face recognition[MobileFaceNet]
本文来自《MobileFaceNets: Efficient CNNs for Accurate Real-Time Face Verification on Mobile Devices》,时间线为2018年4月。是北京交通大学和握奇数据公司的作品。
人脸发展至今,效果相比传统方法有了很大的提升,然而受限于机器资源和实时性部署等需求,需要考虑诸如MobileNet等网络的使用。
0 引言
在越来越多的手机和嵌入式设备上,人脸验证变成越来越流行的一个认证技术。然而,现在高准确度的人脸验证模型都是建立在又深又宽的CNN模型上的,并通过各种loss函数去提供有监督训练。而大CNN模型需要较多计算力,这对于移动和嵌入式设备来说,是无法满足的。几个高效的CNN架构,如MobilenetV1,ShuffleNet,MobileNetV2近些年来作为解决移动设备的视觉识别任务。一种简单的方式就是不修改这些CNN结构,直接延用到人脸验证上,而这对于现今的人脸识别榜单上的结果来说,简直不能看。
本文作者提出的模型参数都不到1百万个,且在相同的实验环境下,MobileFaceNets效果是MobileNetV2的2倍多。通过在提炼过的MS-Celeb-1M数据集上采样ArcFace 的loss从头训练,MobileFaceNets模型size只有4MB,且在LFW上获得了99.55%的准确度,在MegaFace挑战1的TAR@FAR10-6上获得了92.59%的准确度,这就可以与那些大CNN模型相比较了。注意到现在的许多方法如剪枝[37],low-bit 量化[29],和知识蒸馏[16]都可以用来提升MobileFaceNets的效率。
1 本文主要工作
本部分介绍了本文提出的极端高效的CNN模型,以加速移动设备上实时人脸验证,这克服了人脸验证上常见mobile net的不足。为了让结果可复现,采用了ArcFace loss去训练整个人脸验证模型,涉及的部分参数延用参考文献[5]。
1.1 常见移动设备上网络在人脸验证上的不足
在常见的视觉识别任务中使用的mobile网络都有一个全局平均池化层(global average pooling layer,GAP),如MobileNetV1,Shufflenet,Mobilenetv2.对于人脸验证和识别任务,一些研究者[5,14]发现带有全局平均池化的CNN准确度要低于不带有GAP层的网络。不过只是还没有理论性的分析这一结论。这里借助文献[19]的相关描述来分析这一现象。
通常人脸验证流程包含:预处理人脸图片,提取人脸特征,基于特征距离相似性对2张人脸进行匹配。通过采用[5,20,21,22]中的预处理方法,并基于MTCNN进行人脸检测和5个人脸关键点标注并进行对齐,得到每个人脸图片大小112x112,然后通过减去127.5,除以128来进行归一化。最后,一个人脸特征embedding CNN 会将每个对齐后的人脸映射到一个特征向量上,如图1.

不失一般性,下面采用Mobilenetv2作为人脸特征embedding CNN的结构。为了让输出map和原始网络224x224输入一样的size,在第一个卷积层使用stride=1而不是2,因为stride=2会导致准确度较低。所以在全局平均池化层前面的卷积层输出(称为FMap-end)的空间分辨率是7x7。虽然理论上FMap-end角上单元的感受也和中心区域单元的感受野大小是一样的,可是他们处在输入图片的不同位置。如[24]所述,中心区域感受野比其他区域在最后输出上更有影响,且一个感受野内部的这种影响呈现高斯分布。FMap-end的角单元的感受野上有效的感受野size要小于中心单元上的有效感受野。当输入图像时一个对齐的人脸,FMap-end的一个角单元携带比中心单元更少的人脸信息。因此FMap-end上不同的单元对于提取一个人脸特征向量有着不同的重要性。
在MobileNetv2中,平铺后的FMap-end不合适直接用来作为人脸特征,因为维度太高了(62720维)。所以自然做法就是加上全局平均池化层并作为特征向量,而这在许多研究者文献中[5,14]证实准确度也较低,如表2
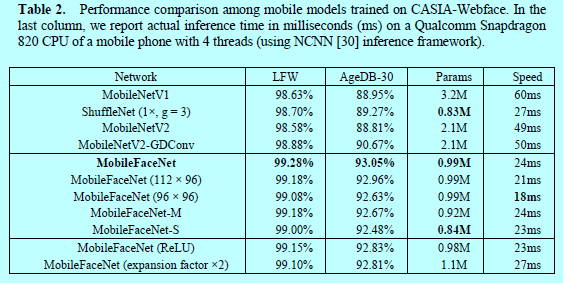
