LCA的几种做法
P3379 LCA
$ 1:$蜗牛爬式
void dfs(int u,int fa) {
f[u]=fa;//预处理father
for(int i=head[u]; i; i=e[i].nxt) if(e[i].v!=fa) {
int &w=e[i].w,&v=e[i].v;
dis[v]=dis[u]+w;
h[v]=h[u]+1;//预处理深度
dfs(v,u);
}
}
int LCA(int x,int y) {
while(h[x]<h[y])y=f[y];
while(h[x]>h[y])x=f[x];//移动至同一深度
while(x!=y) x=f[x],y=f[y];
return x;
}
复杂度:\(O( log(n) )\) ~ \(O(n)\)
当然,这东西非常好卡,一卡就凉\(->\) \(O(n)\)
事实上,这种暴力算法,数据达到5e5时绝对会T(不卡你也会)...
\(2:\) 倍增大法
复杂度 预处理:\(O(nlog(n))\) 查询:\(O(log(n))\),有常数
算法核心:
\(1.\) 预处理\(fa[i][k]\):i上的第\(2^k\)个祖先(如果没有,记为\(-1\))
--- 预处理方法 \(O(n log(log(n)))\)
--- 递推式 \(fa[i][k]=fa[fa[i][k-1][k-1]\)
--- 外层接k的循环,内层接i的循环
void dfs(int u,int f) {
fa[u][0]=f;
for(reg int i=head[u]; i; i=nxt[i]) if(to[i]!=f) {
reg int &v=to[i],&w=x[i];
h[v]=h[u]+1;
dis[v]=dis[u]+w;
dfs(v,u);
}
}
void LCA_init() {
dfs(1,-1);
for(reg int j=0; j+1<L; j++)
for(reg int i=1; i<=n; i++) {
if(fa[i][j]<0)fa[i][j+1]=-1;
else fa[i][j+1]=fa[f[i][j]][j];
}
}
\(2.\)通过一种类似于二进制枚举的方法找爸爸,其原理与蜗牛爬式类似
--- \(step1:\)将x,y移动到同一深度
--- \(step2:\)枚举x,y的上层祖先,防止过度移动,倒着循环
int LCA(int x,int y) {
if(h[x]>h[y])swap(x,y);
int del=h[y]-h[x];
for(int i=0; (1<<i)<=del; i++)
if(del&(1<<i))
y=f[y][i];
if(x==y)return x;//这句话很关键,很容易忘,不加会过度
for(int i=ceil(log(h[x])); i>=0; i--)
if(fa[x][i]!=fa[y][i])
x=fa[x][i],y=fa[y][i];
return fa[x][0];
}优化\(1:\)预处理 $log[N] $数组
for(int i=2;i<=n;i++)
Log[i]=Log[i-1]+((1<<Log[i-1]+1)==i);优化\(2:\) \(dfs\)同时预处理 \(f[i][k]\) 数组
----因为深搜时根的数组会先被处理,不会调用到未处理的区域
void dfs(int u,int f) {
fa[u][0]=f;
for(int j=1;j<L;j++)
if(fa[u][j-1]<0)fa[u][j]=-1;
else fa[u][j]=fa[fa[u][j-1]][j-1];
for(reg int i=head[u]; i; i=nxt[i]) if(to[i]!=f) {
reg int &v=to[i],&w=x[i];
h[v]=h[u]+1;
dis[v]=dis[u]+w;
dfs(v,u);
}
}整体代码\(Show\)
#include<cstdio>
#include<cstring>
#include <algorithm>
#include<cmath>
using namespace std;
#define reg register
const int N=5e5+10,LN=23;
int n,m,L,st;
int f[N][LN],h[N];
int to[N<<1],head[N<<1],nxt[N<<1],cnt,Log[N];
#define add(u,v) nxt[++cnt]=head[u],head[u]=cnt,to[head[u]]=v
