内存栅栏(memory barrier):解救peterson算法的应用陷阱
最近一个项目中用到了peterson算法来做临界区的保护,简简单单的十几行代码,就能实现两个线程对临界区的无锁访问,确实很精炼。但是在这不是来分析peterson算法的,在实际应用中发现peterson算法并不能对临界区进行互斥访问,也就是说两个线程还是有可能同时进入临界区。但是按照代码的分析,明明可以实现互斥访问的呀,这是怎么回事呢?
首先用一个测试程序来检验一下。临界区是对一个全局变量的自加一运算,两个线程各加一百万次,最后结果应该是两百万。由于自加一运算不是原子的,如果两个线程同时进入临界区,最后的结果就会少于两百万。
#include <iostream>
#include <pthread.h>
using namespace std; static volatile bool flag[] = {false, false};
static volatile int turn = ; static volatile int gCount = ; void procedure0() {
flag[] = true;
turn = ;
while (flag[] && (turn == ));
gCount++;
flag[] = false;
} void procedure1() {
flag[] = true;
turn = ;
while (flag[] && (turn == ));
gCount++;
flag[] = false;
} void* ThreadFunc0(void* args)
{
int i;
for (i = ; i<; i++)
procedure0();
return NULL;
} void* ThreadFunc1(void* args)
{
int i;
for (i = ; i<; i++)
procedure1();
return NULL;
} int main()
{
pthread_t pid0, pid1; if (pthread_create(&pid0, , &ThreadFunc0, NULL))
{
cout << "Create thread0 failed." << endl;
return ;
}
if (pthread_create(&pid1, , &ThreadFunc1, NULL))
{
cout << "Create thread1 failed." << endl;
return ;
} pthread_join(pid0, NULL);
pthread_join(pid1, NULL);
cout << gCount << endl; if (gCount == )
cout << "Success" << endl;
else
cout << "Fail" << endl; return ;
}
peterson测试代码
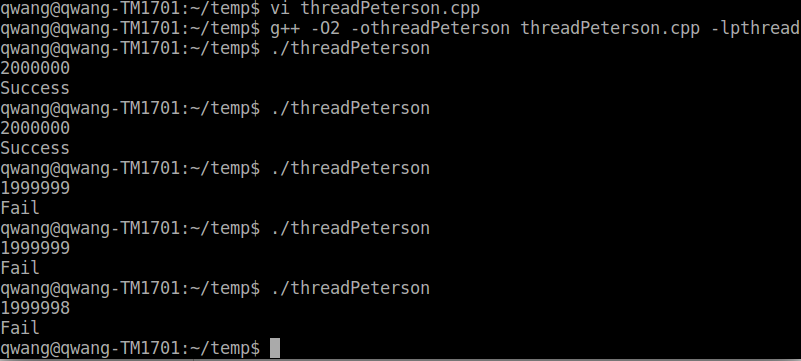
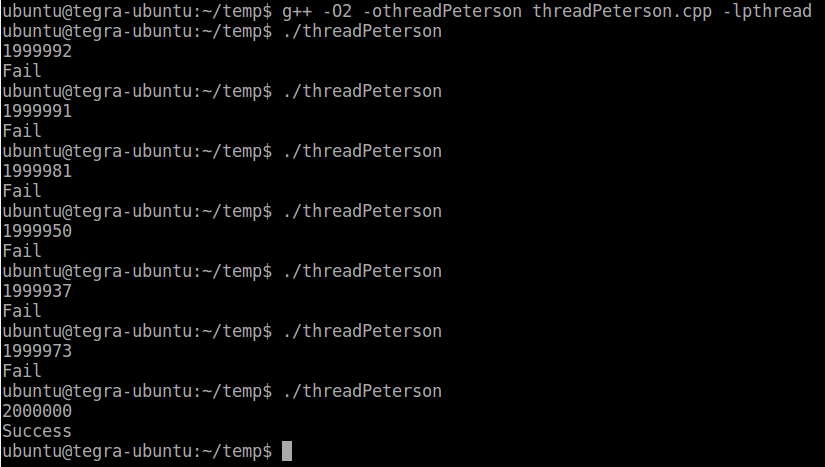
x86平台peterson锁失效 arm平台peterson锁失效
这个测试程序在Linux上用gcc编译,无论用O0,O1,O2编译选项,我试过x86平台,Arm平台,结果都有可能小于两百万,也就是这样实现的peterson锁不能阻止两个线程同时进入临界区。原因在于现代的编译器和多核CPU因为优化代码的原因,最擅长的事情就是指令乱序执行。编译器做的是静态乱序优化,CPU做的是动态乱序优化。简单来说,就是指令最终在CPU的执行顺序和我们在程序中写的顺序可能是大相径庭的。当然这种乱序执行是要在保证最终执行结果正确的前提下的,大多数情况下都不会引起问题,我们对指令的乱序执行也毫无感知。但是在一些特殊的情况下,比如peterson算法里,乱序优化可能会引起问题。
通常情况下,乱序优化都可以把对不同地址的load操作提到store之前去,我想这是因为load操作如果cache命中的话,要比store快很多。以线程0为例,看这3行。
