6.824 Lab 2: Raft 2C
Part 2C
Do a git pull to get the latest lab software.
If a Raft-based server reboots it should resume service where it left off. This requires that Raft keep persistent state that survives a reboot. The paper's Figure 2 mentions which state should be persistent, and raft.go contains examples of how to save and restore persistent state.
A “real” implementation would do this by writing Raft's persistent state to disk each time it changes, and reading the latest saved state from disk when restarting after a reboot. Your implementation won't use the disk; instead, it will save and restore persistent state from a Persister object (see persister.go). Whoever calls Raft.Make() supplies a Persister that initially holds Raft's most recently persisted state (if any). Raft should initialize its state from that Persister, and should use it to save its persistent state each time the state changes. Use the Persister's ReadRaftState() and SaveRaftState() methods.“真正的”实现是这样做的:在每次更改时将Raft的持久状态写入磁盘,并在重新启动时从磁盘读取最新保存的状态。
Complete the functions persist() and readPersist() in raft.go by adding code to save and restore persistent state. You will need to encode (or "serialize") the state as an array of bytes in order to pass it to the Persister. Use the labgob encoder we provide to do this; see the comments in persist() and readPersist(). labgob is derived from Go's gob encoder; the only difference is that labgob prints error messages if you try to encode structures with lower-case field names.
You now need to determine at what points in the Raft protocol your servers are required to persist their state, and insert calls to persist() in those places. There is already a call to readPersist() in Raft.Make(). Once you've done this, you should pass the remaining tests. You may want to first try to pass the "basic persistence" test (go test -run 'TestPersist12C'), and then tackle the remaining ones (go test -run 2C).
In order to avoid running out of memory, Raft must periodically discard old log entries, but you do not have to worry about this until the next lab.
- Many of the 2C tests involve servers failing and the network losing RPC requests or replies.
- In order to pass some of the challenging tests towards the end, such as those marked "unreliable", you will need to implement the optimization to allow a follower to back up the leader's nextIndex by more than one entry at a time. See the description in the extended Raft paper starting at the bottom of page 7 and top of page 8 (marked by a gray line). The paper is vague about the details; you will need to fill in the gaps, perhaps with the help of the 6.824 Raft lectures.
|
If desired, the protocol can be optimized to reduce the number of rejected AppendEntries RPCs. For example, when rejecting an AppendEntries request, the follower can include the term of the conflicting entry and the first index it stores for that term. With this information, the leader can decrement nextIndex to bypass all of the conflicting entries in that term; one AppendEntries RPC will be required for each term with conflicting entries, rather than one RPC per entry. In practice, we doubt this optimization is necessary, since failures happen infrequently and it is unlikely that there will be many inconsistent entries. |
- A reasonable amount of time to consume for the full set of Lab 2 tests (2A+2B+2C) is 4 minutes of real time and one minute of CPU time.
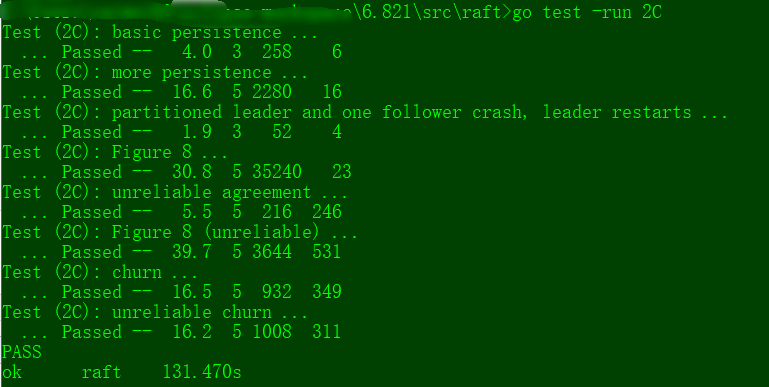
Your code should pass all the 2C tests (as shown below), as well as the 2A and 2B tests.
