Innobackupex(xtrabackup)物理备份
1. Percona XtraBackup介绍
Percona XtraBackup(简称PXB)是 Percona 公司开发的一个完全开源的用于 MySQL 数据库物理热备的备份工具,在备份过程中不会锁定数据库。它可以备份来自MySQL5.1,5.5,5.6和5.7服务器上的InnoDB,XtraDB和MyISAM表的数据,以及带有XtraDB的Percona服务器。
Percona XtraBackup为所有版本的Percona Server,MySQL和MariaDB进行MySQL热备份。它执行流,压缩和增量MySQL备份。
1.1 工具集
软件包安装完后一共有4个可执行文件,如下:
usr
├── bin
│ ├── innobackupex
│ ├── xbcrypt
│ ├── xbstream
│ └── xtrabackup
其中最主要的是 innobackupex 和 xtrabackup,前者是一个 perl 脚本,后者是 C/C++ 编译的二进制。
xtrabackup 是用来备份 InnoDB 表的,不能备份非 InnoDB 表,和 mysqld server 没有交互;innobackupex 脚本用来备份非 InnoDB 表,同时会调用 xtrabackup 命令来备份 InnoDB 表,还会和 mysqld server 发送命令进行交互,如加读锁(FTWRL)、获取位点(SHOW SLAVE STATUS)等。简单来说,innobackupex 在 xtrabackup 之上做了一层封装。
一般情况下,我们是希望能备份 MyISAM 表的,虽然我们可能自己不用 MyISAM 表,但是 mysql 库下的系统表是 MyISAM 的,因此备份基本都通过 innobackupex 命令进行;另外一个原因是我们可能需要保存位点信息。
另外2个工具相对小众些,xbcrypt 是加解密用的;xbstream 类似于tar,是 Percona 自己实现的一种支持并发写的流文件格式。两都在备份和解压时都会用到(如果备份用了加密和并发)。
1.2 原理及通信方式
2个工具之间的交互和协调是通过控制文件的创建和删除来实现的,主要文件有:
- xtrabackup_suspended_1
- xtrabackup_suspended_2
- xtrabackup_log_copied
举个栗子,我们来看备份时 xtrabackup_suspended_2 是怎么来协调2个工具进程的
innobackupex在启动xtrabackup进程后,会一直等xtrabackup备份完 InnoDB 文件,方式就是等待 xtrabackup_suspended_2 这个文件被创建出来;xtrabackup在备完 InnoDB 数据后,就在指定目录下创建出这个文件,然后等这个文件被innobackupex删除;innobackupex检测到文件 xtrabackup_suspended_2 被创建出来后,就继续往下走;innobackupex在备份完非 InnoDB 表后,删除 xtrabackup_suspended_2 这个文件,这样就通知xtrabackup可以继续了,然后等 xtrabackup_log_copied 被创建;xtrabackup检测到 xtrabackup_suspended_2 文件删除后,就可以继续往下了。
是不是感觉有点不可思议,通过文件是否存在来控制进程,这种方式非常的不靠谱,因为非常容易被外部干扰,比如文件被别人误删掉,或者2个正在跑的备份控制文件误放在同一个目录下,就等着备份乱掉吧,但是 Percona 就是这么干的。
