java面试题——高级篇
一、集合
Hashmap的原理
源码分析参考文章:http://www.cnblogs.com/xwdreamer/archive/2012/06/03/2532832.html
题目参考文章:http://www.importnew.com/7099.html
总结:
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。
HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。
当两个不同的键对象的hashcode相同时会发生什么? 它们会储存在同一个bucket位置的链表中。键对象的equals()方法用来找到键值对。
面试时可能会问到的问题:
1.“你用过HashMap吗?” “什么是HashMap?你为什么用到它?”
用过,HashMap是基于哈希表的Map接口的非同步实现(Hashtable跟HashMap很像,唯一的区别是Hashtalbe中的方法是线程安全的,也就是同步的)。此实现提供所有可选的映射操作,并允许使用null键和null值。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
2.“你知道HashMap的工作原理吗?” “你知道HashMap的get()方法的工作原理吗?
答案:HashMap是基于hashing的原理,我们使用put(key, value)存储对象到HashMap中,使用get(key)从HashMap中获取对象。当我们给put()方法传递键和值时,我们先对键调用hashCode()方法,返回的hashCode用于找到bucket位置来储存Entry对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。
解释:这里关键点在于指出,HashMap是在bucket中储存键对象和值对象,作为Map.Entry。这一点有助于理解获取对象的逻辑。如果你没有意识到这一点,或者错误的认为仅仅只在bucket中存储值的话,你将不会回答如何从HashMap中获取对象的逻辑。这个答案相当的正确,也显示出面试者确实知道hashing以及HashMap的工作原理
3.当两个对象的hashcode相同会发生什么
答案:因为hashcode相同,所以它们的bucket位置相同,‘碰撞’会发生。因为HashMap使用链表存储对象,这个Entry(包含有键值对的Map.Entry对象)会存储在链表中。
解释:这个答案非常的合理,虽然有很多种处理碰撞的方法,这种方法是最简单的,也正是HashMap的处理方法。
4.如果两个键的hashcode相同,你如何获取值对象?
答案:当我们调用get(k)方法,HashMap会使用键对象的hashcode找到bucket位置,找到bucket位置之后,会调用keys.equals()方法去找到链表中正确的节点,最终找到要找的值对象。
解释:许多情况下,面试者会在这个环节中出错,因为他们混淆了hashCode()和equals()方法。因为在此之前hashCode()屡屡出现,而equals()方法仅仅在获取值对象的时候才出现。一些优秀的开发者会指出使用不可变的、声明作final的对象,并且采用合适的equals()和hashCode()方法的话,将会减少碰撞的发生,提高效率。不可变性使得能够缓存不同键的hashcode,这将提高整个获取对象的速度,使用String,Interger这样的wrapper类作为键是非常好的选择。
5.如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?
答案:默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。
解释:除非你真正知道HashMap的工作原理,否则你将回答不出这道题。
6.你了解重新调整HashMap大小存在什么问题吗?
答案:当重新调整HashMap大小的时候,确实存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。
解释:你可能回答不上来,这时面试官会提醒你当多线程的情况下,可能产生条件竞争(race condition)。
7.为什么String, Interger这样的wrapper类适合作为键?
答案:String, Interger这样的wrapper类作为HashMap的键是再适合不过了,而且String最为常用。因为String是不可变的,也是final的,而且已经重写了equals()和hashCode()方法了。其他的wrapper类也有这个特点。不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。不可变性还有其他的优点如线程安全。如果你可以仅仅通过将某个field声明成final就能保证hashCode是不变的,那么请这么做吧。因为获取对象的时候要用到equals()和hashCode()方法,那么键对象正确的重写这两个方法是非常重要的。如果两个不相等的对象返回不同的hashcode的话,那么碰撞的几率就会小些,这样就能提高HashMap的性能。
8.我们可以使用自定义的对象作为键吗?
答案:这是前一个问题的延伸。当然你可能使用任何对象作为键,只要它遵守了equals()和hashCode()方法的定义规则,并且当对象插入到Map中之后将不会再改变了。如果这个自定义对象时不可变的,那么它已经满足了作为键的条件,因为当它创建之后就已经不能改变了。
9.我们可以使用CocurrentHashMap来代替Hashtable吗?
