linux 系统管理--进程管理
linux 系统管理--进程管理
一、进程基本概述
1.什么是进程?
比如:windows上安装的QQ,我们会将其称为QQ程序,那么当QQ运行之后,在任务管理器中,我们可以看到QQ程序在运行着,此时,我们称其为:QQ进程。
言简意赅总结:当我们运行一个程序,那么我们将该程序叫进程
注意:
1.当程序运行为进程后,系统会为该进程分配内存,以及运行的身份和权限。
2.在进程运行的过程中,服务器上回有各种状态来表示当前进程的指标信息。
进程是已启动的可执行程序的运行实例,进程有以下组成部分:
局部和全局变量当前的调度上下文分配给进程使用的系统资源,例如文件描述符、网络端口等给进程分配对应的pid,ppid
2.程序和进程的区别?
1.程序是开发写出来的代码,是永久存在的。数据和指令的集合,是一个静态的概念,比如/bin/ls、/bin/cp等二进制文件。
2.进程是一个程序的运行过程,会随着程序的终止儿销毁,不会永远在系统中存在。是一个动态概念,进程是存在生命周期概念的。
3.进程的生命周期
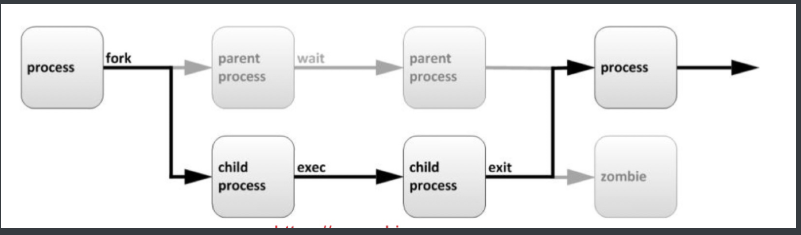
程序运行时进程的状态关系:
1.当父进程接收到任务调度时,会通过fork派生子进程来处理,那么子进程会集成父进程的衣钵。
2.子进程在处理任务代码时,父进程会进入等待的状态...
3.如果子进程在处理任务过程中,父进程退出了,子进程没有退出,那么这些子进程就没有父进程来管理了,就变成了僵尸进程。
4.每个进程都会有自己的PID号,(process id)子进程则PPID
二、监控进程状态

1.使用ps命令查看当前的进程状态(静态查看)
常用组合:ps aux 查看进程
[root@zls ~]# ps auxa:显示所有与终端相关的进程,由终端发起的u:显示用户导向的用户列表x:显示所有与终端无关的进程
在多任务处理操作系统中,每个CPU(或核心)在一个时间点上只能处理一个进程。
在进程运行时,它对 CPU 时间和资源分配的要求会不断变化,从而为进程分配一个状态,它随着环境要求而改变。
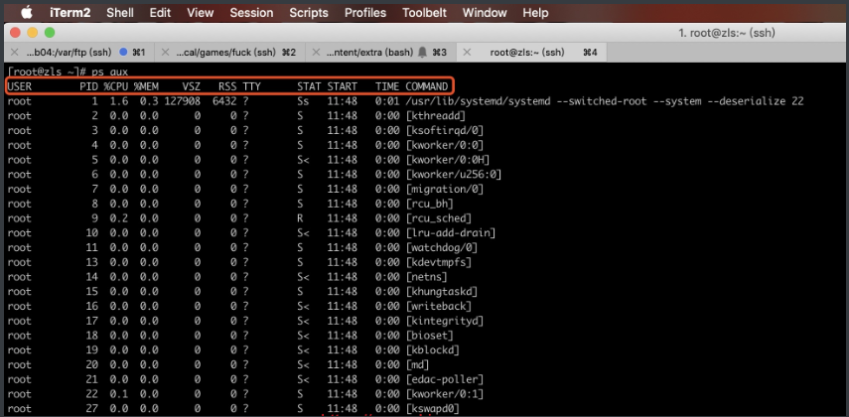
USER: //启动程序的用户PID: //进程ID%CPU: //占用CPU的百分比%MEM: //占用内存的百分比VSZ: //虚拟内存集(进程占用虚拟内存的空间)RSS: //物理内存集(进程占用物理内存的空间)TTY: //运行的终端?: #内核运行的终端tty1: #机器运行的终端pts/0: #远程连接的终端STAT: //进程状态D: #无法中断的休眠状态(通IO的进程)R: #正在运行的状态S: #处于休眠的状态T: #暂停或被追踪的状态W: #进入内存交换(从内核2.6开始无效)X: #死掉的进程(少见)Z: #僵尸进程<: #优先级高的进程N: #优先级较低的进程L: #有些页被锁进内存s: #父进程(在它之下有子进程开启着)l: #以线程的方式运行|: #多进程的+: #该进程运行在前台START: //进程被触发开启的时间TIME: //该进程实际使用CPU的运行时间COMMAND: //命令的名称和参数[]: #内核态的进程没[]: #用户态的进程
案例一:PS命令查看前台进程转换到停止
#在终端上运行vim[root@zls ~]# vim zls.txt#查看vim运行的状态,S:睡眠状态 +:在前台运行[root@zls ~]# ps aux|grep [v]imroot 1306 0.0 0.2 151664 5180 pts/0 S+ 13:00 0:00 vim zls.txt#执行ctrl + z,将进程放置后台[1]+ 已停止 vim zls.txt#进程状态变成了T,暂停或被追踪的状态[root@zls ~]# ps aux|grep [v]imroot 1306 0.0 0.2 151664 5180 pts/0 T 13:00 0:00 vim zls.txt
案例二:PS命令查看不可中断状态
#在终端上运行tar命令[root@zls ~]# tar zcf zls.tar.gz /etc/ /usr/ /var/ /usr/#持续查看tar进程的状态[root@zls ~]# ps aux|grep [t]arroot 1348 13.3 0.0 124008 1700 pts/0 R+ 13:06 0:00 tar zcf zls.tar.gz /etc/ /usr/ /var/ /usr/[root@zls ~]# ps aux|grep [t]arroot 1348 13.2 0.0 124008 1716 pts/0 R+ 13:06 0:00 tar zcf zls.tar.gz /etc/ /usr/ /var/ /usr/[root@zls ~]# ps aux|grep [t]arroot 1348 15.7 0.0 124008 1716 pts/0 S+ 13:06 0:00 tar zcf zls.tar.gz /etc/ /usr/ /var/ /usr/[root@zls ~]# ps aux|grep [t]arroot 1348 13.6 0.0 124008 1736 pts/0 S+ 13:06 0:00 tar zcf zls.tar.gz /etc/ /usr/ /var/ /usr/[root@zls ~]# ps aux|grep [t]arroot 1348 15.1 0.0 124008 1736 pts/0 R+ 13:06 0:00 tar zcf zls.tar.gz /etc/ /usr/ /var/ /usr/[root@zls ~]# ps aux|grep [t]arroot 1348 14.1 0.0 124008 1736 pts/0 