Python-使用Magellan进行数据匹配总结
参考:http://www.biggorilla.org/zh-hans/walkt/
使用Magellan进行数据匹配过程如下:
假设有两个数据源为A和B,
A共有四列数据:(A_Column1,A_Column2,A_Column3,A_Column4)
B共有五列数据: (B_Column1,B_Column2,B_Column3,B_Column4,B_Column5)
假设A_Column1和B_Column1是相关的,而A_Column2和B_Column2相关的
1、首先建立合并列表
分别在A和B数据中建立一个混合列mixture
在A中 mixture = A_Column1 + A_Column2 就是把 A_Column1 和 A_Column2两列的数据合并到mixture列里面,
同理,在B中 mixture = B_Column1+ B_Column2

2、寻找一个候选集
这个过程就是使用重叠系数连接两个表,我们可以使用混合列创建所需的候选集(我们称之为C)。

注意:这个过程中threshold这个参数代码这要C这个集合中要创建一列_sim_score ,表示相似度分数,如何经过匹配_sim_score 的数据小于0.65,那么就是不合格的,说白了就是相识度很小,
threshold这个设置的过多大,导致可能C的集合很小,值越大代表数据相识度越大 ,threshold最大值是1,代表匹配数据完全一样,值越小代表数据相识度越小,如果所有数据的匹配结果都小于threshold的值,那么
C就是空集合,因此这个值要根据选择的匹配列数进行设置。
3、指定要素
就是指定在py_entitymatching程序包中哪些列对应于各个数据帧中的要素

4、拦截工具故障排除
确保候选集足够松动,能够容纳并不十分接近的电影配对。如果不是这样,那么可能我们已经清除了可能潜在匹配的配对
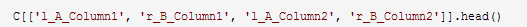
5、从候选集采样
目标是从候选集中获取一个样本,并手动标记抽样候选者;也就是指定候选配对是否是正确的匹配。

要在导出的labeled.csv文件中增加一个label列,根据_sim_score列的数据和实际数据情况,来人为的判断是否是正确的匹配,如果是则在label列中填入数值1,否则,填入数值0
注意:这个label.csv数据集合实际上作为下面机器学习一个训练集,因此这个label列数据之间影响下面机器学习的效果。

6、机器学习算法训练
下面用了几种机器学习算法

在应用任何机器学习方法之前,我们需要抽取一组功能。幸运地是,一旦我们指定两个数据集中的哪些列相互对应,py_entitymatching程序包就可以自动抽取一组功能。指定两个数据集的列之间的对应性,
将启动以下代码片段。然后,它使用py_entitymatching程序包确定各列的类型。通过考虑(变量l_attr_types和r_attr_types中存储的)各个数据集中列的类型,并使用软件包推荐的编译器和类似功能,我们可以抽取一组
用于抽取功能的说明。请注意,变量F并非所抽取功能的集合,相反,它会对说明编码以处理功能。

