【Python爬虫】01:网络爬虫--规则
Python网络爬虫与信息提取
目标:掌握定向网络数据爬取和网页解析的基本能力。
the website is the API
课程分为以下部分:
1、requsets库(自动爬取HTML页面、自动网络请求提交)
2、robots.txt规则(网络爬虫排除标准)(合理合法的使用爬虫)
3、beautiful soup库(解析HTML页面)(提取相关项目)
4、projects项目(实战项目A/B)
5、re正则表达式库(正则表达式详解、提取页面关键信息)
6、专业网络爬虫框架scrapy*(网络爬虫原理介绍、专业爬虫框架介绍)
IDE:集成开发环境,编写、调试、发布Python程序的工具。
常用的Python IDE工具有2大类:
一、文本工具类IDE
二、集成工具类IDE

IDLE:自带、默认、常用、入门级。包含交互式和文件式两种方式。
使用:Python入门、功能简单直接、300+代码以内
sublime text:专为程序员开发的第三方专用编程工具、专业编程体验(专业程序员都用这个)、多种编程风格、工具非注册免费试用。
Wing:公司维护,工具收费;调试功能丰富;版本控制,版本同步;适合多人共同开发
Visual Studio & PTVS:微软公司维护;win环境为主;调试功能丰富。
PyCharm:社区版免费;简单,集成度高;适合较复杂工程。
专门针对科学计算、数据分析的IDE
Canopy:公司维护,工具收费;支持近500个第三方库;适合科学计算领域应用开发。
Anaconda:开源免费;支持近800个第三方库。
Requests库入门
requests库安装:
1、打开“cmd”;2、输入:pip install requests;3、安装完成
requests库测试: 在IDLE操作
>>> import requests
>>> r = requests.get("http://www.baidu.com")
>>> r.status_code # 查看r的状态码
200 # 状态码为200表示爬取成功,不是200则访问失败
>>> r.encoding = "utf-8"
>>> r.text # 下面内容表示成功爬取百度首页内容
'<!DOCTYPE html>\r\n<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write(\'<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=\'+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ \'" name="tj_login" class="lb">登录</a>\');\r\n </script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>\r\n'
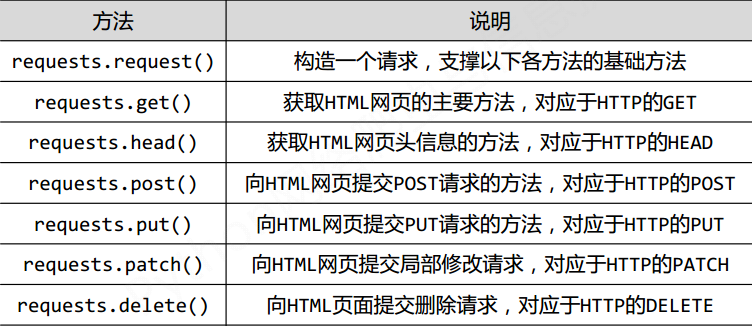
requests库的7个主要方法
| 方法 | 说明 |
| requests.request() | 构造一个请求,是支撑一下各种方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requsets.head() | 获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete() | 向HTML网页提交删除请求,对应于HTTP的DELETE |
requests.get()方法介绍:
r = requests.get(url) # 获得一个网页
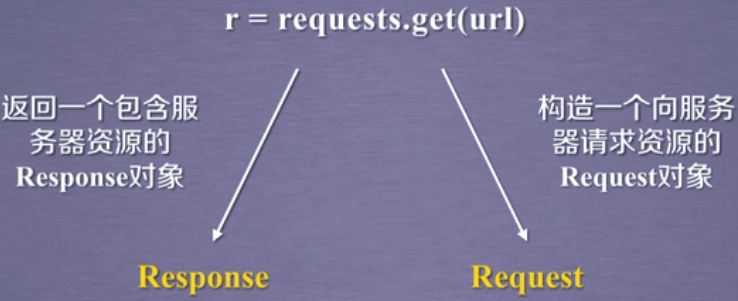
Response对象返回所有网页内容
requests.get(url, params=None, **kwargs) # url: 拟获取页面的url链接
# params:url中的额外参数,字典或字节流格式,可选
# **kwargs:12个控制访问的参数
Response对象的属性
| 属性 | 说明 |
| r.status_code | HTTP请求的返回状态,200表示链接成功,404表示失败(只要不是200就是失败) |
| r.text | HTTP响应内容的字符串形式,即,url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式)(更准确)推荐 |
| r.content | HTTP响应内容的二进制形式 |
r.encoding:根据HTTP中header中charset分析编码方式,如果header中不存在charset,则认为编码为ISO-8859-1
r.apparent_encoding:跟准确,根据HTTP内容分析可能的编码方式,
requests.get()方法获取网上资源的流程
1、用r.status_code方法检查返回的Response对象的状态。
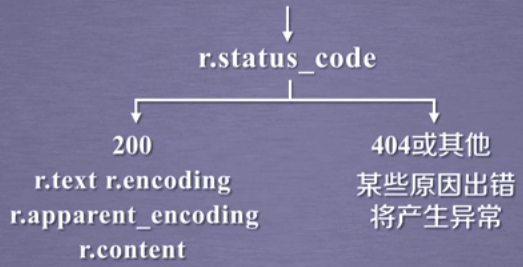
爬取网页的通用代码框架
网络爬取有风险,异常处理很重要
理解requests库的异常
| 异常 | 说明 |
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败、防火墙拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLReuired | URL缺失异常 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常(仅指与远程服务器连接过程超时) |
| requests.Timeout | 请求URL超时,产生超时异常(发出URL请求到收到内容整个过程超时) |
| 异常 | 说明 |
| r.raise_for_status() | 如果是200,则表示正确;如果不是200,则产生异常requests.HTTPError |