$ go test -run 2C
Test (2C): basic persistence ...
... Passed -- 3.4 3 60 6
Test (2C): more persistence ...
... Passed -- 17.0 5 705 16
Test (2C): partitioned leader and one follower crash, leader restarts ...
... Passed -- 1.4 3 27 4
Test (2C): Figure 8 ...
... Passed -- 33.2 5 852 53
Test (2C): unreliable agreement ...
... Passed -- 2.4 5 207 246
Test (2C): Figure 8 (unreliable) ...
... Passed -- 35.3 5 1838 216
Test (2C): churn ...
... Passed -- 16.2 5 5138 2260
Test (2C): unreliable churn ...
... Passed -- 16.2 5 1254 603
PASS
ok raft 124.999s
my homework code
package raft //
// this is an outline of the API that raft must expose to
// the service (or tester). see comments below for
// each of these functions for more details.
//
// rf = Make(...)
// create a new Raft server.
// rf.Start(command interface{}) (index, term, isleader)
// start agreement on a new log entry
// rf.GetState() (term, isLeader)
// ask a Raft for its current term, and whether it thinks it is leader
// ApplyMsg
// each time a new entry is committed to the log, each Raft peer
// should send an ApplyMsg to the service (or tester)
// in the same server.
// import (
"labrpc"
"math/rand"
"sync"
"time"
) import "bytes"
import "labgob" //
// as each Raft peer becomes aware that successive log entries are
// committed, the peer should send an ApplyMsg to the service (or
// tester) on the same server, via the applyCh passed to Make(). set
// CommandValid to true to indicate that the ApplyMsg contains a newly
// committed log entry.
//
// in Lab 3 you'll want to send other kinds of messages (e.g.,
// snapshots) on the applyCh; at that point you can add fields to
// ApplyMsg, but set CommandValid to false for these other uses.
//
type ApplyMsg struct {
CommandValid bool
Command interface{}
CommandIndex int
} type LogEntry struct {
Command interface{}
Term int
} const (
Follower int =
Candidate int =
Leader int =
HEART_BEAT_TIMEOUT = //心跳超时,要求1秒10次,所以是100ms一次
) //
// A Go object implementing a single Raft peer.
//
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[] // Your data here (2A, 2B, 2C).
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
electionTimer *time.Timer // 选举定时器
heartbeatTimer *time.Timer // 心跳定时器
state int // 角色
voteCount int //投票数
applyCh chan ApplyMsg // 提交通道 //Persistent state on all servers:
currentTerm int //latest term server has seen (initialized to 0 on first boot, increases monotonically)
votedFor int //candidateId that received vote in current term (or null if none)
log []LogEntry //log entries; each entry contains command for state machine, and term when entry was received by leader (first index is 1) //Volatile state on all servers:
commitIndex int //index of highest log entry known to be committed (initialized to 0, increases monotonically)
lastApplied int //index of highest log entry applied to state machine (initialized to 0, increases monotonically)
//Volatile state on leaders:(Reinitialized after election)
nextIndex []int //for each server, index of the next log entry to send to that server (initialized to leader last log index + 1)
matchIndex []int //for each server, index of highest log entry known to be replicated on server (initialized to 0, increases monotonically) } // return currentTerm and whether this server
// believes it is the leader.
func (rf *Raft) GetState() (int, bool) {
var term int
var isleader bool
// Your code here (2A).
rf.mu.Lock()
defer rf.mu.Unlock()
term = rf.currentTerm
isleader = rf.state == Leader
return term, isleader
} func (rf *Raft) persist() {
// Your code here (2C).
// Example:
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(rf.currentTerm)
e.Encode(rf.votedFor)
e.Encode(rf.log)
data := w.Bytes()
rf.persister.SaveRaftState(data)
} //
// restore previously persisted state.
//
func (rf *Raft) readPersist(data []byte) {
if data == nil || len(data) < { // bootstrap without any state?
return
}
// Your code here (2C).
