大数据笔记(十三)——常见的NoSQL数据库之HBase数据库(A)
一.HBase的表结构和体系结构
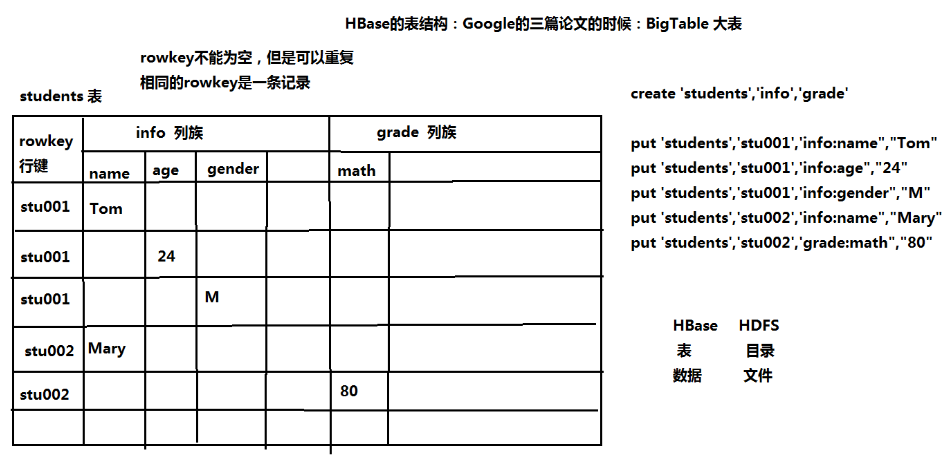
1.HBase的表结构
把所有的数据存到一张表中。通过牺牲表空间,换取良好的性能。
HBase的列以列族的形式存在。每一个列族包括若干列
2.HBase的体系结构
主从结构:
主节点:HBase
从节点:RegionServer 包含多个Region,一个列族就是一个Region
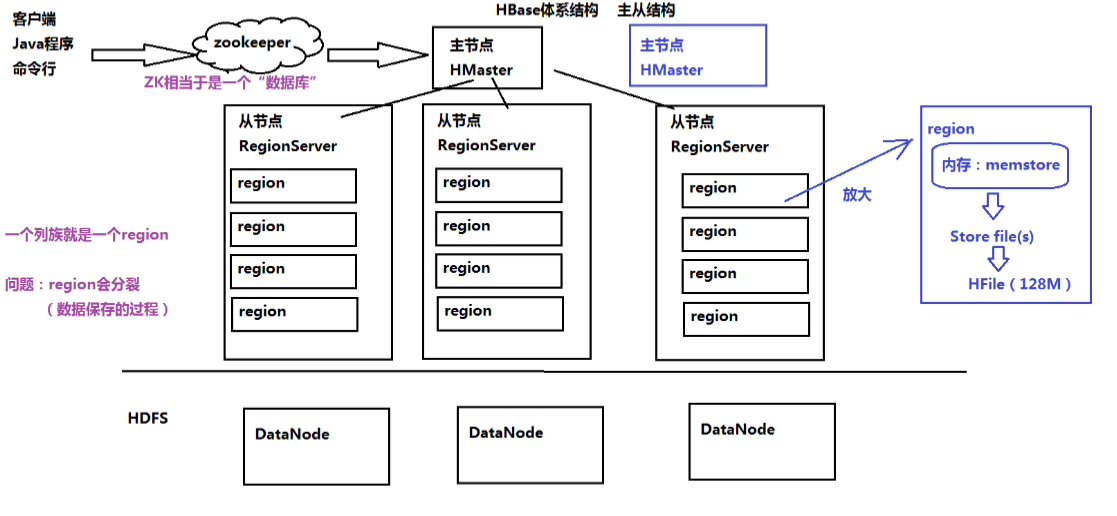
HBase在ZK中保存数据
(*)配置信息、HBase集群结构信息
(*)表的元信息
(*)实现HBase的HA:high avaibility 高可用性
二.搭建HBase的本地模式和伪分布模式
1.解压:
tar -zxvf hbase-1.3.1-bin.tar.gz -C ~/training/
2.设置环境变量: vi ~/.bash_profile
HBASE_HOME=/root/training/hbase-1.3.1
export HBASE_HOME PATH=$HBASE_HOME/bin:$PATH
export PATH
使文件生效:source ~/.bash_profile
本地模式 不需要HDFS、直接把数据存在操作系统
hbase-env.sh
export JAVA_HOME=/root/training/jdk1.8.0_144
hbase-site.xml
<property>
<name>hbase.rootdir</name>
<value>file:///root/training/hbase-1.3.1/data</value>
</property>
伪分布模式
hbase-env.sh 添加下面这一行,使用自带的Zookeeper
export HBASE_MANAGES_ZK=true
hbase-site.xml 把本地模式的property删除,添加下列配置
<property>
<name>hbase.rootdir</name>
<value>hdfs://192.168.153.11:9000/hbase</value>
</property> <property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property> <property>
<!--Zookeeper的地址-->
<name>hbase.zookeeper.quorum</name>
<value>192.168.153.11</value>
</property> <property>
<!--数据冗余度-->
<name>dfs.replication</name>
<value>1</value>
</property>
regionservers
192.168.153.11
可以在web上查看
三.搭建HBase的全分布模式和HA
在putty中设置bigdata12 bigdata13 bigdata14 时间同步:date -s 2018-03-10
主节点:hbase-site.xml
<property>
<name>hbase.rootdir</name>
<value>hdfs://192.168.153.12:9000/hbase</value>
</property> <property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property> <property>
<name>hbase.zookeeper.quorum</name>
<value>192.168.153.12</value>
</property> <property>
<name>dfs.replication</name>
<value>2</value>
</property> <property>
<!--解决时间不同步的问题:允许的时间误差最大值-->
<name>hbase.master.maxclockskew</name>
<value>180000</value>
</property>
regionservers
192.168.154.13
192.168.153.14
拷贝到13和14上:
scp -r hbase-1.3.1/ root@bigdata13:/root/training
