Normal Equation
一、Normal Equation
我们知道梯度下降在求解最优参数\(\theta\)过程中需要合适的\(\alpha\),并且需要进行多次迭代,那么有没有经过简单的数学计算就得到参数\(\theta\)呢?
下面我们看看Ng 4-6 中的房价预测例子:
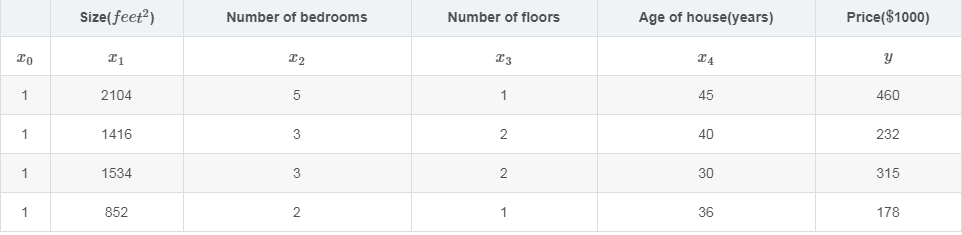
其中\( m = 4, n = 4 \)。在机器学习中,线性回归一般都增加额外的一列特征\(x_0 = 1\),其中我们特征矩阵\(X\)和值向量\(y\)分别为:
\begin{bmatrix}1 & 2104 & 5 & 1 & 45 \\ 1 & 1416 & 3 & 2 & 40 \\ 1 & 1534 & 3 & 2 & 30 \\ 1 & 852 & 2 & 1 & 36 \end{bmatrix}
\begin{bmatrix}460\\ 232\\ 315\\178\end{bmatrix}
而我们的参数\(\theta\)为:
\begin{bmatrix}\theta_0\\ \theta_1\\ \theta_2\\ ...\\\theta_n\end{bmatrix}
那最终的参数\(\theta\)应该为:
\(\theta = (X^TX)^{-1}X^Ty\)
二、证明
我们知道单位矩阵\(E\)有一个性质:
\( A \times A^{-1} = A^{-1} \times A = E \)
首先:
\( y = X \cdot \theta \)
左右同时乘\(X^T\):
\(X^Ty = X^TX \cdot \theta\)
左右再同时乘\(X^TX^{-1}\):
\((X^TX)^{-1}X^Ty = (X^TX)^{-1}X^TX \cdot \theta\)
而我们已知矩阵的逆乘以矩阵得到单位矩阵\(E\):
\((X^TX)^{-1}X^Ty = \theta\)
三、和梯度下降作比较
Normal Equation有一个好处:不需要进行Feature scaling,而Feature scaling对于梯度下降是必须的

如何来选择使用哪种方法么呢?一般如果特征维度不超过1000的话,Normal Equation还是可选的。
此外,如果\((X^TX)^{-1}\)不可逆怎么办?
1)确保不存在冗余特征,比如

因为\(1m = 3.28feet\),所以\(x_1 = (3.28)^2 * x_2\),我们知道线性代数中出现这种线性相关的情况,其行列式值为0,所以不可逆,我们只需确保不会出现冗余特征即可。
2)特征数量\(n\)过多,而样本数量\(m\)过少:解决方法为删除一部分特征,或者增加样本数量。
四、说明
此文参考:https://blog.csdn.net/artprog/article/details/51172025
Normal Equation的更多相关文章
- coursera机器学习笔记-多元线性回归,normal equation
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- Linear regression with multiple variables(多特征的线型回归)算法实例_梯度下降解法(Gradient DesentMulti)以及正规方程解法(Normal Equation)
,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, , ...
- (三)用Normal Equation拟合Liner Regression模型
继续考虑Liner Regression的问题,把它写成如下的矩阵形式,然后即可得到θ的Normal Equation. Normal Equation: θ=(XTX)-1XTy 当X可逆时,(XT ...
- 【转】Derivation of the Normal Equation for linear regression
I was going through the Coursera "Machine Learning" course, and in the section on multivar ...