D+ 13:06 0:00 tar zcf zls.tar.gz /etc/ /usr/ /var/ /usr/[root@zls ~]# ps aux|grep [t]arroot 1348 13.2 0.0 124008 1756 pts/0 R+ 13:06 0:01 tar zcf zls.tar.gz /etc/ /usr/ /var/ /usr/[root@zls ~]# ps aux|grep [t]arroot 1348 15.2 0.0 124140 1756 pts/0 R+ 13:06 0:01 tar zcf zls.tar.gz /etc/ /usr/ /var/ /usr/[root@zls ~]# ps aux|grep [t]arroot 1348 14.7 0.0 124240 1952 pts/0 S+ 13:06 0:01 tar zcf zls.tar.gz /etc/ /usr/ /var/ /usr/
案例三:PS命令查看进程Ss+状态
#过滤bash进程,再开启终端[root@zls ~]# ps aux|grep [b]ashroot 1127 0.0 0.1 115436 2084 tty1 Ss 11:49 0:00 -bashroot 1180 0.0 0.0 115436 1900 tty1 S+ 11:49 0:00 bashroot 1198 0.0 0.1 115564 2152 pts/0 Ss 11:50 0:00 -bashroot 1324 0.0 0.1 115440 2064 pts/1 Ss+ 13:01 0:00 -bash
了解进程如下选项:
PID,PPID当前的进程状态内存的分配情况CPU 和已花费的时间用户UID决定进程的特权
ps命令使用方法
#对进程的CPU进行排序展示[root@zls ~]# ps aux --sort %cpu |less#对进程的占用物理内存排序[root@zls ~]# ps aux --sort rss |less#排序,实在记不住,那就自己排序[root@zls ~]# ps aux|sort -k3 -n#自定义显示字段,指定想看的列[root@zls ~]# ps axo user,pid,ppid,%mem,command |grep sshdroot 869 1 0.2 /usr/sbin/sshd -Droot 1194 869 0.2 sshd: root@pts/0root 1307 869 0.2 sshd: root@pts/1root 1574 869 0.2 sshd: root@pts/2#显示进程的子进程[root@zls ~]# yum install nginx -y[root@zls ~]# systemctl start nginx[root@zls ~]# ps auxf|grep [n]ginxroot 2033 0.0 0.1 125096 2112 ? Ss 13:29 0:00 nginx: master process /usr/sbin/nginxnginx 2034 0.0 0.1 125484 3148 ? S 13:29 0:00 \_ nginx: worker process#默认不加选项是查看指定进程PID[root@zls ~]# ps aux|grep sshdroot 1157 0.0 0.1 105996 3604 ? Ss Feb27 0:00 /usr/sbin/sshd -D[root@zls ~]# cat /run/sshd.pid1157#pgrep常用参数, -l -a[root@zls ~]# pgrep sshd869119413071574[root@zls ~]# pgrep -l sshd869 sshd1194 sshd1307 sshd1574 sshd[root@zls ~]# pgrep -l -a sshd869 /usr/sbin/sshd -D1194 sshd: root@pts/01307 sshd: root@pts/11574 sshd: root@pts/2#查看进程的pid[root@zls ~]# pidof sshd1574 1307 1194 869#查看进程树[root@zls ~]# pstreesystemd─┬─NetworkManager───2*[{NetworkManager}]├─VGAuthService├─abrt-watch-log├─abrtd├─agetty├─auditd───{auditd}├─crond├─dbus-daemon───{dbus-daemon}├─irqbalance├─master─┬─pickup│ └─qmgr├─nginx───4*[nginx]├─polkitd───6*[{polkitd}]├─rsyslogd───2*[{rsyslogd}]├─sshd─┬─sshd───bash───pstree│ └─sshd───bash───bash───bash├─systemd-journal├─systemd-logind├─systemd-udevd├─tuned───4*[{tuned}]├─vmtoolsd───{vmtoolsd}└─vsftpd
2. 动态监控进程--top 命令


