[论文理解] Attentional Pooling for Action Recognition
Attentional Pooling for Action Recognition
简介
这是一篇NIPS的文章,文章亮点是对池化进行矩阵表示,使用二阶池的矩阵表示,并将权重矩阵进行低秩分解,从而使分解后的结果能够自底向上和自顶向下的解释,并巧用attention机制来解释,我感觉学到了很多东西,特别是张量分解等矩阵论的知识点。
基础概念
低秩分解
目的:去除冗余并减少模型的权值参数
方法:使用两个K*1的卷积核代替掉一个K*K的卷积核
原理:权值向量主要分布在一些低秩子空间,使用少量的基就可以恢复权值矩阵
数学公式(本文):
\]
这样就用两个1*f的矩阵去表示原来的f*f的矩阵,本文中是将矩阵做 rank-1分解,也就是分解后的矩阵a和b的秩为1,当然也需要做多组实验确定分解的秩为多少最合适。
普通池化
普通池化可以用下面的公式来表示(n = 16*16 = 256,是特征宽高乘积,f为特征通道数):
\]
可以理解为先对特征进行在空间维度上进行全局求和,得到f个结果,然后再对这些结果利用权值矩阵加权求和就得到最终的pooling结果,pooling的结果为一个scalar。
一般avgpooling可以将该式特殊化,也就是X为n*1的张量,对每个通道执行同样的操作,1和w矩阵都是常值。maxpooling的1矩阵不为全1,最大值对应的那个位置为1.
二阶池
本文提出了二阶池的方法,具体如下:
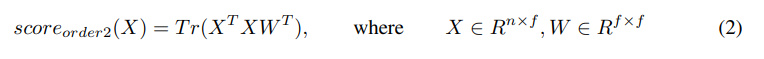
这里我直接从论文中拷出来了,没有自己手打。
这里文章说到二阶池对fine-grained classification的结果有帮助,然后把W做低秩分解,公式就变成了:

其中利用到了矩阵Tr的特点就不解释了。
那么这样分解有什么好处呢? 我觉得这就是本文的一个精髓,可以自顶向下和自底向上来解释公式,公式的可解释性为本文加分很多。
自底向上解释
我们看到公式(6)里先算的是Xb,这里得到的结果是一个n*1的矩阵,这个矩阵刚好可以看成一个attention map,那么作者对他的解释就是由底层特征到高层特征映射过程中生成的attention map,用于评估位置特征。并且,这里的b是针对每个类别都一样的,所以可以自底向上解释,而a是每个类别要学习一个特定的a,所以a的解释是自顶向下的。
自顶向下解释
如上所说,自顶向下解释主要是对a的解释,从上面的公式其实已经可以自底向上解释了,但是作者又做了一步化简:
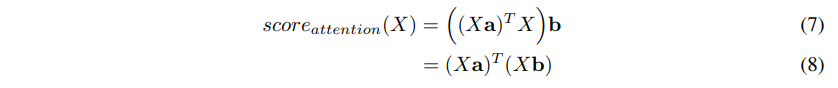
这里我们看到公式被化成了(8)式,这样其实更加直观,Xa得到的是自顶向下与类别相关的结果,而Xb得到的则是自底向上的与类别无关的结果,两者做矩阵乘,得到最终的结果。这种分解方法我感觉很奇妙,而且解释性非常好。
拓展-张量分解
详见博客:http://www.xiongfuli.com/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/2016-06/tensor-decomposition-cp.html
CP分解
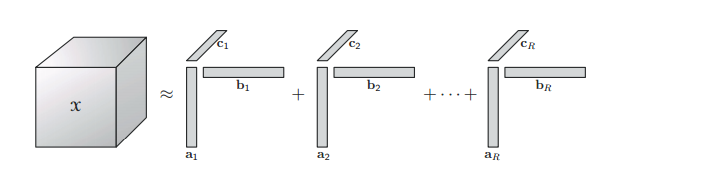
可以对张量做低秩近似,所以这里也可以做很多工作。
Tucker分解

也是一样的。上面那篇博客讲的很详细。也是可以做低秩近似。
所以这个方向是个很神奇的方向,我觉得后面可以做很多东西。需要深厚的数学功底。
网络结构
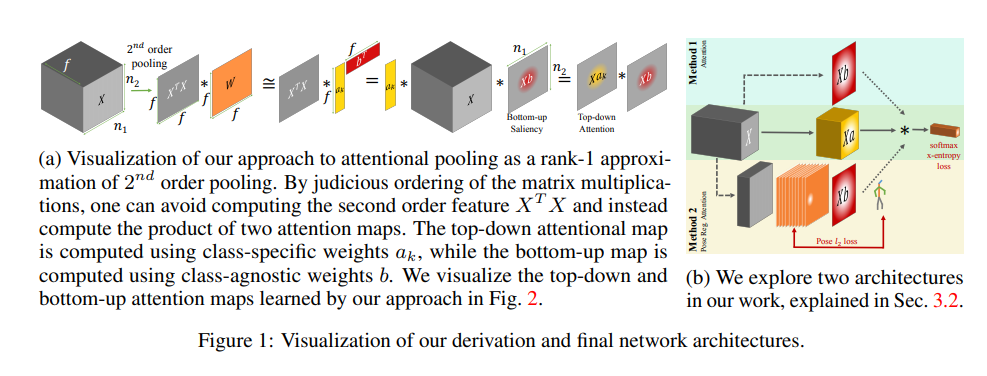
一张图带过吧。因为本位是做human pose的,所以网络结构是针对pose的。结构非常简单,用了两种方法,我们看一下method 2吧。
直接映射到17个channel的特征层,前十六个是pose map,用于预测关键点的,最后一个是attention map,这里的attention map是pose map的by-product,也就是说利用pose map去帮助分类,所以attention map再与Xa作用,最终的结果做分类,这样的一个思路。
后面实验就不看了,我也不是做这个的。。
