jemalloc内存分配原理【转】
原文:http://www.cnblogs.com/gaoxing/p/4253833.html
内存分配是面向虚拟内存的而言的,以页为单位进行管理的,页的大小一般为4kb,当在堆里创建一个对象时(小于4kb),会分配一个页,当再次创建一个对象时会判断该页剩余大小是否够,够的话使用该页剩余的内存,减少系统调用。真实的内存分配算法比这个复杂了,效率不好的内存算法会导致出现很多内存碎片。
内存分配的核心思想概括起来有3条
1:首先讲内存区(memory pool)以最小单位(chunk)定义出来 ,然后区分对象大小分别管理内存,小内存定义不同的规格(bins),根据不同的bin分配固定大小的内存块,并用一个表
管理起来,大对象则以页为单位进行管理,配合小对象所在的页,降低碎片,设计一个好的存储方案(metadata)减少对内存的占用,同时优化内存信息的存储。以使对每个bin或大内存区域的访问性能最优且有上限。
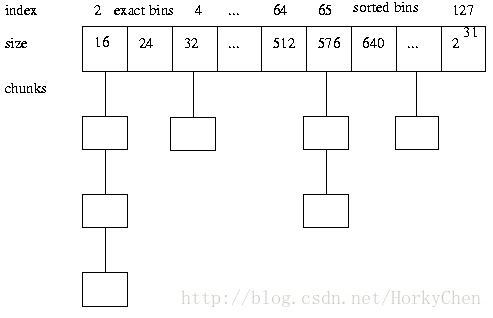
2:当释放内存时,要能够合并小内存为大内存,该保留的保留下次可快速响应,不该保留的释放给系统
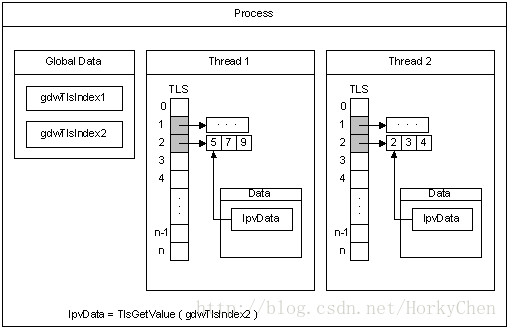
3:多线程环境下,每个线程可以独立的占有一段内存区间(TLS),这样线程内操作可以不加锁
jemalloc是freebsd的内存分配算法,他的layout如下:
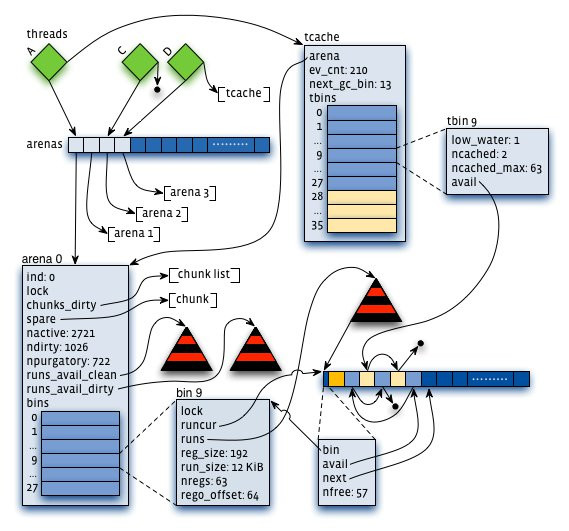
1:arena:把内存分成许多不同的小块来分而治之,该小块便是arena,让我们想象一下,给几个小朋友一张大图纸,让他们随意地画点。结果可想而知,他们肯定相互顾忌对方而不敢肆意地画(synchronization),从而影响画图效率。但是如果老师事先在大图纸上划分好每个人的区域,小朋友们就可以又快又准地在各自地领域上画图。这样的概念就是arena。它是jemalloc的核心分配管理区域,对于多核系统,会默认分配4*cores个arena 。线程采用轮询的方式来选择响应的arena进行内存分配。
2: chunk。具体进行内存分配的区域,默认大小是4M,chunk以page为单位进行管理,每个chunk的前6个page用于存储后面page的状态,比如是否分配或已经分配
3:bin:用来管理各个不同大小单元的分配,比如最小的Bin管理的是8字节的分配,每个Bin管理的大小都不一样,依次递增。
4:run:每个bin在实际上是通过对它对应的正在运行的Run进行操作来进行分配的,一个run实际上就是chunk里的一块区域,大小是page的整数倍,具体由实际的bin来决定,比如8字节的bin对应的run就只有1个page,可以从里面选取一个8字节的块进行分配。在run的最开头会存储着这个run的信息,比如还有多少个块可供分配。
5:tcache。线程对应的私有缓存空间,默认是使用的。因此在分配内存时首先从tcache中找,miss的情况下才会进入一般的分配流程。
arena和bin的关系:每个arena有个bin数组,每个bin管理不同大小的内存(run通过它的配置去获取相应大小的内存),每个tcahe有一个对应的arena,它本身也有一个bin数组(称为tbin),前面的部分与arena的bin数组是对应的,但它长度更大一些,因为它会缓存一些更大的块;而且它也没有对应的run的概念
chunk与run的关系:chunk默认是4M,而run是在chunk中进行实际分配的操作对象,每次有新的分配请求时一旦tcache无法满足要求,就要通过run进行操作,如果没有对应的run存在就要新建一个,哪怕只分配一个块,比如只申请一个8字节的块,也会生成一个大小为一个page(默认4K)的run;再申请一个16字节的块,又会生成一个大小为4096字节的run。run的具体大小由它对应的bin决定,但一定是page的整数倍。因此实际上每个chunk就被分成了一个个的run。
内存分配的,具体流程如下:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
jemalloc内存分配原理【转】的更多相关文章
- 深入Java核心 Java内存分配原理精讲
深入Java核心 Java内存分配原理精讲 栈.堆.常量池虽同属Java内存分配时操作的区域,但其适用范围和功用却大不相同.本文将深入Java核心,详细讲解Java内存分配方面的知识. Java内存分 ...