flag[] = true;
turn = ;
while (flag[] && (turn == ));
前两行是store,第三行是load。但是对同一变量turn的store再load,乱序优化是不可能对他们交换顺序的。但是flag[0]和flag[1]是不同的变量,先store后load就可能被乱序优化成先load flag[1],再store flag[0]。假设两个线程都已退出临界区,准备再次进入,此时flag[0]和flag[1]都是false。按乱序执行先load,两个线程都会有while条件为假,则同时都可以进入了临界区,互斥失效!这就是在有些情况下要保持代码的顺序一致性的重要。
这个问题怎么解决呢?也很简单,就是使用内存栅栏(memory barrier)。顾名思义,他就像个栅栏一样摆在两段代码之间,阻止编译器或者CPU在这两段代码之间进行乱序优化。在x86平台上,阻止编译器的静态乱序优化的汇编代码是
asm volatile("" ::: "memory");
但是它不能阻止CPU运行时的乱序优化。在这里我们需要的不仅仅是阻止静态乱序,还要阻止动态乱序。x86的动态内存栅栏汇编命令有三条,分别是lfence,sfence和mfence,分别表示load栅栏,store栅栏和读写栅栏。也就是lfence只能保证lfence之前的读命令不和它之后的读命令发生乱序。sfence保证sfence之前的写命令不和它之后的写命令发生乱序。mfence保证了它前后的读写命令不发生乱序。这里我们需要用mfence,不过实际上我是了sfence也是可以的,但是lfence不行。
flag[] = true;
turn = ;
asm("mfence");
while (flag[] && (turn == ));
在中间插入一行内存栅栏指令,这样peterson测试程序执行才是完全正确的。
在arm平台,相应的内存栅栏指令有三条,dmb(data memroy barrier),dsb(date synchronization barrier)和isb(instruction synchronization barrier)。dmb保证在dmb之前的内存访问指令在它之后的内存访问指令之前完成,也就是阻止了乱序。dsb更严格一些,保证在dsb完成之前,所有它之前的指令都执行完成。isb最严格,它会清空处理器的流水线,当然就能保证之前的所有指令执行完,它之后的指令必须从cache或内存获取。在这里我们用dmb就足够了,dmb指令带有参数。用来表达该barrier生效的Shareability Domain(NSH表示Non-shareable、ISH表示Inner Shareable、OSH表示Outer Shareable、SY表示Full system,缺省是SY)和内存操作类型(LD表示读操作,ST表示写操作,缺省表示读写操作),比如DMB ISHST 表示对Inner Shareability Domain的读写操作生效。在peterson算法这里是能保证正常工作的,或者直接用dmb sy。
flag[] = true;
turn = ;
asm("dmb ishst");
//asm("dmb sy");
while (flag[] && (turn == ));
由于汇编指令和平台相关,移植不便。4.4.0和之后版本的gcc方便地提供了__sync_synchronize函数完成内存栅栏指令。
flag[] = true;
turn = ;
__sync_synchronize();
while (flag[] && (turn == ));
内存栅栏(memory barrier):解救peterson算法的应用陷阱的更多相关文章
- 内存屏障 & Memory barrier
Memory Barrier http://www.wowotech.net/kernel_synchronization/memory-barrier.html 这里面讲了Memory Barrie ...
