Java 的字节流文件读取(一)
上篇文章我们介绍了抽象化磁盘文件的 File 类型,它仅仅用于抽象化描述一个磁盘文件或目录,却不具备访问和修改一个文件内容的能力。
Java 的 IO 流就是用于读写文件内容的一种设计,它能完成将磁盘文件内容输出到内存或者是将内存数据输出到磁盘文件的数据传输工作。
Java IO 流的设计并不是完美的,设计了大量的类,增加了我们对于 IO 流的理解,但无外乎为两大类,一类是针对二进制文件的字节流,另一类是针对文本文件的字符流。而本篇我们就先来学习有关字节流的相关类型的原理以及使用场景等细节,主要涉及的具体流类型如下:
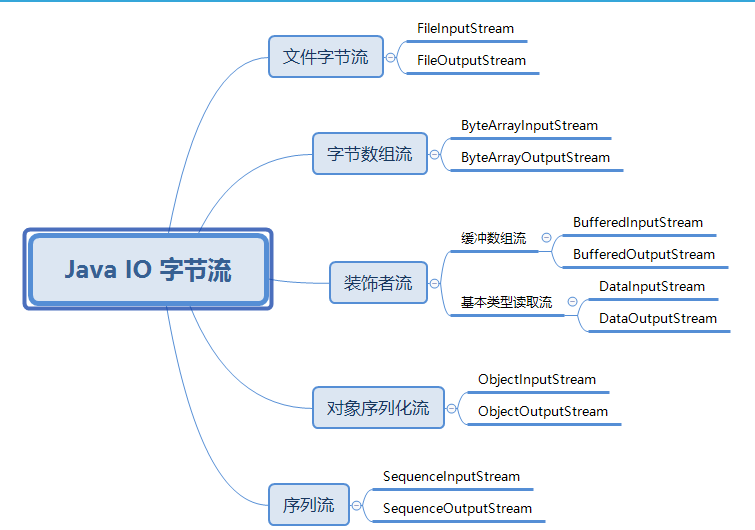
基类字节流 Input/OutputStream
InputStream 和 OutputStream 分别作为读字节流和写字节流的基类,所有字节相关的流都必然继承自他们中任意一个,而它们本身作为一个抽象类,也定义了最基本的读写操作,我们一起来看看:
以 InputStream 为例:
public abstract int read() throws IOException;
这是一个抽象的方法,并没有提供默认实现,要求子类必须实现。而这个方法的作用就是为你返回当前文件的下一个字节。
当然,你也会发现这个方法的返回值是使用的整型类型「int」来接收的,为什么不用「byte」?
首先,read 方法返回的值一定是一个八位的二进制,而一个八位的二进制可以取值的值区间为:「0000 0000,1111 1111」,也就是范围 [-128,127]。
read 方法同时又规定当读取到文件的末尾,即文件没有下一个字节供读取了,将返回值 -1 。所以如果使用 byte 作为返回值类型,那么当方法返回一个 -1 ,我们该判定这是文件中数据内容,还是流的末尾呢?
