图像超分辨-DBPN
本文译自2018CVPR DeepBack-Projection Networks For Super-Resolution
代码: github
特点:不同于feedback net,引入back projection net
结果:state of the art,尤其在大尺度上面,例如x8倍
摘要:
近来提出的前馈网络结构学习低分辨输入的表征和由SR(low-resoluton)至HR(high-resolution)的非线性映射。然而这种方法并没有完整处理SR和HR图像的相互依赖。我们提出 Deep Back-Projection Networks(DBPN),利用一种上-下采样层,提供一种错误反馈机制在每个阶段。我们构建了相互依赖的上-下采样模块,每个模块代表了不同的图像退化和高分辨组件。我们展示了这种想法使得在上下采样阶段的特征连接起来,提升SR结果。取得了当下最好结果对于大的尺度因子例如8倍。
1. Introduction
单图像SR是一个病态逆问题其目的是从LR图像中恢复HR。当下构建HR的典型的方法是学一种LR-HR的映射,由深度网络实现。这些网络计算一系列的SR的特征图,以一个或更多的上采样层为结尾来增加分辨率并最终构建HR图像。对比与单纯的前馈方法,人类视觉利用一种反馈链接来指导某些任务。或许由于缺少这种反馈,当下的仅含前馈的SR网络很难表征LR至HR的关系,尤其对于大尺度因子。

在另一方面,反馈链接在早期的一个SR算法中高效利用,即 iterative back-projection方法。它迭代计算重构误差然后利用他来调整HR图像的强度。尽管提高了图像质量,但是结果仍然受到ringing effect and chessboard effect。此外,该方法对于参数选择敏感,例如迭代次数和模糊算子blur operator,导致结果多变。
受论文Improving resolution by image registration影响,我们构建了一个端到端的网络,基于迭代的上-下采样: Deep Back-Projection Networks (DBPN)。我们的方法成功展示于大尺度因子,如图1。我们的贡献如下:
(1) Error feedback错误反馈 我们提出了一个迭代的错误反馈机制,计算up-and down-projection errors上下投影误差来重构以获得更好结果。这里投影误差用来约束前几层的特征,细节在Section3。
(2) Mutually connected up- and down-sampling stages相互连接的上-下采样阶段 前馈结构可视为一种映射,仅仅将输入的代表性特征到输出空间。这种方法对于LR到HRT的映射是不成功的,尤其是大尺度因子,这是因为LR空间的特征局限性。因此我们的网络不仅利用上采样层生成多样的HR特征并且利用下采样层将其映射到LR空间。这种连接在下图2有show。这种交替式的上(蓝色box)下(金色box)采样过程表征了LR和HR图像的相互关系。
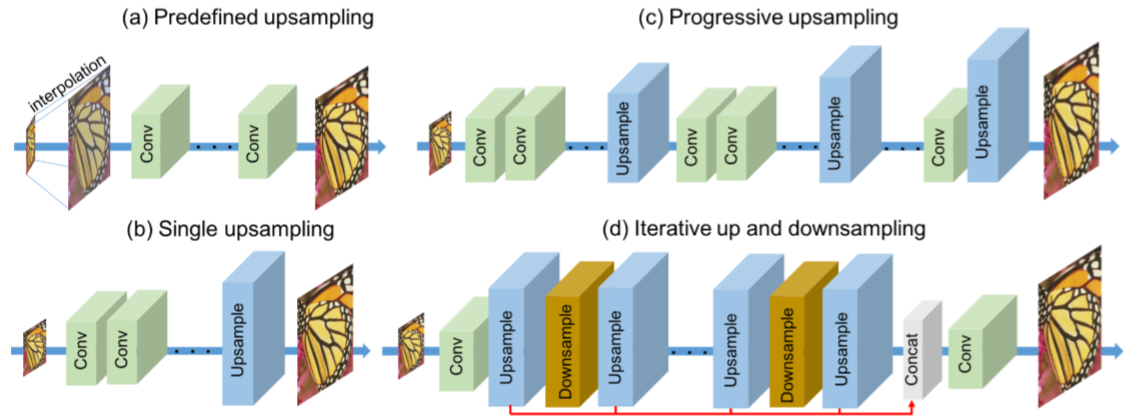
Figure 2
图2. 深度SR网络的对比。(a) Predefined upsampling预定义上采样 (e.g., SRCNN [6] , VDSR [22], DRRN [43])普遍利用传统的插值方法,例如双三次插值 Bicubic来在输入网络之前upscale LR输入图像。 (b)Single upsampling单次上采样 (e.g., FSRCNN [7], ESPCN [38])传播LR特征,然后在最后一步构建SR图像。 (c) Progressive upsampling渐进上采样(LapSRN)利用拉普拉斯金字塔网络逐渐预测SR图像。 (d)我们提出的迭代上下采样DBPN网络在不同阶段利用相互连接的上下采样模块在不同深度获得HR的特征。