爬取网页的通用代码框架
import requests def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status() # 如果状态不是200,引发HTTPError异常
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__ == "__main__":
url = "http://www.baidu.com"
print(getHTTPText(url))
网络爬虫的盗亦有道--robots协议介绍
HTTP协议
HTTP,hypertext transfer protocol,超文本传输协议。
HTTP是一个基于“请求与响应”模式的、无状态的应用层协议
- 请求与响应模式:用户发出请求,服务器做出响应。
- 无状态:第一次请求和第二次请求之间没有相关关联
HTTP协议采用URL作为定位网络资源的标识
- URL格式: http://host[:port][path]
host:合法的Internet主机域名或IP地址
port:端口号,缺省端口为80(默认80)
path:请求资源的路径
- HTTP URL的理解:URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源
HTTP协议对资源的操作
| 方法 | 说明 |
| GET | 请求获取URL位置的资源 |
| HEAD | 请求获取URL位置资源的响应信息报告,即获得该资源的头部信息 |
| POST | 请求向URL位置的资源后附加新的资源 |
| PUT | 请求向URL位置存储一个资源,即覆盖原URL位置的资源 |
| PATCH | 请求局部更新URL位置的资源,即改变该处资源的部分内容 |
| DELETE | 请求删除URL位置存储的资源 |

理解PATCH和PUT的区别
假设URL位置有一组数据UserInfo,包括UserID、 UserName等20个字段
需求:用户修改了UserName,其他不变
• 采用PATCH,仅向URL提交UserName的局部更新请求
• 采用PUT,必须将所有20个字段一并提交到URL,未提交字段被删除
PATCH的最主要好处:节省网络带宽
HTTP协议与Requests库

Requests库的head()方法:可以通过很少的流量,获得资源的概要信息
Requests库的post()方法:向服务器提交新增数据
Requests库的post()方法:与post方法类似,只是会将原有的数据覆盖
Requests库主要方法解析:
Requests库的7个主要方法
requests.request(method,url,**kwargs)
method: 请求方式,对应get/put/post等7种
url: 拟获取页面的url连接
**kwargs: 控制访问的参数,共13个
method : 请求方式
r = requests.request('GET', url, **kwargs)
r = requests.request('HEAD', url, **kwargs)
r = requests.request('POST', url, **kwargs)
r = requests.request('PUT', url, **kwargs)
r = requests.request('PATCH', url, **kwargs)
r = requests.request('delete', url, **kwargs)
r = requests.request('OPTIONS', url, **kwargs)
requests.request(method, url, **kwargs) **kwargs参数介绍
---**kwargs:控制访问的参数,均为可选项
1、params:字典或字节序列,作为参数增加到url中
>>> kv = {'key1':'value1','key2':'value2'}
>>> r = requests.request('GET','http://python123.io/ws',params=kv)
>>> print(r.url)
https://python123.io/ws?key1=value1&key2=value2
2、data:字典、字节序列或文件对象,作为request的内容
>>> kv = {'key1':'value1','key2':'value2'}
>>> r = requests.request('POST','http://python123.io/ws',data=kv)
>>> body = '主题内容'
>>> r = requests.request('POST','http://pyhton123.io/ws',data=body)
3、json:JSON格式的数据,作为request的内容
>>> kv ={'key1':'value1'}
>>> r = requests.request('POST','http://python123.io/ws',json=kv)
4、headers:字典,HTTP定制头(模拟任何浏览器,向浏览器发起访问)
>>> hd = {'user-agent':'Chrome/10'} # Chrome/10 Chrome浏览器第10个版本
>>> r = requests.request('POST','http://python123.io/ws',headers=hd)
Requests库爬取实例
学习资料:中国大学MOOC-Python网络爬虫与信息提取
【Python爬虫】01:网络爬虫--规则的更多相关文章
- [Python学习] 简单网络爬虫抓取博客文章及思想介绍
前面一直强调Python运用到网络爬虫方面很有效,这篇文章也是结合学习的Python视频知识及我研究生数据挖掘方向的知识.从而简介下Python是怎样爬去网络数据的,文章知识很easy ...