而 int 类型占四个字节,高位的三个字节全部为 0,我们只使用它的最低位字节,当遇到流结尾标志时,返回四个字节表示的 -1(32 个 1),这就自然的和表示数据的值 -1(24 个 0 + 8 个 1)区别开来了。
接下来也是一个 read 方法,但是 InputStream 提供默认实现:
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}
public int read(byte b[], int off, int len) throws IOException{
//为了不使篇幅过长,方法体大家可自行查看 jdk 源码
}
这两个方法本质上是一样的,第一个方法是第二个方法的特殊形态,它允许传入一个字节数组,并要求程序将文件中读到的字节从数组索引位置 0 开始填充,供填充数组长度个字节数。
而第二个方法更加宽泛一点,它允许你指定起始位置和字节总数。
InputStream 中还有其他几个方法,基本都没怎么具体实现,留待子类实现,我们简单看看。
- public long skip(long n):跳过 n 个字节,返回实际跳过的字节数
- public void close():关闭流并释放对应的资源
- public synchronized void mark(int readlimit)
- public synchronized void reset()
- public boolean markSupported()
mark 方法会在当前流读取位置打上一个标志,reset 方法即重置读取指针到该标志处。
事实上,文件读取是不可能重置回头读取的,而一般都是将标志位置到重置点之间所有的字节临时保存了,当调用 reset 方法时,其实是从保存的临时字节集合进行重复读取,所以 readlimit 用于限制最大缓存容量。
而 markSupported 方法则用于确定当前流是否支持这种「回退式」读取操作。
OutputStream 和 InputStream 是类似的,只不过一个是写一个是读,此处我们不再赘述了。
文件字节流 FileInput/OutputStream
我们依然着重点于 FileInputStream,而 FileOutputStream 是类似的。
首先 FileInputStream 有以下几种构造器实例化一个对象:
public FileInputStream(String name) throws FileNotFoundException {
this(name != null ? new File(name) : null);
}
public FileInputStream(File file) throws FileNotFoundException {
String name = (file != null ? file.getPath() : null);
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkRead(name);
}
if (name == null) {
throw new NullPointerException();
}
if (file.isInvalid()) {
throw new FileNotFoundException("Invalid file path");
}
fd = new FileDescriptor();
fd.attach(this);
path = name;
open(name);
}
这两个构造器本质上也是一样的,前者是后者的特殊形态。其实你别看后者的方法体一大堆代码,大部分都只是在做安全校验,核心的就是一个 open 方法,用于打开一个文件。
主要是这两种构造器,如果文件不存在或者文件路径和名称不合法,都将抛出 FileNotFoundException 异常。
记得我们说过,基类 InputStream 中有一个抽象方法 read 要求所有子类进行实现,而 FileInputStream 使用本地方法进行了实现:
public int read() throws IOException {
return read0();
}
private native int read0() throws IOException;
这个 read0 的具体实现我们暂时无从探究,但是你必须明确的是,这个 read 方法的作用,它用于返回流中下一个字节,返回 -1 说明读取到文件末尾,已无字节可读。
除此之外,FileInputStream 中还有一些其他的读取相关方法,但大多采用了本地方法进行了实现,此处我们简单看看:
- public int read(byte b[]):读取 b.length() 个长度的字节到数组中
- public int read(byte b[], int off, int len):读取指定长度的字节数到数组中
- public native long skip(long n):跳过 n 的字节进行读取
- public void close():释放流资源
FileInputStream 的内部方法基本就这么些,还有一些高级的复杂的,我们暂时用不到,以后再进行学习,下面我们简单看一个文件读取的例子:
public static void main(String[] args) throws IOException {
FileInputStream input = new FileInputStream("C:\\Users\\yanga\\Desktop\\test.txt");
byte[] buffer = new byte[1024];
int len = input.read(buffer);
String str = new String(buffer);
System.out.println(str);
System.out.println(len);
input.close();
}
输出结果很简单,会打印出我们 test 文件中的内容和实际读出的字节数,但细心的同学就会发现了,你怎么就能保证 test 文件中内容不会超过 1024 个字节呢?
为了能够完整的读出文件中的内容,一种解决办法是:将 buffer 定义的足够大,以期望尽可能的能够存储下文件中的所有内容。
这种方法显然是不可取的,因为我们根本不可能实现知道待读文件的实际大小,一味的创建过大的字节数组其本身也是一种很差劲的方案。
第二种方式就是使用我们的动态字节数组流,它可以动态调整内部字节数组的大小,保证适当的容量,这一点我们后文中将详细介绍。
关于 FileOutputStream,还需要强调一点的是它的构造器,其中有以下两个构造器:
public FileOutputStream(String name, boolean append)
public FileOutputStream(File file, boolean append)
参数 append 指明了,此流的写入操作是覆盖还是追加,true 表示追加,false 表示覆盖。