因为全局平均池化层将FMap-end上每个神经元视为等同重要性,这是不合理的。另一个流行的做法就是将全局平均池化层替换成一个全连接层,以此将FMap-end映射到一个更紧凑的特征向量上,这却会增加整个模型的参数量,即使当维度是128维,Mobilenetv2这个全连接层也会额外增加8百万个参数。所以这个方法本文不采用。
1.2 全局逐深度卷积(Global Depthwise Convolution)
为了让FMap-end中不同的单元有不同的重要性,作者将全局平均池化替换成全局逐深度卷积(global depthwise convolution layer, GDConv)。一个GDConv层就是一个逐深度卷积(如文献[1,25]),其kernel大小等于输入的size,pad=0,stride=1。全局逐深度卷积层的输出为:

这里F是输入的feature map,其size为\(W\times H\times M\);K是逐深度卷积核,其size为\(W\times H\times M\);G是输出,其size为\(1\times 1\times M\)。其中在G的第\(m\)个通道上只有一个元素\(G_m\)。其中\((i,j)\)表示F和K中的空间位置,m表示通道的索引。
全局逐深度卷积的计算量为:
\[W\cdot H\cdot M\]
当在MobilenetV2的FMap-end后采用全局逐深度卷积,其核为7x7x1280,即有1280个通道。计算代价为62720MAdds(即相乘-相加的操作次数,如[3]),和62720个参数。假设MobilenetV2-GDConv表示带有全局逐深度的Mobilenetv2。当基于CIASIA-Wefface数据集,Arcface loss训练MobileNetV2 和 MobileNetV2-GDConv,后者货得明显更好的准确度。所以MobilenetFaceNet采用GDConv结构。
1.3 MobileFaceNet 结构
现在,详细描述下Mobilefacenet结构。Mobilenetv2中的残差bottlenecks是mobilefacenet的主要构建块。为了方便描述,这里采用[3]中一样的概念。MobileFaceNet的结构如表1.
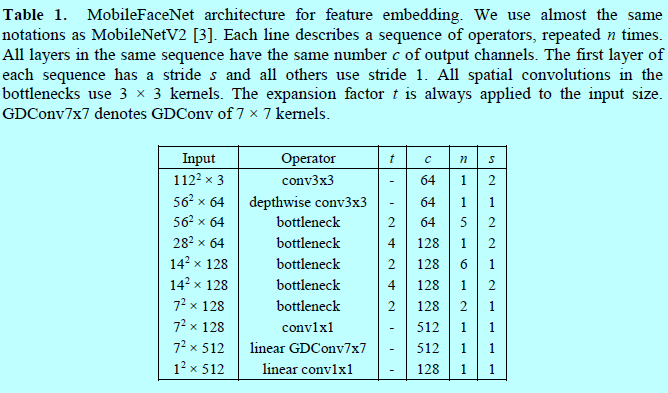
特别的,在MobileFaceNet中的bottleneck的扩展因子比Mobilenetv2中更小一些。且使用PReLU作为激活函数,比ReLU更好。另外,在网络开始就使用了一个快速下采样的策略,在后几层卷积层采用较早维度约间策略,一个线性1x1的卷积层然后接上一个线性全局逐深度卷积层作为特征输出层。在训练中采用BN。然后再部署之前采用BN折叠(如[29]中3.2部分)。
MobileFaceNet网络的计算量是221百万MAdds和0.99百万的参数量。框架进一步细节如下,为了减少计算量,将输入从112x112减少到112x96或者直接96x96。为了减少参数量,移除了MobileFaceNet中GDConv后面的1x1卷积层,此时网络命名为MobileFaceNet-M。从MobileFaceNet-M,移除GDConv前面的1x1卷积层,进一步减少网络结构,此时网络命名为MobileFaceNet-S。这三个网络的性能在下面做详细比较。
2 实验及分析
2.1 训练参数配置和LFW与AgeDB上结果对比
作者采用MobileNetv1,ShuffleNet,MobileNetv2(第一个卷积层stride=1,因为stride=2时候准确度很低)作为baseline模型。所有的MobileFaceNet模型和baseline模型基于CASIA-Webface数据集上从头开始训练,采用ArcFace loss。权值衰减超参为0.0005,在全局操作后的权值衰减超参为0.0004。使用动量为0.9的SGD优化模型,batchsize为512.学习率开始为0.1,然后再36K,52K,58K迭代次数时分别除以10。最终迭代次数为60K次。然后如表2中结果,基于LFW和AgeDB-30进行结果对比。
如之前表2所示,MobileFaceNet获得明显更好的结果,且速度更快。96x96输入的MobileFaceNet速度最快。为了验证极端性能,MobileFaceNet,MobileFaceNet(112x96),MobileFaceNet(96x96)基于干净的MS-Celeb-M训练集,ArcFace loss进行训练。结果如表3.