[root@gong ~]# toptop - 22:58:05 up 4:37, 3 users, load average: 0.00, 0.01, 0.05Tasks: 98 total, 1 running, 97 sleeping, 0 stopped, 0 zombie%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 stKiB Mem : 2047488 total, 1566920 free, 116060 used, 364508 buff/cacheKiB Swap: 0 total, 0 free, 0 used. 1763644 avail Mem#当前系统的时间22:58:05#开启时间up 4:37,#几个用户同时在线3 users,#平均负载:1分钟,5分钟,15分钟load average: 0.00, 0.01, 0.05#总共工作数量98个Tasks:98 total,#1个正在处理1 running,#97个S状态97 sleeping,#00个停止状态2 stopped,#0个僵尸进程0 zombie%Cpu(s):#用户态:用户占用CPU的百分比0.0 us,#内核态:系统程序占用CPU的百分比(通常内核与硬件进行交互)0.0 sy,dd </dev/zero >/dev/null bs=200M count=1000#优先级:优先被调度的程序占用CPU百分比0.0 ni,#空闲:CPU空闲的百分比(windows也有)99.7 id,#等待:CPU等待IO的完成时间0.0 wa,#硬中断:占CPU的百分比0.0 hi,由与系统相连的外设(比如网卡、硬盘)自动产生的。主要是用来通知操作系统,系统外设状态的变化。比如当网卡收到数据包的时候,就会发出一个中断。我们通常所说的中断指的是硬中断(hardirq)。#软中断:占CPU的百分比0.0 si,为了满足实时系统的要求,中断处理应该是越快越好。linux为了实现这个特点,当中断发生的时候,硬中断处理那些短时间就可以完成的工作,而将那些处理事件比较长的工作,放到中断之后来完成,也就是软中断(softirq)来完成。#虚拟机占用物理机的百分比0.0 st
3.中断
硬中断是系统用来影响硬件设备请求的一种机制,它会打断进程的正常调度和执行,然后调用内核中的中断处理程序来影响设备的请求
举个例子:比如你定了一份外卖,但是不确定外卖什么时候送到,也没有别的方法了解外卖的进度,但是配送人员送外卖是不等人的,到了你这,没人接取的话,直接走人了。所以你只能苦苦的等着,时不时的去门口看看外卖送到没有,而不能做其他的事情。不过如果在订外卖的时候,你就跟配送员约定好了,让他送到给你打电话,那你就不用苦苦等着了,可以去忙别的事情了,直到电话一响,接到电话,就可以取外卖了。此时 ==打电话== 就是一个中断的操作。没接到电话之前,你可以做其他事情,当你接到电话之后(就发生了中断),你才要进行另一个动作**取外卖**PS:中断是一个异步的事件处理机制,可以提高操作系统处理并发的能力。
由于中断处理程序会打断其他进程的运行,所以,为了减少对正常进程运行调度的影响,中弄断处理程序就需要尽可能快的运行,如果中弄断本身要做的事情不多,那么处理起来也不会有太大的问题,但是如果中断要处理的事情很多,中断服务程序就有可能要运行很长时间。
特别是,中断处理程序在影响中断时,还会临时关闭中断,这就会导致上一次中断处理完成之前,其他中断都能不能响应,也就是说中断有可能会丢失。
还是以外卖为例:加入你定了2份外卖一份主食和一份饮料,由2个不同的配送员来配送。这次你不用时时等待着,两份外卖都约定了电话取外卖的方式。那么问题又来了。当第一份外卖送到时,配送员给你打了个很长的电话,商量发票处理的方式,与此同时,第二个配送员也到了,也想给你打电话,但是会占线,因为电话占线(也就关闭了中断的响应),第二个配送给你打电话打不通,所以,那么很有可能在尝试几次还占线,就走了(丢失了一次中断)
刚才说了丢失一次中断,如果对于系统来说,每次都只能处理一次中断,那就很刺激了,天天都在丢失中断,用户的请求发过来,没响应,还做个P的运维,回家种地吧...
 

 

软中断:
事实上,为了解决中断处理程序执行过长的和丢失中断的问题,Linux将中断处理过程分成了两个阶段:
第一阶段:用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关工作
第二阶段:用来延迟处理第一阶段未完成的工作,通常以内核线程的方式运行。
还是外卖的那个例子:第一阶段:当你接到第一个配送员电话时,你可以跟他说,你已经知道了,其他事见面再细说,然后就可以挂断电话了。第二阶段:才是取外卖,然后见面聊发票的处理动作。如此一来,第一个配送员不会在电话里占用你很长时间,第二个配送员来的时候,照样可以打通电话。
当网卡在接收数据包的时候,会通过硬中断的方式通知内核,有新数据到了。这时,内核就应该调用中断处理程序来影响它。对第一阶段来说,既然是快速处理,其实就是把网卡接收到的数据包,先放置内存当中,然后更新一下硬件寄存器的状态(表示数据已经读好了),而第二阶段,被软中断信号唤醒后,需要从内存中找到网络数据,再按照网络协议栈,对数据进行逐层解析和处理,直到把它发送给应用程序。
总结:
第一阶段:直接处理硬件请求,也就是我们常说的硬中断,特点是快速执行。
第二阶段:由内核触发该请求,也就是我们常说的软中断,特点是延迟执行。
4.Linux软中断与硬中断小结:
1.Linux中中断处理程序分为上半部和下半部:
上半部对应硬中断,用来快速处理
下半部对应软中断,用来异步处理上半部未完成的工作
2.Linux中的软中断包括:网络收发,定时,调度等各种类型,可以通过/proc/softirqs来观察中断的运行情况
在企业中,会经常听说一个问题,就是大量的网络小包会导致性能问题,为啥呢?
因为大量的网络小包会导致频繁的硬中断和软中断,所以大量的网络小包传输速度很慢,但如果将所有的网络小包"打包","压缩"一次性传输,是不是会快很多。就好比,你在某东自营买了100个快递,都是第二天到,如果分100个快递员,给你配送,你一天要接100个电话,~~~~~~~~ 但是如果,某东只让一个快递员,把你买的100个快递,打包成一个大包裹,派送给你,会不会快很多?
