机器学习算法总结(三)——集成学习(Adaboost、RandomForest)
1、集成学习概述
集成学习算法可以说是现在最火爆的机器学习算法,参加过Kaggle比赛的同学应该都领略过集成算法的强大。集成算法本身不是一个单独的机器学习算法,而是通过将基于其他的机器学习算法构建多个学习器并集成到一起。集成算法可以分为同质集成和异质集成,同质集成是值集成算法中的个体学习器都是同一类型的学习器,比如都是决策树;异质集成是集成算法中的个体学习器由不同类型的学习器组成的。(目前比较流行的集成算法都是同质算法,而且基本都是基于决策树或者神经网络的)
集成算法是由多个弱学习器组成的算法,而对于这些弱学习器我们希望每个学习器的具有较好的准确性、而且各个学习器之间又存在较大的差异性,这样的集成算法才会有较好的结果,然而实际上准确性和多样性往往是相互冲突的,这就需要我们去找到较好的临界点来保证集成算法的效果。根据个体学习器的生成方式不同,我们可以将集成算法分成两类:
1)个体学习器之间存在强依赖关系,必须串行化生成的序列化方法,这一类的代表是Boosting(常见的算法有Adaboost、GBDT);
2)个体学习器之间不存在强依赖关系,可以并行化生成每个个体学习器,这一类的代表是Bagging(常见的算法有RandomForest)。
接下来我们来介绍这两种不同的集成算法。
2、集成算法—Boosting
对于分类问题,给定一个训练集,求得一个弱学习器要比求一个强学习器容易得多,Boosting方法就是从弱学习器出发,反复学习而得到一系列弱学习器,然后组合这些弱学习器,构成一个强学习器。Boosting算法的工作机制可以概括为:先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的样本受到更多的关注(通过施加权重来控制),然后基于调整后的样本集训练下一个基学习器,如此反复进行,直到学得的基学习器的个数达到设定的个数T(基学习器的个数是我们需要调试的超参,通过交叉验证来选择),最终对这T个基学习器根据他们的预测表现来施加不同的权重并结合在一起构成我们的强学习器。
Boosting算法最具代表的是Adaboost算法,关于Adaboost算法的具体流程如下:
1)初始化训练集的权值分布,每个样本的权值一样
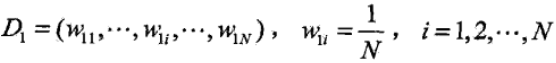
2)对于第m个基学习器,使用权值分布Dm的训练数据集训练模型,得到基学习器Gm
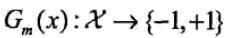
计算Gm(x)在训练数据集上的分类误差率,在这里我们可以看到分类误差率是和样本权重有关的,是分类错误的样本权重之和,这样就使得下一次分类时在最小化损失函数时,会更加关注本次分类错误的样本
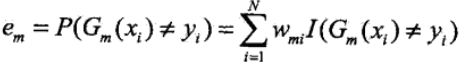
计算Gm(x)的系数αm,该系数最后会用来作为基学习器的权重,权重系数是随着分类误差率较小而增大的,也就是分类准确性越高的模型,权重也越大
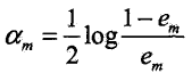
更新训练数据集的权值分布,求得Dm+1
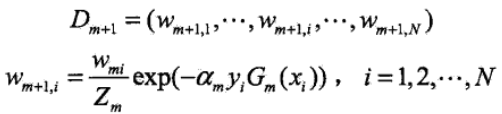
其中Zm是规范场因子,其表达式为
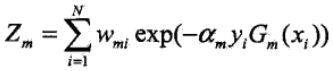
3)构建基学习器的线性组合
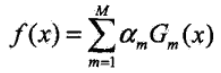
则最终的学习器模型如下

3、集成算法—Bagging
