大数据之路【第十二篇】:数据挖掘--NLP文本相似度
一、词频----TF
• 假设:如果一个词很重要,应该会在文章中多次出现
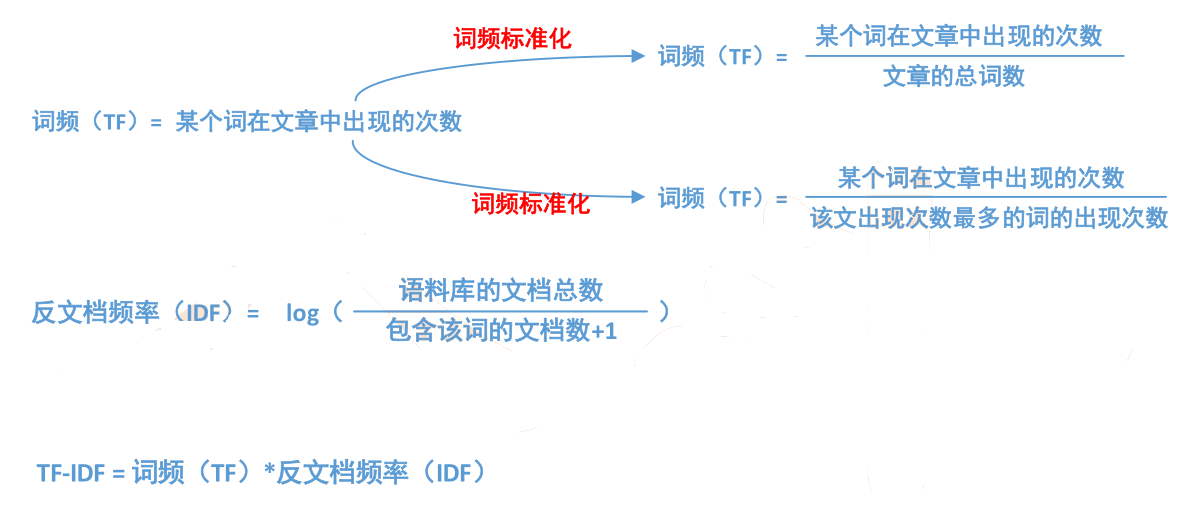
• 词频——TF(Term Frequency):一个词在文章中出现的次数
• 也不是绝对的!出现次数最多的是“的”“是”“在”,这类最常用的词,叫做停用词(stop words)
• 停用词对结果毫无帮助,必须过滤掉的词
• 过滤掉停用词后就一定能接近问题么?
• 进一步调整假设:如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能反映了这篇文章的特性,正是我们所需要的关键词
二、反文档频率----IDF
• 在词频的基础上,赋予每一个词的权重,进一步体现该词的重要性,
• 最常见的词(“的”、“是”、“在”)给予最小的权重
• 较常见的词(“国内”、“中国”、“报道”)给予较小的权重
• 较少见的词(“养殖”、“维基”)
• 将TF和IDF进行相乘,就得到了一个词的TF-IDF值,某个词对文章重要性越高,该值越大,于是排在前面的几个词,就是这篇文章的关键词。
计算步骤
三、LCS定义
• 最长公共子序列(Longest Common Subsequence)
• 一个序列S任意删除若干个字符得到的新序列T,则T叫做S的子序列
• 两个序列X和Y的公共子序列中,长度最长的那个,定义为X和Y的最长公共子序列
– 字符串12455与245576的最长公共子序列为2455
– 字符串acdfg与adfc的最长公共子序列为adf
• 注意区别最长公共子串(Longest Common Substring)
– 最长公共子串要求连接
四、LCS作用
• 求两个序列中最长的公共子序列算法
– 生物学家常利用该算法进行基金序列比对,以推测序列的结构、功能和演化过程。
• 描述两段文字之间的“相似度”
– 辨别抄袭,对一段文字进行修改之后,计算改动前后文字的最长公共子序列,将除此子序列
外的部分提取出来,该方法判断修改的部分
五、求解---暴力穷举法
• 假定字符串X,Y的长度分别为m,n;
• X的一个子序列即下标序列{1,2,……,m}严格递增子序列,因此,X共有2^m 个不同子序列;同理,Y有2^n 个不同子序列;
• 穷举搜索法时间复杂度O(2 ^m ∗ 2^n );
• 对X的每一个子序列,检查它是否也是Y的子序列,从而确定它是否为X和Y的公共子序列,并且在检查过程中选出最长的公共子序列;
• 复杂度高,不可用!