scp -r hbase-1.3.1/ root@bigdata14:/root/training
四.HBase在Zookeeper中保存的数据和HA的实现

HA的实现:
不需要额外配置,只用在其中一个从节点上单点启动Hmaster
bigdata13:hbase-daemon.sh start master
五.操作HBase
1.Web Console网页:端口:16010
2.命令行
开启hbase: start-hbase.sh
开启hbase shell
建表:
hbase(main):001:0> create 'students','info','grade' //创建表
0 row(s) in 1.7020 seconds => Hbase::Table - students
hbase(main):002:0> desc 'students' //查看表结构
Table students is ENABLED
students
COLUMN FAMILIES DESCRIPTION
{NAME => 'grade', BLOOMFILTER => 'ROW', VERSIONS => '', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODIN
G => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '', BLOCKCACHE => 'true', BLOCKSIZE => '', REPLICATI
ON_SCOPE => ''}
{NAME => 'info', BLOOMFILTER => 'ROW', VERSIONS => '', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING
=> 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '', BLOCKCACHE => 'true', BLOCKSIZE => '', REPLICATIO
N_SCOPE => ''}
2 row(s) in 0.2540 seconds hbase(main):003:0> describe 'students'
Table students is ENABLED
students
COLUMN FAMILIES DESCRIPTION
{NAME => 'grade', BLOOMFILTER => 'ROW', VERSIONS => '', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODIN
G => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '', BLOCKCACHE => 'true', BLOCKSIZE => '', REPLICATI
ON_SCOPE => ''}
{NAME => 'info', BLOOMFILTER => 'ROW', VERSIONS => '', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING
=> 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '', BLOCKCACHE => 'true', BLOCKSIZE => '', REPLICATIO
N_SCOPE => ''}
2 row(s) in 0.0240 seconds
desc和describe的区别:
desc是SQL*PLUS语句
describe是SQL语句
分析students表的结构

查看有哪些表:list
插入数据:put
put 'students','stu001','info:name','Tom'
put 'students','stu001','info:age',''
put 'students','stu001','grade:math',''
put 'students','stu002','info:name','Mary'
put 'students','stu002','info:age',''
查询数据:
scan 相当于:select * from students

get 相当于 select * from students where rowkey=??