(3) Deep concatenation深度级联 我们的网络表示了不同类型的图像退化和HR组件。这种能力使得网络可以利用HR特征图的深度级联来重构HR图像。不像其他网络,我们的重构直接利用不同类型的LR-HR特征,无需在采样层中传播,上图2中红色箭头。
(4) Improvement with dense connection稠密链接实现提升 我们在每个上-下采样阶段利用稠密链接(论文DenseNet:Densely Connected Convolutional Networks)来鼓励特征重用以提升网络精度。
2. Related Work
2.1 Image super-resolution using deep networks
如图2, 深度SR网络主要划分为4种类型。
(a) Predefined upsampling 主要利用插值作为上采样描述子来产生中等分辨率(MR)的图像。这种策略首先有SRCNN提出,利用简单的卷积网络学习一种MR至HR的非线性映射关系。随后又有利用残差学习residual learning和递归层recursive layers的网络结构。然而由于MR的引入,这种方法可能产生新的噪声。
(b) Single upsampling 提供见到有效的方法来增加空间分辨率。这种方法主要有FSRCNN和ESPCN。这些方法被证实有效提升空间分辨率且可替代预定义的描述子。然而由于网络容量限制无法学习到完整的映射。NTIRE2007的冠军算法EDSR就属于这种类型。然而它的每一层需要大量的滤波器,同时需要大量的时间,大约8天!这些问题催使可有效保留HR组件的轻量级网络的诞生。
(c) Progressive upsampling 近来由LapSRN提出。它利用不容尺度在一个前馈网络里渐进构建多张SR图像。简言之,这个网络是单个上采样网络的堆叠,仅依赖于受限的LR特征。基于此,LapSRN甚至优于我们浅层网络中大尺度因子(eg:8倍)的实验结果。
(d) Iterative up and downsampling 由本文提出。我们关注于提升在不同深度对SR特征的采样率和分布式任务来计算不同阶段的重构误差。这个方案使得网络可以在生成更深特征的同时通过学习多找种上下采样描述子( up- and down-sampling operators)来保留HR组件。
2.2 Feedback networks
这种方法不是学习一种input-to-output空间的映射in one step,而是多步实现预测,使得网络可以拥有自纠正(self-correcting)的过程。前馈过程在许多计算任务中已经实现。
一些前馈网络的例子:In the context of human pose estimation, Carreira et al. [3] proposed an iterative error feedback by iteratively estimating and applying a correction to the current estimation. PredNet [32] is an unsupervised recurrent network to predictively code the future frames by recursively feeding the predictions back into the model. For image segmentation,Lietal.[29]learnimplicitshapepriorsandusethemto improve the prediction. However, to our knowledge, feedback procedures have not been implemented to SR.