- memory barrier 内存栅栏 并发编程
并发编程 memory barrier (内存栅栏) CPU级 1.CPU中有多条流水线,执行代码时,会并行进行执行代码,所以CPU需要把程序指令 分配给每个流水线去分别执行,这个就是乱序执行: 2. ...
- 内存屏障(Memory barrier)-- 转发
本文例子均在 Linux(g++)下验证通过,CPU 为 X86-64 处理器架构.所有罗列的 Linux 内核代码也均在(或只在)X86-64 下有效. 本文首先通过范例(以及内核代码)来解释 Me ...
- 并行计算之Memory barrier(内存
本文转载自:http://name5566.com/4535.html 参考文献列表:http://en.wikipedia.org/wiki/Memory_barrierhttp://en.wiki ...
- 理解 Memory barrier(内存屏障)无锁环形队列
原文:https://www.cnblogs.com/my_life/articles/5220172.html Memory barrier 简介 程序在运行时内存实际的访问顺序和程序代码编写的访问 ...
- 理解 Memory barrier(内存屏障)【转】
转自:http://name5566.com/4535.html 参考文献列表:http://en.wikipedia.org/wiki/Memory_barrierhttp://en.wikiped ...
- memory barrier 内存屏障 编译器导致的乱序
小结: 1. 很多时候,编译器和 CPU 引起内存乱序访问不会带来什么问题,但一些特殊情况下,程序逻辑的正确性依赖于内存访问顺序,这时候内存乱序访问会带来逻辑上的错误, 2. https://gith ...
- 理解 Memory barrier
理解 Memory barrier(内存屏障) 发布于 2014 年 04 月 21 日2014 年 05 月 15 日 作者 name5566 参考文献列表:http://en.wikipedia. ...
- Linux内核同步机制之(三):memory barrier【转】
转自:http://www.wowotech.net/kernel_synchronization/memory-barrier.html 一.前言 我记得以前上学的时候大家经常说的一个词汇叫做所见即 ...
随机推荐
- 随select动,将value值显示在后面的input里
<!doctype html><html lang="en"> <head> <meta charset="UTF-8" ...
- Beyond Compare 4 提示错误“这个授权密钥已被吊销”的解决办法
错误提示: 这个授权密钥已被吊销. 解决方法: 删除以下目录中的所有文件即可. C:\Users\Administrator\AppData\Roaming\Scooter Software\Beyo ...
- 从零开始学spring cloud(五) -------- 将服务注册到Eureka上
一.开发前准备工作: 官方文档地址:https://cloud.spring.io/spring-cloud-static/spring-cloud-netflix/2.1.0.RELEASE/mul ...
- layabox typescript 安装固定版本
安装最新版本方法: https://blog.csdn.net/adelais__/article/details/79181474 固定版本(比如2.1.5): C:\Users\Administr ...
- L3-021 神坛(极角排序求三角形最小面积)
在古老的迈瑞城,巍然屹立着 n 块神石.长老们商议,选取 3 块神石围成一个神坛.因为神坛的能量强度与它的面积成反比,因此神坛的面积越小越好.特殊地,如果有两块神石坐标相同,或者三块神石共线,神坛的面 ...
- strin 数组转换成int 数组
string[] strarry = ids.Trim(',').Split(','); int[] arryInts = Array.ConvertAll<string, int>(st ...
- 《Java从入门到精通》学习总结1
1. Java既是编译型语音,也是解释型语言:先将源代码编译成Java字节码,然后Java虚拟机对Java字节码进行解释运行 2. 使用命令行编译Java源代码时,如果代码中有中文,在编译时需要指定编 ...
- JavaSE基础知识(5)—面向对象(Object类)
一.包 java.lang包,属于java中的核心包,系统默认导入的,不用手动导入该包中的类:Object.System.String.Integer等 1.包的好处 ①分类管理java文件,查找和管 ...
- rest_framework的视图组件继承过哪些类?
- maven项目引用时,导入类报错,选择两个项目同时执行Maven update
maven项目引用时,导入类报错,选择两个项目同时执行Maven update springboot引入第三方jar,需要扫描时加@ComponentScan("第三方的包名") ...