之所以这么搞,估计主要是因为 perl 和 C 二进制2个进程,没有既好用又方便的通信方式,搞个协议啥的太麻烦了。但是官方也觉得这种方式不靠谱,11年就搞了个 blueprint 要用C重写 innobackupex,终于在2.3 版本实现了,innobackupex 功能全部集成到 xtrabackup 里面,只有一个 binary,另外为了使用上的兼容考虑,innobackupex作为 xtrabackup 的一个软链。对于二次开发来说,2.3 摆脱了之前2个进程协作的负担,架构上明显要好于之前版本。考虑到 perl + C 这种架构的长期存在,大多数读者朋友也基本用的2.3之前版本,本文的介绍也是基于老的架构(2.2版本),但是原理和2.3是一样的,只是实现上的差别。
1.3 备份过程
innobackupex备份过程如下图:
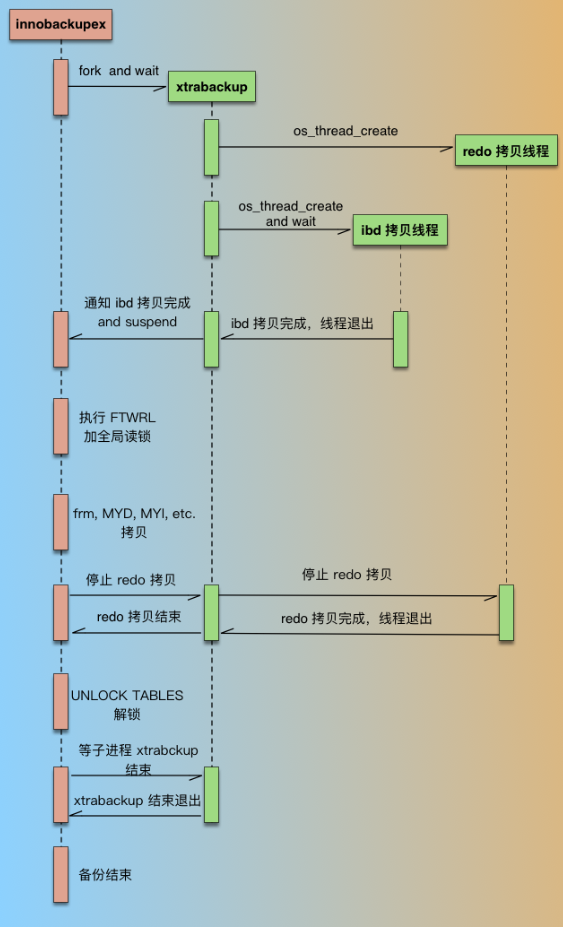
innobackupex在启动后,会先 fork 一个进程,启动xtrabackup进程,然后就等待xtrabackup备份完 ibd 数据文件;xtrabackup在备份 InnoDB 相关数据时,是有2种线程的,1种是 redo 拷贝线程,负责拷贝 redo 文件,1种是 ibd 拷贝线程,负责拷贝 ibd 文件;redo 拷贝线程只有一个,在 ibd 拷贝线程之前启动,在 ibd 线程结束后结束。xtrabackup进程开始执行后,先启动 redo 拷贝线程,从最新的 checkpoint 点开始顺序拷贝 redo 日志;然后再启动 ibd 数据拷贝线程,在xtrabackup拷贝 ibd 过程中,innobackupex进程一直处于等待状态(等待文件被创建)。xtrabackup拷贝完成idb后,通知innobackupex(通过创建文件),同时自己进入等待(redo 线程仍然继续拷贝);innobackupex收到xtrabackup通知后,执行FLUSH TABLES WITH READ LOCK(FTWRL),取得一致性位点,然后开始备份非 InnoDB 文件(包括 frm、MYD、MYI、CSV、opt、par等)。拷贝非 InnoDB 文件过程中,因为数据库处于全局只读状态,如果在业务的主库备份的话,要特别小心,非 InnoDB 表(主要是MyISAM)比较多的话整库只读时间就会比较长,这个影响一定要评估到。- 当
innobackupex拷贝完所有非 InnoDB 表文件后,通知xtrabackup(通过删文件) ,同时自己进入等待(等待另一个文件被创建); xtrabackup收到innobackupex备份完非 InnoDB 通知后,就停止 redo 拷贝线程,然后通知innobackupexredo log 拷贝完成(通过创建文件);innobackupex收到 redo 备份完成通知后,就开始解锁,执行UNLOCK TABLES;- 最后
innobackupex和xtrabackup进程各自完成收尾工作,如资源的释放、写备份元数据信息等,innobackupex等待xtrabackup子进程结束后退出。
在上面描述的文件拷贝,都是备份进程直接通过操作系统读取数据文件的,只在执行 SQL 命令时和数据库有交互,基本不影响数据库的运行,在备份非 InnoDB 时会有一段时间只读(如果没有MyISAM表的话,只读时间在几秒左右),在备份 InnoDB 数据文件时,对数据库完全没有影响,是真正的热备。
InnoDB 和非 InnoDB 文件的备份都是通过拷贝文件来做的,但是实现的方式不同,前者是以page为粒度做的(xtrabackup),后者是 cp 或者 tar 命令(innobackupex),xtrabackup 在读取每个page时会校验 checksum 值,保证数据块是一致的,而 innobackupex 在 cp MyISAM 文件时已经做了flush(FTWRL),磁盘上的文件也是完整的,所以最终备份集里的数据文件都是写入完整的。
1.4 增量备份
PXB 是支持增量备份的,但是只能对 InnoDB 做增量,InnoDB 每个 page 有个 LSN 号,LSN 是全局递增的,page 被更改时会记录当前的 LSN 号,page中的 LSN 越大,说明当前page越新(最近被更新)。每次备份会记录当前备份到的LSN(xtrabackup_checkpoints 文件中),增量备份就是只拷贝LSN大于上次备份的page,比上次备份小的跳过,每个 ibd 文件最终备份出来的是增量 delta 文件。