2.2 在MegaFace挑战上结果
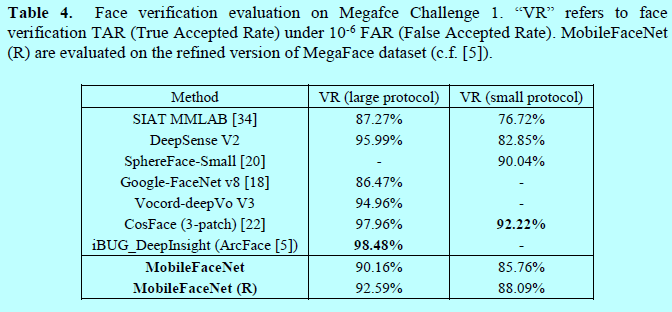
本文中采用Facescrub[36]数据集作为测试集去评估MobileFaceNet在Megaface挑战1上的结果。表4给出了结果,其中以0.5百万张图片作为阈值区分是large protocol还是small protocol。
reference:
- Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., et al.: Mobilenets: Efficient convolutional neural networks for mobile vision applications. CoRR, abs/1704.04861 (2017)
- Zhang, X., Zhou, X., Lin, M., Sun, J.: Shufflenet: An extremely efficient convolutional neural network for mobile devices. CoRR, abs/1707.01083 (2017)
- Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen, L.C.: MobileNetV2: Inverted Residuals and Linear Bottlenecks. CoRR, abs/1801.04381 (2018)
- Guo, Y., Zhang, L., Hu, Y., He, X., Gao, J.: Ms-celeb-1m: A dataset and benchmark for large-scale face recognition. arXiv preprint, arXiv: 1607.08221 (2016)
- Deng, J., Guo, J., Zafeiriou, S.: ArcFace: Additive Angular Margin Loss for Deep Face Recognition. arXiv preprint, arXiv: 1801.07698 (2018)
- Huang, G.B., Ramesh, M., Berg, T., et al.: Labeled faces in the wild: a database for studying face recognition in unconstrained environments. (2007)
- Kemelmacher-Shlizerman, I., Seitz, S. M., Miller, D., Brossard, E.: The megaface benchmark: 1 million faces for recognition at scale. In: CVPR (2016)
- Moschoglou, S., Papaioannou, A., Sagonas, C., Deng, J., Kotsia, I., Zafeiriou, S.: Agedb: The first manually collected in-the-wild age database. In: CVPRW (2017)
- Iandola, F. N., Han, S., Moskewicz, M.W., Ashraf, K., Dally, W.J., Keutzer, K.: Squeezenet: Alexnet-level accuracy with 50x fewer parameters and 0.5 mb model size. arXiv preprint, arXiv:1602.07360 (2016)
- Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. In: NIPS (2012)
- Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: a large-scale hierarchical image database. In: CVPR. IEEE (2009)
- Russakovsky, O., Deng, J., Su, H., et al.: Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 115, 211–252 (2015)
- Zoph, B., Vasudevan, V., Shlens, J., Le, Q.V.: Learning transferable architectures for scalable image recognition. arXiv preprint, arXiv:1707.07012 (2017)
- Wu, X., He, R., Sun, Z., Tan, T.: A light cnn for deep face representation with noisy labels. arXiv preprint, arXiv:1511.02683 (2016)
- Wu, B., Wan, A., Yue, X., Jin, P., Zhao, S., Golmant, N., et al.: Shift: A Zero FLOP, Zero Parameter Alternative to Spatial Convolutions. arXiv preprint, arXiv: 1711.08141 (2017)
- Hinton, G. E., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. In arXiv:1503.02531 (2015)
- Luo, P., Zhu, Z., Liu, Z., Wang, X., Tang, X., Luo, P., et al.: Face Model Compression by Distilling Knowledge from Neurons. In: AAAI (2016)
- Schroff, F., Kalenichenko, D., Philbin, J.: Facenet: a unified embedding for face recognition and clustering. In: CVPR (2015)
- Long, J., Zhang, N., Darrell, T.: Do convnets learn correspondence? Advances in Neural Information Processing Systems, 2, 1601-1609 (2014)