top命令使用:
[root@zls ~]# top#指定N秒变化时间[root@zls ~]# top -d 1#查看指定进程的动态信息[root@zls ~]# top -d 1 -p 10126[root@zls ~]# top -d 1 -p 10126,1#查看指定用户的进程[root@zls ~]# top -d 1 -u apache#将 2 次 top 信息写入到文件[root@zls ~]# top -d 1 -b -n 2 > top.txttop 常见指令h 查看帮出z 高亮显示1 显示所有CPU的负载s 设置刷新时间b 高亮现实处于R状态的进程M 按内存使用百分比排序输出P 按CPU使用百分比排序输出R 对排序进行反转f 自定义显示字段k kill掉指定PID进程W 保存top环境设置 ~/.toprcq 退出#进程IDPID#用户USER#优先级,正常为20PR#nice值,正常为0,负值表示高优先级,正值表示低优先级NI#虚拟内存占用VIRT#真实内存占用RES#共享内存占用SHR#模式状态S#CPU占用百分比%CPU#内存占用百分比%MEM#运行时间TIME+#运行命令COMMAND
5.kill信号管理:
当程序运行为进程后,如果希望强行停止就可以使用kill命令对进程发送关闭信号,除了kill还有pkill、killall
定义守护进程的角色
结束用户会话和进程
kill,killall,pgrep,pkill
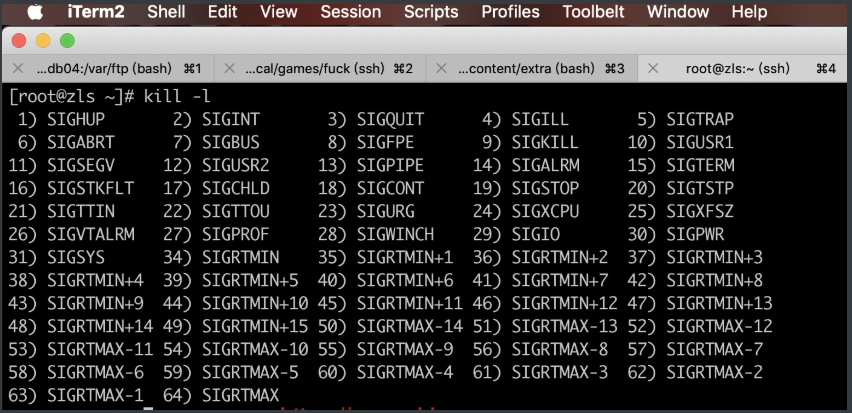
[root@zls ~]# kill -l //列出所有支持的信号//常见信号列表:数字信号 信号别名 作用1 HUP 挂起信号,往往可以让进程重新配置2 INT 中断信号,起到结束进程的作用,和ctrl + c 的作用一样3 QUIT 让进程退出,结果是进程退出9 KILL 直接结束进程,不能被进程捕获15 TERM 进程终止,这是默认信号18 CONT 被暂停的进程将继续恢复运行19 STOP 暂停进程20 TSTP 用户停止请求,作用类似于ctrl + z 把进程放到后台并暂停
6.kill命令发送信号
// 给 vsftpd 进程发送信号 1,15[root@zls ~]# yum -y install vsftpd[root@zls ~]# systemctl start vsftpd//发送重启信号,例如 vsftpd 的配置文件发生改变,希望重新加载[root@zls ~]# kill -1 9160//发送停止信号,vsftpd 服务有停止的脚本 systemctl stop vsftpd[root@zls ~]# kill 9160// 给vim进程发送信号 9,15[root@zls ~]# touch file1 file2//使用远程终端1打开file1[root@zls ~]# tty/dev/pts/1[root@zls ~]# vim file1//使用远程终端2打开file2[root@zls ~]# tty/dev/pts/2[root@zls ~]# vim file2//查看当前进程pid[root@zls ~]# ps aux |grep vimroot 4362 0.0 0.2 11104 2888 pts/1 S+ 23:02 0:00 vim file1root 4363 0.1 0.2 11068 2948 pts/2 S+ 23:02 0:00 vim file2//发送15信号[root@zls ~]# kill 4362//发送9信号[root@zls ~]# kill -9 4363//还可以同时给所有vim进程发送信号, 模糊匹配,同时给多个进程发送信号[root@zls ~]# killall vim//使用pkill踢出从远程登录到本机的用户, pkill 类似killall[root@zls ~]# w20:50:17 up 95 days, 9:30, 1 user, load average: 0.00, 0.00, 0.00USER TTY FROM LOGIN@ IDLE JCPU PCPU WHATxuliangw pts/0 115.175.115.39 20:22 0.00s 0.01s 0.00s sshd: zls [priv]//终止 pts/0上所有进程, 除了bash本身[root@zls ~]# pkill -t pts/0-t:指定终端//终止pts/0上所有进程, 并且bash也结束(用户被强制退出)[root@zls ~]# pkill -9 -t pts/0//列出zls用户的所有进程,-l输出pid[root@linux-zls ~]# pgrep -l -u zls32206 sshd32207 bash
三、进程的优先级[进阶]
优先级指的是优先享受资源,生活中的例子,比如...算了,太多了。
在启动进程时,为不同的进程使用不同的调度策略。
nice值越高:表示优先级越低,例如19,该进程容易将CPU使用量让给其他进程。
nice值越低:表示优先级越高,例如-20,该进程更不倾向于让出CPU。
1.使用top或ps命令查看进程的优先级
#使用top看优先级[root@zls ~]# toptop - 19:36:33 up 7:47, 4 users, load average: 0.00, 0.01, 0.05Tasks: 99 total, 1 running, 97 sleeping, 1 stopped, 0 zombie%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 stKiB Mem : 2030148 total, 155208 free, 159544 used, 1715396 buff/cacheKiB Swap: 1048572 total, 1048572 free, 0 used. 1633728 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND533 root 20 0 298716 6108 4780 S 0.3 0.3 0:23.45 vmtoolsd2337 root 20 0 161980 2240 1556 R 0.3 0.1 0:00.01 top1 root 20 0 127908 6492 4092 S 0.0 0.3 0:01.85 systemd2 root 20 0 0 0 0 S 0.0 0.0 0:00.01 kthreadd#使用ps查看优先级[root@zls ~]# ps axo command,nice |grep 折叠shd/usr/sbin/sshd -D 0sshd: root@pts/0 0sshd: root@pts/1 0sshd: root@pts/2 0
2.使用nice命令指定进程优先级
#打开一个终端[root@zls ~]# nice -n -5 vim zls#打开另一个终端,查看进程的优先级[root@zls ~]# ps aux|grep [v]imroot 2342 0.1 0.2 151720 5212 pts/1 S<+ 19:49 0:00 vim zls[root@zls ~]# ps axo command,nice|grep [v]imvim zls -5
3.使用renice调整已运行程序的优先级
