JVM(10)之 年老代收集器

在上一篇博文我们介绍了JAVA新生代收集器,本篇博文我们要讲的就是关于老年代的一些收集器。老年代存活的一般是大对象以及生命很顽强的对象,因此新生代的复制算法很明显不能适应该区域的特性,所以老年代采用的是“标记-清除-整理”算法(以前的博文有详细讨论过)。
- Serila Old收集器:该收集器是Serial收集器的老年代版,同样是一个单线程的收集器,优劣势和Serial收集器一样,这里就不多说了。
- Parallel Old收集器:在我们之前文章的代码例子中默认的年老代收集器,也是Parallel Scavenge收集器的老年代版本。关注点也和Parallel Scavenge收集器一样,注重系统的吞吐量,适合于CPU资源敏感的场合。
- CMS(Concurrent Mark Sweep)收集器:是一种以最短停顿时间为目标的收集器。当应用尤其重视服务的响应速度,希望系统能有最短的停顿时间,该收集器非常适合。
CMS收集器的收集过程比以往的收集器都要复杂,收集过程分为四个步骤:初始标记、并发标记、重新标记、并发清除。
先介绍下每个过程,再来说他是怎么达到最短停顿时间这个目标的。初始标记是需要进行STW的,但仅仅只是标记GC Roots能够直接关联的对象(并不是死掉的对象哦~),由于有OopMap的存在,因此该步骤速度非常快。如图,其中蓝色底纹的便是能够直接关联的对象。 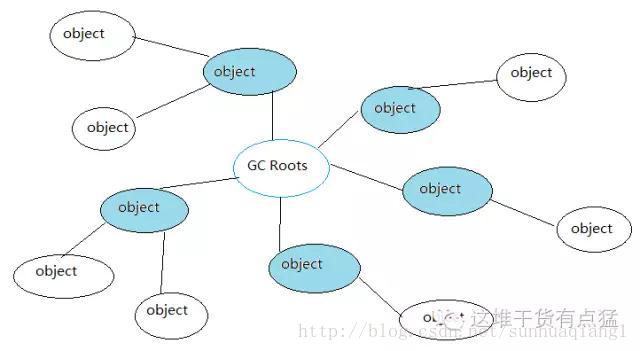
接着就进入了第二步,并发标记。这步是不需要STW的,不需要!他和我们的主程序线程共同执行,从上一步被标记的对象开始,进行可达性分析组成“关系网”。由于不需要进行SWT,所以该步骤不会影响用户体验。既然不暂停线程,小伙伴是不是又怕回收了不该回收的对象?为了避免这个问题,因此就有了第三步。
重新标记是需要STW的,但这又有什么关系呢?重新标记只是为了修改在上一步标记中有了变动的对象。有了这一步,就不怕回收掉不该回收的对象了。而且,由于这一步只是对上一步的结果进行修改,所以STW的时间相当短,对用户的影响不大。
最后一步就是并发清除了,这一步也不需要进行STW,只是清除一些不在“关系网”上的对象而已。
讲到这里,大家应该知道了该收集器如何做到最短停顿时间了吧。通过一次短STW时间的标记和一次不需要STW的标记,大大缩下来第三步标记的范围(只需要修改就好了),第四步不需要STW。
看上去很完美,但还是有他的缺陷:大量使用了并发操作,因此会占用一部分CPU的资源,导致吞吐量下降;当在并发清除垃圾的时候,也就是第四步的时候,他是与当前主线程并发执行的,因此他在回收的时候,我们的主线程又会产生新的垃圾,而这些垃圾在这次回收过程已经回收不了了,只能等待下一次回收了。这些垃圾又叫做“浮动垃圾”。
到这里我们就把老年代的收集器也讲完啦,不知道小伙伴们吸收消化的怎样。学习更重要的还是靠自己的努力与勤奋,别人能给点毕竟有限,自己挖掘才能发现无尽!
JVM(10)之 年老代收集器的更多相关文章
- JAVA 年老代收集器 第10节
JAVA 年老代收集器 第10节 上一章我们讲了新生代的收集器,那么这一章我们要讲的就是关于老年代的一些收集器.老年代的存活的一般是大对象以及生命很顽强的对象,因此新生代的复制算法很明显不能适应该区域 ...
- JVM(9)之 年轻代收集器
开发十年,就只剩下这套架构体系了! >>> 继续上一篇博文所讲的,STW即GC时候的停顿时间,他会暂停我们程序中的所有线程.如果STW所用的时间长而且次数多的话,那么我们整个系统 ...