MyISAM 是没有增量的机制的,每次增量备份都是全部拷贝的。
增量备份过程和全量备份一样,只是在 ibd 文件拷贝上有不同。
恢复过程:
如果看恢复备份集的日志,会发现和 mysqld 启动时非常相似,其实备份集的恢复就是类似 mysqld crash后,做一次 crash recover。
恢复的目的是把备份集中的数据恢复到一个一致性位点,所谓一致就是指原数据库某一时间点各引擎数据的状态,比如 MyISAM 中的数据对应的是 15:00 时间点的,InnoDB 中的数据对应的是 15:20 的,这种状态的数据就是不一致的。 PXB 备份集对应的一致点,就是备份时FTWRL的时间点,恢复出来的数据,就对应原数据库FTWRL时的状态。
因为备份时 FTWRL 后,数据库是处于只读的,非 InnoDB 数据是在持有全局读锁情况下拷贝的,所以非 InnoDB 数据本身就对应 FTWRL 时间点;InnoDB 的 ibd 文件拷贝是在 FTWRL 前做的,拷贝出来的不同 ibd 文件最后更新时间点是不一样的,这种状态的 ibd 文件是不能直接用的,但是 redo log 是从备份开始一直持续拷贝的,最后的 redo 日志点是在持有 FTWRL 后取得的,所以最终通过 redo 应用后的 ibd 数据时间点也是和 FTWRL 一致的。所以恢复过程只涉及 InnoDB 文件的恢复,非 InnoDB 数据是不动的。备份恢复完成后,就可以把数据文件拷贝到对应的目录,然后通过mysqld来启动了。
1.5 功能总结
1) 在不暂停数据库的情况下创建热的InnoDB备份
2) 进行MySQL的增量备份
3) 将压缩的MySQL备份传输到另一台服务器
4) 在MySQL服务器之间移动表格
5) 轻松创建新的MySQL复制从站
6) 在不增加服务器负载的情况下备份MySQL
2. 安装Xtrabackup备份命令
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo
yum -y install perl perl-devel libaio libaio-devel perl-Time-HiRes perl-DBD-MySQL wget https://www.percona.com/downloads/XtraBackup/Percona-XtraBackup-2.4.4/binary/redhat/6/x86_64/percona-xtrabackup-24-2.4.4-1.el6.x86_64.rpm
yum -y install percona-xtrabackup--2.4.-.el6.x86_64.rpm
2.1 Xtrabackup常用参数
常用参数:
--user=USER 指定备份用户,不指定的话为当前系统用户
--password=PASSWD 指定备份用户密码
--port=PORT 指定数据库端口
--defaults-group=GROUP-NAME 在多实例的时候使用
--host=HOST 指定备份的主机,可以为远程数据库服务器
--apply-log 回滚日志
--database 指定需要备份的数据库,多个数据库之间以空格分开
--defaults-file 指定mysql的配置文件
--copy-back 将备份数据复制回原始位置
--incremental 增量备份,后面跟要增量备份的路径
--incremental-basedir=DIRECTORY 增量备份时使用指向上一次的增量备份所在的目录
--incremental-dir=DIRECTORY 增量备份还原的时候用来合并增量备份到全量,用来指定全备路径
--redo-only 对增量备份进行合并
--rsync 加快本地文件传输,适用于non-InnoDB数据库引擎。不与--stream共用
--safe-slave-backup 会暂停slave的sql线程,待备份结束后再启动
--no-timestamp 生成的备份文件不以时间戳为目录.