2.3 .Adversarial training
例如生成对抗网络利用对抗训练应用于多种重建问题。对于SR任务,Johnson介绍了一种基于高级预训练提取特征的感知损失。SRGAN方法可视作single upsampling方法,它提出自然图像流形可以生成照片般图像通过约束一个基于欧式距离(特征分别提取自VGG19和SRResNet)的损失函数。
我们的网络可以由对抗损失扩展为生成网络。然鹅我们仅仅利用MSE目标函数优化网络。因此我们可以比较DBPN和同样用MSE优化的SRResNet,而不是利用对抗损失优化的DBPN。
2.4 Back-projection
Back-projection是作为一种高效迭代过程来优化重构误差。最初Back-projection作为多LR输入图像设计,然而仅仅输入一张LR图像,更新过程可通过利用多个上采样描述子来对LR图像采样,并迭代的计算重构误差。已有证明Back-projection可以提高SR图像的质量。有人提出利用迭代projection process来refine 高频文本细节,但是能实现最优解的初始化未知。之前的工作大多需要连续的、不可学的预定义参数。例如模糊operator和迭代次数。
为扩展这个算法,我们实现了一种可训练的端到端的结构,更关注于利用相互连接的上下采样模块来学习LR到HR的非线性关系。HR和LR图像的关系由创建可迭代的上下-投影单元来构建。上投影up-projection生成HR特征。下投影down-projection将其投影到LR空间,图2d所示。这个方案使得网络可以通过学习多种上下采样operator来保留HR组件,并生成深度特征学习大量的SR和HR特征。
3. Deep Back-Projection Networks
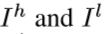 分别为HR和LR图像。大小分别为(M ×N)和
分别为HR和LR图像。大小分别为(M ×N)和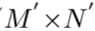 。
。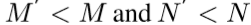 。DBPN结构的主要组成就是反射单元projection unit,作为训练SR系统的一部分,映射LR特征至HR特征(up-projection),或者映射HR特征至LR特征(down-projection)。
。DBPN结构的主要组成就是反射单元projection unit,作为训练SR系统的一部分,映射LR特征至HR特征(up-projection),或者映射HR特征至LR特征(down-projection)。