- Python初学者之网络爬虫(二)
声明:本文内容和涉及到的代码仅限于个人学习,任何人不得作为商业用途.转载请附上此文章地址 本篇文章Python初学者之网络爬虫的继续,最新代码已提交到https://github.com/octans ...
- Python 利用Python编写简单网络爬虫实例3
利用Python编写简单网络爬虫实例3 by:授客 QQ:1033553122 实验环境 python版本:3.3.5(2.7下报错 实验目的 获取目标网站“http://bbs.51testing. ...
- Python 利用Python编写简单网络爬虫实例2
利用Python编写简单网络爬虫实例2 by:授客 QQ:1033553122 实验环境 python版本:3.3.5(2.7下报错 实验目的 获取目标网站“http://www.51testing. ...
- 智普教育Python培训之Python开发视频教程网络爬虫实战项目
网络爬虫项目实训:看我如何下载韩寒博客文章Python视频 01.mp4 网络爬虫项目实训:看我如何下载韩寒博客文章Python视频 02.mp4 网络爬虫项目实训:看我如何下载韩寒博客文章Pytho ...
- Python爬虫-01:爬虫的概念及分类
目录 # 1. 为什么要爬虫? 2. 什么是爬虫? 3. 爬虫如何抓取网页数据? # 4. Python爬虫的优势? 5. 学习路线 6. 爬虫的分类 6.1 通用爬虫: 6.2 聚焦爬虫: # 1. ...
- 从零开始学Python 三(网络爬虫)
本章由网络爬虫的编写来学习python.首先写几行代码抓取百度首页,提提精神,代码如下: import urllib.request file=urllib.request.urlopen(" ...
- Python中的网络爬虫怎么用?
爬虫概述 (约2016年)网络爬虫个人使用和科研范畴基本不存在问题,但商业盈利范畴就要看对方了. 通过网站的Robots协议(爬虫协议)可以知道可以和不可以抓取的内容,其中User-Agent: 为允 ...
- Python 基础教程 —— 网络爬虫入门篇
前言 Python 是一种解释型.面向对象.动态数据类型的高级程序设计语言,它由 Guido van Rossum 于 1989 年底发明,第一个公开发行版发行于 1991 年.自面世以后,Pytho ...
- 【Python开发】【神经网络与深度学习】如何利用Python写简单网络爬虫
平时没事喜欢看看freebuf的文章,今天在看文章的时候,无线网总是时断时续,于是自己心血来潮就动手写了这个网络爬虫,将页面保存下来方便查看 先分析网站内容,红色部分即是网站文章内容div,可以看 ...
随机推荐
- DAX和Power BI中的参考日期表
本文使用Power BI模板描述DAX中的引用Date表,可以在Analysis Services模型中使用相同的技术.在Dax Date Template页面下载最新版本的模板. 为什么引用Date ...
- 信号报告-python
#Signal report.py a = eval(input()) #这里要整除 readability = a // 10 strength = a - readability * 10 # p ...
- python从零开始 -- 第2篇之python版本差异
python从零开始 -- 第2篇之python版本差异 第0篇开始,咱们就说选择 python 3.x,一般来说,咱们面临选择的时候总是想了解更多一点,并且版本之间的对比能引申出很多有意思的故事和知 ...
- MySQL 8.0.13 下载安装教程
MySQL是使用最多的数据库,自己电脑上肯定要装一个来多加学习,自己搞不懂的一些东西要多写一些 sql 语句练习. 首先去 mysql 官网下载,地址:https://dev.mysql.com/do ...
- sublime text 3 ,React,html元素自动补全方法(用Emmet写法写jsx中的html)
1. 安装emmet: Preferences -> Package Control -> Install Package -> emmet 2. 配置emmet: Preferen ...
- js: 文件(excel)下载处理
以前很少接触文件下载的功能,昨天和后台开发人员联调下载功能出现了问题,一开始我请求接口,返回二进制文件流乱码,在网上找了方法,可以解决.后面后台开发人员改了一下,返回文件地址,然后就解决了.所以我了解 ...
- centos vsftpd
1.配置文件 # 是否允许匿名登录FTP服务器,默认设置为YES允许# 用户可使用用户名ftp或anonymous进行ftp登录,口令为用户的E-mail地址.# 如不允许匿名访问则设置为NOanon ...
- hdu 4506 快速幂
小明自从告别了ACM/ICPC之后,就开始潜心研究数学问题了,一则可以为接下来的考研做准备,再者可以借此机会帮助一些同学,尤其是漂亮的师妹.这不,班里唯一的女生又拿一道数学题来请教小明,小明当然很高兴 ...
- spring3-struts2整合
spring 负责对象创建 struts 用Action处理请求 说明: spring版本:spring-framework-3.2.5.RELEASE struts版本:struts-2.3. ...
- 黑an网络---an网入门
我认为学网络的会上an网也是一项必备的技能,我不是鼓励你去犯罪而是保护自己的个人隐私免遭被侵害.an网和shen网实际上都是从英文翻译来的,an网即Dark Net或Dark Web,shen网则译为 ...