六、求解---动态规划法
• 字符串X,长度为m,从1开始数;
• 字符串Y,长度为n,从1开始数;
• X i =<x 1 ,……,x i >即X序列的前i个字符(1<=i<=m)(X i 计作“字符串X的i前缀”)
• Y i =<y 1 ,……,y i >即Y序列的前i个字符(1<=j<=n)(Y j 计作“字符串Y的j前缀”)
• LCS(X,Y)为字符串X和Y的最长公共子序列,即为Z=<z 1 ,……,z k >
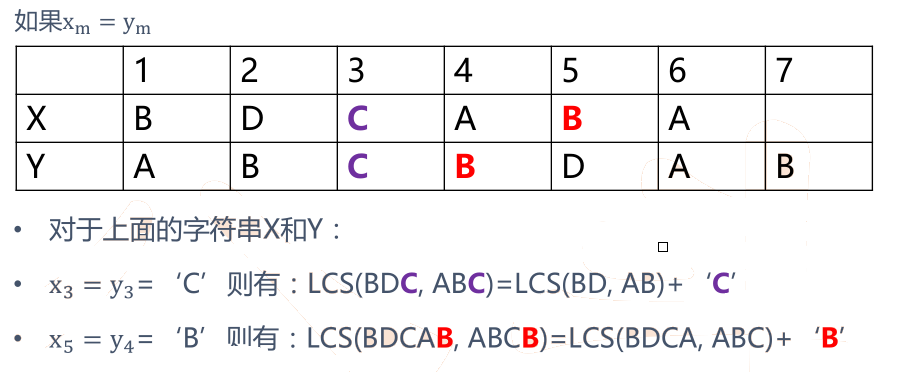
• 如果x m = y n (最后一个字符相同),则:X ? 与Y n 的最长公共子序列Z k 的最后一个字符必定为x m (= y n )
• Zk= x m = y n
七、LCS总结分析
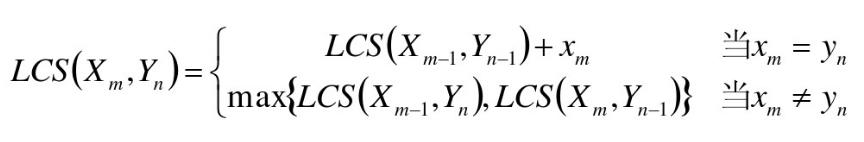
• 属于动态规划问题!