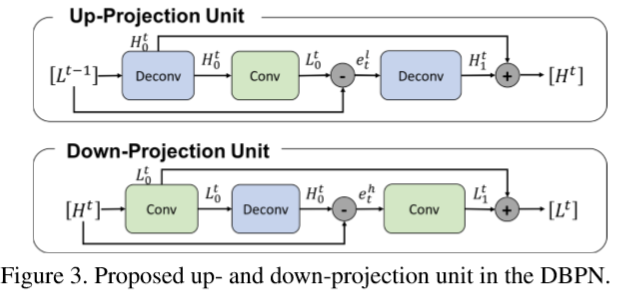
3.1 Projection units
up-projection 单元定义如下:

上面*代表空间卷积操作。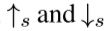 分别为尺度因子为s的上-下采样operator,
分别为尺度因子为s的上-下采样operator, 为阶段 t 的(反)卷积层。
为阶段 t 的(反)卷积层。
这个projection单元令之前计算的LR特征图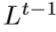 作为输入,将其映射至HR特征图
作为输入,将其映射至HR特征图 ,然后试着映射回LR特征图
,然后试着映射回LR特征图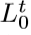 ,(这体现了back-project)。那么LR特征图与重构的之间的残差(差异)
,(这体现了back-project)。那么LR特征图与重构的之间的残差(差异) 又被再次映射到HR。该单元最终的输出为HR的特征图
又被再次映射到HR。该单元最终的输出为HR的特征图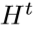 ,是两个HR特征图的和。
,是两个HR特征图的和。
down-projection 单元定义很类似地,只不过任务为映射HR的特征图至LR的特征图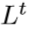 :
:
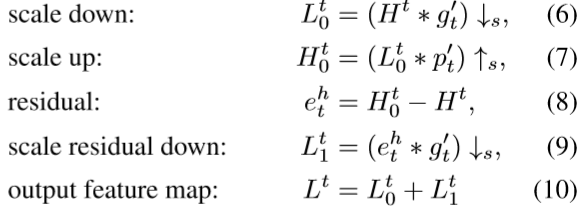
我们交替H、L组织一系列反射单元projection unit 。这些单元可理解为自纠正过程,即将反射误差喂给采样层,通过反向传递反射误差来交替优化。
反射层利用大尺寸滤波器例如8*8和12*12。在其他网络中,大尺寸滤波器是应避免的因为降低了收敛速度,可能产生次优解。然而,迭代利用我们的反射单元使得网络抑制限制并在浅层网络中使得大尺度因子( large scaling factor)表现良好。
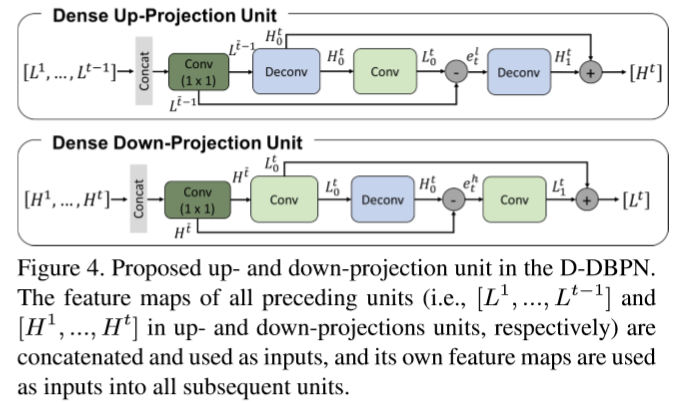
3.2 Dense projection units
DenseNet已经证明了其缓解了梯度消失问题,产生更好特征,鼓励特征重用。于此,我们通过在反射单元projection units中引入dense connections来提升DBPN,称Dense DBPN(D-DBPN)。
