Python 爬虫四 基础案例-自动登陆github
GET&POST请求一般格式
爬取Github数据
GET&POST请求一般格式
很久之前在讲web框架的时候,曾经提到过一句话,在网络编程中“万物皆socket”。任何的网络通信归根结底,就是服务端跟客户端的一次socket通信。发送一个socket请求给服务端,服务端作出响应返回socket给客户端。
在此,就不详细介绍HTTP请求头,网上的大牛博客多的很,这里针对请求头跟请求体,稍微了解下一般规律,只是为了爬虫准备基础。
HTTP请求
既然万物皆socket,那么不论客户端还是服务端拿到的一定是一段socket,说白了就是一串字符串。那么请求头与请求体,或者响应头与响应体是如何解析出来的呢?
这里,先查看下google的network内的请求信息:
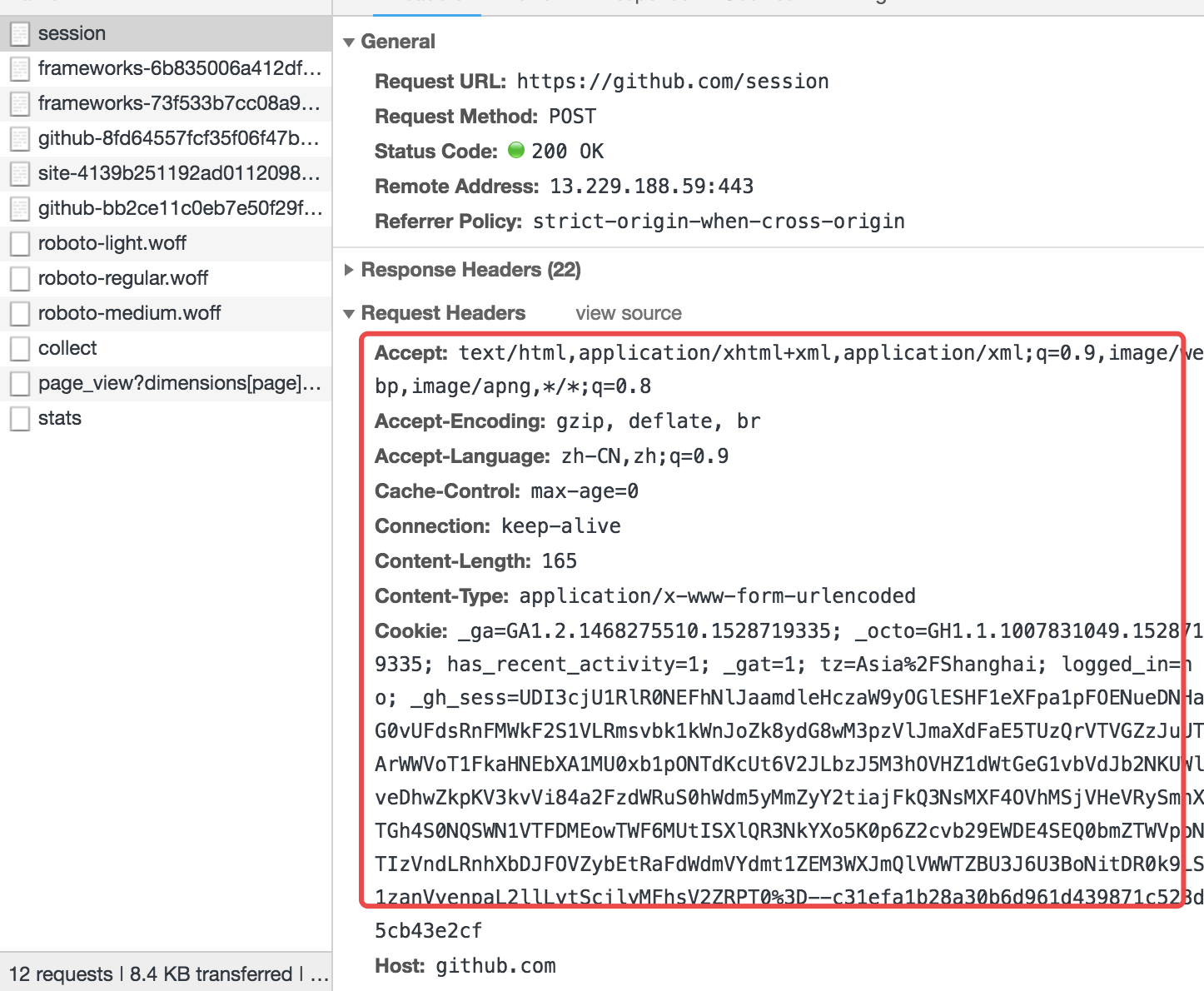
无论是请求还是响应都是特别规整的数据。
在Http请求中,请求头跟请求体之间是通过/r/n/r/n分割开的。
请求头内容Accept-Encoding: gzip, deflate, br/r/nContent-Type: application/x-www-form-urlencoded/r/n......./r/n/r/n请求体
如上的一串字符串、会根据/r/n/r/n解析出来请求头跟请求体,然后根据/r/n来换行。
响应体也是一样的套路。
唯一需要特殊提醒的是:
*************************************响应*************************************
普通:
响应头:
content-encoding:utf8
....
