Spark运行架构
http://blog.csdn.net/pipisorry/article/details/52366288
1、 Spark运行架构
1.1 术语定义
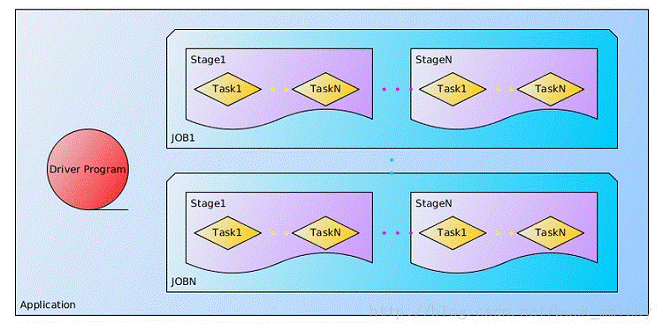
lApplication:Spark Application的概念和Hadoop MapReduce中的类似,指的是用户编写的Spark应用程序,包含了一个Driver 功能的代码和分布在集群中多个节点上运行的Executor代码;
lDriver:Spark中的Driver即运行上述Application的main()函数并且创建SparkContext,其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;当Executor部分运行完毕后,Driver负责将SparkContext关闭。通常用SparkContext代表Drive;
lExecutor:Application运行在Worker节点上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的一批Executor。在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutorBackend,类似于Hadoop MapReduce中的YarnChild。一个CoarseGrainedExecutorBackend进程有且仅有一个executor对象,它负责将Task包装成taskRunner,并从线程池中抽取出一个空闲线程运行Task。每个CoarseGrainedExecutorBackend能并行运行Task的数量就取决于分配给它的CPU的个数了;
lCluster Manager:指的是在集群上获取资源的外部服务,目前有:
Ø Standalone:Spark原生的资源管理,由Master负责资源的分配;
Ø Hadoop Yarn:由YARN中的ResourceManager负责资源的分配;
lWorker:集群中任何可以运行Application代码的节点,类似于YARN中的NodeManager节点。在Standalone模式中指的就是通过Slave文件配置的Worker节点,在Spark on Yarn模式中指的就是NodeManager节点;
l作业(Job):包含多个Task组成的并行计算,往往由Spark Action催生,一个JOB包含多个RDD及作用于相应RDD上的各种Operation;
l阶段(Stage):每个Job会被拆分很多组Task,每组任务被称为Stage,也可称TaskSet,一个作业分为多个阶段;
l任务(Task): 被送到某个Executor上的工作任务;
并行
“一个Job里的Stage都是串行的,前一个Stage完成后下一个Stage才会进行”,显然上面的话是不严谨的:Stage 可以并行执行的;存在依赖的Stage 必须在依赖的Stage执行完成后才能执行下一个Stage;Stage的并行度取决于资源数。[Spark 多个Stage执行是串行执行的么?]
并行化集合的一个重要参数是分区(partition),即这个分布式数据集可以分割为多少片。Spark中每个任务(task)都是基于分区的,每个分区一个对应的任务(task)。典型场景下,一般每个CPU对应2~4个分区。并且一般而言,Spark会基于集群的情况,自动设置这个分区数。当然,你还是可以手动控制这个分区数,只需给parallelize方法再传一个参数即可(如:sc.parallelize(data, 10) )。注意:Spark代码里有些地方仍然使用分片(slice)这个术语,这只不过是分区的一个别名,主要为了保持向后兼容。
e.g. 你可以在集群上为每个 CPU 设置 2-4 个切片(slices)(也就是numslices数目应该设置为#cpu * 2-4)。

输入可能以多个文件的形式存储在HDFS上,每个File都包含了很多块,称为Block。
当Spark读取这些文件作为输入时,会根据具体数据格式对应的InputFormat进行解析,一般是将若干个Block合并成一个输入分片,称为InputSplit,注意InputSplit不能跨越文件。
随后将为这些输入分片生成具体的Task。InputSplit与Task是一一对应的关系。
随后这些具体的Task每个都会被分配到集群上的某个节点的某个Executor去执行。
- 每个节点可以起一个或多个Executor。
- 每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task。
- 每个Task执行的结果就是生成了目标RDD的一个partiton。
注意: 这里的core是虚拟的core而不是机器的物理CPU核,可以理解为就是Executor的一个工作线程。
而 Task被执行的并发度 = Executor数目 * 每个Executor核数。
至于partition的数目:
- 对于数据读入阶段,例如sc.textFile,输入文件被划分为多少InputSplit就会需要多少初始Task。
- 在Map阶段partition数目保持不变。
- 在Reduce阶段,RDD的聚合会触发shuffle操作,聚合后的RDD的partition数目跟具体操作有关,例如repartition操作会聚合成指定分区数,还有一些算子是可配置的。
[在Spark集群中,集群的节点个数、RDD分区个数、cpu内核个数三者与并行度的关系?]