- 5种方法推导Normal Equation
引言: Normal Equation 是最基础的最小二乘方法.在Andrew Ng的课程中给出了矩阵推到形式,本文将重点提供几种推导方式以便于全方位帮助Machine Learning用户学习. N ...
- 机器学习入门:Linear Regression与Normal Equation -2017年8月23日22:11:50
本文会讲到: (1)另一种线性回归方法:Normal Equation: (2)Gradient Descent与Normal Equation的优缺点: 前面我们通过Gradient Desce ...
- CS229 3.用Normal Equation拟合Liner Regression模型
继续考虑Liner Regression的问题,把它写成如下的矩阵形式,然后即可得到θ的Normal Equation. Normal Equation: θ=(XTX)-1XTy 当X可逆时,(XT ...
- 正规方程 Normal Equation
正规方程 Normal Equation 前几篇博客介绍了一些梯度下降的有用技巧,特征缩放(详见http://blog.csdn.net/u012328159/article/details/5103 ...
- Normal Equation of Computing Parameters Analytically
Normal Equation Note: [8:00 to 8:44 - The design matrix X (in the bottom right side of the slide) gi ...
随机推荐
- 前端使用Javascrip实现图片轮播
Javascript实现网页图片自动轮播 1.创建一个img标签 设置默认图片,以及图片的高度和宽度,为了大家方便,我将CSS样式和JS语句都写在一个html文件中,演示用的图片来自小明官网:'htt ...
- u盘中毒,启动显示找不到指定模块
u盘中毒,插入电脑,启动显示找不到指定模块,关闭杀毒软件还是这样: 小编经常是在学校教室的电脑上插入U盘再拔出就出现这样的情况,遇到N次了, 所以决定把方法记录下来: (演示使用的是win10系统,其 ...
- Codeforces Round #419 Div. 1
A:暴力枚举第一列加多少次,显然这样能确定一种方案. #include<iostream> #include<cstdio> #include<cmath> #in ...
- SQL Server查询优化器的工作原理
SQL Server的查询优化器是一个基于成本的优化器.它为一个给定的查询分析出很多的候选的查询计划,并且估算每个候选计划的成本,从而选择一个成本最低的计划进行执行.实际上,因为查询优化器不可能对每一 ...
- bzoj 2131 : 免费的馅饼 (树状数组优化dp)
题目链接:https://www.lydsy.com/JudgeOnline/problem.php?id=2131 思路: 题目给出了每个馅饼的下落时间t,和位置p,以及价值v,我们可以得到如下状态 ...
- git同步远程已删除的分支和删除本地多余的分支
使用 git branch -a 可以查看本地分支和远程分支情况 但远程分支(红色部分)删除后,发现本地并没有同步过来. 一. 同步本地的远程分支 查看本地分支和追踪情况: git remote sh ...
- Docker 私有仓库 Harbor registry 安全认证搭建 [Https]
Harbor源码地址:https://github.com/vmware/harborHarbort特性:基于角色控制用户和仓库都是基于项目进行组织的, 而用户基于项目可以拥有不同的权限.基于镜像的复 ...
- 在 CentOS 上编写 init.d service script [转]
背景:之前编写了一些脚本,下载了一些开源软件,想把它们做成系统服务,通过 service your_prog_name start 这样的方式来后台运行,并在开机时自动启动.在了解了 daemon 命 ...
- python3 集合set
set是一种集合的数据类型,使用{}表示 集合中元素是无序的,并且不可重复,集合最重要的作用就是可以去重 set是不可哈希的,set中的元素必须是可哈希的 可以切片,可以迭代 交集.并集.差集.对称差 ...
- 洛谷 P4705 玩游戏 解题报告
P4705 玩游戏 题意:给长为\(n\)的\(\{a_i\}\)和长为\(m\)的\(\{b_i\}\),设 \[ f(x)=\sum_{k\ge 0}\sum_{i=1}^n\sum_{j=1}^ ...