- Liu, W., Wen, Y., Yu, Z., Li, M., Raj, B., Song, L.: Sphereface: Deep hypersphere embedding for face recognition. In: CVPR (2017)
- Wang, F., Cheng, J., Liu, W., Liu, H.: Additive margin softmax for face verification. IEEE Signal Proc. Let., 25(7), 926-930 (2018)
- Wang, H., Wang, Y., Zhou, Z., Ji, X., Gong, D., Zhou, J., et al.: CosFace: Large Margin Cosine Loss for Deep Face Recognition. In arXiv: 1801.0941 (2018)
- Zhang, K., Zhang, Z., Li, Z., Qiao, Y.: Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks. IEEE Signal Proc. Let., 23(10):1499–1503, 2016.
- Luo, W., Li, Y., Urtasun, R., Zemel, R.: Understanding the Effective Receptive Field in Deep Convolutional Neural Networks. In: NIPS (2016)
- Chollet, F.: Xception: Deep learning with depthwise separable convolutions. arXiv preprint, arXiv:1610.02357 (2016)
- Yi, D., Lei, Z., Liao, S., Li, S. Z.: Learning face representation from scratch. arXiv preprint, arXiv:1411.7923 (2014)
- He, K., Zhang, X., Ren, S., Sun, J.: Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In: CVPR (2015)
- Ioffe, S., Szegedy, C.: Batch normalization: accelerating deep network training by reducing internal covariate shift. In: International Conference on Machine Learning (2015)
- Jacob, B., Kligys, S., Chen, B., Zhu, M., Tang, M., Howard, A., et al.: Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. arXiv preprint, arXiv: 1712.05877 (2017)
- NCNN: a high-performance neural network inference framework optimized for the mobile platform, https://github.com/Tencent/ncnn, the version in Apr 20, 2018.
- Taigman, Y., Yang, M., Ranzato, M., et al.: DeepFace: closing the gap to human-level performance in face verification. In: CVPR (2014)
- Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, et al, “Deep face recognition,” In BMVC, volume 1, page 6, 2015.
- Sun, Y., Wang, X., Tang, X.: Deeply learned face representations are sparse, selective, and robust. In: Computer Vision and Pattern Recognition, pp. 2892–2900 (2015).
- Wen, Y., Zhang, K., Li, Z., Qiao, Y.: A discriminative feature learning approach for deep face recognition. In: ECCV (2016)
- Deng, W., Chen, B., Fang, Y., Hu, J.: Deep Correlation Feature Learning for Face Verification in the Wild. IEEE Signal Proc. Let., 24(12), 1877 – 1881 (2017)
- Ng, H. W., Winkler, S.: A data-driven approach to cleaning large face datasets. In: IEEE International Conference on Image Processing (ICIP), pp. 343–347 (2014)
- Han, S., Mao, H., Dally, W. J.: Deep compression: Compressing deep neural network with pruning, trained quantization and Huffman coding. CoRR, abs/1510.00149 (2015)
- He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
face recognition[MobileFaceNet]的更多相关文章
- face recognition[MobiFace]
本文来自<MobiFace: A Lightweight Deep Learning Face Recognition on Mobile Devices>,时间线为2018年11月.是作 ...