--use-memory 可指定使用多大的内存
--parallel 可指定多少个线程
2.3 指定库备份
innobackupex --defaults-file=/etc/my.cnf --databases=hcms --user=root --password= --use-memory=10G --parallel= /home/sql_bak/ #普通方式指定hcms库不打包备份,不指定库名则为全部备份
time tar -c --03_13--/ |pigz - -p >hcms.tar.gz #对目录压缩
2.4 全库备份
innobackupex --user=root --password=123456 --socket=/tmp/mysql.sock --use-memory=6G --parallel=8 /home/sqlbackup/ #先做一次全备 比如周一0点
#可写成shell加入定时任务自动备份
#!/bin/bash
#sync
#echo 3 > /proc/sys/vm/drop_caches
#echo 0 > /proc/sys/vm/drop_caches
innobackupex --user=root --password=123456 --socket=/tmp/mysql.sock --use-memory=6G --parallel=8 --stream=tar /home/sqlbackup/ | pigz -8 -p 15 > /home/sqlbackup/sql_$(date +%F).tar.gz
sleep 2;
/usr/local/bin/rsync -azv --password-file=/etc/rsync.pas --port=873 /home/sqlbackup/sql_$(date +%F).tar.gz root@10.10.10.xx::90sql
#恢复实践
innobackupex --apply-log --use-memory=10G /home/sqlbackup/2018-09-19_16-01-39 #恢复数据前的准备(合并xtrabackup_log_file和备份的物理文件)
停库:
/etc/init.d/mysqld stop
lsof -i :
破坏数据:
cd /home/sqldata/ #注意:恢复的其实是datadir下面的的所有数据
mv mysql /opt/
恢复:
cp -a /home/sqlbackup/full/2018-09-19_14-30-26/* /home/sqldata/mysql #可直接拷贝备份好的文件恢复
#innobackupex --defaults-file=/etc/my.cnf --copy-back /home/sqlbackup/2018-09-19_16-01-39 #常用还原数据另一种方式
chown -R mysql.mysql /home/sqldata/mysql #授权
/etc/init.d/mysql.server start #数据恢复
数据恢复成功。
2.5 增量实践
#第一次增量 周二0点
innobackupex --user=root --password= --socket=/tmp/mysql.sock --use-memory=6G --parallel= --incremental /home/sqlbackup/ --incremental-basedir=/home/sqlbackup/--19_16--/ #第一次增量,时间是基于最初的全量备份
#第二次增备 周三0点
innobackupex --user=root --password= --socket=/tmp/mysql.sock --use-memory=6G --parallel= --incremental /home/sqlbackup/ --incremental-basedir=/home/sqlbackup/--19_16--/ #第二次增量,时间是基于第一次的增量备份
#查看备份的文件
cd /home/sqlbackup/
[root@localhost sqlbackup]# ll
total
drwxr-x--- root root Sep : --19_16--
drwxr-x--- root root Sep : --19_16--
drwxr-x--- root root Sep : --19_16-- #增量备份恢复
#模拟故障,合并增量开始恢复
a.建议停库:
最好用iptables
iptables -I INPUT -p tcp --dport -j DROP
/etc/init.d/mysqld stop
b.合并数据文件---所有的全量做redo,所有增量做合并,redo
innobackupex --apply-log --use-memory=8G --redo-only /home/sqlbackup/--19_16-- #读取全部备份的事物日志,不回滚
innobackupex --apply-log --use-memory=8G --redo-only --incremental-dir=/home/sqlbackup/--19_16-- /home/sqlbackup/--19_16-- #读取第一次增量备份事物日志的导入全量备份的事物日志中,不回滚
innobackupex --apply-log --use-memory=8G --incremental-dir=/home/sqlbackup/--19_16-- /home/sqlbackup/--19_16-- #读取第二次增量备份事物日志的导入全量备份的事物日志中,不回滚
#至此数据文件准备完毕 #开始正式恢复,还原数据
cd /home/sqldata/
mv mysql mysql_old
\cp -a /home/sqlbackup/full/--19_14-- #copy方式
innobackupex --defaults-file=/etc/my.cnf --copy-back /home/sqlbackup/2018-09-19_16-01-39 #copy-back方式回滚
chown -R mysql.mysql data
#至此增量备份已完成,可查看数据已恢复
#如果报错:180927 10:09:59 innobackupex: Starting the copy-back operation
IMPORTANT: Please check that the copy-back run completes successfully.
At the end of a successful copy-back run innobackupex
prints "completed OK!".
innobackupex version 2.4.4 based on MySQL server 5.7.13 Linux (x86_64) (revision id: df58cf2)
Error: datadir must be specified
说明my.cnf里没有指定datadir,此时需要手动指定--datadir=/home/sqldata/mysql,或者在配置文件里指定
#innobackupex备份迁移别的服务器恢复实践: 请点击"▶▶▶"
2.6 备份脚本示例
阿里云RDS使用Xtrabackup将数据导入自建MySQL参考:https://help.aliyun.com/knowledge_detail/41817.html
cal|awk 'BEGIN{"date +%d"|getline day}{for(i=1;i<=NF;i++) if($i==day) print NR-2}' ##判断今天是本月的第几周
Innobackupex(xtrabackup)物理备份的更多相关文章
- XtraBackup物理备份 阿里云的Mysql备份方案
XtraBackup物理备份 Percona XtraBackup是世界上唯一的开源,免费的MySQL热备份软件,为InnoDB和XtraDB 数据库执行非阻塞备份.使用Percona XtraBac ...