Spark 是一套数据并行处理的引擎。但是 Spark 并不是神奇得能够将所有计算并行化,它没办法从所有的并行化方案中找出最优的那个。每个 Spark stage 中包含若干个 task,每个 task 串行地处理数据。在调试 Spark 的job时,task 的个数可能是决定程序性能的最重要的参数。那么这个数字是由什么决定的呢?在之前的博文中介绍了 Spark 如何将 RDD 转换成一组 stage。task 的个数与 stage 中上一个 RDD 的 partition 个数相同。而一般一个 RDD 的 partition 个数与被它依赖的 RDD 的 partition 个数相同。
由 textFile 或者 hadoopFile 生成的 RDD 的 partition 个数由它们底层使用的 MapReduce InputFormat 决定的。一般情况下,每读到的一个 HDFS block 会生成一个 partition。通过 parallelize 接口生成的 RDD 的 partition 个数由用户指定,如果用户没有指定则由参数 spark.default.parallelism 决定。
要想知道 partition 的个数,可以通过接口 rdd.partitions().size() 获得(scala? pyspark好像没有)。
这里最需要关心的问题在于 task 的个数太小。如果运行时 task 的个数比实际可用的 slot 还少,那么程序解没法使用到所有的 CPU 资源。
[Apache Spark Jobs 性能调优(二):调试并发]
本地模式的线程数:
本地模式下,我们可以使用n个线程(n >= 1)。而且在像Spark Streaming这样的场景下,我们可能需要多个线程来防止类似线程饿死这样的问题。
sc = pyspark.SparkContext(master="local[30]", appName='usermeet spark') rdd )
如上设置30个线程并行执行,local[30]是表示会有30个线程来跑task(30个分区数对应30个task)。
、Spark在不同集群中的运行架构
、Spark在不同集群中的运行演示
、问题解决
4.1 YARN-Client启动报错
在进行Hadoop2.X 64bit编译安装中由于使用到64位虚拟机,安装过程中出现下图错误:
[hadoop@hadoop1 spark-1.1.0]$ bin/spark-shell --master YARN-client --executor-memory 1g --num-executors 3
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Exception in thread "main" java.lang.Exception: When running with master 'YARN-client' either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment.
at org.apache.spark.deploy.SparkSubmitArguments.checkRequiredArguments(SparkSubmitArguments.scala:182)
at org.apache.spark.deploy.SparkSubmitArguments.<init>(SparkSubmitArguments.scala:62)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:70)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)

参考资料:
(1)《Spark1.0.0 运行架构基本概念》 http://blog.csdn.net/book_mmicky/article/details/25714419
(2)《Spark架构与作业执行流程简介》 http://www.cnblogs.com/shenh062326/p/3658543.html
(3)《Spark1.0.0 运行架构基本概念》 http://shiyanjun.cn/archives/744.html
from: http://blog.csdn.net/pipisorry/article/details/52366288
ref:
Spark运行架构的更多相关文章
- Spark入门实战系列--4.Spark运行架构
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1. Spark运行架构 1.1 术语定义 lApplication:Spark Appli ...
- 【转载】Spark运行架构
1. Spark运行架构 1.1 术语定义 lApplication:Spark Application的概念和Hadoop MapReduce中的类似,指的是用户编写的Spark应用程序,包含了一个 ...
- spark 运行架构
spark 运行架构基本由三部分组成,包括SparkContext(驱动程序),ClusterManager(集群资源管理器)和Executor(任务执行过程)组成. 其中SparkContext负责 ...