不像原版DenseNets,我们避免使用dropout和batch norm,这些不适于SR。因为它们改变了特征的灵活度(remove the range flexibility of the features)。相反我们在进入反射单元之前,利用1*1卷积用作特征池化和维度缩减。
在D-DBPN中,每个单元的输入是与之前单元输出的连结。令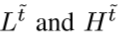 为dense 上-下反射单元的输入。它们由用来合并之前所有每个单元输出(图4)的
为dense 上-下反射单元的输入。它们由用来合并之前所有每个单元输出(图4)的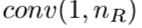 生成。这个提升使得我们可以有效生成特征图,在实验结果有show。
生成。这个提升使得我们可以有效生成特征图,在实验结果有show。
3.3 Network architecture
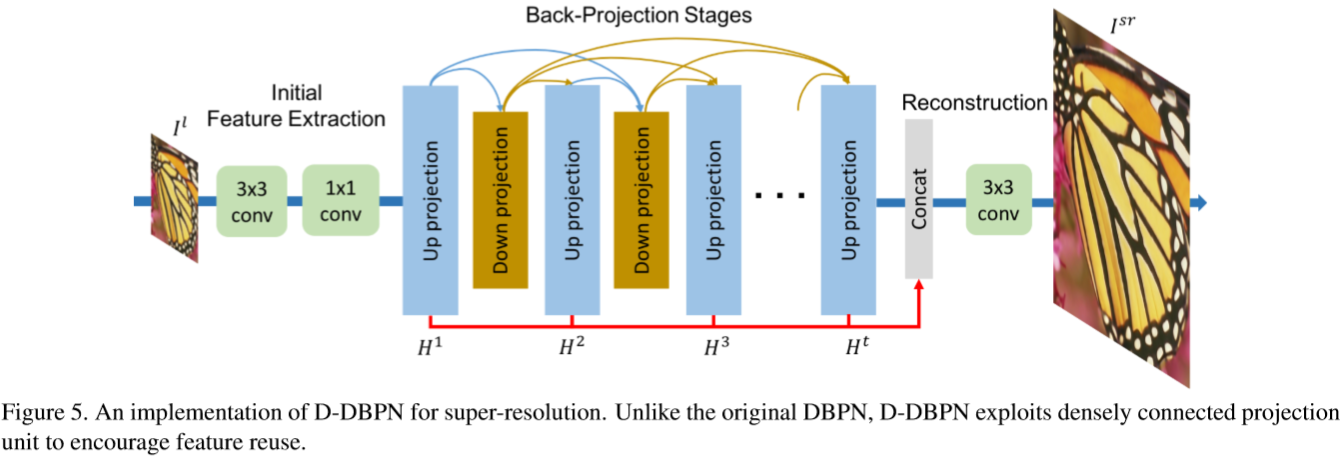
D-DBPN结构如图5。可分为三部分:特征提取 initial feature extraction、反射projection、重构reconstruction。令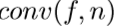 表示卷积层,f表示滤波器尺寸,n为滤波器数量。
表示卷积层,f表示滤波器尺寸,n为滤波器数量。
1. Initial feature extraction 我们利用 从输入构建最初的LR特征图
从输入构建最初的LR特征图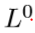 。然后
。然后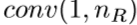 用来实现进入反射单元之前的从
用来实现进入反射单元之前的从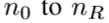 的维度缩减。
的维度缩减。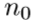 是最初LR特征提取阶段滤波器使用的数量。
是最初LR特征提取阶段滤波器使用的数量。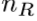 是在每个反射单元用到的滤波器数量。
是在每个反射单元用到的滤波器数量。
2. Back-projection stages 随后的初始特征提取是一系列的反射单元。交替LR和HR特征图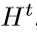 和