字节数组流 ByteArrayInput/OutputStream
所谓的「字节数组流」就是围绕一个字节数组运作的流,它并不像其他流一样,针对文件进行流的读写操作。
字节数组流虽然并不是基于文件的流,但却依然是一个很重要的流,因为它内部封装的字节数组并不是固定的,而是动态可扩容的,往往基于某些场景下,非常合适。
ByteArrayInputStream 是读字节数组流,可以通过以下构造函数被实例化:
protected byte buf[];
protected int pos;
protected int count;
public ByteArrayInputStream(byte buf[]) {
this.buf = buf;
this.pos = 0;
this.count = buf.length;
}
public ByteArrayInputStream(byte buf[], int offset, int length)
buf 就是被封装在 ByteArrayInputStream 内部的一个字节数组,ByteArrayInputStream 的所有读操作都是围绕着它进行的。
所以,实例化一个 ByteArrayInputStream 对象的时候,至少传入一个目标字节数组的。
pos 属性用于记录当前流读取的位置,count 记录了目标字节数组最后一个有效字节索引的后一个位置。
理解了这一点,有关它各种的 read 方法就不难了:
//读取下一个字节
public synchronized int read() {
return (pos < count) ? (buf[pos++] & 0xff) : -1;
}
//读取 len 个字节放到字节数组 b 中
public synchronized int read(byte b[], int off, int len){
//同样的,方法体较长,大家查看自己的 jdk
}
除此之外,ByteArrayInputStream 还非常简单的实现了「重复读取」操作。
public void mark(int readAheadLimit) {
mark = pos;
}
public synchronized void reset() {
pos = mark;
}
因为 ByteArrayInputStream 是基于字节数组的,所有重复读取操作的实现就比较容易了,基于索引实现就可以了。
ByteArrayOutputStream 是写的字节数组流,很多实现还是很有自己的特点的,我们一起来看看。
首先,这两个属性是必须的:
protected byte buf[];
//这里的 count 表示的是 buf 中有效字节个个数
protected int count;
构造器:
public ByteArrayOutputStream() {
this(32);
}
public ByteArrayOutputStream(int size) {
if (size < 0) {
throw new IllegalArgumentException("Negative initial size: "+ size);
}
buf = new byte[size];
}
构造器的核心任务是,初始化内部的字节数组 buf,允许你传入 size 显式限制初始化的字节数组大小,否则将默认长度 32 。
从外部向 ByteArrayOutputStream 写内容:
public synchronized void write(int b) {
ensureCapacity(count + 1);
buf[count] = (byte) b;
count += 1;
}
public synchronized void write(byte b[], int off, int len){
if ((off < 0) || (off > b.length) || (len < 0) ||
((off + len) - b.length > 0)) {
throw new IndexOutOfBoundsException();
}
ensureCapacity(count + len);
System.arraycopy(b, off, buf, count, len);
count += len;
}
看到没有,所有写操作的第一步都是 ensureCapacity 方法的调用,目的是为了确保当前流内的字节数组能容纳本次写操作。
而这个方法也很有意思了,如果计算后发现,内部的 buf 不能够支持本次写操作,则会调用 grow 方法做一次扩容。扩容的原理和 ArrayList 的实现是类似的,扩大为原来的两倍容量。
除此之外,ByteArrayOutputStream 还有一个 writeTo 方法:
public synchronized void writeTo(OutputStream out) throws IOException {
out.write(buf, 0, count);
}
将我们内部封装的字节数组写到某个输出流当中。
剩余的一些方法也很常用:
- public synchronized byte toByteArray()[]:返回内部封装的字节数组
- public synchronized int size():返回 buf 的有效字节数
- public synchronized String toString():返回该数组对应的字符串形式
注意到,这两个流虽然被称作「流」,但是它们本质上并没有像真正的流一样去分配一些资源,所以我们无需调用它的 close 方法,调了也没用(人家官方说了,has no effect)。
测试的案例就不放出来了,等会我会上传本篇文章用到的所有代码案例,大家自行选择下载即可。
为了控制篇幅,余下流的学习,放在下篇文章。
文章中的所有代码、图片、文件都云存储在我的 GitHub 上:
(https://github.com/SingleYam/overview_java)
欢迎关注微信公众号:扑在代码上的高尔基,所有文章都将同步在公众号上。

Java 的字节流文件读取(一)的更多相关文章
- Java 的字节流文件读取(二)
接着上篇文章,我们继续来学习 Java 中的字节流操作. 装饰者缓冲流 BufferedInput/OutputStream 装饰者流其实是基于一种设计模式「装饰者模式」而实现的一种文件 IO 流,而 ...
- java中的文件读取和文件写出:如何从一个文件中获取内容以及如何向一个文件中写入内容
import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.File; import java.io.Fi ...
- Java学习-019-Properties 文件读取实例源代码
在这几天的学习过程中,有开发的朋友告知我,每个编程语言基本都有相应的配置文件支持类,像 Python 编程语言中支持的 ini 文件及其对应的配置文件读取类 ConfigParse,通过这个类,用户可 ...
