Python小爬虫——抓取豆瓣电影Top250数据
python抓取豆瓣电影Top250数据
1.豆瓣地址:https://movie.douban.com/top250?start=25&filter=
2.主要流程是抓取该网址下的Top250的数据,存入本地的txt文件中,并将数据持久化写入数据库中
环境准备:
1.本地安装mysql数据库,具体下载以及安装参照:https://blog.csdn.net/chic_data/article/details/72286329
2.安装好数据后创建database和table,并创建字段
如:我安装的版本是mysqlV8.0
CREATE TABLE doubanTop250(
ID int PRIMARY KEY AUTO_INCREMENT,
rankey int,
name varchar(50),
alias varchar(100),
director varchar(50),
showYear varchar(50),
makeCountry varchar(50),
movieType varchar(50),
movieScore float,
scoreNum int,
shortFilm varchar(255)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
最后我们直接来看代码:
from urllib import request
import re
import pymysql
class MovieTop(object):
def __init__(self):
self.start = 0
self.param = '&filter'
self.headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/65.0.3325.146 Safari/537.36"}
self.movieList = []
self.filePath = './DoubanTop250.txt' def get_page(self):
try:
url = 'https://movie.douban.com/top250?start=' + str(self.start) + '&filter='
myRequest = request.Request(url, headers=self.headers)
response = request.urlopen(myRequest)
page = response.read().decode('utf-8')
print('正在获取第' + str((self.start+25)//25) + '页数据...')
self.start += 25
return page
except request.URLError as e:
if hasattr(e, 'reason'):
print('获取失败,失败原因:', e.reason) def get_page_info(self):
patern = re.compile(u'<div.*?class="item">.*?'
+ u'<div.*?class="pic">.*?'
+ u'<em.*?class="">(.*?)</em>.*?'
+ u'<div.*?class="info">.*?'
+ u'<span.*?class="title">(.*?)</span>.*?'
+ u'<span.*?class="other">(.*?)</span>.*?'
+ u'<div.*?class="bd">.*?'
+ u'<p.*?class="">.*?'
+ u'导演:\s(.*?)\s.*?<br>'
+ u'(.*?) / '
+ u'(.*?) / (.*?)</p>.*?'
+ u'<div.*?class="star">.*?'
+ u'<span.*?class="rating_num".*?property="v:average">'
+ u'(.*?)</span>.*?'
+ u'<span>(.*?)人评价</span>.*?'
+ u'<span.*?class="inq">(.*?)</span>'
, re.S) while self.start <= 225:
page = self.get_page()
movies = re.findall(patern, page)
for movie in movies:
self.movieList.append([movie[0],
movie[1],
movie[2].lstrip(' / '),
movie[3],
movie[4].lstrip(),
movie[5],
movie[6].rstrip(),
movie[7],
movie[8],
movie[9]]) def write_page(self):
print('开始写入文件...')
file = open(self.filePath, 'w', encoding='utf-8')
try:
for movie in self.movieList:
file.write('电影排名:' + movie[0] + '\n')
file.write('电影名称:' + movie[1] + '\n')
file.write('电影别名:' + movie[2] + '\n')
file.write('导演:' + movie[3] + '\n')
file.write('上映年份:' + movie[4] + '\n')
file.write('制作国家/地区:' + movie[5] + '\n')
file.write('电影类别:' + movie[6] + '\n')
file.write('评分:' + movie[7] + '\n')
file.write('参评人数:' + movie[8] + '\n')
file.write('简短影评:' + movie[9] + '\n')
file.write('\n')
print('成功写入文件...')
except Exception as e:
print(e)
finally:
file.close() def upload(self):
db = pymysql.connect("localhost", "root", "root", "PythonTest", charset='utf8')
cursor = db.cursor() insertStr = "INSERT INTO doubanTop250(rankey, name, alias, director," \
"showYear, makeCountry, movieType, movieScore, scoreNum, shortFilm)" \
"VALUES (%d, '%s', '%s', '%s', '%s', '%s', '%s', %f, %d, '%s')" try:
for movie in self.movieList:
insertSQL = insertStr % (int(movie[0]), str(movie[1]), str(movie[2]), str(movie[3]),
str(movie[4]), str(movie[5]), str(movie[6]), float(movie[7]),
int(movie[8]), str(movie[9]))
cursor.execute(insertSQL)
db.commit()
print('成功上传至数据库...')
