Kettle系列:使用Kudu API插入数据到Kudu中
本文详细介绍了在Kettle中使用 Kudu API将数据写入Kudu中, 从本文可以学习到:
1. 如何编写一个简单的 Kettle 的 Used defined Java class.
2. 如何读取Kettle 每个记录的字段. 需要注意的是 getInteger() 返回的是Long 对象; 而获取 Timestamp 字段的方法是getDate().
3. 如何调用Kudu API.
本Kettle示例非常简单, Data Grid 组件定义一些sample data(包含多种数据类型), Java class将这些sample data写入kudu.
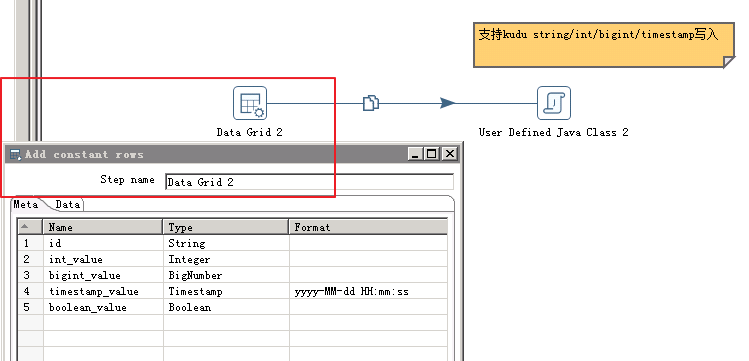
Kudu表schema:
CREATE TABLE kudu_testdb.perf_test_t1
(
id string ENCODING PLAIN_ENCODING COMPRESSION SNAPPY,
int_value int,
bigint_value bigint,
timestamp_value timestamp,
bool_value int,
PRIMARY KEY (histdate,id)
)
PARTITION BY HASH (histdate,id) PARTITIONS 2
STORED AS KUDU
TBLPROPERTIES (
'kudu.table_name' = 'testdb.perf_test_t1',
'kudu.master_addresses' = '10.205.6.1:7051,10.205.6.2:7051,10.205.7.3:7051'
);
重点看Java class 代码:
import java.sql.Timestamp;
import java.util.UUID;
import static java.lang.Math.toIntExact; import org.apache.kudu.client.Insert;
import org.apache.kudu.client.KuduClient;
import org.apache.kudu.client.KuduException;
import org.apache.kudu.client.KuduSession;
import org.apache.kudu.client.KuduTable;
import org.apache.kudu.client.PartialRow;
import org.apache.kudu.client.SessionConfiguration; private final static String KUDU_TABLE="testdb.perf_test_t1";
private final static String KUDU_SERVERS="10.205.6.1:7051,10.205.6.2:7051,10.205.7.3:7051";
private final static int OPERATION_BATCH = 50; KuduClient client=null;
KuduSession session=null;
KuduTable table=null;
Integer recordCount=null;
SessionConfiguration.FlushMode mode; private Object[] previousRow;
private Object[] currentRow; public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException {
if (first) {
first = false;
} currentRow = getRow();
if (currentRow == null) {
setOutputDone();
return false;
} try {
session.setFlushMode(mode);
session.setMutationBufferSpace(OPERATION_BATCH); int uncommit = 0;
while(currentRow != null) {
Insert insert = table.newInsert();
PartialRow kuduRow = insert.getRow(); int intTmp;
Long longTmp;
String stringTmp;
java.util.Date dateTmp;
Boolean booleanTmp; // kettle string -> kudu string
//kuduRow.addString("id",UUID.randomUUID().toString());
stringTmp = get(Fields.In, "id").getString(currentRow);
if (stringTmp!=null)
{
kuduRow.addString("id",stringTmp);
} // kettle int -> kudu int
//import static java.lang.Math.toIntExact;
longTmp=get(Fields.In, "int_value").getInteger(currentRow);
if (longTmp!=null)
{
intTmp =toIntExact(get(Fields.In, "int_value").getInteger(currentRow));
kuduRow.addInt("int_value", intTmp);
} // kettle bigint -> kudu bigint
longTmp=get(Fields.In, "bigint_value").getInteger(currentRow);
if (longTmp!=null)
{
kuduRow.addLong("bigint_value", longTmp);
} // kettle date/timestamp -> kudu timestamp
dateTmp= get(Fields.In, "timestamp_value").getDate(currentRow);
if (dateTmp!=null)
{
longTmp=dateTmp.getTime()+8*3600*1000; //转到东8区时间
kuduRow.addLong("timestamp_value", longTmp*1000);
} // kettle boolean -> kudu int
booleanTmp= get(Fields.In, "boolean_value").getBoolean(currentRow);
if (booleanTmp!=null)
{
intTmp=0;
if (booleanTmp)
{intTmp=1;}
kuduRow.addInt("boolean_value", intTmp);
} // 对于手工提交, 需要buffer在未满的时候flush,这里采用了buffer一半时即提交
uncommit = uncommit + 1;
if (uncommit > OPERATION_BATCH / 2) {
session.flush();
uncommit = 0;
}
session.apply(insert);
previousRow=currentRow;
currentRow=getRow();
} // 对于手工提交, 保证完成最后的提交
if (uncommit > 0) {
session.flush();
} } catch (Exception e) {
e.printStackTrace();
throw e;
} // Send the row on to the next step.