和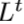 的构建,每个单元可以接触到所有之前单元的输出。
的构建,每个单元可以接触到所有之前单元的输出。
3. Reconstruction 最后,目标HR图像这样重构: ,
,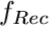 使用
使用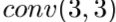 作为重构。
作为重构。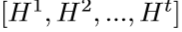 为每个反射单元产生的特征图的连结。
为每个反射单元产生的特征图的连结。
由于这些block的定义,我们的网络结构是模块化的。可以容易的定义和训练不同的阶段,控制深度。对于含有T个阶段的网络,我们有最初的2层提取过程,T个up-projection单元和T-1个 down-projection单元,每个都有3层,之后是重构(大于等于1层)。然而对于dense网络,我们加入 在每个反射单元,除了最初的三个单元。
在每个反射单元,除了最初的三个单元。
4. Experimental Results
4.1.Implementation and training details
提出的网络中,根据尺度因子,反射单元中的滤波器尺寸不同。对于2x放大,我们利用6x6卷积层,步长为2,padding为2。对于4x放大利用8x8卷积层,步长为4,padding为2。最后,对于8x8放大,利用12x12卷积层,步长为8,padding为2。
我们基于何凯明的那篇 Delving deep into rectifiers: Surpassing human-level performance on imagenet classification来初始化。具体计算看论文。所有(反)卷积层后为参数化的整流线性单元(PReLUs)。
我们利用数据集DIV2K、Flickr和ImageNet来训练所有网络。无数据增强。为产生LR图像,在特定尺度因子上利用双三线性差值来downscale HR图像。32x32大小barch为20的LR图像,HR图像尺寸取决于尺度因子。学习率1e-4对于所有层,每迭代5x105 iter学习率/10,总共训练106 iter。对于优化利用Adam,动量因子0.9,权重衰减1e-4。所有实验由caffe搭建、Matlab R2017a、NVIDIA TITAN XGPUs。
4.2. Model analysis
Depth analysis 主要是根据原始DBPN构建了多个网络 S (T = 2), M (T = 4), and L (T = 6) 。效果还是看图吧:
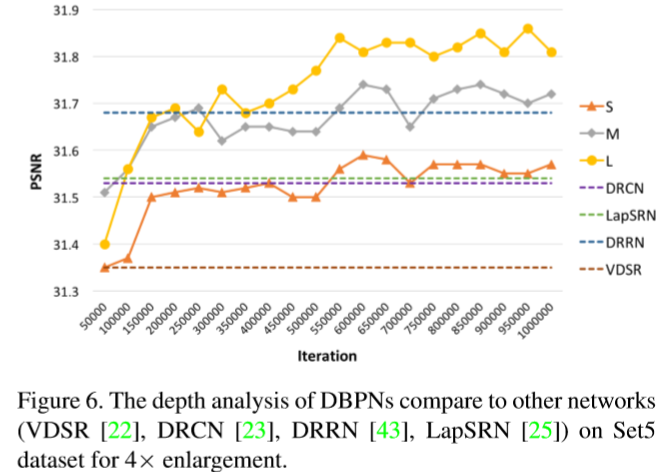
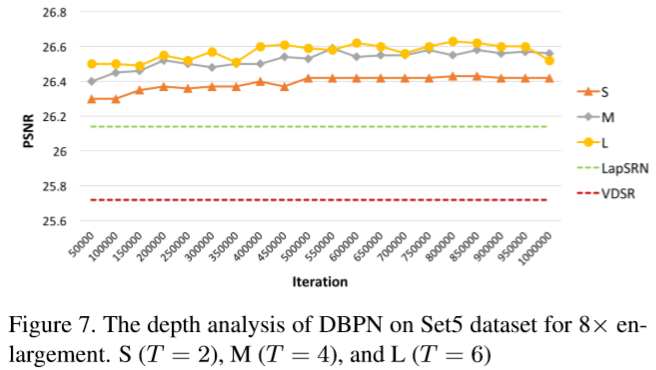
Number of parameters 性能和模型参数数目的折衷。SS network 是 S network (T = 2)的轻量版。
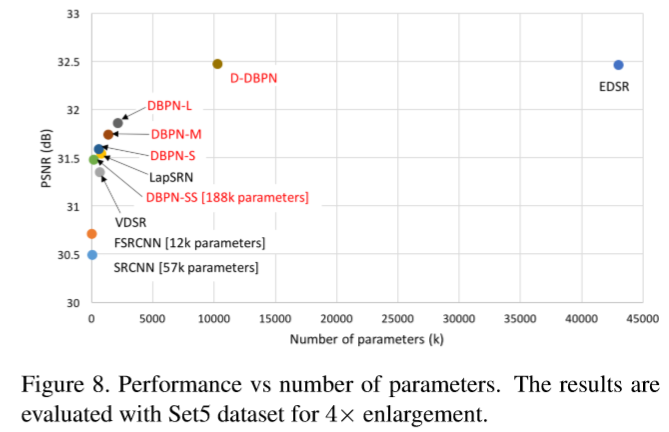

Deep concatenation 每个反射单元通过构建HR组件的不同特征来贡献重构步骤。

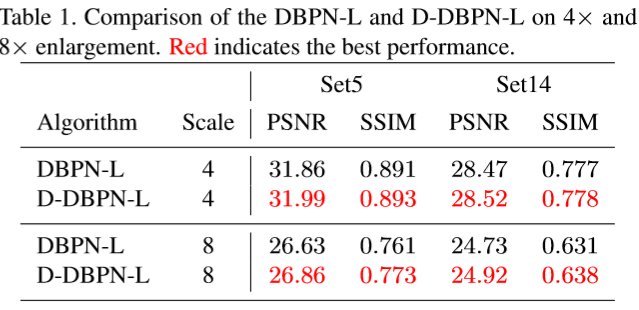
Dense connection 实现 D-DBPN-L作为L网络的稠密连接来展示dense connection如何来提高网络性能。
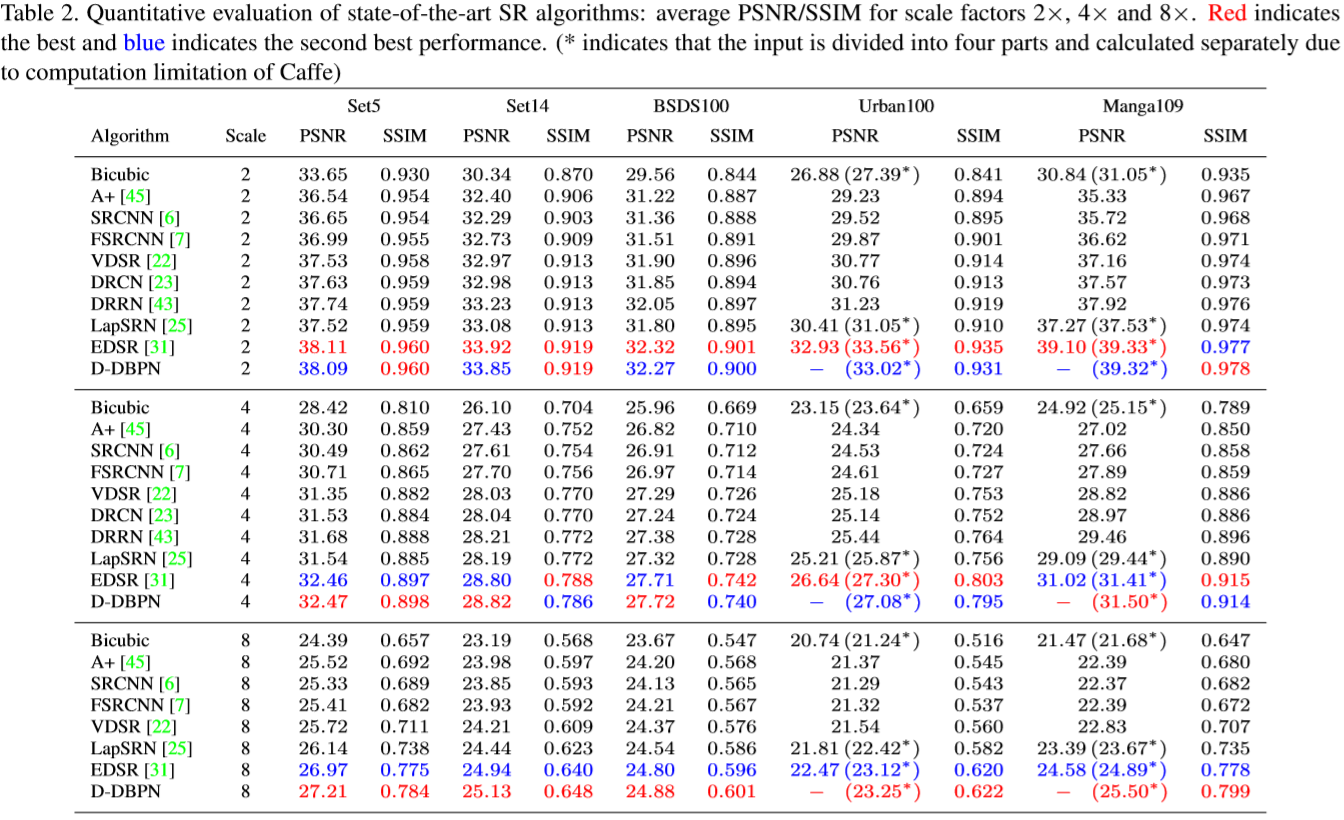
4.3 Comparison with the-state-of-the-arts
和当下优秀的结构 A+ [45], SRCNN [6], FSRCNN [7], VDSR [22], DRCN [23], DRRN [43], LapSRN [25], and EDSR [31]作了对比。5组测试数据:Set5 [2], Set14 [50], BSDS100 [1], Urban100 [16] and Manga109 [33]。


5. Conclusion
我们提出Deep Back-Projection Networks对于单图像超分辨(Single Image Super-resolution, SISR)。和之前的前馈预测SR图像的方法不同,我们提出的网络关注直接利用多个上-下采样阶段增加SR特征,反馈网络不同深度的错误预测来修改采样结果,然后积累每个上采样阶段的自纠正(self-correct)特征来创建SR图像。我们利用上-下scaling 步骤的错误反馈来使网络达到更优。结果展示了与sate-of-the-art方法的有效性对比。此外我们提出的网络在大尺度因子例如8x放大的实验中优于state-of-the-art。
注:首次接触SR,简单翻译,有误请指出。
图像超分辨-DBPN的更多相关文章
- 深度原理与框架-图像超分辨重构-tensorlayer
图像超分辨重构的原理,输入一张像素点少,像素较低的图像, 输出一张像素点多,像素较高的图像 而在作者的文章中,作者使用downsample_up, 使用imresize(img, []) 将图像的像素 ...