#先查看sshd的优先级[root@zls ~]# ps axo pid,command,nice|grep 折叠shd869 /usr/sbin/sshd -D 01194 sshd: root@pts/0 01307 sshd: root@pts/1 01574 sshd: root@pts/2 0#设置sshd的优先级为-20[root@zls ~]# renice -n -20 869869 (进程 ID) 旧优先级为 0,新优先级为 -20#再次查看sshd的优先级[root@zls ~]# ps axo pid,command,nice|grep 折叠shd869 /usr/sbin/sshd -D -201194 sshd: root@pts/0 01307 sshd: root@pts/1 01574 sshd: root@pts/2 0#一定要退出终端重新连接[root@zls ~]# exit登出#再检查,就可以看到当前终端的优先级变化了[root@zls ~]# ps axo pid,command,nice|grep sshd869 /usr/sbin/sshd -D -201194 sshd: root@pts/0 01574 sshd: root@pts/2 02361 sshd: root@pts/1 -20
四、企业案例,Linux假死是怎么回事
所谓假死,就是能ping通,但是ssh不上去;任何其他操作也都没反应,包括上面部署的nginx也打不开页面。
作为一个多任务操作系统,要把系统忙死,忙到ssh都连不上去,也不是那么容易的。尤其是现在还有fd保护、进程数保护、最大内存保护之类的机制。
你可以fork很多进程,系统会变得很慢,但是ssh还是能连上去;你可以分配很多内存,但是内存多到一定程度oom killer就会把你的进程杀掉,于是ssh又能工作了。
有一个确定可以把系统搞成假死的办法是:主进程分配固定内存,然后不停的fork,并且在子进程里面sleep(100)。
也就是说,当主进程不停fork的时候,很快会把系统的物理内存用完,当物理内存不足时候,系统会开始使用swap;那么当swap不足时会触发oom killer进程;
当oom killer杀掉了子进程,主进程会立刻fork新的子进程,并再次导致内存用完,再次触发oom killer进程,于是进入死循环。而且oom killer是系统底层优先级很高的内核线程,也在参与死循环。
此时机器可以ping通,但是无法ssh上去。这是由于ping是在系统底层处理的,没有参与进程调度;sshd要参与进程调度,但是优先级没oom killer高,总得不到调度。
为什么要费那么大的力气把机器搞死?我们知道假死是怎么产生的即可,这样可以针对假死的原因进行预防。 (其实假死的情况很少发生,只有当代码写的bug很多的情况下会出现。)
其实建议使用nice将sshd的进程优先级调高。这样当系统内存吃紧,还能勉强登陆sshd,进入调试。然后分析故障。
五、后台进程管理
通常进程都会在终端前台运行,但是一旦关闭终端,进程也会随着结束,那么此时我们就希望进程能在后台运行,就是将在前台运行的进程放到后台运行,这样即使我们关闭了终端也不影响进程的正常运行。
企业中很多时候会有一些需求:
1.传输大文件,由于网络问题需要传输很久
2.我们之前的国外业务,国内到国外,网速很慢,我们需要选择节点做跳板机,那么就必须知道,哪个节点到其他地区网速最快,丢包率最低。
3.有些服务没有启动脚本,那么我们就需要手动运行,并把他们放到后台
早期的时候,大家都选择使用&,将进程放到后台运行,然后再使用jobs、bg、fg等方式查看进程状态,太麻烦了,也不只管,所以我们推荐使用screen和nohup
作业控制是一个命令行功能,允许一个 shell 实例来运行和管理多个命令。
如果没有作业控制,父进程 fork()一个子进程后,将 sleeping,直到子进程退出。
使用作业控制,可以选择性暂停,恢复,以及异步运行命令,让 shell 可以在子进程运行期间返回接受其 他命令。
前台进程,后台进程jobs,bg,fg
ctrl + Z , ctrl +c , ctrl + B
[root@zls ~]# sleep 3000 & //运行程序(时),让其在后台执行[root@zls ~]# sleep 4000 //^Z,将前台的程序挂起(暂停)到后台[2]+ Stopped sleep 4000[root@zls ~]# ps aux |grep sleep[root@zls ~]# jobs //查看后台作业[1]- Running sleep 3000 &[2]+ Stopped sleep 4000[root@zls ~]# bg %2 //让作业 2 在后台运行[root@zls ~]# fg %1 //将作业 1 调回到前台[root@zls ~]# kill %1 //kill 1,终止 PID 为 1 的进程[root@zls ~]# (while :; do date; sleep 2; done) & //进程在后台运行,但输出依然在当前终端[root@zls ~]# (while :; do date; sleep 2; done) &>/dev/null &
#安装screen命令[root@zls ~]# yum install -y screen#安装redis[root@zls ~]# yum install -y redis#启动redis[root@zls ~]# redis-server#放到后台ctrl + z[1]+ 已停止 redis-server#关闭终端,redis进程就没有了#下载mysql安装包[root@zls ~]# wget https://downloads.mysql.com/archives/get/file/mysql-5.7.24-linux-glibc2.12-x86_64.tar.gz#使用screen[root@zls ~]# screen -S download_mysqld#ctrl + a + d放置后台[detached from 3567.download_mysqld]#查看screen列表[root@zls ~]# screen -listThere is a screen on:3567.download_mysqld (Detached)1 Socket in /var/run/screen/S-root.#打开screen终端[root@zls ~]# screen -r 3567
六、系统平均负载[进阶]
每次发现系统变慢时,我们通常做的第一件事,就是执行top或者uptime命令,来了解系统的负载情况。
[root@zls ~]# uptime20:45:42 up 8:56, 3 users, load average: 0.01, 0.03, 0.05#我们已经比较熟悉前面几个例子,他们分别是当前时间,系统运行时间,以及正在登陆用户数#后面三个数依次是:过去1分钟,5分钟,15分钟的平均负载(Load Average)
平均负载不就是单位时间内,CPU的使用率嘛?上面的,0.01不就是CPU的使用率是1%
平均负载是指,单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数
PS:平均负载与CPU使用率并没有直接关系。
1.可运行状态进程,是指正在使用CPU或者正在等待CPU的进程,也就是我们用PS命令看的处于R状态的进程
2.不可中断进程,(你在做什么事情的时候是不能被打断的呢?...不可描述)系统中最常见的是等待硬件设备的IO相应,也就是我们PS命令中看到的D状态(也成为Disk Sleep)的进程。
例如:当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,他是不能被其他进程或者中断程序打断的,这个是后续的进程就处于不可中断的状态,如果此时进程强制被打断,kill -9 ... perfect准备好护照吧,有多远,走多远,千万别回来了。不可中断状态实际上是系统对进程和硬件设备的一种保护机制
因此,可以简单理解为,平均负载其实就是单位时间内的活跃进程数。
最理想的状态是每个CPU上都刚还运行着一个进程,这样每个CPU都得到了充分利用。所以在评判负载时,首先你要知道系统有几个CPU,这可以通过top命令获取,或grep 'model name' /proc/cpuinfo
例1:
架设现在在4,2,1核的CPU上,如果平均负载为2时,意味着什么呢?
