建堆复杂度O(n)证明
堆排序中首先需要做的就是建堆,广为人知的是建堆复杂度才O(n),它的证明过程涉及到高等数学中的级数或者概率论,不过证明整体来讲是比较易懂的。
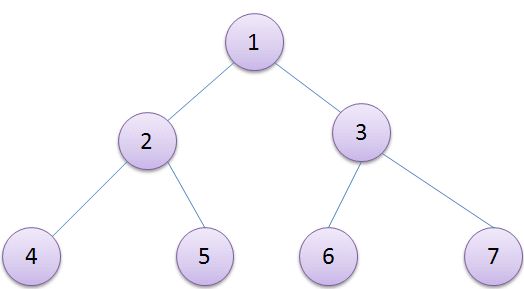
堆排过程
代码如下
void print(vector<int> &arr){for(auto n: arr) printf("%d\t", n);cout<<endl;}// 以arr[n]为根的子树,将arr[n]向下调整至合适位置void Heapify(vector<int> &arr, int size, int n){int L = n*2+1, R = L+1;if(L>=size) return ;//无孩int big = arr[L]; // 取两孩之大者if(R<size) big = max(big, arr[R]);if(arr[n]>=big) return ; //无需调整int c = L; // 欲与父交换位置的孩子if(big!=arr[L]) c = R;swap(arr[n], arr[c]);Heapify(arr, size, c);}// 小根堆void BuildHeap(vector<int> &arr){int last = (arr.size()-1)/2;for(int i=last; i>=0; i--) {Heapify(arr, arr.size(), i);}}// 顺便排序void Sort(vector<int> &arr){int size = arr.size();for(int i=size-1; i>0; i--) {swap(arr[0], arr[i]);Heapify(arr, i, 0); //调整一下arr[0]}}int main(){vector<int> vect{9, 10, 6, 3, 1, 6, 2, 8, 4};print(vect); //排序前BuildHeap(vect); //建堆Sort(vect); //排序print(vect); //排序后return 0;}
建堆的过程就是从最后一个分支结点开始逐层向上遍历,将结点向下调整至合适的位置,以不至于破坏原来的堆。比如上图,遍历的结点编号依次为3 2 1,首先调整以3为根的子树成堆,其次是以2为根的子树成堆,最后是以1为根的子树成堆。至此建堆完成,复杂度O(n)。
注意:建堆不能写成如下这样,这样的建堆算法复杂度是O(nlogn),虽然不会影响堆排序的复杂度O(nlogn),但是实现其他算法时就很不利了。
// 将arr[n]向上调整至合适位置void AdjustHeap(vector<int> &arr, int n){if(n<=0) return ;if(arr[(n-1)/2] > arr[n]) { //与父结点比较swap(arr[(n-1)/2], arr[n]);AdjustHeap(arr, (n-1)/2); //递归调整}}// 小根堆void BuildHeap(vector<int> &arr){for(int i=1; i<arr.size(); i++) {AdjustHeap(arr, i);}}
复杂度计算
从直观上看,Heapify()的递归深度最多为\({log_n}\),故它的复杂度上限为O(logn)。而BuildHeap()中的循环为\({ \frac{n}{2} }\)次,故它的复杂度为O(nlogn),但这不是它的实际复杂度,而是一个估算的上界,它很可能永远达不到这个上界。为了方便计算,考虑结点数量为n,高度为h的满二叉树,因此\({2^h-1 = n}\),即\({h = log_2{(n+1)}}\)。
| 第几层 | 最多调整次数 | 层调整次数累计 |
|---|---|---|
| \({h}\) | \(0\) | \({2^{h-1}*0}\) |
| \({h-1}\) | \(1\) | \({2^{h-2}*1}\) |
| \({h-2}\) | \(2\) | \({2^{h-3}*2}\) |
| \(\vdots\) | \(\vdots\) | \(\vdots\) |
| \(3\) | \({ h-3 }\) | \({2^{2}*(h-3)}\) |
| \(2\) | \({ h-2 }\) | \({2^{1}*(h-2)}\) |
| \(1\) | \({ h-1 }\) | \({2^{0}*(h-1)}\) |
将最右边一列累加起来就是建堆的调整次数,则建堆的调整次数\({S(n)}\)为
\]
\]
则
\]
将(1)式减去(2)式得
\]
\]
\]
\]
又因 \({ n = 2^h-1 }\),故有
\]
注意:上面列式均是当n趋于无穷大时的计算,且(3)式是由级数的直接变换所得。其他的证明思路还有用概率的,就不写了。
写公式写到头皮发麻,写错n次了,如果错漏请不吝指正,感谢!