- JAVA 年轻代收集器 第九节
JAVA 年轻代收集器 第九节 继续上一章所讲的,STW即GC时候的停顿时间,他会暂停我们程序中的所有线程.如果STW所用的时间长而且次数多的话,那么我们整个系统稳定性以及可用性将大大降低. 因此我 ...
- JVM学习记录3--垃圾收集器
贴个图 Serial收集器 最简单的收集器,单线程,收集器会暂停用户线程,称为"stop the world". ParNew收集器 Serial收集器的多线程版本,其它类似.默认 ...
- JVM垃圾回收之CMS收集器
从前文JVM垃圾回收几种常见算法和常见收集器我们知道,CMS是老年代垃圾收集器.CMS 收集器主要关注系统停顿时间.CMS 是 Concurrent Mark Sweep 的缩写,意为并发标记清除,从 ...
- JVM垃圾收集算法——分代收集算法
分代收集算法(Generational Collection): 当前商业虚拟机的垃圾收集都采用"分代收集算法". 这种算法并没有什么新的思想,只是根据对象存活周期的不同将内存划分 ...
- JVM的stack和heap,JVM内存模型,垃圾回收策略,分代收集,增量收集
(转自:http://my.oschina.net/u/436879/blog/85478) 在JVM中,内存分为两个部分,Stack(栈)和Heap(堆),这里,我们从JVM的内存管理原理的角度来认 ...
- 《深入理解java虚拟机》笔记(7)JVM调优(分代垃圾收集器)
以下配置主要针对分代垃圾回收算法而言. 一.堆大小设置 年轻代的设置很关键 JVM中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制:系统的可用虚拟内存限制:系统的可用 ...
- Java GC收集器配置说明
根据Java GC收集器具体分类,我们可以看出JVM根据需求不同提供了三种选择:串行收集器.并行收集器.并发收集器. 串行收集器只适用于小数据量的情况,我们主要了解一下并行收集器和并发收集器.默认情况 ...
随机推荐
- Linux性能优化从入门到实战:01 Linux性能优化学习路线
我通过阅读各种相关书籍,从操作系统原理.到 Linux内核,再到硬件驱动程序等等. 把观察到的性能问题跟系统原理关联起来,特别是把系统从应用程序.库函数.系统调用.再到内核和硬件等不同的层级贯 ...
- 14DBCP连接池
实际开发中“获得连接”或“释放资源”是非常消耗系统资源的两个过程,为了解决此类性能问题,通常情况我们采用连接池技术,来共享连接Connection.这样我们就不需要每次都创建连接.释放连接了,这些操作 ...
- alert(1) to win 9
function escape(s) { function htmlEscape(s) { return s.replace(/./g, function(x) { return { '<': ...
- 对async 函数的研究
async 函数 1.ES2017 标准引入了 async 函数,使得异步操作变得更加方便. async 函数是什么?一句话,它就是 Generator 函数的语法糖. 前文有一个 Generator ...
- Centos6安装mysql
此处安装的是MariaDB,介绍如下: MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可. 开发这个分支的原因之一是:甲骨文公司收购了MySQL后,有将My ...
- linux运维、架构之路-Nginx反向代理
一. Nginx负载均衡和反向代理知识 1.集群概念 一堆服务器合作做同一件事,这些机器可能需要整个技术团队架构.设计和统一协调管理,这些机器可以分布在一个机房,也可以分布在全国各个地区的多个机房 ...
- php substr_count()函数 语法
php substr_count()函数 语法 作用:统计一个字符串,在另一个字符串中出现次数大理石量具 语法:substr_count(string,substring,start,length) ...
- hdu 4641K-string SAM的O(n^2)算法 以及 SAM+并查集优化
转载:http://www.cnblogs.com/hxer/p/5675149.html 题意:有一个长度为n(n < 5e4)的字符串,Q(Q<=2e5)次操作:操作分为:在末尾插入一 ...
- POJ 2502 Subway ( 最短路 && 最短路建图 )
题意 : 给出二维平面上的两个点代表起点以及终点,接下来给出若干条地铁线路,除了在地铁线路上行进的速度为 40km/h 其余的点到点间都只能用过步行且其速度为 10km/h ,现问你从起点到终点的最短 ...
- ubuntu 18.04下修改pip镜像源
在home/用户名/目录下创建.pip文件夹 然后cd .pip 创建pip.conf文件touch pip.conf 输入以下内容然后保存即可 [global] timeout = 6000 ind ...