1.在4个CPU的系统上,意味着CPU有50%空闲。
2.在2个CPU的系统上,以为这所有的CPU都刚好完全被占用。
3.在1个CPU的系统上,则意味着有一半的进程竞争不到CPU。
那么...平均负载有三个数值,我们应该关注哪个呢?
实际上,我们都需要关注,就好比北京5月份的天气,如果只看晚上天气,感觉在过冬天,但是你结合了早上,中午,晚上三个时间点的温度来看,基本就可以全方位的了解这一天的天气情况了。
1.如果1分钟,5分钟,15分钟的三个值基本相同,或者相差不大,那就说明系统负载很平稳。
2.如果1分钟的值远小于15分钟的值,就说明系统像最近1分钟的负载在减少,而过去15分钟内却有很大的负载。
3.反过来,如果1分钟的大于15分钟,就说明最近1分钟的负载在增加,这种增加有可能只是临时的,也有可能还会持续上升...说的跟股票似的。所以要持续观察。(emmmm...一旦K线下降,就拋,割肉)
4.一旦1分钟的平均负载接近或超过了CPU的个数,就意味着,系统正在发生过载的问题,这时候就得分析问题了,并且要想办法优化。
架设我们在有2个CPU系统上看到平均负载为2.73,6.90,12.98那么说明在过去1分钟内,系统有136%的超载(2.73/2100%=136%)
5分钟:(6.90/2100%=345%)
15分钟:(12.98/2*100%=649%)
但整体趋势来看,系统负载是在逐步降低。
当平均负载高于CPU数量70%的时候,你就应该分析排查负载高的问题了,一旦负载过高,就可能导致进程相应变慢,进而影响服务的正常功能。
但70%这个数字并不是绝对的,最推荐的方法,还是把系统的平均负载监控起来,然后根据更多的历史数据,判断负载的变化趋势,当发现负载有明显升高的趋势时,比如说负载翻倍了,你再去做分析和调查。
在实际工作中,我们经常容易把平均负载和CPU使用率混淆,所以在这里,我也做一个区分,可能你会感觉到疑惑,既然平均负载代表的是活跃进程数,那平均负载搞了,不就意味着CPU使用率高嘛?
我们还是要回到平均负载的含义上来,平均负载指的是每单位时间内,处于可运行状态和不可中断状态的进程数,所以,它不仅包括了正在使用CPU的进程数,还包括等待CPU和等待IO的进程数。
而CPU的使用率是单位时间内,CPU繁忙情况的统计,跟平均浮现在并不一定完全对应。
比如:
CPU密集型进程,使用大量的CPU会导致平均负载升高,此时这两者是一致的。
IO密集型进程,等待IO也会导致平均负载升高,但CPU使用率不一定很高。
大量等待CPU的进程调度也会导致平均负载升高,此时的CPU使用率也会比较高。
但是CPU的种类也分两种:
CPU密集型
IO密集型
例如MySQL服务器,就需要尽量选择使用IO密集型CPU
----
下面我们以三个示例分别来看这三中情况,并用:stress、mpstat、pidstat等工具找出平均负载升高的根源
stress是Linux系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景。
mpstat是多核CPU性能分析工具,用来实时检查每个CPU的性能指标,以及所有CPU的平均指标。
pidstat是一个常用的进程性能分析工具,用来实时查看进程的CPU,内存,IO,以及上下文切换等性能指标。
#安装stress命令[root@zls ~]# yum install -y stress
案例一:CPU密集型
我们在第一个中断运行stress命令,模拟一个CPU使用率100%的场景:
#第一个终端执行[root@zls ~]# stress --cpu 1 --timeout 600#第二个终端查看[root@zls ~]# uptime22:04:12 up 10:15, 4 users, load average: 1.98, 0.57, 0.22#高亮显示变化区域[root@zls ~]# watch -d uptimeEvery 2.0s: uptime Sun Jul 14 22:05:16 201922:05:16 up 10:16, 4 users, load average: 2.84, 1.05, 0.41
使用mpstat查看CPU使用率的变化情况
[root@zls ~]# mpstat -P ALL 5Linux 3.10.0-862.el7.x86_64 (zls) 2019年07月14日 _x86_64_ (1 CPU)22时08分51秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle22时08分56秒 all 99.20 0.00 0.80 0.00 0.00 0.00 0.00 0.00 0.00 0.0022时08分56秒 0 99.20 0.00 0.80 0.00 0.00 0.00 0.00 0.00 0.00 0.0022时08分56秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle22时09分01秒 all 99.60 0.00 0.40 0.00 0.00 0.00 0.00 0.00 0.00 0.0022时09分01秒 0 99.60 0.00 0.40 0.00 0.00 0.00 0.00 0.00 0.00 0.00
从终端2可以看到,1分钟平均负载会慢慢增加到2.00,而从终端三中还可以看到,正好有一个CPU的使用率为100%,但他的IOwait只有0,这说明平均负载的升高正式由于CPU使用率为100%,那么到底哪个进程导致CPU使用率为100%呢?可以使用pidstat来查询
#间隔5秒输出一组数据[root@zls ~]# pidstat -u 5 1Linux 3.10.0-862.el7.x86_64 (zls) 2019年07月14日 _x86_64_ (1 CPU)22时14分00秒 UID PID %usr %system %guest %CPU CPU Command22时14分05秒 0 8349 0.00 0.20 0.00 0.20 0 kworker/0:322时14分05秒 0 9903 99.60 0.00 0.00 99.60 0 stress平均时间: UID PID %usr %system %guest %CPU CPU Command平均时间: 0 8349 0.00 0.20 0.00 0.20 - kworker/0:3平均时间: 0 9903 99.60 0.00 0.00 99.60 - stress
案例二:I/O密集型
还是使用stress命令,但是这次模拟IO的压力
[root@zls ~]# stress --io 1 --timeout 600s
在第二个终端运行uptime查看平均负载的变化情况
[root@zls ~]# watch -d uptimeEvery 2.0s: uptime Sun Jul 14 22:17:38 201922:17:38 up 10:28, 4 users, load average: 2.47, 2.25, 1.61
在第三个终端运行mpstat查看CPU使用率的变化情况
[root@zls ~]# mpstat -P ALL 5Linux 3.10.0-862.el7.x86_64 (zls) 2019年07月14日 _x86_64_ (1 CPU)22时19分32秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle22时19分37秒 all 2.78 0.00 97.22 0.00 0.00 0.00 0.00 0.00 0.00 0.0022时19分37秒 0 2.78 0.00 97.22 0.00 0.00 0.00 0.00 0.00 0.00 0.0022时19分37秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle22时19分42秒 all 3.01 0.00 96.99 0.00 0.00 0.00 0.00 0.00 0.00 0.0022时19分42秒 0 3.01 0.00 96.99 0.00 0.00 0.00 0.00 0.00 0.00 0.00#发现CPU与内核打交道的sys占用非常高