答案:这是另外一个很热门的面试题,因为ConcurrentHashMap越来越多人用了。我们知道Hashtable是synchronized的,但是ConcurrentHashMap同步性能更好,因为它仅仅根据同步级别对map的一部分进行上锁。ConcurrentHashMap当然可以代替HashTable,但是HashTable提供更强的线程安全性
10.Hashmap为什么大小是2的幂次
答案:为了hash的平均分布,减少碰撞值
11.什么是HashMap的加载因子
答案:加载因子是表示Hsah表中元素的填满的程度.若:加载因子越大,填满的元素越多,好处是,空间利用率高了,但:冲突的机会加大了.反之,加载因子越小,填满的元素越少,好处是:冲突的机会减小了,但:空间浪费多了.
Arraylist的原理
源码分析参考文章:http://www.importnew.com/19867.html
问题参考文章:http://www.importnew.com/9928.html
ArrayList是基于数组实现的,是一个动态数组,其容量能自动增长,类似于C语言中的动态申请内存,动态增长内存。
ArrayList不是线程安全的,只能用在单线程环境下,多线程环境下可以考虑用Collections.synchronizedList(List l)函数返回一个线程安全的ArrayList类,也可以使用concurrent并发包下的CopyOnWriteArrayList类。
ArrayList实现了Serializable接口,因此它支持序列化,能够通过序列化传输,实现了RandomAccess接口,支持快速随机访问,实际上就是通过下标序号进行快速访问,实现了Cloneable接口,能被克隆。
1、ArrayList的大小是如何自动增加的?你能分享一下你的代码吗?
答案:当有人试图在arraylist中增加一个对象的时候,Java会去检查arraylist,以确保已存在的数组中有足够的容量来存储这个新的对象。如果没有足够容量的话,那么就会新建一个长度更长的数组,旧的数组就会使用Arrays.copyOf方法被复制到新的数组中去,现有的数组引用指向了新的数组
源码:
//ArrayList Add方法:
public boolean add(E e){
ensureCapacity(size+1); //Increment modCount!!
elementData[size++] = e;
return true;
} //ensureCapacity方法:处理ArrayList的大小
public void ensureCapacity(int minCapacity) {
modCount++;
int oldCapacity = elementData.length;
if (minCapacity > oldCapacity) {
Object oldData[] = elementData;
int newCapacity = (oldCapacity * 3)/2 + 1;
if (newCapacity < minCapacity)
newCapacity = minCapacity;
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
}
解释:请注意这样一个情况:新建了一个数组;旧数组的对象被复制到了新的数组中,并且现有的数组指向新的数组。
2、什么情况下你会使用ArrayList?什么时候你会选择LinkedList?
答案:访问元素比插入或者是删除元素更加频繁的时候,你应该使用ArrayList。当你在某个特别的索引中,插入或者是删除元素更加频繁,或者你压根就不需要访问元素的时候,你会选择LinkedList。
这里的主要原因是,在ArrayList中访问元素的最糟糕的时间复杂度是”1″,而在LinkedList中可能就是”n”了。在ArrayList中增加或者删除某个元素,通常会调用System.arraycopy方法,这是一种极为消耗资源的操作,因此,在频繁的插入或者是删除元素的情况下,LinkedList的性能会更加好一点。
3、当传递ArrayList到某个方法中,或者某个方法返回ArrayList,什么时候要考虑安全隐患?如何修复安全违规这个问题呢?
答案:
当array被当做参数传递到某个方法中,如果array在没有被复制的情况下直接被分配给了成员变量,那么就可能发生这种情况,即当原始的数组被调用的方法改变的时候,传递到这个方法中的数组也会改变。下面的这段代码展示的就是安全违规以及如何修复这个问题。
ArrayList被直接赋给成员变量——安全隐患:

修复这个安全隐患:

4、如何复制某个ArrayList到另一个ArrayList中去?写出你的代码?