int rd() {
int s=0;
char x=getchar();
while(x<'0'||x>'9')x=getchar();
while(x>='0'&&x<='9')s=(s<<1)+(s<<3)+(x^'0'),x=getchar();
return s;
}
void dfs(int u,int fa) {
f[u][0]=fa;
for(int j=1;j<L;j++)
if(f[u][j-1]<0)f[u][j]=-1;
else f[u][j]=f[f[u][j-1]][j-1];
for(int i=head[u]; i; i=nxt[i]) if(to[i]!=fa) {
reg int &v=to[i];
h[v]=h[u]+1;
dfs(v,u);
}
}
void LCA_init() {
dfs(st,-1);
for(int i=2;i<=n;i++)
Log[i]=Log[i-1]+((1<<Log[i-1]+1)==i);
}
int LCA(int x,int y) {
if(h[x]>h[y])swap(x,y);
int del=h[y]-h[x];
for(int i=0; (1<<i)<=del; i++)
if(del&(1<<i))
y=f[y][i];
if(x==y)return x;
for(int i=Log[h[x]]+1; i>=0; i--)
if(f[x][i]!=f[y][i])
x=f[x][i],y=f[y][i];
return f[x][0];
}
int main() {
n=rd(),m=rd(),st=rd();
L=ceil(log(n));
for(int i=1,u,v,w; i<n; i++)
u=rd(),v=rd(),add(u,v),add(v,u);
LCA_init();
for(int i=1,a,b; i<=m; i++)
a=rd(),b=rd(),printf("%d\n",LCA(a,b));
}\(3.\)重链剖分
查询原理:与蜗牛爬类似
实际上,我们可以注意到蜗牛爬式大部分时间的浪费在一个个找上
而我们通过重链剖分使这个过程加快
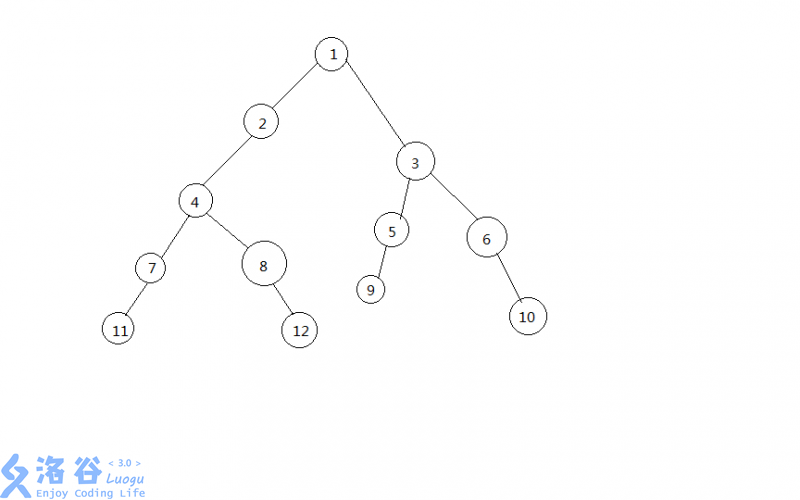
对于查询\(LCA(11,9)\),蜗牛爬式给出的过程是
11,9
7,9
4,5
2,3
1,1
1
一个个爬上去
事实上 \(11-7-4\)的过程可以化为\(11-4\)
同样的 \(4-2-1\) 化为\(4-1\) 等等
这条链越长,其中无用的部分越多,所以把一条条链分出来非常有必要
所以有了重链剖分,这是它的过程
11,9
4,9
4,3
4,1
1
过程简化了不少,当链越长,效果越好
算法核心:
维护\(size[N],son[N],top[N],fa[N],depth[N]\)数组
\(size[N]:\)这个子树的结点数量
\(son[N]:\)这个结点下最重的儿子
\(top[N]:\)这条链的顶端
\(fa[N]:\)这个结点的父亲
\(depth[N]:\)这个节点的深度
这个过程可以在两次深搜内解决
void dfs1(int u,int f) {
fa[u]=f;
son[u]=0,size[u]=1;
for(int i=head[u]; i; i=e[i].nxt) if(e[i].v!=f) {
int &v=e[i].v;
depth[v]=depth[u]+1;
dfs1(v,u);
if(size[son[u]]<size[v])son[u]=v;
size[u]+=size[v];
}
}这里处理了\(fa[N],son[N],size[N],depth[N]\)数组
也就是说,只剩\(top[N]\)了
void dfs2(int u,int t) {
top[u]=t;
if(son[u])dfs2(son[u],t);//把这一条链连到底,top都设成t
else return;//如果是叶节点就不用找了
for(int i=head[u]; i; i=e[i].nxt) {
int &v=e[i].v;
if(v==f[u]||v==son[u])continue;
dfs2(v,v);//对于其他的轻链,分开处理,以它自己为top
}
}查询部分:
int LCA(int x,int y) {
while(top[x]!=top[y]) {
if(depth[top[x]]>depth[top[y]])x=fa[top[x]];