考虑所需功能的集合F,现在我们可以计算训练数据的功能值,并找出我们数据中丢失数值的原因。在这种情况下,我们选择将丢失值替换为列的平均值。

使用计算的功能,我们可以评估不同机器学习算法的性能,并为我们的匹配任务选择最佳的算法。

7、评估匹配质量
评估匹配质量非常重要。可以针对此目的使用训练集,并衡量随机森林预测匹配的质量。我们可以发现,我们获得最高精确性,并且能够重现测试集。

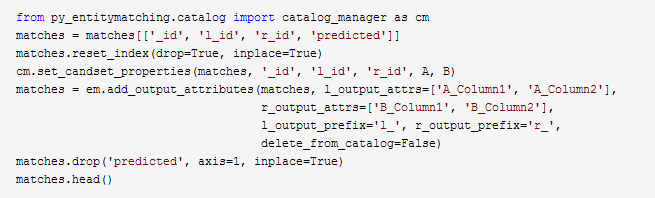
8、使用训练的模型匹配数据集
使用训练的模型对两个标记进行如下匹配

请注意,匹配数据帧包含了很多存储数据集抽取功能的列。以下代码片段移除了所有非必要的列,并创建一个格式良好的拥有最终形成的整合数据集的数据帧。
Python-使用Magellan进行数据匹配总结的更多相关文章
- VLOOKUP函数将一个excel表格的数据匹配到另一个表中
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- python爬虫的页面数据解析和提取/xpath/bs4/jsonpath/正则(1)
一.数据类型及解析方式 一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值.内容一般分为两部分,非结构化的数据 和 结构化的数据. 非结构化数据:先有数据,再有结构, 结构化数 ...
- python爬取拉勾网数据并进行数据可视化
爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示.直方图展示.词云展示等并根据可视化的数据做 ...
- python爬虫---爬虫的数据解析的流程和解析数据的几种方式
python爬虫---爬虫的数据解析的流程和解析数据的几种方式 一丶爬虫数据解析 概念:将一整张页面中的局部数据进行提取/解析 作用:用来实现聚焦爬虫的吧 实现方式: 正则 (针对字符串) bs4 x ...
- 分析Python中解析构建数据知识
分析Python中解析构建数据知识 Python 可以通过各种库去解析我们常见的数据.其中 csv 文件以纯文本形式存储表格数据,以某字符作为分隔值,通常为逗号:xml 可拓展标记语言,很像超文本标记 ...
- Python正则表达式处理中的匹配对象是什么?
老猿才开始学习正则表达式处理时,对于搜索返回的匹配对象这个名词不是很理解,因此在前阶段<第11.3节 Python正则表达式搜索支持函数search.match.fullmatch.findal ...
- JavaScript 解析 Django Python 生成的 datetime 数据 时区问题解决
JavaScript 解析 Django/Python 生成的 datetime 数据 当Web后台使用Django时,后台生成的时间数据类型就是Python类型的. 项目需要将几个时间存储到数据库中 ...
- 【转载】使用Pandas进行数据匹配
使用Pandas进行数据匹配 本文转载自:蓝鲸的网站分析笔记 原文链接:使用Pandas进行数据匹配 目录 merge()介绍 inner模式匹配 lefg模式匹配 right模式匹配 outer模式 ...
- Python下载Yahoo!Finance数据
Python下载Yahoo!Finance数据的三种工具: (1)yahoo-finance package. (2)ystockquote. (3)pandas.
随机推荐
- CORS跨域cookie传递
服务端 Access-Control-Allow-Credentials:true Access-Control-Allow-Methods:* Access-Control-Allow-Origin ...
- bzoj2957:楼房重建
题意:http://www.lydsy.com/JudgeOnline/problem.php?id=2957 sol :首先考虑转化问题,即给你一个斜率序列,让你动态维护单调栈 考虑线段树,令ge ...
- Java面试题之Oracle 支持哪三种事务隔离级别
Oracle 支持三种事务隔离级别: 1.读已提交:(默认) 2.串行化: 3.只读模式
- 原生dialog
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Linux C/C++内存泄漏检测工具:Valgrind
Valgrind 是一款 Linux下(支持 x86.x86_64和ppc32)程序的内存调试工具,它可以对编译后的二进制程序进行内存使用监测(C语言中的malloc和free,以及C++中的new和 ...
- flask框架下的jinja2模板引擎(3)(模板继承与可以在模板使用的变量、方法)
flask 框架下的jinja2模块引擎(1):https://www.cnblogs.com/chichung/p/9774556.html flask 框架下的jinja2模块引擎(2):http ...
- hdu 5109(构造数+对取模的理解程度)
Alexandra and A*B Problem Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Jav ...
- IIS——MIME介绍与添加MIME类型
MIME(MultipurposeInternet Mail Extensions)多用途互联网邮件扩展类型.是设定某种扩展名的文件用一种应用程序来打开的方式类型,当该扩展名文件被访问的时候,浏览器会 ...
- react 如何处理页面加载时无法将获取缓存信息存入全局变量中
最近在做一个权限功能时,发现在读取用户公司ID进行列表查询 时,无法钭读取到缓存中的数据存入页面全局变量中进行加载查询 将问题代码整理出来 将信息存入缓存: let menuList = Helper ...
- UVA 11149.Power of Matrix-矩阵快速幂倍增
Power of Matrix UVA - 11149 代码: #include <cstdio> #include <cstring> #include < ...