响应体:
<html>.....</html>
重定向:
响应头:
status code
location:http://www.baidu.com
**************************************************************************
重定向只有响应头,里面又一个状态码(具体忘了是多少),还有一个location,是指向重定向网址的。
关于GET请求
Get请求只有请求头。
GitHub自动登录爬取
看到这份需求的第一步,需要先打开github的登陆页面测试下登陆:
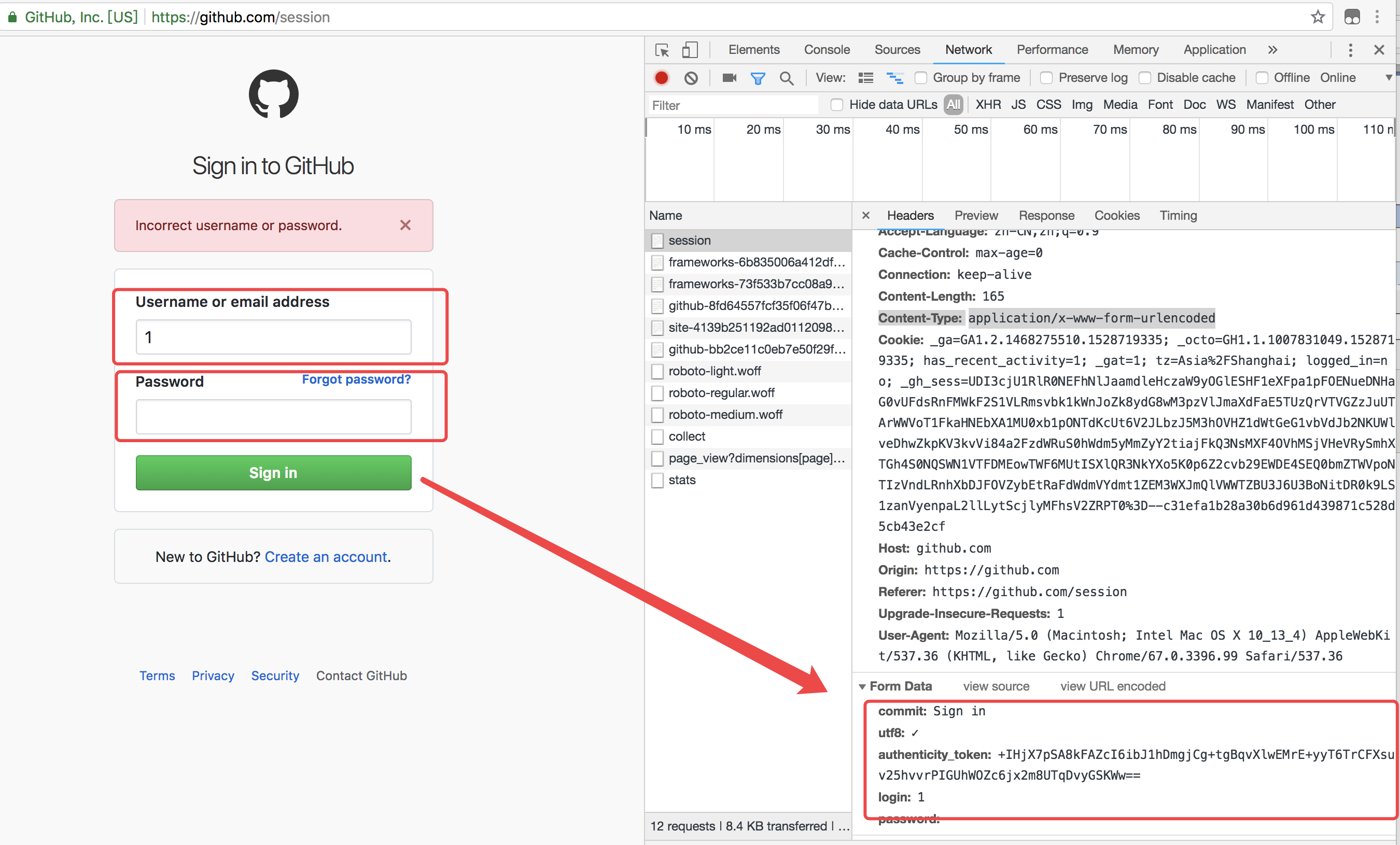
上面的图片,随便输入了账号密码测试,发现了两点
1、账号密码验证是form提交
2、熟悉的字眼token
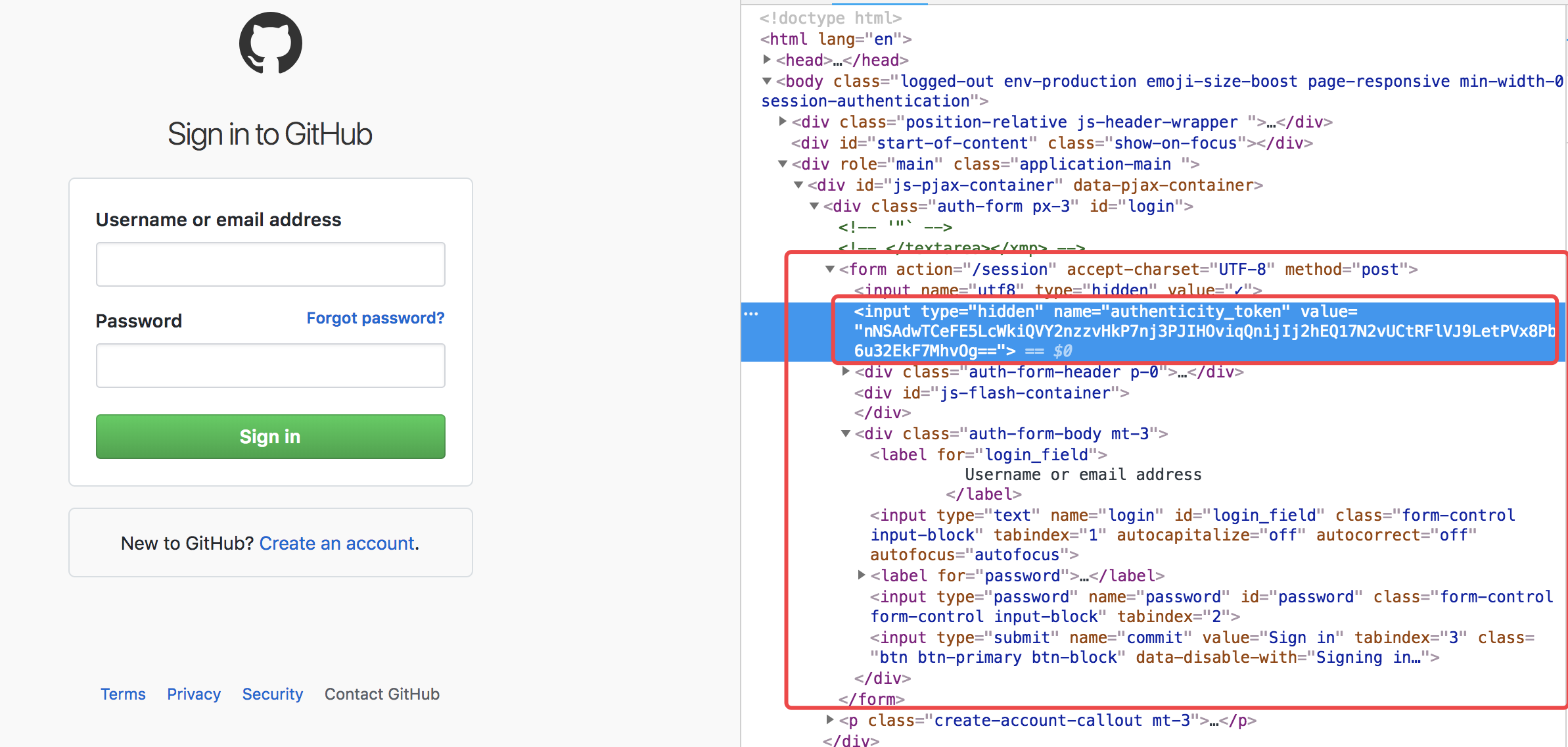
如果是从django看过来的小伙伴一定会会心一笑、懂了。所以,自动登录爬取数据的一般流程如下:
1、发送get请求,先获取到token值
2、发送post请求,进行登陆验证
3、带着cookie肆意妄为
代码如下:
import requests
from bs4 import BeautifulSoup # 第一步:发送第一次请求,获取csrftoken