Bagging算法的核心是通过在原始数据集上进行采样,获得多份不同的样本集,用这些样本集来训练基学习器。第一节中我们提到基学习器需要平衡准确性和多样性,因此我们所采集的样本需要满足这两点,Bagging采用自助采样法(Bootstrap)进行采样,自助采样法的规则如下:给定包含m的样本的数据集,我们先随机从中抽取一个样本出来,再将该样本放回,以便在下一次仍有机会抽到,这样经过m次随机采样,我们就可以获得m的样本的样本集(这样的样本集中约含有原始数据集中的63.2%的样本),按照这种方式抽取出T份样本集出来,用这T份样本集训练出T个基学习器,在预测时根据这T个基学习器预测的结果,通常采用投票法来决定最终的输出。Bagging与Adaboost只适用于二分类问题不同,可以不经修改的用于多分类问题。
Bagging算法中最常见的算法就是RandomForest(随机森林)算法,RandomForest是Bagging的一种变体,在Bagging的基础上引进了属性干扰这一策略,主要是用来提高基学习器之间的多样性,具体规则:传统的决策树是在整个属性集上选择最优的属性来划分样本集合,而RandomForest先在属性集上随机选取k个属性组成一个子属性集,然后在这个子属性集上选择最优的属性来划分样本集合,这里的参数k控制了随机性的引入程度,一般情况下推荐k=log2d,d为属性集的大小。
Bagging算法的作用主要是减小模型的方差,我们来看看bagging和方差具体有什么样的关系。假设有$n$个随机变量,方差记为${\sigma}^2$,两两变量之间为$\epsilon$,则$n$个随机变量的均值方差为:
${\epsilon} * {\sigma}^2 + (1 - {\epsilon}) * {\sigma}^2 / n$
因此当两两变量之间的相关性为0时,$n$个随机变量的均值方差则为:${\sigma}^2 / n$。
因此对于$n$个模型,若是模型之间相互独立,则方差会降低 $n$倍,但实际中模型之间不可能相互独立,因此我们只能尽量增加模型的多样性,当前也得平衡基学习器的准确率。
4、集成学习的输出方式
最终的强学习器的输出结果是和每个弱学习器相关的,但是对于这些弱学习器的输出值,我们以什么样的方式整合输出呢?
1)平均法
对于数值类的回归问题,通常使用的方式是平均法,也即是对每个弱学习器的输出加和取平均值,将该平均值作为最后的输出,当然有的时候会给每个学习器带上权重,此时就是加权平均获得最终的输出值。
2)投票法
对于分类问题的输出方式常采用投票法,最简单的投票方式就是取弱学习器中预测最多的那一类作为我们的输出值,其次严格一点的投票方式是不但要输出预测最多的那一类的值,且该类的值要占到预测的值的一半以上,最后还有对每个弱学习器赋予权重,对于最终的投票计算会乘以对应的权重(比如选举时班长的一票顶五票,而普通学生一票就只是一票)。
3)学习法
对于平均法和投票法相对比较简单,有时候在预测时可能存在误差,于是就衍生出了学习法,例如stacking,当使用stacking时是将所有弱学习器的输出作为输入,在这基础上再建立一个模型,让机器自己去学习输出方式,有时候我们会训练多个强学习器,比如将训练一个随机森林的学习器,再训练一个Adaboost的学习器,然后将这两个学习器的弱学习器的输出作为输入(这样我们就有两条输入数据),训练一个用于最终预测的学习器来输出结果。
5、Adaboost和RandomForest对比
Adaboost算法常用的弱学习器是决策树和神经网络(理论上可以用任何学习器作为基学习器)。对于决策树,Adaboost分类用了CART分类树,Adaboost回归用了CART回归树。Adaboost和Boosting算法一样,重点关注模型的偏差,迭代的过程中是以降低偏差为目的,一般偏差会较小,但这并不意味这Adaboost的方差很大,很容易过拟合,实际上是可以通过调整模型的复杂度来避免过拟合的,例如决策树为基学习器时,可以调节树深,或者是叶节点中样本的个数等来实现。Adaboost只能做二分类问题,最终的输出是用sign函数决定的。当然对算法上做一些修改也是可以用于回归问题的,但是对于多分类问题就比较复杂。
