STL源码剖析——序列式容器#5 heap
准确来讲,heap并不属于STL容器,但它是其中一个容器priority queue必不可少的一部分。顾名思义,priority queue就是优先级队列,允许用户以任何次序将任何元素加入容器内,但取出时是从优先权最高的元素开始取。而优先权有两种,可以是容器内数值最低的,也可以是数值最高的。而priority queue是选择了数值高作为评判优先级的标准。对应实现方法就是binary max heap,其作为priority queue的底层机制。
所谓的binary heap(二叉堆),是一种完全二叉树,也就是说,整棵二叉树除了最底层的叶子节点外,其他节点都是被填满的,而最底层的节点是从左至右不得有空节点的,如图所示:

如图所示,完全二叉树整棵树内没有任何节点漏洞,这使得我们可以使用数组来存储一棵完全二叉树上的所有结点。另外,如果我们数组的索引1开始记录节点,那么父节点与子节点在数组中的关系就一般为:父节点在 i 处,其左子节点必位于数组的 2i 处,其右子节点必位于数组的 2i+1 处。这种以数组表示树的方式,称为隐式表述法。我们的heap需要动态改变节点数,所以用vector是更好的选择。由于priority queue选择的是binary max heap做为自己的底层机制,所以也只提供了max heap的实现,所以我们接下里讨论的都是大根堆(max heap)。每个节点的键值都大于或等于其子节点的键值。
heap算法
- push_heap
为了满足完全二叉树的条件,最新加入的元素一定要放在最下一层做为叶子节点,并填补在从左至右的第一个空格。新加入的元素并不一定适合于现有的位置,为了满足max-heap的条件,我们需要对刚加入的元素进行一个上浮(percolate up)的操作:将新节点与其父节点比较,如果其键值比父节点的大,就父子交换位置,交换后新加的元素成为了父节点,此时再与它的父节点比较,如此一直上溯,直到不需对换或直到根节点为止。
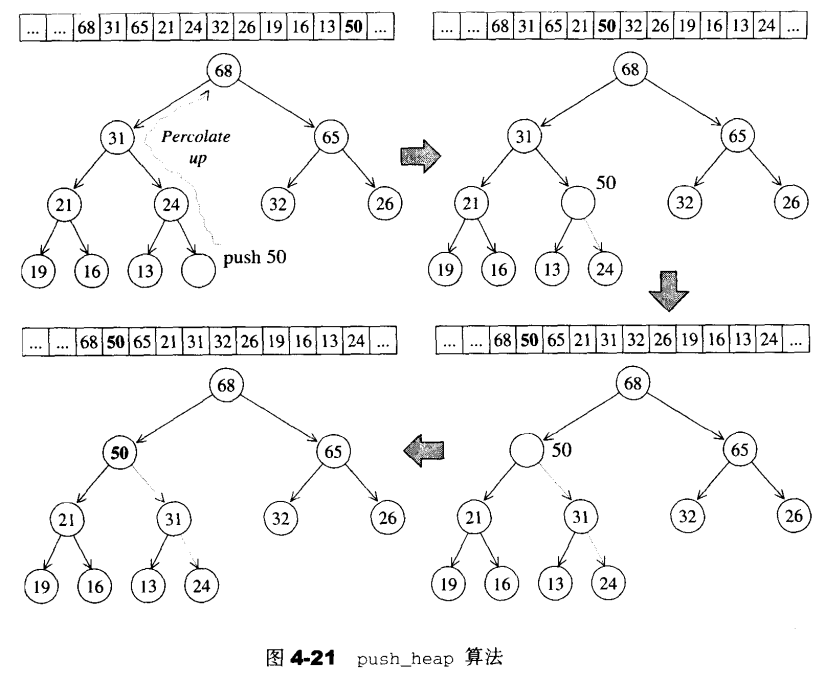
push_heap函数接受两个随机迭代器,用来表示一个heap底部容器(vector)的头尾,并且新元素已经插入到底部容器的最尾端,才会进入到该函数。如果参数不符合,或并无新元素插入,该函数的执行结果不可预期。
template <class RandomAccessIterator>
inline void push_heap(RandomAccessIterator first, RandomAccessIterator last) {
// 注意,此函数被调用时,新元素应已置于底层容器的最尾端。
//即是新元素被加入到数组(原本最后元素的下一位置)后,才调用该函数
__push_heap_aux(first, last, distance_type(first), value_type(first));
}
template <class RandomAccessIterator, class Distance, class T>
inline void __push_heap_aux(RandomAccessIterator first,
RandomAccessIterator last, Distance*, T*) {
__push_heap(first, Distance((last - first) - ), Distance(),
T(*(last - )));
//于上个函数获取到的迭代器所指对象类型T,用于强制转换
//Distance(0)为指出最大值的索引值
//Distance((last - first) - 1)为指出新添值的索引值
}
template <class RandomAccessIterator, class Distance, class T>
void __push_heap(RandomAccessIterator first, Distance holeIndex,
Distance topIndex, T value) {
//holeIndex为指出新添值的索引值
//topIndex最大值的索引值
//value为新添值内容
Distance parent = (holeIndex - ) / ; // 找出新元素的父节点