答案:下面就是把某个ArrayList复制到另一个ArrayList中去的几种技术:
- 使用clone()方法,比如ArrayList newArray = oldArray.clone();
- 使用ArrayList构造方法,比如:ArrayList myObject = new ArrayList(myTempObject);
- 使用Collection的copy方法。
注意1和2是浅拷贝(shallow copy)。
5、在索引中ArrayList的增加或者删除某个对象的运行过程?效率很低吗?解释一下为什么?
答案:在ArrayList中增加或者是删除元素,要调用System.arraycopy这种效率很低的操作,如果遇到了需要频繁插入或者是删除的时候,你可以选择其他的Java集合,比如LinkedList。
看一下下面的代码:
在ArrayList的某个索引i处添加元素:

删除ArrayList的某个索引i处的元素:

二、java虚拟机
native关键字
修饰方法表示这个方法是本地方法,即虚拟机的底层C程序,如线程Thread的start方法调用的start0()方法就是一个本地方法
java内存模型
什么是类的加载
类的加载指的是将类的.class文件中的二进制数据读入到内存中,将其放在运行时数据区的方法区内,然后在堆区创建一个java.lang.Class对象,用来封装类在方法区内的数据结构。类的加载的最终产品是位于堆区中的Class对象,Class对象封装了类在方法区内的数据结构,并且向Java程序员提供了访问方法区内的数据结构的接口。
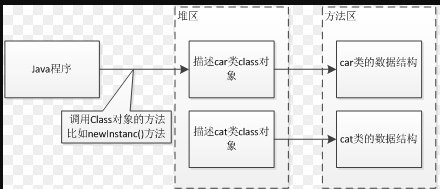
类加载器并不需要等到某个类被“首次主动使用”时再加载它,JVM规范允许类加载器在预料某个类将要被使用时就预先加载它,如果在预先加载的过程中遇到了.class文件缺失或存在错误,类加载器必须在程序首次主动使用该类时才报告错误(LinkageError错误)如果这个类一直没有被程序主动使用,那么类加载器就不会报告错误
从更高的一个维度再次来看JVM和系统调用之间的关系
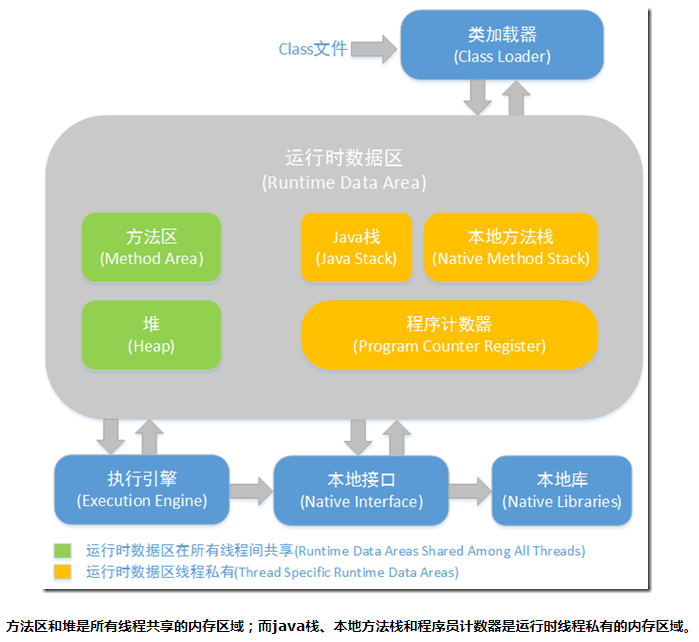
JVM内存结构主要有三大块:堆内存、方法区和栈。堆内存是JVM中最大的一块由年轻代和老年代组成,而年轻代内存又被分成三部分,Eden空间、From Survivor空间、To Survivor空间,默认情况下年轻代按照8:1:1的比例来分配;
方法区存储类信息、常量、静态变量等数据,是线程共享的区域,为与Java堆区分,方法区还有一个别名Non-Heap(非堆);栈又分为java虚拟机栈和本地方法栈主要用于方法的执行。
通过一张图来了解如何通过参数来控制各区域的内存大小

控制参数
-Xms设置堆的最小空间大小。
-Xmx设置堆的最大空间大小。
-XX:NewSize设置新生代最小空间大小。
-XX:MaxNewSize设置新生代最大空间大小。
-XX:PermSize设置永久代最小空间大小。
-XX:MaxPermSize设置永久代最大空间大小。
-Xss设置每个线程的堆栈大小。
没有直接设置老年代的参数,但是可以设置堆空间大小和新生代空间大小两个参数来间接控制。老年代空间大小=堆空间大小-年轻代大空间大小
什么时候触发垃圾回收
1.当程序在新生代申请内存失败时会触发垃圾回收,回收的过程:把eden区还存活的对象放到S1(幸存区1),如果S1已结满了就把S1还存活的对象放到S2(幸存区2),S2满了就把幸存的对象放到老年代,老年代满了就把幸存的对象放到持久代
2.当老年代或者持久代内存满了就触发full gc,在代码里面显示的使用System.gc()也会触发full gc,full gc会使应用程序变得很慢,所以要尽量避免full gc,jvm调优的本质就是减少full gc
三、BIO、NIO、AIO
BIO:blocking IO,阻塞IO