那么到底哪个进程导致iowait这么高呢?
[root@zls ~]# pidstat -u 5 1Linux 3.10.0-862.el7.x86_64 (zls) 2019年07月14日 _x86_64_ (1 CPU)22时20分59秒 UID PID %usr %system %guest %CPU CPU Command22时21分04秒 0 6900 0.00 0.20 0.00 0.20 0 kworker/0:022时21分04秒 0 10104 2.76 83.07 0.00 85.83 0 stress22时21分04秒 0 10105 0.00 10.63 0.00 10.63 0 kworker/u256:2平均时间: UID PID %usr %system %guest %CPU CPU Command平均时间: 0 6900 0.00 0.20 0.00 0.20 - kworker/0:0平均时间: 0 10104 2.76 83.07 0.00 85.83 - stress平均时间: 0 10105 0.00 10.63 0.00 10.63 - kworker/u256:2
这时候发现看到的数据比较少,需要更新一下命令:
#下载新版本的包[root@zls ~]# wget http://pagesperso-orange.fr/sebastien.godard/sysstat-11.7.3-1.x86_64.rpm#升级到新版本[root@zls ~]# rpm -Uvh sysstat-11.7.3-1.x86_64.rpm准备中... ################################# [100%]正在升级/安装...1:sysstat-11.7.3-1 ################################# [ 50%]正在清理/删除...2:sysstat-10.1.5-17.el7 ################################# [100%]
然后再次查看结果,明显显示的数据多了
[root@zls ~]# pidstat -u 5 1Linux 3.10.0-862.el7.x86_64 (zls) 2019年07月14日 _x86_64_ (1 CPU)22时24分40秒 UID PID %usr %system %guest %wait %CPU CPU Command22时24分45秒 0 281 0.00 0.20 0.00 0.40 0.20 0 xfsaild/sda322时24分45秒 0 10104 2.99 82.67 0.00 0.00 85.66 0 stress22时24分45秒 0 10105 0.00 8.76 0.00 92.43 8.76 0 kworker/u256:222时24分45秒 0 10118 0.20 0.40 0.00 0.00 0.60 0 watch22时24分45秒 0 10439 0.00 3.98 0.00 94.82 3.98 0 kworker/u256:322时24分45秒 0 11007 0.00 0.20 0.00 0.00 0.20 0 pidstat平均时间: UID PID %usr %system %guest %wait %CPU CPU Command平均时间: 0 281 0.00 0.20 0.00 0.40 0.20 - xfsaild/sda3平均时间: 0 10104 2.99 82.67 0.00 0.00 85.66 - stress平均时间: 0 10105 0.00 8.76 0.00 92.43 8.76 - kworker/u256:2平均时间: 0 10118 0.20 0.40 0.00 0.00 0.60 - watch平均时间: 0 10439 0.00 3.98 0.00 94.82 3.98 - kworker/u256:3平均时间: 0 11007 0.00 0.20 0.00 0.00 0.20 - pidstat
案例三:大量进程的场景
当系统运行进程超出CPU运行能力时,就会出现等待CPU的进程。
1.首先,我们还是使用stress命令,模拟的是多个进程
[root@zls ~]# stress -c 4 --timeout 600
2.由于系统只有一个CPU,明显比4个进程要少的多。因此,系统的CPU处于严重过载状态
[root@zls ~]#Every 2.0s: uptime Sun Jul 14 22:28:50 201922:28:50 up 10:39, 4 users, load average: 3.96, 3.89, 3.00
3.在运行pidstat命令来查看一下进程的情况
[root@zls ~]# pidstat -u 5 1Linux 3.10.0-862.el7.x86_64 (zls) 2019年07月14日 _x86_64_ (1 CPU)22时31分12秒 UID PID %usr %system %guest %wait %CPU CPU Command22时31分17秒 0 11317 24.75 0.00 0.00 75.05 24.75 0 stress22时31分17秒 0 11318 24.95 0.00 0.00 75.45 24.95 0 stress22时31分17秒 0 11319 24.75 0.00 0.00 75.25 24.75 0 stress22时31分17秒 0 11320 24.75 0.00 0.00 75.45 24.75 0 stress22时31分17秒 0 11381 0.20 0.40 0.00 0.00 0.60 0 watch22时31分17秒 0 11665 0.00 0.20 0.00 0.00 0.20 0 pidstat平均时间: UID PID %usr %system %guest %wait %CPU CPU Command平均时间: 0 11317 24.75 0.00 0.00 75.05 24.75 - stress平均时间: 0 11318 24.95 0.00 0.00 75.45 24.95 - stress平均时间: 0 11319 24.75 0.00 0.00 75.25 24.75 - stress平均时间: 0 11320 24.75 0.00 0.00 75.45 24.75 - stress平均时间: 0 11381 0.20 0.40 0.00 0.00 0.60 - watch平均时间: 0 11665 0.00 0.20 0.00 0.00 0.20 - pidstat
总结:
1.平均负载高有可能是CPU密集型进程导致的
2.平均负载高并不一定代表CPU的使用率就一定高,还有可能是I/O繁忙
3.当发现负载高时,可以使用mpstat、pidstat等工具,快速定位到,负载高的原因,从而做出处理
linux 系统管理--进程管理的更多相关文章
- linux系统管理--进程管理
这两天一直维护公司的服务器,主要对进程管理和linux工作管理,把一些零散的知识整理一下,书归正传~ 什么进程? 以下是百度给的解释的进程,说实话,云里雾里的,其实linux进程和windows进程 ...