while (holeIndex > topIndex && *(first + parent) < value) {
// 当尚未到达顶端,且父节点小于新值(不符合 heap 的次序特性),继续上浮
// 由于以上使用 operator<,可知 STL heap 是一种 max-heap(大根堆)。
*(first + holeIndex) = *(first + parent); // 子位置设父值
holeIndex = parent; // percolate up:調整新添值的索引值,向上提升至父节点。
parent = (holeIndex - ) / ; // 获取新索引值的父节点
} // 持续到顶端,或满足 heap 的次序特性为止。
*(first + holeIndex) = value; // 令最后的索引值为新值,完成插入。
}
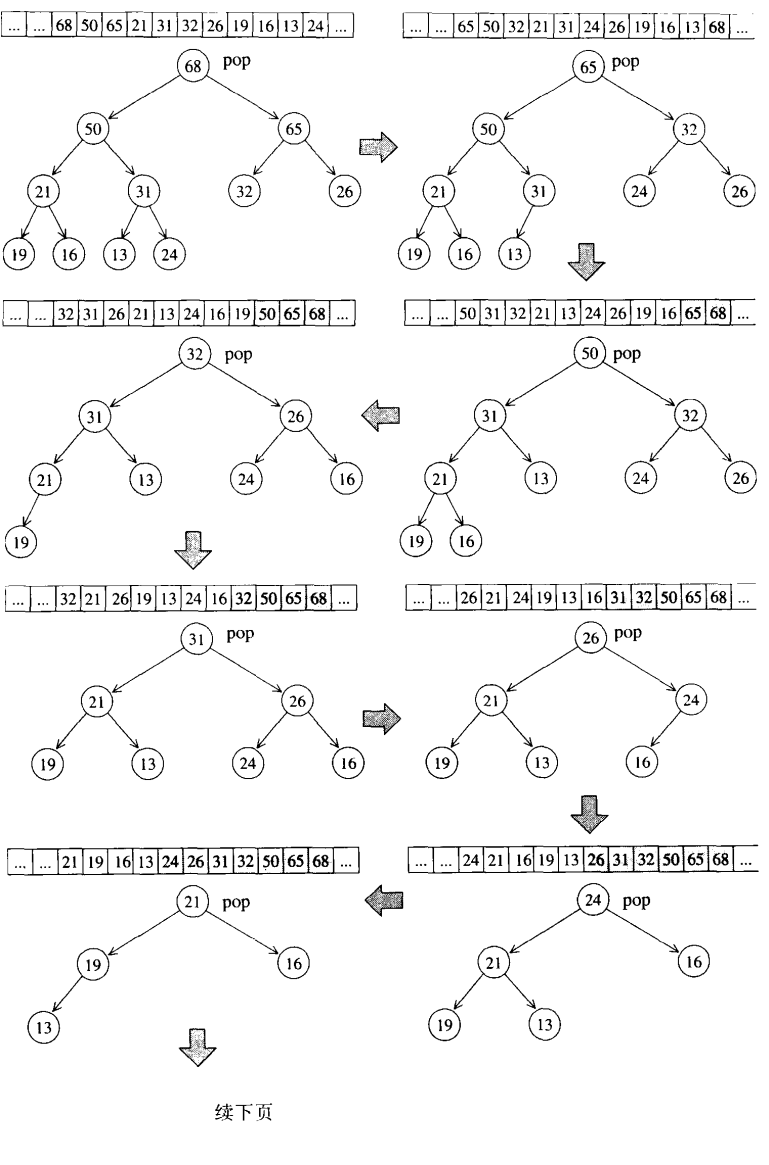
- pop_heap
最大值在根节点处,pop操作取走根节点(其实是把它转移到vector的尾端节点上),为了满足完全二叉树的条件,必须割舍最底层最右边的节点,把其值拿出来放至一临时变量里,然后该位置放根节点的值(最后会被pop_back()给移除)。

template <class RandomAccessIterator>
inline void pop_heap(RandomAccessIterator first, RandomAccessIterator last) {
__pop_heap_aux(first, last, value_type(first));
} template <class RandomAccessIterator, class T>
inline void __pop_heap_aux(RandomAccessIterator first,
RandomAccessIterator last, T*) {
__pop_heap(first, last - , last - , T(*(last - )), distance_type(first));
// 设定准条调整的值为尾值,然后将首值调至
// 尾节点(所以以上将迭代器 result 设为 last-1)。然后重整 [first, last-1),
// 使之重新成一個合格的 heap。
} template <class RandomAccessIterator, class T, class Distance>
inline void __pop_heap(RandomAccessIterator first, RandomAccessIterator last,
RandomAccessIterator result, T value, Distance*) {
*result = *first; // 设定尾值为首值,于是尾值即为要求的结果,
// 可由客端稍后再调用 pop_back() 取出尾值。
__adjust_heap(first, Distance(), Distance(last - first), value);
// 以上重新调整 heap,要调整的索引值为 0(亦即树根处),欲调整值为 value(原尾值)。
} template <class RandomAccessIterator, class Distance, class T>
void __adjust_heap(RandomAccessIterator first, Distance holeIndex,
Distance len, T value) {
//holeIndex:要调整的索引值,从树根处出发
//len:所有元素个数(不包括被调整到尾节点的首节点),即[0, len)
//value:记录了原最底层最右边的节点的值
Distance topIndex = holeIndex;
Distance secondChild = * holeIndex + ; // 调整的索引值的右子节点
while (secondChild < len) {
// 比较这左右两个子值,然后以 secondChild 代表较大子节点。
if (*(first + secondChild) < *(first + (secondChild - )))