except Exception as e:
print(e)
db.rollback()
finally:
db.close() if __name__ == '__main__':
mt = MovieTop()
mt.get_page_info()
mt.write_page()
mt.upload()
执行结果: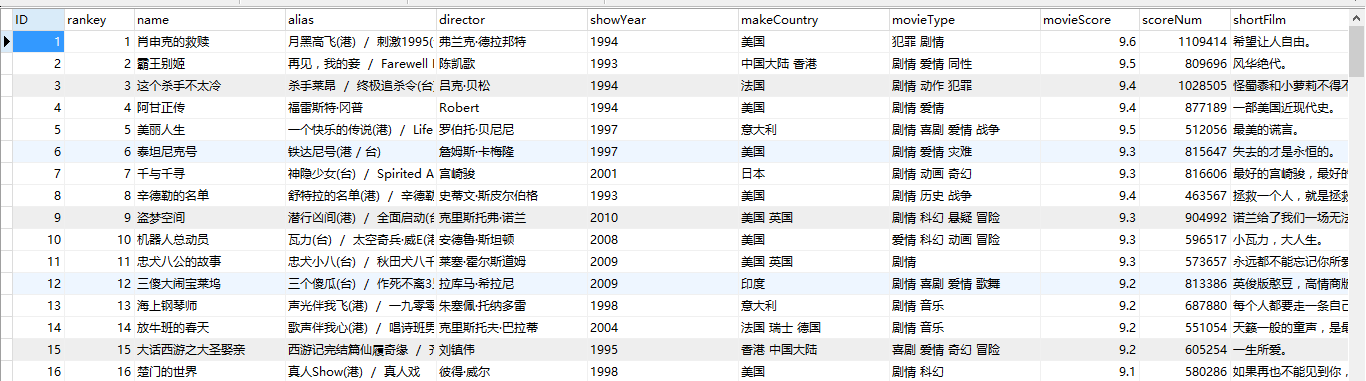
参照原文地址:https://www.cnblogs.com/AlvinZH/p/8576841.html#_label0
Python小爬虫——抓取豆瓣电影Top250数据的更多相关文章
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- Python抓取豆瓣电影top250!
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:404notfound 一直对爬虫感兴趣,学了python后正好看到 ...
- Python:python抓取豆瓣电影top250
一直对爬虫感兴趣,学了python后正好看到某篇关于爬取的文章,就心血来潮实战一把吧. 实现目标:抓取豆瓣电影top250,并输出到文件中 1.找到对应的url:https://movie.douba ...
- python2.7抓取豆瓣电影top250
利用python2.7抓取豆瓣电影top250 1.任务说明 抓取top100电影名称 依次打印输出 2.网页解析 要进行网络爬虫,利用工具(如浏览器)查看网页HTML文件的相关内容是很有必要,我使用 ...
- python爬虫 Scrapy2-- 爬取豆瓣电影TOP250
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- Python3 抓取豆瓣电影Top250
利用 requests 抓取豆瓣电影 Top 250: import re import requests def main(url): global num headers = {"Use ...
- scrapy抓取豆瓣电影相关数据
1. 任务分析及说明 目标网站:https://movie.douban.com/tag/#/ 抓取豆瓣电影上,中国大陆地区,相关电影数据约1000条:数据包括:电影名称.导演.主演.评分.电影类型. ...
- Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统.谷歌浏览器 目的:爬取豆瓣电影排行榜中电影的title.链接地址.图片.评价人数.评分等 网址:https:// ...
随机推荐
- RuntimeError: Python is not installed as a framework.
RuntimeError: Python is not installed as a framework. 文章转载:https://www.cnblogs.com/harelion/p/563776 ...
- babel-preset-env使用指南
文章概览 babel-preset-env是非常重要且常用的一个插件预设,掌握它的用法以及实现原理非常有必要. 本文主要内容包括:babel-preset-env是什么.入门实例.如何配置以支持特定版 ...
- flask实现子域名
什么是子域名? 子域名,类似于xxx.douban.com的形式,如book.douban.com,music.douban.com,movie.douban.com等 用flask怎么实现子域名? ...
- Git_GitHub详解
Git和Github详细教程 一 概述 说到Git和Github,前几天我们知道微软以75亿美元收购全球最大的代码托管和写作平台GitHub,而GitHub是全球最大的代码仓库,很多开发人员都将代码 ...
- IP核引发的关于定,浮点数的认识
上面是一段关于CORDIC_IP测试文件,用于计算给定角度的sin值和cos值,关于数值表示规则在此不再重复,仅仅说明以下3点: 1 数采用原码,反码,补码,本身并没有正确与否之分(这一点很重要,我 ...
- 线程锁(互斥锁Mutex)及递归锁
一.线程锁(互斥锁) 在一个程序内,主进程可以启动很多个线程,这些线程都可以访问主进程的内存空间,在Python中虽然有了GIL,同一时间只有一个线程在运行,可是这些线程的调度都归系统,操作系统有自身 ...
- JEECG 不同(角色的)人对同样的字段数据,使用不同的字段验证规则
JEECG智能开发平台v3 开发指南http://www.jeecg.org/book/jeecg_v3.html jeecg: JEECG是一款基于代码生成器的J2EE快速开发平台,开源界“小普元” ...
- 面向对象设计的SOLID原则、迪米特法则
SPR(The Single Responsibility Principle):单一责任原则 OCP(The Open Closed Principle):开放封闭原则 LSP(The Liskov ...
- PHP中友好的处理方式
在使用PHP进行开发的时候,由于PHP是弱类型语言的特性,所以,偶尔会遇到一些意想不到的错误.规范我们的编程就变得尤为重要了.下面总结一下,我日常开发中的一些经验,可能有些地方不妥,还请多多斧正,指教 ...
- CDH 6.0.1 集群搭建 「After install」
集群搭建完成之后其实还有很多配置工作要做,这里我列举一些我去做的一些. 首先是去把 zk 的角色重新分配一下,不知道是不是我在配置的时候遗漏了什么在启动之后就有报警说目前只能检查到一个节点.去将 zk ...