//putRow(data.outputRowMeta, currentRow); return false;
} public boolean init(StepMetaInterface stepMetaInterface, StepDataInterface stepDataInterface) {
try {
client = new KuduClient.KuduClientBuilder(KUDU_SERVERS).build();
session = client.newSession();
table =client.openTable(KUDU_TABLE);
mode = SessionConfiguration.FlushMode.MANUAL_FLUSH;
} catch (Exception e) {
e.printStackTrace();
throw e;
} return parent.initImpl(stepMetaInterface, stepDataInterface);
} public void dispose(StepMetaInterface smi, StepDataInterface sdi) {
try {
if (!session.isClosed()) {
session.close();
}
} catch (Exception e) {
e.printStackTrace();
throw e;
}
parent.disposeImpl(smi, sdi);
}
Kettle系列:使用Kudu API插入数据到Kudu中的更多相关文章
- 【转载】C#批量插入数据到Sqlserver中的三种方式
引用:https://m.jb51.net/show/99543 这篇文章主要为大家详细介绍了C#批量插入数据到Sqlserver中的三种方式,具有一定的参考价值,感兴趣的小伙伴们可以参考一下 本篇, ...
- C#批量插入数据到Sqlserver中的四种方式
我的新书ASP.NET MVC企业级实战预计明年2月份出版,感谢大家关注! 本篇,我将来讲解一下在Sqlserver中批量插入数据. 先创建一个用来测试的数据库和表,为了让插入数据更快,表中主键采用的 ...
- sql 批量插入数据到Sqlserver中 效率较高的方法
使用SqlBulk #region 方式二 static void InsertTwo() { Console.WriteLine("使用Bulk插入的实现方式"); Stopwa ...
- 关于从JSP页面插入数据到数据库中乱码问题的解决
问题描述:最近我在写一个j2ee的留言板系统模块,遇到了一个非常让我头大的问题,当我从JSP页面输入数据后,通过hibernate中的业务逻辑类HQL语句把这个数据插入到本地的mysql数据库中,可是 ...
- C#批量插入数据到Sqlserver中的三种方式
本篇,我将来讲解一下在Sqlserver中批量插入数据. 先创建一个用来测试的数据库和表,为了让插入数据更快,表中主键采用的是GUID,表中没有创建任何索引.GUID必然是比自增长要快的,因为你生 成 ...
- C#_批量插入数据到Sqlserver中的四种方式
先创建一个用来测试的数据库和表,为了让插入数据更快,表中主键采用的是GUID,表中没有创建任何索引.GUID必然是比自增长要快的,因为你生成一个GUID算法所花的时间肯定比你从数据表中重新查询上一条记 ...
- java批量插入数据进数据库中
方式1: for循环,每一次进行一次插入数据. 方式2: jdbc的preparedStatement的batch操作 PreparedStatement.addBatch(); ...... Pre ...
- C# 之 批量插入数据到 SQLServer 中
创建一个用来测试的数据库和表,为了让插入数据更快,表中主键采用的是GUID,表中没有创建任何索引.GUID必然是比自增长要快.而如果存在索引的情况下,每次插入记录都会进行索引重建,这是非常耗性能的.如 ...
- C#批量插入数据到Sqlserver中的四种方式 - 转
先创建一个用来测试的数据库和表,为了让插入数据更快,表中主键采用的是GUID,表中没有创建任何索引.GUID必然是比自增长要快的,因为你生成一个GUID算法所花的时间肯定比你从数据表中重新查询上一条记 ...
随机推荐
- Markdown 使用技巧
懒得复制,直接贴网页吧 懒得复制,直接贴网页吧*2 懒得复制,直接贴网页吧*3
- Before NOIP 2018
目录 总结 刷题 2018 - 9 - 24 2018 - 9 - 25 2018 - 9 - 26 2018 - 9 - 27 2018 - 9 - 28 2018 - 9 - 29 2018 - ...
- 【Loj117】有源汇上下界最小流(网络流)
[Loj117]有源汇上下界最小流(网络流) 题面 Loj 题解 还是模板题. #include<iostream> #include<cstdio> #include< ...
- JavaWeb项目:在线评测系统
此项目为本人的Java大作业. 项目文件和相关资源已上传到本人的GitHub 一.项目概况 1.1设计内容 一个在线评测系统,分用户和管理员两种身份.用户能够通过注册登录,参加比赛,最后实时得到比赛结 ...
- NOIP2013火柴排队
Solution 恕我直言,这题是真的坑. 对于这道题,一个很显然的思路是对于A B两个序列,他们交换完后相对的两个数在原序列中的相对大小是相同的,于是我们就把序列按照A排序,在把B离散化,求逆序对, ...
- 【php】php从多个数组中取出最大的值
function _arr_max($arr = []){ if(func_num_args() > 1){ $result = []; foreach(func_get_args() as $ ...
- 数据库设计E-R图
项目数据库的设计主要划分为以下6个阶段,本篇主要着重来介绍概念设计阶段 A.系统需求分析阶段B.概念结构设计阶段C.逻辑结构设计阶段D.物理结构设计阶段E.数据库实施阶段F.数据库运行与维护阶段 E- ...
- 解决关于confluence缓慢 字体乱码 宏乱码 编辑不能贴图等问题
应用场景:Confluence软件不用多说,与Jira一样,都是atlassion的精品软件,不再介绍. 这里因为使用的是破解版的confluence,故遇见一些问题,只能百度谷歌自行解决,也在此记录 ...
- JavaScript深入之变量对象
前言 在上篇<javascript深入之执行上下文栈>中讲到,当javascript代码执行一段可执行代码(executable code)时,会创建对应的执行上下文(execution ...
- eclipse中如何复制用点分隔的全类名
结果: com.xxx..redis.service.JedisClient