secondChild--;
// Percolate down:令较大子值代替要调整索引值处的值,再令调整的索引值下移至较大子节点处。
*(first + holeIndex) = *(first + secondChild);
holeIndex = secondChild;
// 继续找出要调整的索引值的右子节点
secondChild = * (secondChild + );
}
if (secondChild == len) { // 相等,说明沒有右子节点(不是说没有,而是被准备pop掉的元素占用了,见*result = *first;),只有左子节点
// Percolate down:令左子值代替要调整索引值处的值,再令要调整的索引值下移至左子节点处。
*(first + holeIndex) = *(first + (secondChild - ));
holeIndex = secondChild - ;
} // 此时可能尚未满足次序特性,再执行一次上浮操作
__push_heap(first, holeIndex, topIndex, value);
}
注意,pop_heap之后,最大元素只是被放置于底部容器的最尾端,尚未被取走。如果要取其值,可使用底部容器的back()函数。如果要移除它,可使用底部容器所提供的pop_back()函数。
- sort_heap
既然每次调用pop_heap可获得heap中键值最大的元素,如果持续对整个heap做pop_heap操作,且每次的操作范围都从后向前缩减一个元素,那么当整个程序执行完毕,我们便有了一个递增序列。sort_heap便是如此做的。该函数接受两个迭代器,用来表示heap的首尾。如果并非首尾,该函数的执行结果不可预期。注意,排序过后,底层容器里的就不再是一个合法的heap了。
template <class RandomAccessIterator>
void sort_heap(RandomAccessIterator first, RandomAccessIterator last) {
// 以下,每执行一次 pop_heap(),极大值即被放在尾端。
// 尾端自减后(往左移动一格)再执行一次 pop_heap(),次极值又被放在新尾端。一直下去,最后即得
// 排序结果。
while (last - first > )
pop_heap(first, last--); // 每执行 pop_heap() 一次,操作范围即退缩一格。
}

- make_heap
这个算法用来将一段现有的数据转化为一个heap。把一段数据转换为heap的要点就是找到最后一个拥有子节点的节点,例如:
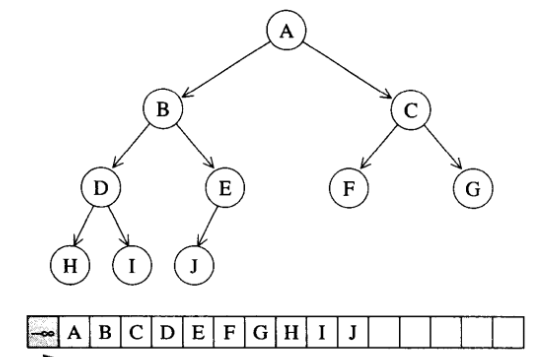
假设这是一个普通数组,并无heap特性,那么要想其转化为一个heap,切入点就是找到最后一个拥有子节点的节点,上图而言就是E点,以E节点为首的子树,对该子树进行下沉操作和上浮操作,即先交换E跟J的值,再对J进行上浮操作。这样以E节点为首的子树就符合heap特性了。然后自减,来到了D节点(倒二拥有子节点的节点),同样对以D节点为首的子树进行下沉和上浮操作;然后再自减,直至到达根节点为止。这样整个数组就符合heap特性了。那么问题来了?怎么在一个普通数组中找到最后一个拥有子节点的节点的索引值呢?可以证明的是,如果有一长度为n的数组,那么最后一个拥有子节点的节点的索引值就是 (n - 2) / 2 ,这是数组从索引0开始的情况。
// 将 [first,last) 排列为一个 heap。
template <class RandomAccessIterator>
inline void make_heap(RandomAccessIterator first, RandomAccessIterator last) {
__make_heap(first, last, value_type(first), distance_type(first));
} template <class RandomAccessIterator, class T, class Distance>
void __make_heap(RandomAccessIterator first, RandomAccessIterator last, T*,