// Example:
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
var currentTerm int
var votedFor int
var log []LogEntry
if d.Decode(¤tTerm) != nil ||
d.Decode(&votedFor) != nil ||
d.Decode(&log) != nil {
// error...
panic("fail to decode state")
} else {
rf.currentTerm = currentTerm
rf.votedFor = votedFor
rf.log = log
}
} //
// example RequestVote RPC arguments structure.
// field names must start with capital letters!
//
type RequestVoteArgs struct {
// Your data here (2A, 2B).
Term int //candidate’s term
CandidateId int //candidate requesting vote
LastLogIndex int //index of candidate’s last log entry (§5.4)
LastLogTerm int //term of candidate’s last log entry (§5.4)
} //
// example RequestVote RPC reply structure.
// field names must start with capital letters!
//
type RequestVoteReply struct {
// Your data here (2A).
Term int //currentTerm, for candidate to update itself
VoteGranted bool //true means candidate received vote
} //
// example RequestVote RPC handler.
//
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
// Your code here (2A, 2B).
rf.mu.Lock()
defer rf.mu.Unlock()
defer rf.persist() // 改动需要持久化
DPrintf("Candidate[raft%v][term:%v] request vote: raft%v[%v] 's term%v\n", args.CandidateId, args.Term, rf.me, rf.state, rf.currentTerm)
if args.Term < rf.currentTerm ||
(args.Term == rf.currentTerm && rf.votedFor != - && rf.votedFor != args.CandidateId) {
reply.Term = rf.currentTerm
reply.VoteGranted = false
return
} if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
rf.switchStateTo(Follower)
} // 2B: candidate's vote should be at least up-to-date as receiver's log
// "up-to-date" is defined in thesis 5.4.1
lastLogIndex := len(rf.log) -
if args.LastLogTerm < rf.log[lastLogIndex].Term ||
(args.LastLogTerm == rf.log[lastLogIndex].Term &&
args.LastLogIndex < (lastLogIndex)) {
// Receiver is more up-to-date, does not grant vote
reply.Term = rf.currentTerm
reply.VoteGranted = false
return
} rf.votedFor = args.CandidateId
reply.Term = rf.currentTerm
reply.VoteGranted = true
// reset timer after grant vote
rf.electionTimer.Reset(randTimeDuration())
} type AppendEntriesArgs struct {
Term int //leader’s term
LeaderId int //so follower can redirect clients
PrevLogIndex int //index of log entry immediately preceding new ones
PrevLogTerm int //term of prevLogIndex entry
Entries []LogEntry //log entries to store (empty for heartbeat; may send more than one for efficiency)
LeaderCommit int //leader’s commitIndex
} type AppendEntriesReply struct {
Term int //currentTerm, for leader to update itself
Success bool //true if follower contained entry matching prevLogIndex and prevLogTerm //Figure 8: A time sequence showing why a leader cannot determine commitment using log entries from older terms. In
// (a) S1 is leader and partially replicates the log entry at index
// 2. In (b) S1 crashes; S5 is elected leader for term 3 with votes
// from S3, S4, and itself, and accepts a different entry at log
// index 2. In (c) S5 crashes; S1 restarts, is elected leader, and
// continues replication. At this point, the log entry from term 2
// has been replicated on a majority of the servers, but it is not
// committed. If S1 crashes as in (d), S5 could be elected leader
// (with votes from S2, S3, and S4) and overwrite the entry with
// its own entry from term 3. However, if S1 replicates an entry from its current term on a majority of the servers before
// crashing, as in (e), then this entry is committed (S5 cannot
// win an election). At this point all preceding entries in the log
// are committed as well.
