 在神经网络中,dropout是一种“玄学”的正则化方法,以减少过拟合 ...
随机推荐
- Codeforces Round #345(Div. 2)-651A.水题 651B.。。。 651C.去重操作 真是让人头大
A. Joysticks time limit per test 1 second memory limit per test 256 megabytes input standard input o ...
- Graph(Floyd)
http://acm.hdu.edu.cn/showproblem.php?pid=4034 Graph Time Limit: 2000/1000 MS (Java/Others) Memor ...
- JDBC连接数据库(查询)的步骤
先导入jar包 代码: import java.sql.Connection;import java.sql.DriverManager;import java.sql.ResultSet;impor ...
- TypeScript装饰器(decorators)
装饰器是一种特殊类型的声明,它能够被附加到类声明,方法, 访问符,属性或参数上,可以修改类的行为. 装饰器使用 @expression这种形式,expression求值后必须为一个函数,它会在运行时被 ...
- 基于VUE选择上传图片并在页面显示(图片可删除)
demo例子: 依赖文件 : http://files.cnblogs.com/files/zhengweijie/jquery.form.rar HTML文本内容: <template> ...
- ADO.NET复习总结(5)--工具类SqlHelper 实现登录
工具类SqlHelper 即:完成常用数据库操作的代码封装 一.基础知识1.每次进行操作时,不变的代码: (1)连接字符串:(2)往集合存值:(3)创建连接对象.命令对象:(4)打开连接:(5)执行命 ...
- P2P视频模块
P2P视频模块数据手册 公 司 : 深圳市万秀电子有限公司 网 站 : http://www.wanxiucx.com 总 机 : 0755-23215689 联系人: 张先生 手 机 : 1 ...
- PostgreSql问题:ERROR: column "1" does not exist
摘录自:http://blog.csdn.net/shuaiwang/article/details/1807421 在PostgreSQL中,不论是在pgAdmin中还是在命令行控制台里面,在SQL ...
- python_如何去除字符串中不想要的字符?
问题: 过滤用户输入中前后多余的空白字符 ' ++++abc123--- ' 过滤某windows下编辑文本中的'\r': 'hello world \r\n' 去掉文本中unicode组 ...
- Map排序与有序
排序: private static List<Map.Entry<String, Long>> sortHashMap(HashMap<String,Long> ...