r1 = requests.get(
url='https://github.com/login'
)
bs1 = BeautifulSoup(r1.text, 'html.parser') # 对获取到的文本对象解析获取token值
obj_token = bs1.find(
name='input',
attrs={'name': 'authenticity_token'}
)
# token = obj_token.attrs.get('value') # 获取token值的两种方式
token = obj_token.get('value')
print(token)
# 第二步:发送post请求,携带用户名密码并伪造请求头
r2 = requests.post(
url='https://github.com/session',
data={
'commit': 'Sign in',
'utf8': '✓',
'authenticity_token': token,
'login': 'wuzdandz@qq.com',
'password': 'jiao88'
}
) r2_cookie = r2.cookies.get_dict()
print(r2_cookie)
print(r2.text)
# 因为是form data提交所以网页是走的重定向,获取状态码&location
# 1、根据状态码;2、根据错误提示 # 第三步:访问个人页面,携带cookie
r3 = requests.get(
url='https://github.com/settings/repositories',
cookies=r2_cookie
)
print(r3.text)
测试结果:
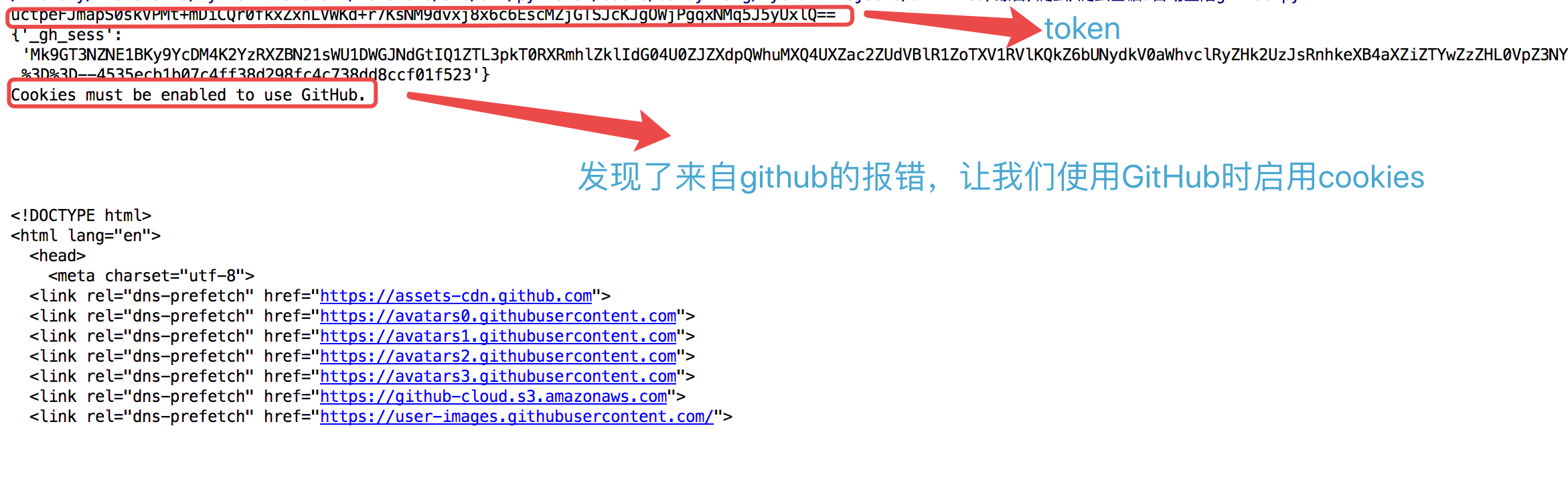
此时,github已经提示需要开启cookies。再来查看一次network:
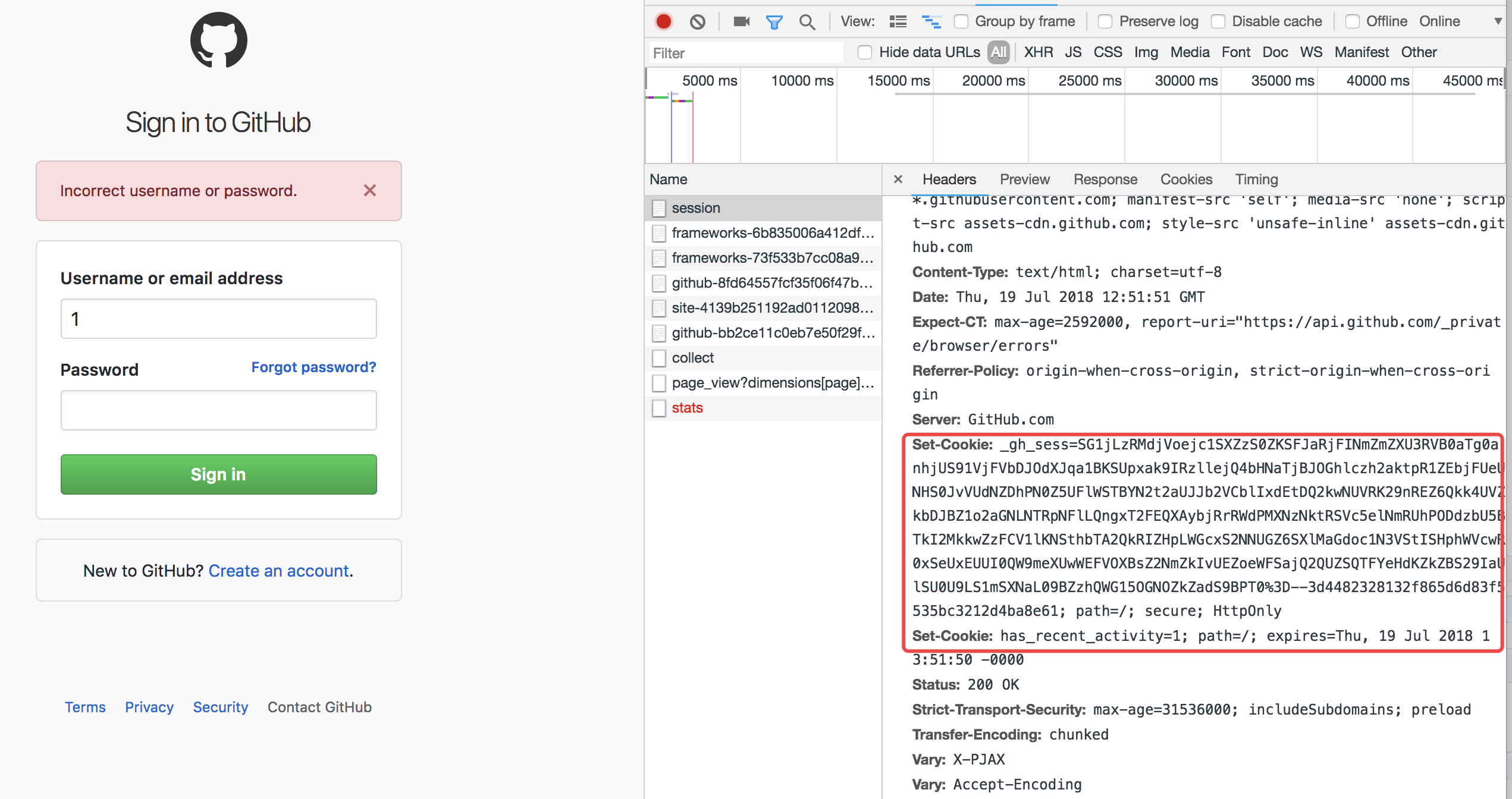
发现第一次响应头就带着cookie了。所以一般流程应该改成:
1、发送get请求,先获取到token值和cookie
2、发送post请求,带入账号名密码,cookies进行登陆验证
3、带着cookie肆意妄为
修改下代码:
import requests
from bs4 import BeautifulSoup # 第一步:发送第一次请求,获取csrftoken
r1 = requests.get(
url='https://github.com/login'
)
