机器学习分类算法之K近邻(K-Nearest Neighbor)
一、概念
KNN主要用来解决分类问题,是监督分类算法,它通过判断最近K个点的类别来决定自身类别,所以K值对结果影响很大,虽然它实现比较简单,但在目标数据集比例分配不平衡时,会造成结果的不准确。而且KNN对资源开销较大。
二、计算
通过K近邻进行计算,需要:
1、加载打标好的数据集,然后设定一个K值;
2、计算预测对象与打标对象的欧式距离,
欧氏距离是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式:
二维平面上两点a(x1,y1)与b(x2,y2)间的欧氏距离:
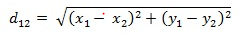
三维空间两点a(x1,y1,z1)与b(x2,y2,z2)间的欧氏距离:

两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的欧氏距离:
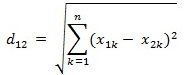
import math
import operator def get_distance(vect_test, vect_train):
distance = 0
for i in range(len(vect_test)):
distance = pow((vect_test[i] - vect_train[i]), 2)
return math.sqrt(distance) def get_neighbor(vect_test, train_vect_set, k):
distance = []
for vect_train in train_vect_set:
dist = get_distance(vect_test, vect_train)
distance.append((dist, vect_train))
distance.sort(key=operator.itemgetter(0))
neighbors = []
for i in range(k):
neighbors.append(distance[i][1])
return neighbors def get_result(neighbors):
votes = {}
for neighbor in neighbors:
vote = neighbor[-1]
if vote in votes:
votes[vote] += 1
else:
votes[vote] = 1
vote_order = sorted(votes.items(), key=operator.itemgetter(1), reverse=True)
return vote_order[0][0] def k_nearest_neighbor(vect_test, vect_train, k):
neighbors = get_neighbor(vect_test, vect_train, k)
result = get_result(neighbors)
print(result) if __name__ == '__main__':
vect_train = [[1, 1, 1, 'a'], [2, 2, 2, 'b'], [1, 1, 3, 'a'], [4, 4, 4, 'b'], [0, 0, 0, 'a'], [4, 5, 4, 'b']]
vect_test = [5, 5, 5]
k_nearest_neighbor(vect_test, vect_train, 3)
机器学习分类算法之K近邻(K-Nearest Neighbor)的更多相关文章
- K近邻(k-Nearest Neighbor,KNN)算法,一种基于实例的学习方法
1. 基于实例的学习算法 0x1:数据挖掘的一些相关知识脉络 本文是一篇介绍K近邻数据挖掘算法的文章,而所谓数据挖掘,就是讨论如何在数据中寻找模式的一门学科. 其实人类的科学技术发展的历史,就一直伴随 ...
- k近邻法(k-nearest neighbor, k-NN)
一种基本分类与回归方法 工作原理是:1.训练样本集+对应标签 2.输入没有标签的新数据,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最相似数据(最近邻)的分类标签. 3.一般 ...
- k近邻法( k-nearnest neighbor)
基本思想: 给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,这k个实例的多数属于某个类,就把该输入实例分为这个类 距离度量: 特征空间中两个实例点的距离是两个实例点相似 ...
- 机器学习:分类算法性能指标之ROC曲线
在介绍ROC曲线之前,先说说混淆矩阵及两个公式,因为这是ROC曲线计算的基础. 1.混淆矩阵的例子(是否点击广告): 说明: TP:预测的结果跟实际结果一致,都点击了广告. FP:预测结果点击了,但是 ...
- 第三章 K近邻法(k-nearest neighbor)
书中存在的一些疑问 kd树的实现过程中,为何选择的切分坐标轴要不断变换?公式如:x(l)=j(modk)+1.有什么好处呢?优点在哪?还有的实现是通过选取方差最大的维度作为划分坐标轴,有何区别? 第一 ...
- DNS通道检测 国外学术界研究情况——研究方法:基于流量,使用机器学习分类算法居多,也有使用聚类算法的;此外使用域名zif low也有
http://www.ijrter.com/papers/volume-2/issue-4/dns-tunneling-detection.pdf <DNS Tunneling Detectio ...
- 机器学习算法之K近邻算法
0x00 概述 K近邻算法是机器学习中非常重要的分类算法.可利用K近邻基于不同的特征提取方式来检测异常操作,比如使用K近邻检测Rootkit,使用K近邻检测webshell等. 0x01 原理 ...
- K近邻算法小结
什么是K近邻? K近邻一种非参数学习的算法,可以用在分类问题上,也可以用在回归问题上. 什么是非参数学习? 一般而言,机器学习算法都有相应的参数要学习,比如线性回归模型中的权重参数和偏置参数,SVM的 ...
- KNN (K近邻算法) - 识别手写数字
KNN项目实战——手写数字识别 1. 介绍 k近邻法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法.它的工作原理是:存在一个 ...
随机推荐
- python正则之match search findall
match:只匹配一次,开头匹配不上,则不继续匹配 a,b,\w+ match(a,"abcdef") 匹配a >>> re.match("a" ...
- 第五周课程总结&试验报告
this和super的区别 区别点 this super 属性访问 访问同类中的属性,如果本类没有此属性则从父类中继续查找 访问父类中的属性 方法 访问本类中的方法,如果本类中没有此方法,则从父类中继 ...
- 【python】集合 list差集|并集|交集
两个list差集 list(set(b).difference(set(a))) # b中有而a中没有的 示例: a=[1,2,3] b=[2,3] list(set(a).difference(se ...
- GO开发:etcd用法
etcd是什么? A highly-available key value store for shared configuration and service discovery.是一个键值存储仓库 ...
- Windows下GIT的用户密码修改
Windows下GIT的用户密码修改
- 如何在linux上部署vue项目
安装nginx的前奏 安装依赖 yum -y install gcc zlib zlib-devel pcre-devel openssl openssl-devel 创建一个文件夹 cd /usr/ ...
- 【Airtest】Airtest中swipe方法兼容不同分辨率的解决方法
使用Airtest中swipe方法由于不同分辨率的手机上滑动的坐标位置不同,所以想要兼容所有的手机,仅仅靠固定坐标就会出现问题 想要兼容所有的手机,可以按照如下思路进行 1.首先获取手机的分辨率,可以 ...
- 测试需要了解的技术之基础篇三__持续集成持续交付DevOps
持续集成.持续交付.DevOps 1.容器技术Docker:容器技术介绍.Docker安装与加速配置.Docker基础命令.Docker搭建selenium.Docker搭建持续集成平台Jenkins ...
- TCP/IP协议-1
转载资源,链接地址https://www.cnblogs.com/evablogs/p/6709707.html
- [JS] 鼠标点击文本框清空默认值,离开文本框恢复默认值
在使用文本框的时候,若设定了初始值,选择文本框进行输入的时候要将本来的内容进行删除,会显得非常麻烦 可以在文本框属性定义触发onfocus和onblur两个事件时对应的js功能 下面以asp.net代 ...