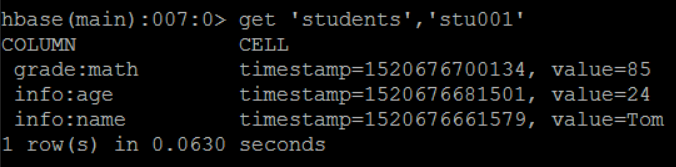
清空表中的数据
delete DML(可以回滚)
truncate DDL(不可以回滚)
补充:DDL:数据定义语言,如 create/alter/drop/truncate/comment/grant等
DML:数据操作语言,如select/delete/insert/update/explain plan等
DCL:数据控制语言,如commit/roollback
2、delete会产生碎片;truncate不会
3、delete不会释放空间;truncate会
4、delete可以闪回(flashback),truncate不可以闪回
truncate 'students' -----> 本质: 先删除表,再重建
日志:
Truncating 'students' table (it may take a while):
- Disabling table...
- Truncating table...
0 row(s) in 4.0840 seconds
3.JAVA API
修改etc文件:C:\Windows\System32\drivers\etc
添加一行:192.168.153.11 bigdata11
TestHBase.java
package demo; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.Test; import io.netty.util.internal.SystemPropertyUtil; /**
* 1.需要一个jar包: hamcrest-core-1.3.jar
* 2.修改windows host文件
* C:\Windows\System32\drivers\etc\hosts
* 192.168.153.11 bigdata11
* @author YOGA
*
*/
public class TestHBase { @Test
public void testCreateTable() throws Exception{
//配置ZK的地址信息
Configuration conf = new Configuration();
//hbase-site.xml文件里
conf.set("hbase.zookeeper.quorum", "192.168.153.11"); //得到HBsase客户端
HBaseAdmin client = new HBaseAdmin(conf); //创建表的描述符
HTableDescriptor htd = new HTableDescriptor(TableName.valueOf("mytable")); //添加列族
htd.addFamily(new HColumnDescriptor("info"));
htd.addFamily(new HColumnDescriptor("grade")); //建表
client.createTable(htd); client.close();
} @Test
public void testPut() throws Exception{
//配置ZK的地址信息
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "192.168.153.11"); //得到HTable客户端
HTable client = new HTable(conf, "mytable"); //构造一个Put对象,参数:rowKey
Put put = new Put(Bytes.toBytes("id001"));
//put.addColumn(family, //列族
// qualifier, //列
// value) ֵ//列对应的值
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes("Tom")); client.put(put);
//client.put(List<Put>);
client.close();
} @Test
public void testGet() throws Exception{
//配置ZK的地址信息
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "192.168.153.11"); //得到HTable客户端
HTable client = new HTable(conf, "mytable"); //构造一个Get对象
Get get = new Get(Bytes.toBytes("id001")); //查询
Result result = client.get(get); //取出数据
String name = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")));
System.out.println(name); client.close();
} @Test
public void testScan() throws Exception{
//配置ZK的地址信息
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "192.168.153.11"); //得到HTable客户端
HTable client = new HTable(conf, "mytable"); //定义一个扫描器
Scan scan = new Scan();
//scan.setFilter(filter); 定义一个过滤器 //通过扫描器查询数据
ResultScanner rScanner = client.getScanner(scan); for (Result result : rScanner) {
String name = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")));
System.out.println(name);
}
}
}
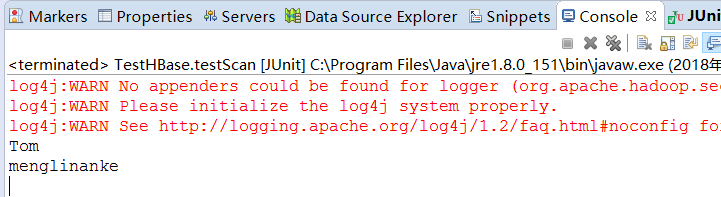
执行以上test,结果(最后一个)


大数据笔记(十三)——常见的NoSQL数据库之HBase数据库(A)的更多相关文章
- 大数据架构师必读的NoSQL建模技术
大数据架构师必读的NoSQL建模技术 从数据建模的角度对NoSQL家族系统做了比较简单的比较,并简要介绍几种常见建模技术. 1.前言 为了适应大数据应用场景的要求,Hadoop以及NoSQL等与传统企 ...
- 大数据笔记(二十一)——NoSQL数据库之Redis
一.Redis内存数据库 一个key-value存储系统,支持存储的value包括string(字符串).list(链表).set(集合).zset(sorted set--有序集合)和hash(哈希 ...
- 转:甲骨文发布大数据解决方案 含最新版NoSQL数据库
原文出处: http://www.searchdatabase.com.cn/showcontent_88247.htm 以下是部分节选: 最新发布的大数据创新成果包括: Oracle Big Dat ...