bs1 = BeautifulSoup(r1.text, 'html.parser')
obj_token = bs1.find(
name='input',
attrs={'name': 'authenticity_token'}
)
# token = obj_token.attrs.get('value')
token = obj_token.get('value')
r1_cookie = r1.cookies.get_dict() # 获取第一次cookie值、格式化成字典
print(r1_cookie) # 第二步:发送post请求,携带用户名密码并伪造请求头
r2 = requests.post(
url='https://github.com/session',
data={
'commit': 'Sign in',
'utf8': '✓',
'authenticity_token': token,
'login': 'wuzdandz@qq.com',
'password': 'jiao88'
},
cookies=r1_cookie # 带入第一次的cookie做验证
) r2_cookie = r2.cookies.get_dict()
print(r2_cookie)
r1_cookie.update(r2_cookie) # 更新到第一次response的cookie字典里
print(r1_cookie)
# 因为是form data提交所以网页是走的重定向,获取状态码&location
# 1、根据状态码;2、根据错误提示 # 第三步:访问个人页面,携带cookie
r3 = requests.get(
url='https://github.com/settings/repositories',
cookies=r1_cookie # 带入cookie肆意妄为
)
print(r3.text)
结果:
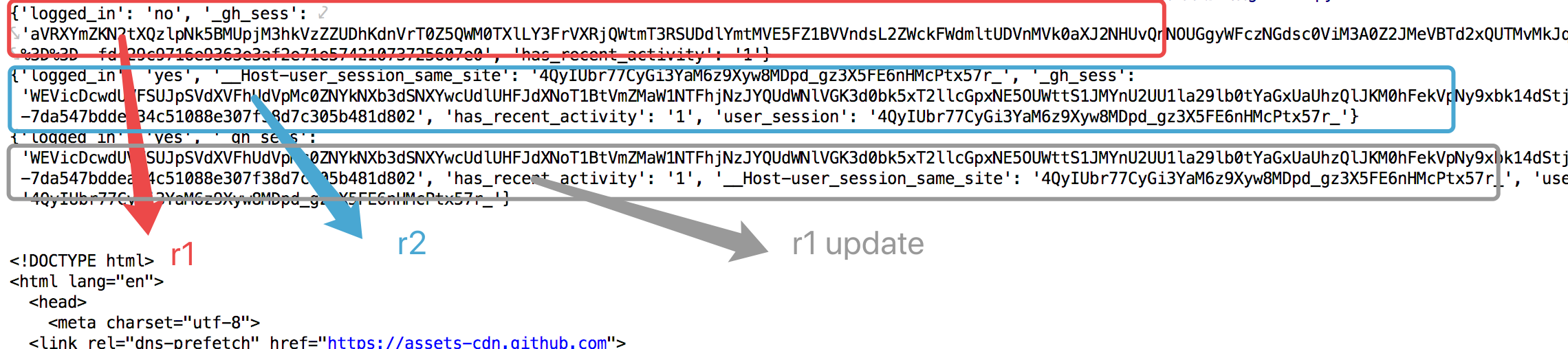
r3.text:
Python 爬虫四 基础案例-自动登陆github的更多相关文章
- Python爬虫教程:requests模拟登陆github
1. Cookie 介绍 HTTP 协议是无状态的.因此,若不借助其他手段,远程的服务器就无法知道以前和客户端做了哪些通信.Cookie 就是「其他手段」之一. Cookie 一个典型的应用场景,就是 ...
- 爬虫【自动登陆github和抽屉】
自动登陆github用户详情页 代码 #! /usr/bin/env python # -*- coding: utf- -*- # __author__ = "wuxiaoyu" ...