ConflictTerm int // 2C
ConflictIndex int // 2C
} func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
defer rf.persist() // 改动需要持久化
DPrintf("leader[raft%v][term:%v] beat term:%v [raft%v][%v]\n", args.LeaderId, args.Term, rf.currentTerm, rf.me, rf.state)
reply.Success = true // 1. Reply false if term < currentTerm (§5.1)
if args.Term < rf.currentTerm {
reply.Success = false
reply.Term = rf.currentTerm
return
}
//If RPC request or response contains term T > currentTerm:set currentTerm = T, convert to follower (§5.1)
if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
rf.switchStateTo(Follower)
} // reset election timer even log does not match
// args.LeaderId is the current term's Leader
rf.electionTimer.Reset(randTimeDuration()) // 2. Reply false if log doesn’t contain an entry at prevLogIndex
// whose term matches prevLogTerm (§5.3)
lastLogIndex := len(rf.log) -
if lastLogIndex < args.PrevLogIndex {
reply.Success = false
reply.Term = rf.currentTerm
// optimistically thinks receiver's log matches with Leader's as a subset
reply.ConflictIndex = len(rf.log)
// no conflict term
reply.ConflictTerm = -
return
} // 3. If an existing entry conflicts with a new one (same index
// but different terms), delete the existing entry and all that
// follow it (§5.3)
if rf.log[(args.PrevLogIndex)].Term != args.PrevLogTerm {
reply.Success = false
reply.Term = rf.currentTerm
// receiver's log in certain term unmatches Leader's log
reply.ConflictTerm = rf.log[args.PrevLogIndex].Term // expecting Leader to check the former term
// so set ConflictIndex to the first one of entries in ConflictTerm
conflictIndex := args.PrevLogIndex
// apparently, since rf.log[0] are ensured to match among all servers
// ConflictIndex must be > 0, safe to minus 1
for rf.log[conflictIndex-].Term == reply.ConflictTerm {
conflictIndex--
}
reply.ConflictIndex = conflictIndex
return
} // 4. Append any new entries not already in the log
// compare from rf.log[args.PrevLogIndex + 1]
unmatch_idx := -
for idx := range args.Entries {
if len(rf.log) < (args.PrevLogIndex++idx) ||
rf.log[(args.PrevLogIndex++idx)].Term != args.Entries[idx].Term {
// unmatch log found
unmatch_idx = idx
break
}
} if unmatch_idx != - {
// there are unmatch entries
// truncate unmatch Follower entries, and apply Leader entries
rf.log = rf.log[:(args.PrevLogIndex + + unmatch_idx)]
rf.log = append(rf.log, args.Entries[unmatch_idx:]...)
} //5. If leaderCommit > commitIndex, set commitIndex = min(leaderCommit, index of last new entry)
if args.LeaderCommit > rf.commitIndex {
rf.setCommitIndex(min(args.LeaderCommit, len(rf.log)-))
} reply.Success = true
} //
// example code to send a RequestVote RPC to a server.
// server is the index of the target server in rf.peers[].
// expects RPC arguments in args.
// fills in *reply with RPC reply, so caller should
// pass &reply.
// the types of the args and reply passed to Call() must be
// the same as the types of the arguments declared in the
// handler function (including whether they are pointers).
//
// The labrpc package simulates a lossy network, in which servers
// may be unreachable, and in which requests and replies may be lost.
// Call() sends a request and waits for a reply. If a reply arrives
// within a timeout interval, Call() returns true; otherwise
// Call() returns false. Thus Call() may not return for a while.
// A false return can be caused by a dead server, a live server that
// can't be reached, a lost request, or a lost reply.
//
// Call() is guaranteed to return (perhaps after a delay) *except* if the
// handler function on the server side does not return. Thus there
// is no need to implement your own timeouts around Call().
//
// look at the comments in ../labrpc/labrpc.go for more details.
//
// if you're having trouble getting RPC to work, check that you've
// capitalized all field names in structs passed over RPC, and
// that the caller passes the address of the reply struct with &, not
// the struct itself.