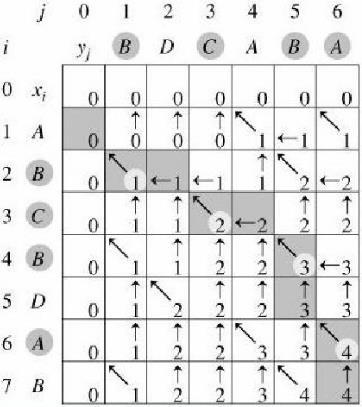
八、数据结构----二维数组
• 使用二维数组C[m,n]
• C[i,j]记录序列X i 和Y j 的最长公共子序列的长度
– 当i=0或j=0时,空虚了是X i 和Y j 的最长公共子序列,故C[i,j]=0
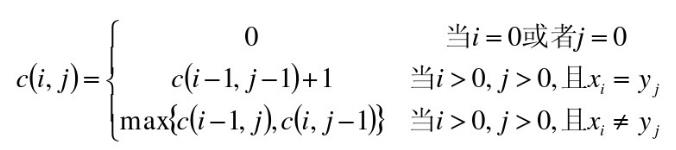
例子:
• X =<A, B, C, B, D, A, B>
• Y=<B, D, C, A, B, A>
mr_lcs mapreduce
##map.py # -*- coding: utf-8 -*-
#!/usr/bin/python import sys def cal_lcs_sim(first_str, second_str):
len_vv = [[0] * 50] * 50 first_str = unicode(first_str, "utf-8", errors='ignore')
second_str = unicode(second_str, "utf-8", errors='ignore') len_1 = len(first_str.strip())
len_2 = len(second_str.strip()) #for a in first_str:
#word = a.encode('utf-8') for i in range(1, len_1 + 1):
for j in range(1, len_2 + 1):
if first_str[i - 1] == second_str[j - 1]:
len_vv[i][j] = 1 + len_vv[i - 1][j - 1]
else:
len_vv[i][j] = max(len_vv[i - 1][j], len_vv[i][j - 1]) return float(float(len_vv[len_1][len_2] * 2) / float(len_1 + len_2)) for line in sys.stdin:
ss = line.strip().split('\t')
if len(ss) != 2:
continue
first_str = ss[0].strip()
second_str = ss[1].strip() sim_score = cal_lcs_sim(first_str, second_str)
print '\t'.join([first_str, second_str, str(sim_score)])
#run.sh HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" INPUT_FILE_PATH_1="/lcs_input.data"
OUTPUT_PATH="/lcs_output" $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH # Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_1 \
-output $OUTPUT_PATH \
-mapper "python map.py" \
-jobconf "mapred.reduce.tasks=0" \
-jobconf "mapred.job.name=mr_lcs" \
-file ./map.py
mr_tfidf mapreduce
##red.py
#!/usr/bin/python import sys
import math current_word = None
count_pool = []
sum = 0 docs_cnt = 508 for line in sys.stdin:
ss = line.strip().split('\t')
if len(ss) != 2:
continue word, val = ss if current_word == None:
current_word = word if current_word != word:
for count in count_pool:
sum += count
idf_score = math.log(float(docs_cnt) / (float(sum) + 1))
print "%s\t%s" % (current_word, idf_score) current_word = word
count_pool = []
sum = 0 count_pool.append(int(val)) for count in count_pool:
sum += count
idf_score = math.log(float(docs_cnt) / (float(sum) + 1))
print "%s\t%s" % (current_word, idf_score)
##run.sh HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" INPUT_FILE_PATH_1="/tfidf_input.data"
OUTPUT_PATH="/tfidf_output" $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH # Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_1 \
-output $OUTPUT_PATH \
-mapper "python map.py" \
-reducer "python red.py" \
-file ./map.py \
-file ./red.py
大数据之路【第十二篇】:数据挖掘--NLP文本相似度的更多相关文章
- Python之路(第二十二篇) 面向对象初级:概念、类属性
一.面向对象概念 1. "面向对象(OOP)"是什么? 简单点说,“面向对象”是一种编程范式,而编程范式是按照不同的编程特点总结出来的编程方式.俗话说,条条大路通罗马,也就说我们使 ...
- Spark项目之电商用户行为分析大数据平台之(十二)Spark上下文构建及模拟数据生成
一.模拟生成数据 package com.bw.test; import java.util.ArrayList; import java.util.Arrays; import java.util. ...
- Python之路(第十二篇)程序解耦、模块介绍\导入\安装、包
一.程序解耦 解耦总的一句话来说,减少依赖,抽象业务和逻辑,让各个功能实现独立. 直观理解“解耦”,就是我可以替换某个模块,对原来系统的功能不造成影响.是两个东西原来互相影响,现在让他们独立发展:核心 ...
