XLNet and Robertra
XLNET
But the AE language model also has its disadvantages. It uses the [MASK] in the pretraining, but this kind of artificial symbols are absent from the real data at finetuning time, resulting in a pretrain-finetune discrepancy.Another disadvantage of [MASK] is that it assumes the predicted (masked) tokens are independent of each other given the unmasked tokens. For example, we have a sentence "It shows that the housing crisis was turned into a banking crisis". We mask "banking" and "crisis". Attention here, we know the masked "banking" and "crisis" contains implicit relation to each other. But AE model is trying to predict "banking" given unmasked tokens, and predict "crisis" given unmasked tokens separately. It ignores the relation between "banking" and "crisis". In other words, it assumes the predicted (masked) tokens are independent of each other. But we know the model should learn such correlation among the predicted (masked) tokens to predict one of the tokens.
A traditional language model would predict the tokens in the order
"I", "like", "cats", "more", "than", "dogs"
where each token uses all previous tokens as context.
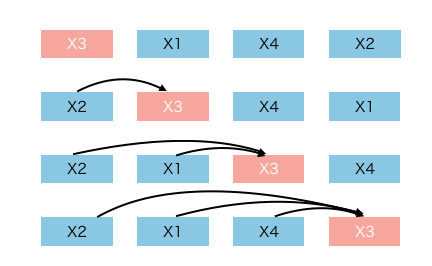
In permutation language modeling, the order of prediction is not necessarily left to right and is sampled randomly instead. For instance, it could be
"cats", "than", "I", "more", "dogs", "like"
where "than" would be conditioned on seeing "cats", "I" would be conditioned on seeing "cats, than" and so on. The following animation demonstrates this.
输入看上去仍然是x1,x2,x3,x4,可以通过不同的掩码矩阵,让当前单词Xi只能看到被排列组合后的顺序x3->x2->x4->x1中自己前面的单词


Robertra
与BERT的差别
Facebook的研究人员发现超参数选择对BERT的最终结果有重大影响,因此他们重新研究了BERT的预训练模型,测量了不同超参数和训练集大小的影响,结果发现BERT存在明显的训练不足。
经过调整后,BERT可以达到或超过其后发布的每个模型的性能,这些结果突出了之前被忽视的设计选择的重要性,
RoBERTa与BERT的不同之处在于,它依赖于预训练大量数据和改变训练数据的mask模式,而且RoBERTa删除了下一句预测(NSP)。
RoBERTa的修改很简单,包括:
- 更长时间的训练时间,更大的batch,更多的数据;
- 删除下一句预测(NSP)目标;
- 在较长序列上进行训练;
- 动态改变用于训练数据的mask模式。(The original BERT implementation performed masking once during data preprocessing, resulting in a single static mask. To avoid using the same mask for each training instance in every epoch, training data was duplicated 10 times so that each sequence is masked in 10 different ways over the 40 epochs of training. Thus, each training sequence was seen with the same mask four times during training.)
参考:
https://zhuanlan.zhihu.com/p/75856238
https://towardsdatascience.com/what-is-xlnet-and-why-it-outperforms-bert-8d8fce710335
https://zhuanlan.zhihu.com/p/70257427
XLNet and Robertra的更多相关文章
- XLNet预训练模型,看这篇就够了!(代码实现)
1. 什么是XLNet XLNet 是一个类似 BERT 的模型,而不是完全不同的模型.总之,XLNet是一种通用的自回归预训练方法.它是CMU和Google Brain团队在2019年6月份发布的模 ...
- 百度ERNIE 2.0强势发布!16项中英文任务表现超越BERT和XLNet
2019年3月,百度正式发布NLP模型ERNIE,其在中文任务中全面超越BERT一度引发业界广泛关注和探讨. 今天,经过短短几个月时间,百度ERNIE再升级.发布持续学习的语义理解框架ERNIE 2. ...
- NLP中的预训练语言模型(三)—— XL-Net和Transformer-XL
本篇带来XL-Net和它的基础结构Transformer-XL.在讲解XL-Net之前需要先了解Transformer-XL,Transformer-XL不属于预训练模型范畴,而是Transforme ...
- XLNet原理探究
1. 前言 XLNet原文链接是CMU与谷歌大脑提出的全新NLP模型,在20个任务上超过了BERT的表现,并在18个任务上取得了当前最佳效果,包括机器问答.自然语言推断.情感分析和文档排序. 这篇新论 ...