//
func (rf *Raft) sendRequestVote(server int, args *RequestVoteArgs, reply *RequestVoteReply) bool {
ok := rf.peers[server].Call("Raft.RequestVote", args, reply)
return ok
} func (rf *Raft) sendAppendEntries(server int, args *AppendEntriesArgs, reply *AppendEntriesReply) bool {
ok := rf.peers[server].Call("Raft.AppendEntries", args, reply)
return ok
} //
// the service using Raft (e.g. a k/v server) wants to start
// agreement on the next command to be appended to Raft's log. if this
// server isn't the leader, returns false. otherwise start the
// agreement and return immediately. there is no guarantee that this
// command will ever be committed to the Raft log, since the leader
// may fail or lose an election. even if the Raft instance has been killed,
// this function should return gracefully.
//
// the first return value is the index that the command will appear at
// if it's ever committed. the second return value is the current
// term. the third return value is true if this server believes it is
// the leader.
//
func (rf *Raft) Start(command interface{}) (int, int, bool) {
index := -
term := -
isLeader := true // Your code here (2B).
rf.mu.Lock()
defer rf.mu.Unlock()
term = rf.currentTerm
isLeader = rf.state == Leader
if isLeader {
rf.log = append(rf.log, LogEntry{Command: command, Term: term})
rf.persist() // 改动需要持久化
index = len(rf.log) -
rf.matchIndex[rf.me] = index
rf.nextIndex[rf.me] = index +
} return index, term, isLeader
} //
// the tester calls Kill() when a Raft instance won't
// be needed again. you are not required to do anything
// in Kill(), but it might be convenient to (for example)
// turn off debug output from this instance.
//
func (rf *Raft) Kill() {
// Your code here, if desired.
} //
// the service or tester wants to create a Raft server. the ports
// of all the Raft servers (including this one) are in peers[]. this
// server's port is peers[me]. all the servers' peers[] arrays
// have the same order. persister is a place for this server to
// save its persistent state, and also initially holds the most
// recent saved state, if any. applyCh is a channel on which the
// tester or service expects Raft to send ApplyMsg messages.
// Make() must return quickly, so it should start goroutines
// for any long-running work.
//
func Make(peers []*labrpc.ClientEnd, me int,
persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{}
rf.peers = peers
rf.persister = persister
rf.me = me // Your initialization code here (2A, 2B, 2C).
rf.state = Follower
rf.votedFor = -
rf.heartbeatTimer = time.NewTimer(HEART_BEAT_TIMEOUT * time.Millisecond)
rf.electionTimer = time.NewTimer(randTimeDuration()) rf.applyCh = applyCh
rf.log = make([]LogEntry, ) // start from index 1 // initialize from state persisted before a crash
rf.mu.Lock()
rf.readPersist(persister.ReadRaftState())
rf.mu.Unlock() rf.nextIndex = make([]int, len(rf.peers))