else y=fa[top[y]];
}
return depth[x]<depth[y]?x:y;
}其实与蜗牛爬式类似,跳过了这条链上的移动过程
\(code\)整体\(Show\)
#include<cstdio>
#include<cstring>
#include<vector>
using namespace std;
#define add(__u,__v) e[++cnt].nxt=head[__u],e[head[__u]=cnt].v=__v
#define reg register
inline void rd(reg int &s){
s=0;
reg char x=getchar();
while(x<'0'||x>'9')x=getchar();
while(x>='0'&&x<='9')s=(s<<1)+(s<<3)+(x^'0'),x=getchar();
}
inline void wt(reg int x){
reg char buf[10]={0,0},l=0;
do buf[++l]=x%10;
while(x/=10);
if(!l)l=1;
for(;l;l--)putchar(buf[l]+'0');
}
const int N=1e5+10;
int n,m,st;
int fa[N],head[N<<1],cnt;
struct node {
int v,nxt;
} e[N<<1];
int depth[N],top[N],son[N],size[N];
void dfs1(int u,int f) {
fa[u]=f;
son[u]=0,size[u]=1;
for(int i=head[u]; i; i=e[i].nxt) if(e[i].v!=f) {
int &v=e[i].v;
depth[v]=depth[u]+1;
dfs1(v,u);
if(size[son[u]]<size[v])son[u]=v;
size[u]+=size[v];
}
}
void dfs2(int u,int t) {
top[u]=t;
if(son[u])dfs2(son[u],t);
else return;
for(int i=head[u]; i; i=e[i].nxt) {
int &v=e[i].v;
if(v==fa[u]||v==son[u])continue;
dfs2(v,v);
}
}
int LCA(int x,int y) {
while(top[x]!=top[y]) {
if(depth[top[x]]>depth[top[y]])x=fa[top[x]];
else y=fa[top[y]];
}
return depth[x]<depth[y]?x:y;
}
int main() {
scanf("%d%d%d",&n,&m,&st);
for(int i=1,u,v; i<n; i++)rd(u),rd(v),add(u,v),add(v,u);
dfs1(st,0),dfs2(st,st);
for(int i=1,a,b; i<=m; i++) rd(a),rd(b),wt(LCA(a,b)),putchar('\n');
}LCA的几种做法的更多相关文章
- Android布局居中的几种做法
Android的布局文件中,如果想让一个组件(布局或View)居中显示在另一个布局(组件)中,可以由这么几种做法: android:layout_gravity android:gravity and ...
- jqGrid中实现radiobutton的两种做法
http://blog.sina.com.cn/s/blog_4f925fc30102e27j.html jqGrid中实现radiobutton的两种做法 ------------------- ...
- SqlServer保留几位小数的两种做法
SqlServer保留几位小数的两种做法 数据库里的 float momey 类型,都会精确到多位小数.但有时候 我们不需要那么精确,例如,只精确到两位有效数字. 解决: 1. 使用 Round( ...
- [置顶]
echarts x轴文字显示不全(xAxis文字倾斜比较全面的3种做法值得推荐)
echarts x轴标签文字过多导致显示不全 如图: 解决办法1:xAxis.axisLabel 属性 axisLabel的类型是object ,主要作用是:坐标轴刻度标签的相关设置.(当然yAxis ...