- MariaDB xtrabackup物理备份与还原
xtrabackup物理备份 1.1 安装xtraback 安装依赖: [root@localhost ~]# yum install -y perl-DBD-MySQL perl-DBI perl- ...
- MySQL数据库之xtrabackup物理备份(一)
前言:说到数据库备份,我们知道可以用来对数据库进行备份的工具有mysqldump.mydumer.mysqlpump等等,实际工作中,机器上的数据库不大的话,都是用mysqldump工具来备份,这些备 ...
- Xtrabackup 物理备份
目录 Xtrabackup 安装 Xtrabackup 备份介绍 Xtrabackup全量备份 准备备份目录 全量备份 查看全量备份内容 Xtrabackup 全量备份恢复数据 删除所有数据库 停止数 ...
- 使用 xtrabackup 进行MySQL数据库物理备份
0. xtrabackup的功能 能实现的功能: 非阻塞备份innodb等事务引擎数据库. 备份myisam表会阻塞(需要锁). 支持全备.增量备份.压缩备份. 快速增量备份(xtradb,原理类似于 ...
- (4.15)mysql备份还原——物理备份之XtraBackup的下载与安装
关键词:mysql物理备份,XtraBackup,XtraBackup安装,XtraBackup下载 实践链接:https://www.cnblogs.com/gered/p/11147193.htm ...
- MySQL数据物理备份之xtrabackup
percona-xtrabackup 它是开源免费的支持MySQL 数据库热备份的软件,它能对InnoDB和XtraDB存储引擎的数据库非阻塞地备份.它不暂停服务创建Innodb热备份: 为mysql ...
- mysql之使用xtrabackup进行物理备份、恢复、在线克隆从库、在线重做主从
注:图片来自<深入浅出MySQL 数据库开发 优化与管理维护 第2版> 物理备份和恢复 1.冷备份:停掉mysql再备份,一般很少用,因为很多应用不允许长时间停机,停机备份的可以直接CP数 ...
- MySQL · 物理备份 · Percona XtraBackup 备份原理
http://mysql.taobao.org/monthly/2016/03/07/ 前言 Percona XtraBackup(简称PXB)是 Percona 公司开发的一个用于 MySQL 数据 ...
随机推荐
- 解题:HAOI2018 苹果树
题面 统计贡献,每个大小为i的子树贡献就是$i(n-i)$,然后子树里又有$i!$种:同时这个子树的根不确定,再枚举这个根是$r$个放的,又有了$r!$种.子树内选点的方式因为子树的根被钦定了顺序所以 ...
- 【洛谷P1903】数颜色
题目大意:给定一个长度为 N 的序列,每个点有一个颜色.现给出 M 个操作,支持单点修改颜色和询问区间颜色数两个操作. 题解:学会了序列带修改的莫队. 莫队本身是不支持修改的.带修该莫队的本质也是对询 ...
- 关于继承的基本知识,方法重写,final和abstract的使用, 动态绑定和静态绑定的知识
一.继承: 涉及关键字: extends(继承) super final abstract 特点: 1.类与类之间可以用 XX是XX来描述 , 那么他们之间就存在继承关系. 2.Java中不支持多继 ...
- php的扩展配置
第一步:在php的安装目录下找到php.ini-development这个文件,并复制一个副本,修改这个副本的文件名为:php.ini 如下图我的目录为: 第二步:打开这个php.ini,修改 将这里 ...
- bzoj2938 AC自动机 + 拓扑排序找环
https://www.lydsy.com/JudgeOnline/problem.php?id=2938 题意:给出N个01病毒序列,询问是否存在一个无限长的串不存在病毒序列 正常来说,想要寻找一个 ...
- 机器学习-随机梯度下降(Stochastic gradient descent)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- docker 基础之网络管理
docker网络基础. docker使用到的与linux网络有关的主要技术 Network Namespace(网络命名空间) Veth设备对 Iptables/NetFilter 网桥 路由 标准的 ...
- C++ 二维数组作为形参传递使用实例
在线代码编辑器: http://codepad.org/ 1.*指针 void display(int *arr, const int row, const int col) { ; i < r ...
- [JVM-1]Java运行时数据区域
Java虚拟机(JVM)内部定义了程序在运行时需要使用到的内存区域 这些区域都有自己的用途,以及创建和销毁的时间.有些区域随着虚拟机进程的启动而存在,有的区域则依赖用户线程的启动和结束而销毁和建立. ...
- 队列 Queue 与 生产者消费模型
队列:先进先出 # from multiprocessing import Queue # Q = Queue(4) # Q.put('a') # Q.put('b') # Q.put('b') # ...