//for persist
for i := range rf.nextIndex {
// initialized to leader last log index + 1
rf.nextIndex[i] = len(rf.log)
}
rf.matchIndex = make([]int, len(rf.peers)) //以定时器的维度重写background逻辑
go func() {
for {
select {
case <-rf.electionTimer.C:
rf.mu.Lock()
switch rf.state {
case Follower:
rf.switchStateTo(Candidate)
case Candidate:
rf.startElection()
}
rf.mu.Unlock() case <-rf.heartbeatTimer.C:
rf.mu.Lock()
if rf.state == Leader {
rf.heartbeats()
rf.heartbeatTimer.Reset(HEART_BEAT_TIMEOUT * time.Millisecond)
}
rf.mu.Unlock()
}
}
}() return rf
} func randTimeDuration() time.Duration {
return time.Duration(HEART_BEAT_TIMEOUT*+rand.Intn(HEART_BEAT_TIMEOUT)) * time.Millisecond
} //切换状态,调用者需要加锁
func (rf *Raft) switchStateTo(state int) {
if state == rf.state {
return
}
DPrintf("Term %d: server %d convert from %v to %v\n", rf.currentTerm, rf.me, rf.state, state)
rf.state = state
switch state {
case Follower:
rf.heartbeatTimer.Stop()
rf.electionTimer.Reset(randTimeDuration())
rf.votedFor = -
case Candidate:
//成为候选人后立马进行选举
rf.startElection() case Leader:
// initialized to leader last log index + 1
for i := range rf.nextIndex {
rf.nextIndex[i] = len(rf.log)
}
for i := range rf.matchIndex {
rf.matchIndex[i] =
} rf.electionTimer.Stop()
rf.heartbeats()
rf.heartbeatTimer.Reset(HEART_BEAT_TIMEOUT * time.Millisecond)
}
} // 发送心跳包,调用者需要加锁
func (rf *Raft) heartbeats() {
for i := range rf.peers {
if i != rf.me {
go rf.heartbeat(i)
}
}
} func (rf *Raft) heartbeat(server int) {
rf.mu.Lock()
if rf.state != Leader {
rf.mu.Unlock()
return
} prevLogIndex := rf.nextIndex[server] - // use deep copy to avoid race condition
// when override log in AppendEntries()
entries := make([]LogEntry, len(rf.log[(prevLogIndex+):]))
copy(entries, rf.log[(prevLogIndex+):]) args := AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
PrevLogIndex: prevLogIndex,
PrevLogTerm: rf.log[prevLogIndex].Term,
Entries: entries,
LeaderCommit: rf.commitIndex,
}
rf.mu.Unlock() var reply AppendEntriesReply
if rf.sendAppendEntries(server, &args, &reply) {
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.state != Leader {
return
}
// If last log index ≥ nextIndex for a follower: send
// AppendEntries RPC with log entries starting at nextIndex
// • If successful: update nextIndex and matchIndex for
// follower (§5.3)
// • If AppendEntries fails because of log inconsistency:
// decrement nextIndex and retry (§5.3)
if reply.Success {
// successfully replicated args.Entries
rf.matchIndex[server] = args.PrevLogIndex + len(args.Entries)
rf.nextIndex[server] = rf.matchIndex[server] + // If there exists an N such that N > commitIndex, a majority
// of matchIndex[i] ≥ N, and log[N].term == currentTerm:
// set commitIndex = N (§5.3, §5.4).
for N := (len(rf.log) - ); N > rf.commitIndex; N-- {
count :=
for _, matchIndex := range rf.matchIndex {
if matchIndex >= N {
count +=
}
} if count > len(rf.peers)/ {