结论
二阶池对局部特征的描述更加丰富。
低秩分解可以用来做attention。
Coding
自己实现一下文章中的method 2吧。
'''
@Descripttion: This is Aoru Xue's demo, which is only for reference.
@version:
@Author: Aoru Xue
@Date: 2019-10-27 13:11:23
@LastEditors: Aoru Xue
@LastEditTime: 2019-10-27 13:18:40
'''
import torch
import torch.nn as nn
from torchsummary import summary
from torch.autograd import Variable
class AttentionalPolling(nn.Module):
def __init__(self):
super(AttentionalPolling, self).__init__()
self.conv = nn.Conv2d(128,16,kernel_size = 1)
self.a = Variable(torch.randn(1,10,128,1))
self.b = Variable(torch.randn(1,128,1))
def forward(self,x):
feat = self.conv(x)
# (64*64,128) @ (128,1) -> (64*64,1)
#print(x.permute(0,2,3,1).view(-1,64*64,128).size())
xb = x.permute(0,2,3,1).contiguous().view(-1,64*64,128) @ self.b
#print(xb.size())
xa = x.permute(0,2,3,1).contiguous().view(-1,1,64*64,128) @ self.a
xa = xa.permute(0,1,3,2).contiguous().view(-1,10,1,4096)
xb = xb.view(-1,1,4096,1)
output = xa @ xb
print(output.size())
return output.view(-1,10)
if __name__ == "__main__":
net = AttentionalPolling()
summary(net,(128,64,64),device = "cpu") # feature X
'''
torch.Size([2, 10, 1, 1])
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 16, 64, 64] 2,064
================================================================
Total params: 2,064
Trainable params: 2,064
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 2.00
Forward/backward pass size (MB): 0.50
Params size (MB): 0.01
Estimated Total Size (MB): 2.51
----------------------------------------------------------------
'''
论文原文:https://arxiv.org/pdf/1711.01467v2.pdf
[论文理解] Attentional Pooling for Action Recognition的更多相关文章
- 【CV论文阅读】Rank Pooling for Action Recognition
这是期刊论文的版本,不是会议论文的版本.看了论文之后,只能说,太TM聪明了.膜拜~~ 视频的表示方法有很多,一般是把它看作帧的序列.论文提出一种新的方法去表示视频,用ranking function的 ...