- Vue学习之路第十二篇:为页面元素设置内联样式
1.有了上一篇的基础,接下来理解内联样式的设置会更简单一点,先看正常的css内联样式: <dvi id="app"> <p style="font-si ...
- 大数据笔记(三十二)——SparkStreaming集成Kafka与Flume
三.集成:数据源 1.Apache Kafka:一种高吞吐量的分布式发布订阅消息系统 (1) (*)消息的类型 Topic:主题(相当于:广播) Queue:队列(相当于:点对点) (*)常见的消息系 ...
- Python之路【第十二篇】:JavaScrpt -暂无内容-待更新
Python之路[第十二篇]:JavaScrpt -暂无内容-待更新
- Python开发【第二十二篇】:Web框架之Django【进阶】
Python开发[第二十二篇]:Web框架之Django[进阶] 猛击这里:http://www.cnblogs.com/wupeiqi/articles/5246483.html 博客园 首页 ...
- 跟我学SpringCloud | 第十二篇:Spring Cloud Gateway初探
SpringCloud系列教程 | 第十二篇:Spring Cloud Gateway初探 Springboot: 2.1.6.RELEASE SpringCloud: Greenwich.SR1 如 ...
- 解剖SQLSERVER 第十二篇 OrcaMDF 行压缩支持(译)
解剖SQLSERVER 第十二篇 OrcaMDF 行压缩支持(译) http://improve.dk/orcamdf-row-compression-support/ 在这两个月的断断续续的开发 ...
随机推荐
- memset使用技巧
memset可以对高位数组进行初始化,非常方便.需要注意的是memset的头文件是string.h和memory.h . 下面来谈memset的4个使用技巧: (注:一下dp高维数组都是全局变量,局部 ...
- Python逆向(二)—— pyc文件结构分析
一.前言 上一节我们知道了pyc文件是python在编译过程中出现的主要中间过程文件.pyc文件是二进制的,可以由python虚拟机直接执行的程序.分析pyc文件的文件结构对于实现python编译与反 ...
- 使用adb连接Mumu模拟器
1)下载Mumu模拟器 2)运行Mumu模拟器 3)找到mumu安装目录下的MuMu\emulator\nemu\vmonitor\bin目录 4)在当前目录打开cmd,执行 adb connect ...
- 新款戴尔笔记本win10系统改win7 安装教程
下载U盘启动制作工具 及戴尔DELL ghost win7 旗舰版GHO 文件 下载地址:http://pan.baidu.com/s/1c17JqpU 插入制作好的U盘启动盘,开机按F2进入BIO ...
- prometheus(docker)安装和报警 -- nginx域名监控
软件组件:prometheusalertmanagerprometheus-webhook-dingtalk nginx-vts-exporternginx (###--add-module=../n ...
- Re3 : Real-Time Recurrent Regression Networks for Visual Tracking of Generic Objects
Re3 : Real-Time Recurrent Regression Networks for Visual Tracking of Generic Objects 2019-10-04 14:4 ...
- 数码视讯Q7的刷机
Q7的硬件配置 CPU: S905LRAM: MIRA P3P4GF4DMF DDR3 512MB * 2 = 1GBROM: 镁光29F64G08CBABB * 1 = 8GBWIFI: RTL81 ...
- HikariCP连接池配置
官网: https://github.com/brettwooldridge/HikariCP HikariCP现在已经是spring-boot-starter-jdbc中自带的默认连接池,在我们的生 ...
- 几个简单易用的IDEA快捷键
常见的几个Idea的代码快捷键 格式化代码: Ctrl + Alt + L Optimize Imports(优化包引用): Ctrl-Alt-O 单行注释(//): Ctrl-/ 块注释(/*... ...
- Android NDK编译选项设置
Android NDK编译选项设置 网易加固关注 0.5472016.08.22 14:07:00字数 3,034阅读 6,805 在Android NDK开发中,有两个重要的文件:Android.m ...