// most of nodes agreed on rf.log[i]
rf.setCommitIndex(N)
break
}
} } else {
if reply.Term > rf.currentTerm {
rf.currentTerm = reply.Term
rf.switchStateTo(Follower)
rf.persist() // 改动需要持久化
} else {
//如果走到这个分支,那一定是需要前推(优化前推)
rf.nextIndex[server] = reply.ConflictIndex // if term found, override it to
// the first entry after entries in ConflictTerm
if reply.ConflictTerm != - {
for i := args.PrevLogIndex; i >= ; i-- {
if rf.log[i-].Term == reply.ConflictTerm {
// in next trial, check if log entries in ConflictTerm matches
rf.nextIndex[server] = i
break
}
}
}
//和等待下一轮执行相比,直接retry并没有明显优势,
// go rf.heartbeat(server)
}
}
// rf.mu.Unlock()
}
} // 开始选举,调用者需要加锁
func (rf *Raft) startElection() { // DPrintf("raft%v is starting election\n", rf.me)
rf.currentTerm +=
rf.votedFor = rf.me //vote for me
rf.persist() // 改动需要持久化
rf.voteCount =
rf.electionTimer.Reset(randTimeDuration()) for i := range rf.peers {
if i != rf.me {
go func(peer int) {
rf.mu.Lock()
lastLogIndex := len(rf.log) -
args := RequestVoteArgs{
Term: rf.currentTerm,
CandidateId: rf.me,
LastLogIndex: lastLogIndex,
LastLogTerm: rf.log[lastLogIndex].Term,
}
// DPrintf("raft%v[%v] is sending RequestVote RPC to raft%v\n", rf.me, rf.state, peer)
rf.mu.Unlock()
var reply RequestVoteReply
if rf.sendRequestVote(peer, &args, &reply) {
rf.mu.Lock()
defer rf.mu.Unlock()
if reply.Term > rf.currentTerm {
rf.currentTerm = reply.Term
rf.switchStateTo(Follower)
rf.persist() // 改动需要持久化
}
if reply.VoteGranted && rf.state == Candidate {
rf.voteCount++
if rf.voteCount > len(rf.peers)/ {
rf.switchStateTo(Leader)
}
}
}
}(i)
}
}
} //
// several setters, should be called with a lock
//
func (rf *Raft) setCommitIndex(commitIndex int) {
rf.commitIndex = commitIndex
// apply all entries between lastApplied and committed
// should be called after commitIndex updated
if rf.commitIndex > rf.lastApplied {
DPrintf("%v apply from index %d to %d", rf, rf.lastApplied+, rf.commitIndex)
entriesToApply := append([]LogEntry{}, rf.log[(rf.lastApplied+):(rf.commitIndex+)]...) go func(startIdx int, entries []LogEntry) {
for idx, entry := range entries {
var msg ApplyMsg
msg.CommandValid = true
msg.Command = entry.Command
msg.CommandIndex = startIdx + idx
rf.applyCh <- msg
// do not forget to update lastApplied index
// this is another goroutine, so protect it with lock
rf.mu.Lock()
if rf.lastApplied < msg.CommandIndex {
rf.lastApplied = msg.CommandIndex
}
rf.mu.Unlock()
}
}(rf.lastApplied+, entriesToApply)
}
}
func min(x, y int) int {
if x < y {
return x
} else {
return y
}
}
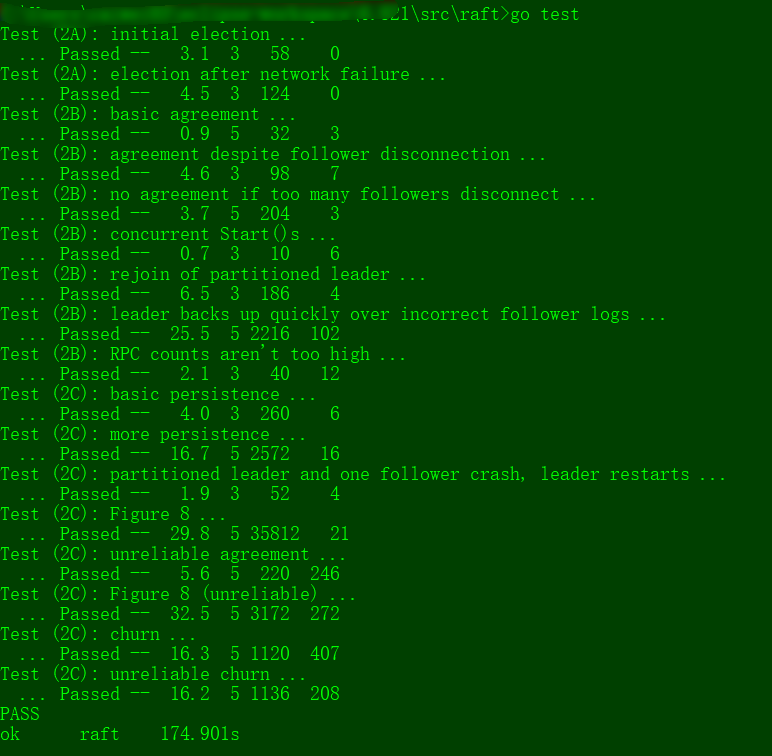
test 2c
test all
6.824 Lab 2: Raft 2C的更多相关文章
- 6.824 Lab 2: Raft 2A
6.824 Lab 2: Raft Part 2A Due: Feb 23 at 11:59pm Part 2B Due: Mar 2 at 11:59pm Part 2C Due: Mar 9 at ...
- 6.824 Lab 2: Raft 2B
Part 2B We want Raft to keep a consistent, replicated log of operations. A call to Start() at the le ...