- One-Time Project Recognition
Please indicate the source if you need to repost. After implementing NetSutie for serveral companies ...
- 论文阅读(Xiang Bai——【TIP2014】A Unified Framework for Multi-Oriented Text Detection and Recognition)
Xiang Bai--[TIP2014]A Unified Framework for Multi-Oriented Text Detection and Recognition 目录 作者和相关链接 ...
- 论文阅读(Lukas Neuman——【ICDAR2015】Efficient Scene Text Localization and Recognition with Local Character Refinement)
Lukas Neuman--[ICDAR2015]Efficient Scene Text Localization and Recognition with Local Character Refi ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION 这篇论文
由Andrew Zisserman 教授主导的 VGG 的 ILSVRC 的大赛中的卷积神经网络取得了很好的成绩,这篇文章详细说明了网络相关事宜. 文章主要干了点什么事呢?它就是在在用卷积神经网络下, ...
- Pattern Recognition And Machine Learning读书会前言
读书会成立属于偶然,一次群里无聊到极点,有人说Pattern Recognition And Machine Learning这本书不错,加之有好友之前推荐过,便发了封群邮件组织这个读书会,采用轮流讲 ...
- Notes on 'Selective Search For Object Recognition'
UijlingsIJCV2013, Selective Search For Object Recognition code 算法思想 利用分割算法将图片细分成很多region, 或超像素. 在这个基 ...
- 自然语言18.1_Named Entity Recognition with NLTK
QQ:231469242 欢迎nltk爱好者交流 https://www.pythonprogramming.net/named-entity-recognition-nltk-tutorial/?c ...
随机推荐
- python模块--collections
python的内建模块collections有几个关键的数据结构,平常在使用的时候,开发者可以直接调用,不需要自己重复制造轮子,这样可以提高开发效率. 1. deque双端队列 平常我们使用的pyth ...
- 测者的性测试手册:SWAP的监控
swap是什么 swap是磁盘上的一块区域,可以使一个磁盘分区,也可以是一个文件,也可能是一个两种的组合.当物理内存资源紧张的时候,操作系统(Linux)会将一些不常访问的数据放到swap里.为其他常 ...
- 添加用户到sudoers
** is not in the sudoersfile. This incident will bereported.” (用户不在sudoers文件中……) 处理这个问题很简单,但应该先理解其原 ...
- 2019年Web前端最新导航(常见前端框架、前端大牛)
本文最初发表于博客园,并在GitHub上持续更新前端的系列文章.欢迎在GitHub上关注我,一起入门和进阶前端. 前言 本文列出了很多与前端有关的常见网站.博客.工具等,整体来看比较权威.有些东西已经 ...
- Redis内存数据库快速入门
Redis简介 Redis是一个开源(BSD许可),内存数据结构存储,用作数据库,缓存和消息代理.它支持数据结构,如 字符串,散列,列表,集合,带有范围查询的排序集,位图,超级日志,具有半径查询和流的 ...
- Python基于皮尔逊系数实现股票预测
# -*- coding: utf-8 -*- """ Created on Mon Dec 2 14:49:59 2018 @author: zhen "&q ...
- [20190321]smem的显示缺陷.txt
[20190321]smem的显示缺陷.txt1.smem 加入-m参数显示存在缺陷,map的信息不全:# smem -tk -m -U oracle -P "oraclepeis|ora_ ...
- python3 之视频抽针
import cv2 import os Path = "C:/Users/zl3269/Desktop/test/video/" # 视频的格式 /aisg-server/Dat ...
- python3+beautifulsoup4爬取汽车信息
import requests from bs4 import BeautifulSoup response = requests.get("https://www.autohome.com ...
- JAVA API的下载和中文查看API
一.JAVA API的下载 1.1 JAVA由SUN公司开发,2006年SUN公司宣布将Java技术作为免费软件对外发布,标志着JAVA的公开免费.2009年,SUN公司被甲骨文公司收购,因此我们现在 ...