NIO:non-blocking IO,非阻塞IO,为所有的原始类型(boolean类型除外)提供缓存支持的数据容器,使用它可以提供非阻塞式的高伸缩性网络。
AIO:asynchronous-non-blocking IO:异步非阻塞IO
1.基本概念引入
同步:用户触发IO操作,你发起了请求就得等着对方给你返回结果,你不能走,针对调用方的,你发起了请求你等
异步:触发触发了IO操作,即发起了请求以后可以做自己的事,等处理完以后会给你返回处理完成的标志,针对调用方的,你发起了请求你不等
阻塞:你调用我,我试图对文件进行读写的时候发现没有可读写的文件,我的程序就会进入等待状态,等可以读写了,我处理完给你返回结果,这里的等待和同步的等待有很大的区别,针对服务提供方的,你调用我我发现服务不可用我等
非阻塞:你调用我,我试图对文件读写的时候发现没有读写的文件,不等待直接返回,等我发现可以读写文件处理完了再给你返回成功标志,针对服务提供方的,你调用我我不等,我处理完了给你返回结果
四、数据库
乐观锁和悲观锁
乐观锁:
乐观锁( Optimistic Locking ) 相对悲观锁而言,乐观锁假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让返回用户错误的信息,让用户决定如何去做
相对于悲观锁,在对数据库进行处理的时候,乐观锁并不会使用数据库提供的锁机制。一般的实现乐观锁的方式就是记录数据版本。
实现数据版本有两种方式,第一种是使用版本号,第二种是使用时间戳。
备注:
数据版本,为数据增加的一个版本标识。当读取数据时,将版本标识的值一同读出,数据每更新一次,同时对版本标识进行更新。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的版本标识进行比对,如果数据库表当前版本号与第一次取出来的版本标识值相等,则予以更新,否则认为是过期数据。
使用版本号实现乐观锁
使用版本号时,可以在数据初始化时指定一个版本号,每次对数据的更新操作都对版本号执行+1操作。并判断当前版本号是不是该数据的最新的版本号。
1.查询出商品信息
select (status,status,version) from t_goods where id=#{id}
2.根据商品信息生成订单
3.修改商品status为2
update t_goods
set status=2,version=version+1
where id=#{id} and version=#{version};
乐观锁优点与不足
乐观并发控制相信事务之间的数据竞争(data race)的概率是比较小的,因此尽可能直接做下去,直到提交的时候才去锁定,所以不会产生任何锁和死锁。但如果直接简单这么做,还是有可能会遇到不可预期的结果,例如两个事务都读取了数据库的某一行,经过修改以后写回数据库,这时就遇到了问题。
悲观锁:
悲观锁,正如其名,它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度(悲观),因此,在整个数据处理过程中,将数据处于锁定状态。 悲观锁的实现,往往依靠数据库提供的锁机制 (也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)
在数据库中,悲观锁的流程如下:
在对任意记录进行修改前,先尝试为该记录加上排他锁(exclusive locking)。
如果加锁失败,说明该记录正在被修改,那么当前查询可能要等待或者抛出异常。 具体响应方式由开发者根据实际需要决定。
如果成功加锁,那么就可以对记录做修改,事务完成后就会解锁了。
其间如果有其他对该记录做修改或加排他锁的操作,都会等待我们解锁或直接抛出异常。
在查询语句后面增加LOCK IN SHARE MODE,Mysql会对查询结果中的每行都加共享锁,当没有其他线程对查询结果集中的任何一行使用排他锁时,可以成功申请共享锁,否则会被阻塞。其他线程也可以读取使用了共享锁的表,而且这些线程读取的是同一个版本的数据。