- 6.824 Lab 3: Fault-tolerant Key/Value Service 3A
6.824 Lab 3: Fault-tolerant Key/Value Service Due Part A: Mar 13 23:59 Due Part B: Apr 10 23:59 Intr ...
- 6.824 Lab 3: Fault-tolerant Key/Value Service 3B
Part B: Key/value service with log compaction Do a git pull to get the latest lab software. As thing ...
- MIT-6.824 Lab 3: Fault-tolerant Key/Value Service
概述 lab2中实现了raft协议,本lab将在raft之上实现一个可容错的k/v存储服务,第一部分是实现一个不带日志压缩的版本,第二部分是实现日志压缩.时间原因我只完成了第一部分. 设计思路 如上图 ...
- 6.824 Lab 5: Caching Extents
Introduction In this lab you will modify YFS to cache extents, reducing the load on the extent serve ...
- MIT 6.824 Lab2C Raft之持久化
书接上文Raft Part B | MIT 6.824 Lab2B Log Replication. 实验准备 实验代码:git://g.csail.mit.edu/6.824-golabs-2021 ...
- MIT 6.824 Lab2D Raft之日志压缩
书接上文Raft Part C | MIT 6.824 Lab2C Persistence. 实验准备 实验代码:git://g.csail.mit.edu/6.824-golabs-2021/src ...
- MIT 6.824 Llab2B Raft之日志复制
书接上文Raft Part A | MIT 6.824 Lab2A Leader Election. 实验准备 实验代码:git://g.csail.mit.edu/6.824-golabs-2021 ...
随机推荐
- VUE+DJANGO
1.router类型不能设置为history const router = new Router({ mode: '', routes, }); //避免打包到django后刷新报错 2.样式放sta ...
- MyEclipse使用教程:使用DevStyle增强型启动
[MyEclipse CI 2019.4.0安装包下载] DevStyle不仅仅是一组新的主题,它还包含了一个完全改进的启动体验,拥有更直观的UI,帮助开发人员快速启动IDE.DevStyle作为Ec ...
- IDEA 2018.1可用License服务(持续更新)
1. http://idea.congm.in 2.http://idea.toocruel.net
- 【leetcode】1224. Maximum Equal Frequency
题目如下: Given an array nums of positive integers, return the longest possible length of an array prefi ...
- Shell-07数组与字符串
Shell-07数组与字符串 数组 数组说白了就是一段连续的变量,一段连续的内存存储空间 解决:变量过多的问题:在同类的变量中,我们不需要去定义多个名字,而是以数组的方式来定义:(列表) 数组名 索引 ...
- Buffer转成字符串
如果data为buffer格式,则: data.toString()
- asp.net批量下载
1.首先读取文件夹下的文件,可能同时存在多个文件 2.选中文件,然后点击下载,同时可以选择多个文件. 思路:通过生产压缩包的形式进行下载,然后再清楚压缩包,这样用户可以一次性全部下载下来. 一.获取目 ...
- 【BZOJ4570】 [Scoi2016]妖怪
Description 邱老师是妖怪爱好者,他有n只妖怪,每只妖怪有攻击力atk和防御力dnf两种属性.邱老师立志成为妖怪大师,于 是他从真新镇出发,踏上未知的旅途,见识不同的风景.环境对妖怪的战斗力 ...
- Xshell Linux常用命令
Xshell :一个强大的安全终端模拟软件,它支持SSH1, SSH2, 以及Microsoft Windows 平台的TELNET 协议. 0 帮助 命令 与清屏 help 查看帮助命令 ls ...
- es之对文档进行更新操作
5.7.1:更新整个文档 ES中并不存在所谓的更新操作,而是用新文档替换旧文档: 在内部,Elasticsearch已经标记旧文档为删除并添加了一个完整的新文档并建立索引.旧版本文档不会立即消失 ,但 ...