- 图像超分辨-IDN
本文译自2018CVPR Fast and Accurate Single Image Super-Resolution via Information Distillation Network 代码 ...
- paper 119:[转]图像处理中不适定问题-图像建模与反问题处理
图像处理中不适定问题 作者:肖亮博士 发布时间:09-10-25 图像处理中不适定问题(ill posed problem)或称为反问题(inverse Problem)的研究从20世纪末成为国际上的 ...
- 基于稀疏表示的图像超分辨率《Image Super-Resolution Via Sparse Representation》
由于最近正在做图像超分辨重建方面的研究,有幸看到了杨建超老师和马毅老师等大牛于2010年发表的一篇关于图像超分辨率的经典论文<ImageSuper-Resolution Via Sparse R ...
- 论文阅读之:Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network 2016.10.23 摘要: ...
- (cvpr2019 ) Better Version of SRMD
SRMD的内容上篇,已经介绍,本文主要介绍SRMD的升级版,解决SRMD的诸多问题, 并进行模拟实验. 进行双三次差值(bicubic)===>对应matlab imresize() %% re ...
- [ZZ] Valse 2017 | 生成对抗网络(GAN)研究年度进展评述
Valse 2017 | 生成对抗网络(GAN)研究年度进展评述 https://www.leiphone.com/news/201704/fcG0rTSZWqgI31eY.html?viewType ...
- TensorFlow精选Github开源项目
转载于:http://www.matools.com/blog/1801988 TensorFlow源码 https://github.com/tensorflow/tensorflow 基于Tens ...
- SRCNN之后的深度学习超分辨率
SRCNN开山之作 IDN 信息蒸馏网络information distillation network(IDN) Fast and Accurate Single Image Super-Resol ...
随机推荐
- ojdbc6下载地址
https://www.oracle.com/technetwork/database/enterprise-edition/jdbc-112010-090769.html oracle驱动先去官网下 ...
- 本地服务器上挂载A目录到B目录
原因: 由于某个分区满了,切磁盘无法扩大分区空间,但是项目依赖该分区,需要继续像该分区存储文件,此时其他分区还有很大的空间,使用挂载的方式,在有空间的分区创建新目录,将新目录挂载到源目录下即可. 执行 ...
- NGUI使用图集的精灵换图片
创建了一个sprite,选择的是某一个图集下的sprite,现在我想点击它来换图片.前提是你的sprite已经加了UIButton 代码如下: public void OnClick() { if ( ...
- Xstart Insatll And Usage
不进入 Linux 桌面环境,又需要运行一些图形化的软件,比如 Oracle 数据库的安装等 安装 Windows 上 Xstart 安装:https://www.cnblogs.com/jhxxb/ ...
- Oracle 数据库分页查询与排序分页查询
一.分页查询 原始查询语句 SELECT * FROM NASLE_WFSHH 修改为分页查询语句,加上 ROWNUM 列.此处为查询第 1 页,每页 9 条数据 SELECT * FROM ( SE ...
- 16、JDBC-DBUtils封装
使用DBUtils写个通用CURD小工具 依赖配置 pom.xml <?xml version="1.0" encoding="UTF-8"?> & ...
- vue实现简单的全选、反选、不选
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- spring注解第04课 @Import
1.beans package com.atguigu.bean; public class Blue { public Blue(){ System.out.println("blue.. ...
- iOS快捷代码块
//数据请求 /**<#封装数据请求(只适用本人)#>*/ NSString * requestUrl = [NSString stringWithFormat:@"%@%@&q ...
- loj 10050 连续子段最大异或和
#include<bits/stdc++.h> #define rep(i,x,y) for(register int i=x;i<=y;i++) using namespace s ...