MySQL InnoDB中使用悲观锁
要使用悲观锁,我们必须关闭mysql数据库的自动提交属性,因为MySQL默认使用autocommit模式,也就是说,当你执行一个更新操作后,MySQL会立刻将结果进行提交。set autocommit=0;
//0.开始事务
begin;/begin work;/start transaction; (三者选一就可以)
//1.查询出商品信息
select status from t_goods where id=1 for update;
//2.根据商品信息生成订单
insert into t_orders (id,goods_id) values (null,1);
//3.修改商品status为2
update t_goods set status=2;
//4.提交事务
commit;/commit work;
悲观锁优点与不足
悲观并发控制实际上是“先取锁再访问”的保守策略,为数据处理的安全提供了保证。但是在效率方面,处理加锁的机制会让数据库产生额外的开销,还有增加产生死锁的机会;另外,在只读型事务处理中由于不会产生冲突,也没必要使用锁,这样做只能增加系统负载;还有会降低了并行性,一个事务如果锁定了某行数据,其他事务就必须等待该事务处理完才可以处理那行数
知识拓展:
1.排他锁
排他锁又称写锁,如果事务T对数据A加上排他锁后,则其他事务不能再对A加任任何类型的封锁。获准排他锁的事务既能读数据,又能修改数据。
用法:
SELECT ... FOR UPDATE;
在查询语句后面增加FOR UPDATE,Mysql会对查询结果中的每行都加排他锁,当没有其他线程对查询结果集中的任何一行使用排他锁时,可以成功申请排他锁,否则会被阻塞。
2. 共享锁
共享锁又称读锁,是读取操作创建的锁。其他用户可以并发读取数据,但任何事务都不能对数据进行修改(获取数据上的排他锁),直到已释放所有共享锁。
如果事务T对数据A加上共享锁后,则其他事务只能对A再加共享锁,不能加排他锁。获准共享锁的事务只能读数据,不能修改数据。
用法:
SELECT ... LOCK IN SHARE MODE;
在查询语句后面增加LOCK IN SHARE MODE,Mysql会对查询结果中的每行都加共享锁,当没有其他线程对查询结果集中的任何一行使用排他锁时,可以成功申请共享锁,否则会被阻塞。其他线程也可以读取使用了共享锁的表,而且这些线程读取的是同一个版本的数据。
乐观锁:修改数据库记录前,给数据库的记录加上一个版本号version,修改时把版本号加1,两个人如果同时修改数据,第一个人已经把version加1了,第二个人就不能再修改了,并发数比较少时用数据库的乐观锁和悲观锁即可满足需求,并发数比较大时就redis的队列来解决
五、服务间的通信
webservice对应的wsdl返回的数据是xml格式的,
restfull风格的对应的wdl,返回的数据是json的,轻量级的,现在比较常用,去wsdl留wdl
webservice和restfull的底层实现都是socket只是实现方式不一样而已
六,数据结构和算法
数据结构:hashmap和list底层原理
算法:堆栈,快速排序,递归算法
java面试题——高级篇的更多相关文章
- 史上最难的一道Java面试题 (分析篇)
博客园 匠心零度 转载请注明原创出处,谢谢! 无意中了解到如下题目,觉得蛮好. 题目如下: public class TestSync2 implements Runnable { int b = 1 ...
- [ Java面试题 ]泛型篇
1.Java中的泛型是什么 ? 使用泛型的好处是什么? 泛型是Java SE 1.5的新特性,泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数. 好处: 1.类型安全,提供编译期间的类 ...