- Java学习-017-EXCEL 文件读取实例源代码
众所周知,EXCEL 也是软件测试开发过程中,常用的数据文件导入导出时的类型文件之一,此文主要讲述如何通过 EXCEL 文件中 Sheet 的索引(index)或者 Sheet 名称获取文件中对应 S ...
- Java学习-016-CSV 文件读取实例源代码
上文(CSV文件写入)讲述了日常自动化测试过程中将测试数据写入 CSV 文件的源码,此文主要讲述如何从 CSV 文件获取测试过程中所需的参数化数据.敬请各位小主参阅,若有不足之处,敬请大神指正,不胜感 ...
- Java解决大文件读取的内存问题以及文件流的比较
Java解决大文件读取的内存问题以及文件流的比较 传统方式 读取文件的方式一般是是从内存中读取,官方提供了几种方式,如BufferedReader, 以及InputStream 系列的,也有封装好的如 ...
- Java之properties文件读取
1.工程结构 2.ConfigFileTest.java package com.configfile; import java.io.IOException; import java.io.Inpu ...
- Java开发中文件读取方式总结
JAVA开发中,免不了要读文件操作,读取文件,首先就需要获取文件的路径. 路径分为绝对路径和相对路径. 在文件系统中,绝对路径都是以盘符开始的,例如C:\abc\1.txt. 什么是相对路径呢?相对路 ...
- JAVA 中的文件读取
1. InputStream / OutputStream处理字节流抽象类:所有输入.输出(内存)类的超类,一般使用 FileInputStream / FileOutputStream 输出字符 u ...
随机推荐
- PR 审批界面增加显示项方法
PR 审批界面增加显示项 解决方法 Step 1: 进入审批界面: Step 2: 在上图中,点击左下角'About this Page'查看数据源 点击上图中'Expand ...
- STL - vector容器
1Vector容器简介 vector是将元素置于一个动态数组中加以管理的容器. vector可以随机存取元素(支持索引值直接存取, 用[]操作符或at()方法,这个等下会详讲). vector尾部添加 ...
- JAVA中重写equals()方法的同时要重写hashcode()方法
object对象中的 public boolean equals(Object obj),对于任何非空引用值 x 和 y,当且仅当 x 和 y 引用同一个对象时,此方法才返回 true:注意:当此方法 ...
- java解决hash算法冲突
看了ConcurrentHashMap的实现, 使用的是拉链法. 虽然我们不希望发生冲突,但实际上发生冲突的可能性仍是存在的.当关键字值域远大于哈希表的长度,而且事先并不知道关键字的具体取值时.冲突就 ...
- Linux Framebuffer驱动剖析之一—软件需求
嵌入式企鹅圈将以本文作为2015年的终结篇,以回应第一篇<Linux字符设备驱动剖析>.嵌入式企鹅圈一直专注于嵌入式Linux和物联网IOT两方面的原创技术分享,稍后会发布嵌入式企鹅圈的2 ...
- LeetCode(44)- Isomorphic Strings
题目: Given two strings s and t, determine if they are isomorphic. Two strings are isomorphic if the c ...
- masm下几种常见函数调用方式
masm没有fastcall调用方式,其特点为: 1 第一个参数放入ecx,第二个参数放入edx: 2 如果有剩余参数则从右向左压栈: 3 被调用函数清理栈(平衡栈): 4 若有返回值放入eax: 5 ...
- 使用bootstrap table 插件固定表头时 表头与表格内容无法对齐
在使用bootstrap table开发后台管理系统,表格利用bootstrap-table插件来实现,使用bootstrap-table过程中,会出现表头错位的情况 表头对不齐效果: 解决的方法: ...
- C++笔记018:构造函数的调用规则
原创笔记,转载请注明出处! 点击[关注],关注也是一种美德~ 一.默认构造函数 两个特殊的构造函数 1.默认无参构造函数 当类中没有定义构造函数时,编译器默认提供一个无参构造函数,并且其函数体为空 ...
- MySQL性能调优——索引详解与索引的优化
--索引优化,可以说是数据库相关优化.理解尤其是查询优化中最常用的优化手段之一.所以,只有深入索引的实现原理.存储方式.不同索引间区别,才能设计或使用最优的索引,最大幅度的提升查询效率! 一.BTre ...