- [Linux]系统管理: 进程管理(ps/top/pstree/kill/pkill), 工作管理, 系统资源查看, 系统定时任务
进程管理:查看与终止 进程查看 1. 进程是正在执行的程序或命令. 2. 进程管理的作用: 判断服务器健康状态, 查看系统中所有进程 杀死进程 3. 查看系统中所有进程 ps aux # 查看系 ...
- 012-linux系统管理——进程管理与工作管理
linux系统管理——进程管理 top 命令是使用 top - :: up :, user, load average: 0.06, 0.60, 0.48 #五分钟钱,十分钟前,十五分钟前负载的值根据 ...
- Linux操作系统的进程管理
Linux操作系统的进程管理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.进程相关概念 1>.进程概述 内核的功用: 进程管理.文件系统.网络功能.内存管理.驱动程序. ...
- .Neter玩转Linux系列之五:crontab使用详解和Linux的进程管理以及网络状态监控
一.crontab使用详解 概述:任务调度:是指系统在某个时间执行的特定的命令或程序. 任务调度分类: (1)系统工作:有些重要的工作必须周而 复始地执行. (2)个别用户工作:个别用户可能希望执 行 ...
- Linux:进程管理
Linux:进程管理 进程间通信 文件和记录锁定. 为避免两个进程间同时要求访问同一共享资源而引起访问和操作的混乱,在进程对共享资源进行访问前必须对其进行锁定,该进程访问完后再释放.这是UNIX为共享 ...
- Linux操作系统的进程管理和作业管理
Linux操作系统的进程管理和信号 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.lsof命令详解 1>.lsof概述 list open files查看当前系统文件的工 ...
- 【linux之进程管理,系统监控】
一.进程管理 前台进程:一般是指占据着标准输入和/或标准输出的进程后台进程:不占据默认开启的进程都是前台进程ctrl+C 中断ctrl+z 从前台转入后台bg 后台进程编号 让其在后台运行ls -R ...
- Linux内核——进程管理与调度
进程的管理与调度 进程管理 进程描写叙述符及任务结构 进程存放在叫做任务队列(tasklist)的双向循环链表中.链表中的每一项包括一个详细进程的全部信息,类型为task_struct,称为进程描写叙 ...
随机推荐
- struts2中的Action实现的三种方式
Action类创建方式有哪些? 方式一:直接创建一个类,可以是POJO,即原生Java类,没有继承任何类,也没有实现任何接口 这种方式使得strust2框架的代码侵入性更低,但是这种方式是理想状态,开 ...
- java知识链接
Java内存模型简称jmm: 它定义了一个线程对另一个线程是可见的,另外就是共享变量的概念,因为Java内存模型又叫做共享内存模型,也就是多个线程会同时访问一个变量,这个变量又叫做共享变量, 共享变量 ...
- 【JVM】JVM参数
JVM参数的含义 参数名称 含义 默认值 -Xms 初始堆大小 物理内存的1/64(<1GB) 默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆 ...
- android智能手机如何查看APK包名
工具/原料 智能手机一部 USB线一根 方法/步骤 1 首先.使用USB线,将电脑和手机连起来.注意.手机的USB调试默认需要打开,如下图所示. 2 然后启动电脑端的cmd应用,进入dos界面 ...
- Oracle分组函数之ROLLUP
功能介绍: 首先是进行无字段的聚合,然后在对字段进行从左到右依次组合后聚合 创建表: Create Table score ( classID Int, studentName ), subject ...
- HDU 6034 Balala Power! —— Multi-University Training 1
Talented Mr.Tang has nn strings consisting of only lower case characters. He wants to charge them wi ...
- 【HDOJ6606】Distribution of books(二分,BIT)
题意:给定一个长为n的数组,要求挑它前缀的一段,将其分成k段,使得每段和的最大值最小 1<=k<=n<=2e5,abs(a[i])<=1e9 思路: 刚开始写了线段树TLE 改 ...
- Linux 性能检测常用的10个基本命令
1. uptime $ uptime 23:51:26 up 21:31, 1 user, load average: 30.02, 26.43, 19.0212 该命令可以大致的看出计算机的整体 ...
- python的os.path.join()
在python中,os.path.join()是用来拼接目录路径得.同类型得还有join(),os.path.spilt(),spilt()三个函数.1,os.path.join(),将join()里 ...
- ALM11服务器IP变更相关配置修改
最近项目新增了网络控制,需要把ALM服务器迁移到新的区域.服务器整体复制后更改了IP地址. ALM与Oracle在同一台服务器(windows server 2008 R2) ALM的配置也需要做如下 ...