- 大数据笔记(一)——Hadoop的起源与背景知识
一.大数据的5个特征(IBM提出): Volume(大量) Velocity(高速) Variety(多样) Value(价值) Varacity(真实性) 二.OLTP与OLAP 1.OLTP:联机 ...
- 【大数据应用技术】作业九|安装关系型数据库MySQL 安装大数据处理框架Hadoop
本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 1.安装MySql 按ctrl+alt+t打开终端窗口,安 ...
- 大数据笔记01:大数据之Hadoop简介
1. 背景 随着大数据时代来临,人们发现数据越来越多.但是如何对大数据进行存储与分析呢? 单机PC存储和分析数据存在很多瓶颈,包括存储容量.读写速率.计算效率等等,这些单机PC无法满足要求. 2. ...
- 大数据笔记(十九)——数据采集引擎Sqoop和Flume安装测试详解
一.Sqoop数据采集引擎 采集关系型数据库中的数据 用在离线计算的应用中 强调:批量 (1)数据交换引擎: RDBMS <---> Sqoop <---> HDFS.HBas ...
- 开源大数据技术专场(上午):Spark、HBase、JStorm应用与实践
16日上午9点,2016云栖大会“开源大数据技术专场” (全天)在阿里云技术专家封神的主持下开启.通过封神了解到,在上午的专场中,阿里云高级技术专家无谓.阿里云技术专家封神.阿里巴巴中间件技术部高级技 ...
- 大数据之 ZooKeeper原理及其在Hadoop和HBase中的应用
ZooKeeper是一个开源的分布式协调服务,由雅虎创建,是Google Chubby的开源实现.分布式应用程序可以基于ZooKeeper实现诸如数据发布/订阅.负载均衡.命名服务.分布式协调/通知. ...
- 大数据学习系列之八----- Hadoop、Spark、HBase、Hive搭建环境遇到的错误以及解决方法
前言 在搭建大数据Hadoop相关的环境时候,遇到很多了很多错误.我是个喜欢做笔记的人,这些错误基本都记载,并且将解决办法也写上了.因此写成博客,希望能够帮助那些搭建大数据环境的人解决问题. 说明: ...
随机推荐
- 【查阅】mysql配置文件/参数文件重要参数笔录(my.cnf)
持续更新,积累自己对参数的理解 [1]my.cnf参数 [client]port = 3306socket = /mysql/data/3306/mysql.sockdefault-character ...
- Boostrap4 li列表橫向
Boostrap3 li元素橫向: <ul class="nav navbar-nav list-inline"> <li class="list-in ...
- 拦截器Interceptor和过滤器Filter的区别
(1)过滤器(Filter):当你有一堆东西的时候,你只希望选择符合你要求的某一些东西.定义这些要求的工具,就是过滤器.(理解:就是一堆字母中取一个B) (2)拦截器(Interceptor):在一个 ...
- ModelForm操作
ModelForm a. class Meta: model, # 对应Model的 fields=None, # 字段 exclude=None, # 排除字段 labels=None, # 提示信 ...
- 剑指offer 分行从上到下打印二叉树
题目: 从上到下按层打印二叉树,同一层的节点按照从左到右的顺序打印,每一层打印到一行. /* struct TreeNode { int val; struct TreeNode *left; str ...
- luogu P5329 [SNOI2019]字符串
传送门 显然要写一个排序,那只要考虑cmp函数怎么写就行了.第\(i\)个字符串和第 \(j\)个,首先前\(min(i,j)-1\)个字符是相同的,然后就是要比较后缀\(min(i,j)\)和\(m ...
- 【学习总结】快速上手Linux玩转典型应用-第1章-课程介绍
课程目录链接 快速上手Linux玩转典型应用-目录 1. Linux有什么用 2. 课程安排 3. 课程收获 基本运维能力,等等 END
- python 快速排序实现
# -*- coding: utf-8 -*- def quicksort(array): # 基线条件:为空或只包含一个元素的数组是"有序"的 if len(array) < ...
- SpringBoot项目优化和Jvm调优
https://www.cnblogs.com/jpfss/p/9753215.html 项目调优 作为一名工程师,项目调优这事,是必须得熟练掌握的事情. 在SpringBoot项目中,调优主要通过配 ...
- Result window is too large, from + size must be less than or equal to: [10000] but was [78440]. See the scroll api for a more efficient way to request large data sets
{"error":{"root_cause":[{"type":"query_phase_execution_exception& ...