建堆复杂度O(n)证明的更多相关文章
- 建堆是 O(n) 的时间复杂度证明。
建堆的复杂度先考虑满二叉树,和计算完全二叉树的建堆复杂度一样. 对满二叉树而言,第 \(i\) 层(根为第 \(0\) 层)有 \(2^i\) 个节点. 由于建堆过程自底向上,以交换作为主要操作,因此 ...
- Python3实现最小堆建堆算法
今天看Python CookBook中关于“求list中最大(最小)的N个元素”的内容,介绍了直接使用python的heapq模块的nlargest和nsmallest函数的解决方式,记得学习数据结构 ...
- 堆+建堆、插入、删除、排序+java实现
package testpackage; import java.util.Arrays; public class Heap { //建立大顶堆 public static void buildMa ...
- 快速排序的期望复杂度O(nlogn)证明。
快速排序的最优时间复杂度是 \(O(nlogn)\),最差时间复杂度是 \(O(n^2)\),期望时间复杂度是 \(O(nlogn)\). 这里我们证明一下快排的期望时间复杂度. 设 \(T(n)\) ...
- 第十章 优先级队列 (b4)完全二叉堆:批量建堆
- BUG-FREE-For Dream
一直直到bug-free.不能错任何一点. 思路不清晰:刷两天. 做错了,刷一天. 直到bug-free.高亮,标红. 185,OA(YAMAXUN)--- (1) findFirstDuplicat ...
- 剑指offer面试题30:最小的k个数
一.题目描述 输入n个整数,找出其中最小的K个数.例如输入4,5,1,6,2,7,3,8这8个数字,则最小的4个数字是1,2,3,4,. 二.解题思路 1.思路1 首先对数组进行排序,然后取出前k个数 ...
- 自己动手实现java数据结构(八) 优先级队列
1.优先级队列介绍 1.1 优先级队列 有时在调度任务时,我们会想要先处理优先级更高的任务.例如,对于同一个柜台,在决定队列中下一个服务的用户时,总是倾向于优先服务VIP用户,而让普通用户等待,即使普 ...
- 【Unsolved】线性时间选择算法的复杂度证明
线性时间选择算法中,最坏情况仍然可以保持O(n). 原因是通过对中位数的中位数的寻找,保证每次分组后,任意一组包含元素的数量不会大于某个值. 普通的Partition最坏情况下,每次只能排除一个元素, ...
随机推荐
- C# web项目添加*.ashx文件后报错处理
说明:我是菜鸟,博文水平有限,仅作学习过程中的备忘笔记 1.截图信息: ———————————————————————————————————————————————————————————————— ...
- Doxygen生成美丽注释文档(1):初体验
Chapter 1 - 准备工作 (Windows环境) 1.1 程序包下载 1. Doxygen * 源码: git clone https://github.com/doxygen/doxygen ...
- JedisCluster 链接redis集群
先贴代码: <!-- redis客户端 --><dependency> <groupId>redis.clients</groupId> <a ...
- HBase学习(一)
HBase是建立在Hadoop文件系统之上的分布式面向列的数据库.它是一个开源项目,是横向扩展的. HBase是一个数据模型,类似于谷歌的大表设计,可以提供快速随机访问海量结构化数据.它利用了Hado ...
- (转)企业级NFS网络文件共享服务
企业级NFS网络文件共享服务 原文:http://www.cnblogs.com/chensiqiqi/archive/2017/03/10/6530859.html --本教学笔记是本人学习和工作生 ...
- (转)shell脚本输出带颜色字体
shell脚本输出带颜色字体 原文:http://blog.csdn.net/andylauren/article/details/60873400 输出特效格式控制:\033[0m 关闭所有属性 ...
- 导出csv文件时韩文乱码解决方法
从asp.net导出csv这样配置可以防止韩文等乱码,在头部加上0xEF, 0xBB, 0xBF: string fileName = "attachment;filename=" ...
- DEDE用{dede:sql}标签取出当前文档的附加表中的内容
最近在用DEDE做项目,遇到一个需求是要在article_image.htm模板中直接取出附加表addonimages中的某一记录的imgurls字段的内容.而这条记录是不断变化的,比如我点击了< ...
- Junit使用过程中需要注意的诡异bug以及处理办法
在开发过程中我们有时会遇到狠多的问题和bug,对于在编译和运行过程中出现的问题很好解决,因为可以在错误日志中得到一定的错误提示信息,从而可以找到一些对应的解决办法.但是有时也会遇到一些比较诡异的问题和 ...
- Window WindowManager 和WindowManager.LayoutParams
<一> Window window是android中的窗口,表示顶级窗口的意思,也就是主窗口,它有两个实现类, PhoneWindow和MidWindow,我们一般的activity对应的 ...