Adaboost的主要优点:
1)Adaboost作为分类器时,分类精度很高
2)在Adaboost的框架下,可以使用各种分类回归模型来构建基学习器
3)作为简单的二分类问题,构建简单,结果可理解
4)不容易发生过拟合
Adaboost的主要缺点:
1)对异常样本敏感,异常样本在迭代中可能会获得较高的权重,影响最终的强学习其的预测准确性
2)Adaboost只能做二分类问题,要做多分类问需要做其他的变通
RandomForest算法常用的弱学习器也是决策树和神经网络,对于决策树,在随机森林中也是使用CART分类回归树来处理分类回归问题,通常采用投票法和平均法来决定最后的输出,对于分类问题采用投票法也决定了随机森林能无修改的应用于多分类问题,随机森林和Bagging算法一样,重点关注降低模型的方差,泛化能力强,但是有时候也会出现较大的训练误差,这可以通过加大模型的复杂度来解决,另外在随机森林中是采用随机选择子特征集的,子特征集的个数也会影响要模型的方差和偏差,一般认为子特征集越大,模型的偏差会越小。因为随机森林的模型简单,效果好,因此也产生了很多变种算法,这些变种算法可以用来处理分类回归问题,也可以处理特征转换,异常点检测等。
例如extra trees就是随机森林的一种推广形式,它改变了两个地方,一是不再采取自助采样法去随机抽取样本,而是采用原始集作为训练样本;二是直接随机选择特征(相当于子特征集只有一个元素)。extra trees的方差比随机森林更小,因此泛化能力更强,但是偏差也更大。
随机森林的主要优点:
1)训练可以高度并行化,因此算法的速度要选快于Adaboost。
2)由于随机子特征集,因此在高维特征下,算法仍具有较好的效率
3)在训练后可以给出各个特征对输出的重要性
4)由于随机采样,训练出的模型的方差小,泛化能力强
5)算法实现起来比Boosting更简单
6)对部分特征缺失不敏感
随机森林的主要缺点:
1)在某些噪声比较大的样本集上,RF模型容易陷入过拟合
2)取值比较多的特征容易影响随机森林的决策,影响模型的拟合效果
最后关于Bagging重点降低方差,Boosting重点降低偏差来说一说。首先对于Bagging来说,利用对样本进行重采样,然后用类似的模型来训练基学习器,由于子样本集的相似性和使用的模型相同,因此最终的基学习器有近似相等的方差和偏差,对于类似的偏差是无法通过模型平均来降低的,而对于方差在模型平均时会弱化每个基学习器的异常值,强化每个基学习器的共通值,因此会降低模型的方差。对于Boosting,其算法的核心就是关注偏差,在算法优化过程中每次都最小化弱学习器,这本身就是一种以降低偏差为目的的优化方式,因此会降低模型的偏差,当然Boosting也会降低模型的方差,只是没有偏差明显。
机器学习算法总结(三)——集成学习(Adaboost、RandomForest)的更多相关文章
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 集成学习AdaBoost算法——学习笔记
集成学习 个体学习器1 个体学习器2 个体学习器3 ——> 结合模块 ——>输出(更好的) ... 个体学习器n 通常,类似求平均值,比最差的能好一些,但是会比最好的差. 集成可能提 ...
- 集成学习-Adaboost
Adaboost 中文名叫自适应提升算法,是一种boosting算法. boosting算法的基本思想 对于一个复杂任务来说,单个专家的决策过于片面,需要集合多个专家的决策得到最终的决策,通俗讲就是三 ...
- 《机器学习Python实现_10_10_集成学习_xgboost_原理介绍及回归树的简单实现》
一.简介 xgboost在集成学习中占有重要的一席之位,通常在各大竞赛中作为杀器使用,同时它在工业落地上也很方便,目前针对大数据领域也有各种分布式实现版本,比如xgboost4j-spark,xgbo ...