- [论文理解]Selective Search for Object Recognition
Selective Search for Object Recognition 简介 Selective Search是现在目标检测里面非常常用的方法,rcnn.frcnn等就是通过selective ...
- 论文列表 for Action recognition
要读的论文: https://www.cnblogs.com/hizhaolei/p/10565405.html 骨架动作识别论文汇总 https://blog.csdn.net/bianxuewei ...
- 201904Online Human Action Recognition Based on Incremental Learning of Weighted Covariance Descriptors
论文标题:Online Human Action Recognition Based on Incremental Learning of Weighted Covariance Descriptor ...
- 论文笔记 | A Closer Look at Spatiotemporal Convolutions for Action Recognition
( 这篇博文为原创,如需转载本文请email我: leizhao.mail@qq.com, 并注明来源链接,THX!) 本文主要分享了一篇来自CVPR 2018的论文,A Closer Look at ...
- 【CV论文阅读】+【搬运工】LocNet: Improving Localization Accuracy for Object Detection + A Theoretical analysis of feature pooling in Visual Recognition
论文的关注点在于如何提高bounding box的定位,使用的是概率的预测形式,模型的基础是region proposal.论文提出一个locNet的深度网络,不在依赖于回归方程.论文中提到locne ...
- 【论文笔记】Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition 2018-01-28 15:4 ...
- Recent papers on Action Recognition | 行为识别最新论文
CVPR2019 1.An Attention Enhanced Graph Convolutional LSTM Network for Skeleton-Based Action Recognit ...
- Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition (ST-GCN)
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition 摘要 动态人体骨架模型带有进行动 ...
随机推荐
- Hadoop网页监控配置
接之前的内容http://www.cnblogs.com/jourluohua/p/8734406.html 在之前那的内容中,仅实现了Hadoop的安装和运行,距离实际使用还有很远.现在先完成一个小 ...
- mysql5.5.x.zip 解压版安装教程
一,前言 记一次安装解压版的mysql 5.5的经过,参考了一些文章,也遇到了一些错误,最终都安装成功了.在这里记录一下安装的过程,一方面自己做一个记录,领一方面给大家提供一份参考. 二,环境 1,w ...
- idea中 参数没有描述报错 @param XX tag description is missing错误,去除黄色警告
最近在使用idea开发工具,在方法备注中参数没有描述报错就会报一些黄色警告: @param XX tag description is missing,下面展示去除黄色警告的方法 File--sett ...
- 六、取消eslint 校验代码
一.取消eslint 校验代码 删除 "eslintConfig": { "root": true, "env": { "node ...
- 关于STM32中printf函数的重定向问题
printf函数一般是打印到终端的,stm32芯片调试中经常需要用到串口来打印调试信息,那能不能用串口实现类似windows的Console中的printf呢? 答案是肯定的,那就是printf函数的 ...
- 关于Vue-$router传参出现刷新页面或者返回页面丢失数据的问题
也算是踩到坑了,但不是我踩到的,不过还是得说下这个问题,很严重,对于小白和初学者是比较有帮助的,如果使用到路由传参,请选择你想要的传参方式params或者query 1.query this.$rou ...
- Python with open 使用技巧
在使用Python处理文件的是,对于文件的处理,都会经过三个步骤:打开文件->操作文件->关闭文件.但在有些时候,我们会忘记把文件关闭,这就无法释放文件的打开句柄.这可能觉得有些麻烦,每次 ...
- 【bzoj 4046 加强版】Pork barrel
刚考完以为是神仙题--后来发现好像挺蠢的-- QwQ 题意 给你一张 \(n\) 个点 \(m\) 条边的无向图(不一定连通),有 \(q\) 组询问,每组询问给你 \(2\) 个正整数 \(l,h\ ...
- maven项目引入外部jar包
方式1:dependency 本地jar包 <dependency> <groupId>com.hope.cloud</groupId> <!--自定义--& ...
- Mongodb索引和执行计划 hint 慢查询
查询索引 索引存放在system.indexes集合中 > show tables address data person system.indexes 默认会为所有的ID建上索引 而且无法删除 ...