- Python爬虫学习笔记之模拟登陆并爬去GitHub
(1)环境准备: 请确保已经安装了requests和lxml库 (2)分析登陆过程: 首先要分析登陆的过程,需要探究后台的登陆请求是怎样发送的,登陆之后又有怎样的处理过程. 如果已经 ...
- 如何用Python爬虫实现百度图片自动下载?
Github:https://github.com/nnngu/LearningNotes 制作爬虫的步骤 制作一个爬虫一般分以下几个步骤: 分析需求 分析网页源代码,配合开发者工具 编写正则表达式或 ...
- Python爬虫(四)——开封市58同城数据模型训练与检测
前文参考: Python爬虫(一)——开封市58同城租房信息 Python爬虫(二)——对开封市58同城出租房数据进行分析 Python爬虫(三)——对豆瓣图书各模块评论数与评分图形化分析 数据的构建 ...
- Python爬虫(四)——豆瓣数据模型训练与检测
前文参考: Python爬虫(一)——豆瓣下图书信息 Python爬虫(二)——豆瓣图书决策树构建 Python爬虫(三)——对豆瓣图书各模块评论数与评分图形化分析 数据的构建 在这张表中我们可以发现 ...
- 爬虫自动登陆GitHub
import requests from bs4 import BeautifulSoup r1 = requests.get( url='https://github.com/login' ) s1 ...
- Python 爬虫五 进阶案例-web微信登陆与消息发送
首先回顾下网页微信登陆的一般流程 1.打开浏览器输入网址 2.使用手机微信扫码登陆 3.进入用户界面 1.打开浏览器输入网址 首先打开浏览器输入web微信网址,并进行监控: https://wx.qq ...
- Python爬虫(十一)_案例:使用正则表达式的爬虫
本章将结合先前所学的爬虫和正则表达式知识,做一个简单的爬虫案例,更多内容请参考:Python学习指南 现在拥有了正则表达式这把神兵利器,我们就可以进行对爬取到的全部网页源代码进行筛选了. 下面我们一起 ...
随机推荐
- 2018最完整ITTO分节整理指导(PMP项目管理入门必备)
2018年项目管理基础教材<PMBOK>指南进行了改版,之前的一些PMP资料没有太大帮助,反而会让大家记忆混淆,用最新的会好一些,今天小编就把搜集到的2018年项目管理最详细的ITTO的P ...
- 点赞功能与redis
转:https://edu.aliyun.com/a/20538 摘要: 前言点赞其实是一个很有意思的功能.基本的设计思路有大致两种, 一种自然是用mysql等数据库直接落地存储, 另外一种就是利用点 ...
- M1-Flask-Day3
内容概要: websocket mysql连接池 sqlalchemy flask-sqlalchemy 练习: 1. 谈谈Flask和Django的认识? Django大而全的框架,把Web相关设计 ...
- python bytes类型去除尾部字节
by = b'\x01\x02' print(by) by = by.rstrip() print(by) by = by.rstrip(chr(2).encode()) print(by) b'\x ...
- go tcp
TCP编程 1.客户端和服务器 2.服务端的处理流程 监听端口 接收客户端的链接 创建goroutine,处理该链接 3.客户端的处理流程 建立与服务端的链接 进行数据收发 关闭链接 服务端代码 pa ...
- protobuf 编译安装
1.protobuf是google公司提出的数据存储格式,详细介绍可以参考:https://developers.google.com/protocol-buffers 2.下载最新的protobuf ...
- 使用 boot-repair 对 Windows + Ubuntu 双系统引导修复
问题描述: 由于在windows上进行更新/重装/修改了引导设置以后,windows会“自私”地重写引导,导致Ubuntu系统引导消失而无法选择Ubuntu启动.
- Synchronous XMLHttpRequest on the main thread is deprecated because of its detrimental effects to the end user's experience. For more jquery-1.12.4.js:10208
ajax执行请求之后返回了数据但是不执行success()函数,原因是返回得数据类型不是ajax请求中设定的:dataType:"json",因为是一个Map<Object, ...
- 标签中的onclick调用js方法传递多个参数的解决方案
1.JS方法 <script type="text/javascript"> funcation cc(parameter1,parameter2,parameter3 ...
- extern "C" 含义
extern "C" 被 extern 限定的函数或变量是 extern 类型的 被 extern "C" 修饰的变量和函数是按照 C 语言方式编译和链接的 e ...