- JVM内存分配原理
堆栈常量池等内存分配原理详解 存储的方式: 寄存器 栈(stack) 堆(heap) 静态域 常量池 非RAM存储 JAVA寄存器 最快的存储区, 由编译器根据需求进行分配,我们在程序中无法控制. ...
- 深入理解golang:内存分配原理
一.Linux系统内存 在说明golang内存分配之前,先了解下Linux系统内存相关的基础知识,有助于理解golang内存分配原理. 1.1 虚拟内存技术 在早期内存管理中,如果程序太大,超过了空闲 ...
- linux环境内存分配原理 mallocinfo
Linux的虚拟内存管理有几个关键概念: Linux 虚拟地址空间如何分布?malloc和free是如何分配和释放内存?如何查看堆内内存的碎片情况?既然堆内内存brk和sbrk不能直接释放,为什么不全 ...
- 【转】linux环境内存分配原理 malloc info
Linux的虚拟内存管理有几个关键概念: Linux 虚拟地址空间如何分布?malloc和free是如何分配和释放内存?如何查看堆内内存的碎片情况?既然堆内内存brk和sbrk不能直接释放,为什么不全 ...
- ptmalloc,tcmalloc和jemalloc内存分配策略研究 ? I'm OWen..
转摘于http://www.360doc.com/content/13/0915/09/8363527_314549949.shtml 最近看了glibc的ptmaoolc,Goolge的tcmall ...
- linux环境内存分配原理 mallocinfo【转】
转自:http://www.cnblogs.com/dongzhiquan/p/5621906.html Linux的虚拟内存管理有几个关键概念: Linux 虚拟地址空间如何分布?malloc和fr ...
- TCMalloc 内存分配原理简析
一.TCMalloc TCMalloc简介 为啥要介绍 TCMalloc? 因为golang的内存分配算法绝大部分都是来自 TCMalloc,golang只改动了其中的一小部分.所以要理解golang ...
- java内存分配原理
一般Java在内存分配时会涉及到以下区域: ◆寄存器:我们在程序中无法控制 ◆栈:存放基本类型的数据和对象的引用,但对象本身不存放在栈中,而是存放在堆中 ◆堆:存放用new产生的数据 ◆静态域:存放在 ...
随机推荐
- 换个语言学一下 Golang (13)——Web表单处理
介绍 表单是我们平常编写Web应用常用的工具,通过表单我们可以方便的让客户端和服务器进 行数据的交互.对于以前开发过Web的用户来说表单都非常熟悉.表单是一个包含表单元素的区域.表单元素是允许用户在表 ...
- [Tools] 多媒体视频处理工具FFmpeg
FFMpeg FFmpeg是一套可以用来记录.转换数字音频.视频,并能将其转化为流的开源计算机程序.采用LGPL或GPL许可证.它提供了录制.转换以及流化音视频的完整解决方案.它包含了非常先进的音频/ ...
- Serverless
一.介绍 是指依赖于第三方应用程序或服务来管理服务器端逻辑的应用程序. 此类应用程序是基于云的数据库(如Google Firebase)或身份验证服务. 无服务器也意味着开发为事件触发的代码,并且在无 ...
- 【转载】C#使用InsertRange方法往ArrayList集合指定位置插入另一个集合
在C#的编程开发中,ArrayList集合是一个常用的非泛型类集合,ArrayList集合可存储多种数据类型的对象.在实际的开发过程中,我们可以使用InsertRange方法在ArrayList集合指 ...
- vue项目的一个package.json
{ "name": "projectName", "version": "1.0.1", "des ...
- Linux chage命令详解
原文 chage命令用于密码实效管理,该是用来修改帐号和密码的有效期限,接下来通过本文给大家介绍Linux chage命令相关知识,本文介绍的非常详细,具有参考借鉴价值,感兴趣的朋友一起学习吧 lin ...
- .Net core3.0 集成swagger5.0上传文件
.Net core 3.0已经更新了,相信有挺多博主大佬们都更新了如何在.Net core3.0使用swagger,这里就不详细说了. 我们知道,如果.net core 2.x使用swagger上传文 ...
- 机器学习笔记8:XGBoost
目录 1 回顾一下决策树 2 XGBoost举例 2.1 问题和结果 2.2 第一棵树的计算方法 2.3 第二棵树的计算方法 3 XGBoost公式推导 3.1 第一种理解公式 3.2 第二种理解公式 ...
- JanusGraph安装graphexp
准备:JanusGraph环境,graphexp源码,nginx 本文采用的环境:JanusGraph + cassandra + ES + GraphExp(cassandra 或者HBase作为后 ...
- Vim 简易配置
Macbook终端vim使用系统剪切板 系统自带的, 可执行程序是 /usr/bin/vim, 安装目录是 /usr/share/vim/, 版本7.3. 我使用 homebrew 后顺手安装了一次 ...