- Spark学习(一)——Spark运行架构
基本概念 在具体讲解Spark运行架构之前,需要先了解几个重要的概念: RDD:是弹性分布式数据集(Resilient Distributed Dataset)的简称,是分布式内存的一个抽象概念,提供 ...
- Spark运行架构详解
原文引自:http://www.cnblogs.com/shishanyuan/p/4721326.html 1. Spark运行架构 1.1 术语定义 lApplication:Spark Appl ...
- Spark 运行架构核心总结
摘要: 1.基本术语 2.运行架构 2.1基本架构 2.2运行流程 2.3相关的UML类图 2.4调度模块: 2.4.1作业调度简介 2.4.2任务调度简介 3.运行模式 3.1 standalo ...
- 3.2 Spark运行架构
一.基本概念 1.RDD Resillient Distributed Dataset 弹性分布式数据集 2.DAG 反映RDD之间的依赖关系 3.Executor 进程驻守在机器上面,由进程派生出很 ...
- Spark入门:Spark运行架构(Python版)
此文为个人学习笔记如需系统学习请访问http://dblab.xmu.edu.cn/blog/1709-2/ 基本概念 * RDD:是弹性分布式数据集(Resilient Distributed ...
- 【Todo】Spark运行架构
接上一篇:http://www.cnblogs.com/charlesblc/p/6108105.html 上一篇文章中主要参考的是 Link 这个系列下一篇讲的是Idea,没有细看,又看了再下一篇: ...
随机推荐
- ios开发-日期处理(类似朋友圈,微博等的发送时间)
ios开发中,我们经常要处理从服务器获取的时间.类似朋友圈,微博这些应用.我们经常可以看到“刚刚”,“31分钟前发表”,“昨天5点”,之类的字样. 当时我们从服务器端获取的都是那条朋友圈信息,或者微博 ...
- 机器学习技法:03 Kernel Support Vector Machine
Roadmap Kernel Trick Polynomial Kernel Gaussian Kernel Comparison of Kernels Summary
- [Luogu 3835]【模板】可持久化平衡树
Description 您需要写一种数据结构(可参考题目标题),来维护一些数,其中需要提供以下操作(对于各个以往的历史版本): 插入x数 删除x数(若有多个相同的数,因只删除一个,如果没有请忽略该操作 ...
- hdu 5465 (树状数组 + 博弈)
题意:基于矩阵的NIM游戏,求异或和. 思路:在x1,y1 到 x2, y2的异或和 = A[ x2 ][ y2 ] ^ A[x1-1][ y2 ] ^ A[ x2 ][y1 - 1] ^ A[ x ...
- [BZOJ]1089 严格n元树(SCOI2003)
十几年前的题啊……果然还处于高精度遍地走的年代.不过通过这道题,小C想mark一下n叉树计数的做法. Description 如果一棵树的所有非叶节点都恰好有n个儿子,那么我们称它为严格n元树.如果该 ...
- [济南集训 2017] 求gcd之和
题目大意: 求\(\sum_{i=1}^n\sum_{j=1}^mgcd(i,j)\) 解题报告: 有一个结论:一个数的所有因子的欧拉函数之和等于这个数本身 运用这个我们可以开始推: \(\sum_{ ...
- Mysql bug: The server time zone value '�й���ʱ��' is unrecognized or represents more than one time zone.
在 MySQL 中执行命令试下: set global time_zone='+8:00': 解释:在访问数据库时出现时区无法识别问题,在通过在数据库连接URL后,加上?serverTimezone= ...
- angular 路由的引用
使用angular路由 遇到的坑. 使用cmd 安装好node.js 安装成功 输入node -v 能查看版本说明安装成功 搭建angular项目输入命令 npm install -g angu ...
- Swift 3.0项目迁移的一些记录
刚执行完Convert后报错600+,真是令人奔溃. 之后重新编译,仔细分析后发现其实真实错误远没有那么多.最终实际修改到的错误也就几十个,而且其中某些还是同一种错误. 这个项目是一个供自己使用的浏览 ...
- .net环境下跨进程、高频率读写数据
一.需求背景 1.最近项目要求高频次地读写数据,数据量也不是很大,多表总共加起来在百万条上下. 单表最大的也在25万左右,历史数据表因为不涉及所以不用考虑, 难点在于这个规模的热点数据,变化非常频繁. ...