- java面试题-spring篇
这次是关于spring的面试题,和上次一样依旧挑了几个具有代表性的. 一. 谈谈你对 Spring 的理解 Spring 是一个开源框架,为简化企业级应用开发而生.Spring 可以是使简单的 Ja ...
- [ Java面试题 ]基础篇之一
1.一个".java"源文件中是否可以包括多个类(不是内部类)?有什么限制? 可以有多个类,但只能有一个public的类,并且public的类名必须与文件名相一致. 2.Java有 ...
- [ Java面试题 ] 集合篇
1.ArrayList和Vector的区别 这两个类都实现了List接口(List接口继承了Collection接口),他们都是有序集合,即存储在这两个集合中的元素的位置都是有顺序的,相当于一种动态的 ...
- [ Java面试题 ] 框架篇
1.谈谈你对Struts的理解. 1. struts是一个按MVC模式设计的Web层框架,其实它就是一个Servlet,这个Servlet名为ActionServlet,或是ActionServlet ...
- [ Java面试题 ]基础篇之二
1.String s = new String("xyz");创建了几个StringObject?是否可以继承String类? 两个或一个都有可能,"xyz"对 ...
- [ Java面试题 ]多线程篇
1.什么是线程? 线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位.程序员可以通过它进行多处理器编程,你可以使用多线程对运算密集型任务提速.比如,如果一个线程完成一 ...
- [ Java面试题 ]算法篇
1.堆和栈在内存中的区别是什么? 概念: 栈(stack)是为执行线程留出的内存空间.当函数被调用的时候,栈顶为局部变量和一些 bookkeeping 数据预留块.当函数执行完毕,块就没有用了,可能在 ...
随机推荐
- Webpack 4 : ERROR in Entry module not found: Error: Can't resolve './src'
ERROR in Entry module not found: Error: Can't resolve './src' in 'E:\ASUS\Documents\VSCode files\Web ...
- UNION ALL \UNION
(一)UNION ALL \UNION 的用法和区别 UNION UNION ALL 用途 用于使用SELECT语句组合两个或多个表的结果集. 用于使用SELECT语句组合两个或多个表的 ...
- SQlServer 变量定义 赋值
declare @id int declare @name char(10) ;注意:char(10)为10位,要是位数小了会让数据出错 set @id=1 select @id=1 select @ ...
- 添加wcf服务引用,无法签出当前文件
写了一些wcf服务接口,使用控制台可以正常启动服务,想要测试一下,新建项目添加服务引用,提示:“无法签出当前文件.该文件可能为只读或已锁定,或者您需要手动签出它.” 在网上找了找,有说可能是因为源代码 ...
- ES6 变量与解构(二)
一.变量的声明与使用 [测试示例需要在node环境中测试,浏览器环境下并不完全兼容ES6代码]ES6中可以使用 {} 来包含任意一段代码,被 {} 包裹的内容称为一个代码块(局部作用域) let关键字 ...
- iOS编程
一.语法 1. performSelector 2.
- Android 工作流提交审批填写审批意见PopWindow工具类
公司的项目中几乎都会有走工作流这个环节,为了提高效率,现在特意把弹出的填写审批意见PopWindow改转成工具类,提高效率,免得下次又得整.先看运行效果.
- ta和夏天一起来了
目录 ta和夏天一起来了 上半年,过去的就让去过去,遗憾的也别再遗憾. 下半年,拥有的请好好珍惜,想要的请努力去追. ta和夏天一起来了 转眼结束了2019的上半年,在这个月末, 季度末, 周末, ...
- 苹果电脑Mac系统如何安装Adobe Flash Player
一)安装/更新Adobe Flash Player 开系统偏好设置 , Flash player 更新,立即检查/立刻安装: Flash插件官方每月常规更新1~2次,为避免频繁过期,建议设置为允许A ...
- LDA-作为线性判别 降维 推导
LDA 降维原理 前面对 LDA 作为作为分类器 有详细推导, 其核心就是 贝叶斯公式, 已知全概率, 求(条件概率)最大先验概率, 类似的问题. 而 LDA 如果作为 降维 的原理是: a. 将带上 ...