- BERT、ERNIE以及XLNet学习记录
主要是对 BERT: Pre-training of Deep Bidirectional Transformers for Language Understandingtichu提出的BERT 清华 ...
- 自然语言处理(三) 预训练模型:XLNet 和他的先辈们
预训练模型 在CV中,预训练模型如ImagNet取得很大的成功,而在NLP中之前一直没有一个可以承担此角色的模型,目前,预训练模型如雨后春笋,是当今NLP领域最热的研究领域之一. 预训练模型属于迁移学 ...
- Transformer 和 Transformer-XL——从基础框架理解BERT与XLNet
目录写在前面1. Transformer1.1 从哪里来?1.2 有什么不同?1.2.1 Scaled Dot-Product Attention1.2.2 Multi-Head Attention1 ...
- XLNet:运行机制及和Bert的异同比较
这两天,XLNet貌似也引起了NLP圈的极大关注,从实验数据看,在某些场景下,确实XLNet相对Bert有很大幅度的提升.就像我们之前说的,感觉Bert打开两阶段模式的魔法盒开关后,在这条路上,会有越 ...
- 3分钟了解GPT Bert与XLNet的差异
译者 | Arno 来源 | Medium XLNet是一种新的预训练模型,在20项任务中表现优于BERT,且有大幅度的提升. 这是什么原因呢? 在不了解机器学习的情况下,不难估计我们捕获的上下文越多 ...
随机推荐
- 公司框架-关于verifyInputgbg()方法的使用注意事项
verifyInputgbg这个方法的主要作用是:一次校验页面上的所有非空的比录项. 今天在使用这个方法的时候,遇到了这样一个问题,自己在页面上明明都录入有值,但是在还是报页面的录入信息不完整.阻断. ...
- js的类型系统--js基于原型的基石是所有对象最终都能够类型自证
一.动态类型 变量能够类型自证的类型即为动态类型 二.基础与内置类型 三.对象与类型的关系 1.对象本身能够自证为基本类型: 2.元原型可能为一个空的集合: 3.复合对象的成员能够自证为基本类型: 4 ...
- MongoDB的安装、基本操作
此说明文档针对的community版本是v4.2.0(1)下载下载官网,此时的community版本是v4.2.0https://www.mongodb.com/download-center/com ...
- 使用plotly dash-component-boilerplate 生成自己的组件
plotly 基于dash-component-boilerplate给我们提供了可以快速生成基于使用python 调用的react 组件 以下是一个简单的使用脚手架生成一个组件,同时可以了解组件的工 ...
- 第五届新疆ACM H-虚无的后缀
来源 第五届新疆省ACM-ICPC程序设计竞赛nowcoder重现赛 H-虚无的后缀 思路1 好菜哦. 首先后缀零的个数最多,我们只需要考虑他的质因子2和5的个数就行了(存为a,b). 因为其他因子对 ...
- Note_3.31
2019/4/1 奇奇怪怪的笔记 整理了一些之前没有写过的东西,把它们拼在一起,并没有什么逻辑可言qwq FWT快速沃尔什变换 \[ FWT(A)=merge(FWT(A0),FWT(A0+A1)) ...
- jmeter(五十一)_性能测试中的服务器资源监控与分析
概述 性能测试过程中,对服务器资源的监控是必不可少的.这里的资源又分了两块,windows和linux linux下监控资源 访问网址http://jmeter-plugins.org/downl ...
- [技术博客]使用adb命令获取app(游戏)错误和警告日志
adb命令的使用 直接在命令行中输入: adb logcat *:W 注意:这句命令的意思是显示所有优先级大于等于警告(Warning)的日志,查找崩溃问题一般用: adb logcat *:E 注意 ...
- 【转】聊聊并发(一)——深入分析Volatile的实现原理
即两个或多个进程读写某些共享数据,而最后的结果取决于进程运行的精确时序,称为竞争条件(race condition). 引言 在多线程并发编程中synchronized和Volatile都扮演着重要的 ...
- Java编程思想之四控制执行流程
程序必须再执行过程中控制它的世界,并做出选择.在Java中,你要使用执行控制语句来做出选择. 4.1true和false 所有条件语句都利用条件表达式的真或假来决定执行路径. Java不允许使用数字作 ...