- LVS+keepalived 的DR模式的两种做法
LVS DR模式搭建 准备工作 三台机器: dr:192.168.13.15 rs1:192.168.13.16 rs2: 192.168.13.17 vip:192.168.13.100 修改DR上 ...
- 代码:PC 链接列表面板border的一种做法(每行之间有分割线)
PC 链接列表面板,border的一种做法 做页面经常遇到一种问题,上面是标题,下面是单行链接列表.为了保证后台套页面方便,所有列表项必须完全一样.但我们无法解决第一行或最后一行多出来的分割线. 使用 ...
- .NET类型转型的四种做法(转)
.NET类型转型的四种做法: ◆ 强制转型:(int)变量名称 ◆ int.Parse(字符串变量名称) ◆ Convert.To类型(变量名称) ◆ TryParse 强制转型 (casting) ...
- Mediocre String Problem (2018南京M,回文+LCP 3×3=9种做法 %%%千年好题 感谢"Grunt"大佬的细心讲解)
layout: post title: Mediocre String Problem (2018南京M,回文+LCP 3×3=9种做法 %%%千年好题 感谢"Grunt"大佬的细 ...
- js函数只执行一次,函数重写,变量控制与闭包三种做法
一.情景需求 调用后台接口需要附带token信息,那么在每个请求的头部添加token的做法就不太优雅了:一个网站请求100次,那就得写添加100次token,假设某天接口有所变动,改起来就十分麻烦了. ...
随机推荐
- 一.B/S架构和C/S架构
1.B/S架构 Browser-Server, 浏览器和服务器架构.包含客户端浏览器.web应用服务器.数据库服务器的软件系统.用户只需要一个浏览器就可以访问服务.系统更新的时候,只需要更新服务端, ...
- 剑指Offer 总结
给一个链表,若其中包含环,请找出该链表的环的入口结点,否则,输出null. public class Solution { public ListNode EntryNodeOfLoop(ListNo ...
- 70.JS---利用原生js做手机端网页自适应解决方案rem布局
利用原生js做手机端网页自适应解决方案rem布局 刚开始我用的是下面这段代码,然后js通过外部链接引入,最后每次用手机刷新网页的时候都会出现缩略图 function getRem(pwidth, pr ...
- Android实现二维码扫描功能
1.效果预览 先上图展示效果(模拟器没有摄像头,录出来效果不好,将就看) 2.集成步骤 1.拷贝本项目demo中的com.google.zxing5个包引入到自己的项目中. 2.拷贝本项目demo中的 ...
- springboot设置访问端口和项目路径
找到,application.properties, 添加如下配置即可 server.port=8088server.servlet.context-path=/
- zabbix--自定义监控项vsftpd
Zabbix 自定义监控项之监控 vsftpd zabbix 提供了很多监控选择,功能丰富,我们还可以根据自定义来监控想要监控一些日常的服务等. 说明: 此处我们通过监控 ftp (自定义命令),实现 ...
- git merge origin master git merge origin/master区别
git merge origin master //将origin merge 到 master 上 git merge origin/master //将origin上的master分支 merge ...
- Explorer(2019年牛客多校第八场E题+线段树+可撤销并查集)
题目链接 传送门 题意 给你一张无向图,每条边\(u_i,v_i\)的权值范围为\([L_i,R_i]\),要经过这条边的条件是你的容量要在\([L_i,R_i]\),现在问你你有多少种容量使得你可以 ...
- 彻底理解 Cookie、Session、Token
发展史 1.很久很久以前,Web 基本上就是文档的浏览而已, 既然是浏览,作为服务器, 不需要记录谁在某一段时间里都浏览了什么文档,每次请求都是一个新的HTTP协议, 就是请求加响应, 尤其是我不用记 ...
- 如何显示隐藏的文件在win7系统中
点左下角“开始”菜单,再点击“计算机”. 点击窗口顶部靠左位置的“组织”菜单,选择其中的“文件夹和搜索选项”. 在弹出的窗口里点击切换到“查看”选项卡. 在窗口中部位置下拉滚动条,找到“显示隐藏的 ...