- 《机器学习Python实现_10_02_集成学习_boosting_adaboost分类器实现》
一.简介 adaboost是一种boosting方法,它的要点包括如下两方面: 1.模型生成 每一个基分类器会基于上一轮分类器在训练集上的表现,对样本做权重调整,使得错分样本的权重增加,正确分类的样本 ...
- 集成学习-Adaboost 进阶
adaboost 的思想很简单,算法流程也很简单,但它背后有完整的理论支撑,也有很多扩展. 权重更新 在算法描述中,权重如是更新 其中 wm,i 是m轮样本i的权重,αm是错误率,Øm是第m个基学习器 ...
- Day3 《机器学习》第三章学习笔记
这一章也是本书基本理论的一章,我对这章后面有些公式看的比较模糊,这一会章涉及线性代数和概率论基础知识,讲了几种经典的线性模型,回归,分类(二分类和多分类)任务. 3.1 基本形式 给定由d个属性描述的 ...
- 《机器学习Python实现_10_06_集成学习_boosting_gbdt分类实现》
一.利用回归树实现分类 分类也可以用回归树来做,简单说来就是训练与类别数相同的几组回归树,每一组代表一个类别,然后对所有组的输出进行softmax操作将其转换为概率分布,然后再通过交叉熵或者KL一类的 ...
随机推荐
- Field 'id' doesn't have a default value错误解决方法
Field 'id' doesn't have a default value 错误提示. 主键类型获取方式为"native"由数据库生成指定. 检查发现数据库中已存在Employ ...
- Root(hdu5777+扩展欧几里得+原根)2015 Multi-University Training Contest 7
Root Time Limit: 30000/15000 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Others)Total Su ...
- LINUX sed grep awk之间比较整理
正则表达式基础 在最简单的情况下,一个正则表达式看上去就是一个普通的查找串.例如,正则表达式"testing"中没有包含任何元字符,,它可以匹配"testing" ...
- Netty 系列三(ByteBuf).
一.概述和原理 网络数据传输的基本单位总是字节,Netty 提供了 ByteBuf 作为它的字节容器,既解决了 JDK API 的局限性,又为网络应用程序提供了更好的 API,ByteBuf 的优点: ...
- blfs(systemd版本)学习笔记-为桌面环境构建xorg服务
我的邮箱地址:zytrenren@163.com欢迎大家交流学习纠错! lfs准备使用桌面环境,首先需要构建xorg服务 xorg服务项目地址:http://www.linuxfromscratch. ...
- 小tips:JS之break,continue和return这三个语句的用法
break语句 break语句会使运行的程序立刻退出包含在最内层的循环或者退出一个switch语句.由于它是用来退出循环或者switch语句,所以只有当它出现在这些语句时,这种形式的break语句才是 ...
- BZOJ4407: 于神之怒加强版(莫比乌斯反演 线性筛)
Description 给下N,M,K.求 感觉好迷茫啊,很多变换看的一脸懵逼却又不知道去哪里学.一道题做一上午也是没谁了,, 首先按照套路反演化到最后应该是这个式子 $$ans = \sum_{d ...
- Python入门基础之变量和数据类型
在Python中,能够直接处理的数据类型有以下几种: 一.整数 Python可以处理任意大小的整数,当然包括负整数,在Python程序中,整数的表示方法和数学上的写法一模一样,例如:1,100,-80 ...
- adb连接安卓模拟器
为了在电脑上玩手机游戏,国内推出了很多安卓模拟器,mumu.夜神.itools.海马等等.我们也可以用他们来做安卓开发,相对genymotion或者android studio自带的模拟器而言,国产模 ...
- The concurrent snapshot for publication 'xxx' is not available because it has not been fully generated or the Log Reader Agent is not running to activate it
在两台测试服务器部署了复制(发布订阅)后,发现订阅的表一直没有同步过来.重新生成过snapshot ,也重新初始化过订阅,都不能同步数据,后面检查Distributor To Subscriber H ...