Distance*) {
if (last - first < ) return; // 如果長度為 0 或 1,不必重新排列。
Distance len = last - first;
// 找出第一个需要重排的子树头部,以 parent 标示出。由于任何叶子节点都不需执行
// perlocate down(下沉),所以有以下计算。
Distance parent = (len - ) / ; while (true) {
// 重排以 parent 为首的子树。len 是为了让 __adjust_heap() 判断操作范围
__adjust_heap(first, parent, len, T(*(first + parent)));
if (parent == ) return; // 直至根节点,就结束。
parent--; // 未到根节点,就将(即将重排的子树的)索引值向前一個节点
}
}
heap没有迭代器,heap的所有元素都必须遵循特别的排列规则,所以heap不提供遍历功能,也不提供迭代器。
STL源码剖析——序列式容器#5 heap的更多相关文章
- STL源码剖析——序列式容器#1 Vector
在学完了Allocator.Iterator和Traits编程之后,我们终于可以进入STL的容器内部一探究竟了.STL的容器分为序列式容器和关联式容器,何为序列式容器呢?就是容器内的元素是可序的,但未 ...
- STL源码剖析——序列式容器#4 Stack & Queue
Stack stack是一种先进后出(First In Last Out,FILO)的数据结构,它只有一个出口,元素的新增.删除.最顶端访问都在该出口进行,没有其他位置和方法可以存取stack的元素. ...
- STL源码剖析——序列式容器#2 List
list就是链表的实现,链表是什么,我就不再解释了.list的好处就是每次插入或删除一个元素,都是常数的时空复杂度.但遍历或访问就需要O(n)的时间. List本身其实不难理解,难点在于某些功能函数的 ...
- STL源码剖析——序列式容器#3 Deque
Deque是一种双向开口的连续线性空间.所谓的双向开口,就是能在头尾两端分别做元素的插入和删除,而且是在常数的时间内完成.虽然Vector也可以在首端进行元素的插入和删除(利用insert和erase ...
- STL源码剖析:算法
启 算法,问题之解法也 算法好坏的衡量标准:时间和空间,单位是对数.一次.二次.三次等 算法中处理的数据,输入方式都是左闭又开,类型就迭代器, 如:[first, last) STL中提供了很多算法, ...
- STL源码剖析之序列式容器
最近由于找工作需要,准备深入学习一下STL源码,我看的是侯捷所著的<STL源码剖析>.之所以看这本书主要是由于我过去曾经接触过一些台湾人,我一直觉得台湾人非常不错(这里不涉及任何政治,仅限 ...
- STL"源码"剖析-重点知识总结
STL是C++重要的组件之一,大学时看过<STL源码剖析>这本书,这几天复习了一下,总结出以下LZ认为比较重要的知识点,内容有点略多 :) 1.STL概述 STL提供六大组件,彼此可以组合 ...
- 【转载】STL"源码"剖析-重点知识总结
原文:STL"源码"剖析-重点知识总结 STL是C++重要的组件之一,大学时看过<STL源码剖析>这本书,这几天复习了一下,总结出以下LZ认为比较重要的知识点,内容有点 ...
- STL源码剖析读书笔记之vector
STL源码剖析读书笔记之vector 1.vector概述 vector是一种序列式容器,我的理解是vector就像数组.但是数组有一个很大的问题就是当我们分配 一个一定大小的数组的时候,起初也许我们 ...
随机推荐
- [Vscode插件] 自动编译项目中的Sass文件为CSS
插件名 : Live Sass Compiler 今天在VSCode中发现了一个自动watch项目目录下sass文件的插件,摆脱了在控制台中进行手动watch的繁琐. 安装好以后点击右下角即可自动编译 ...
- selenium控制超链接在当前标签页中打开或重新打开一个标签页
selenium控制超链接在当前标签页中打开或重新打开一个标签页 在web页面源码中,控制超链接的打开是在当前标签页还是重新打开一个标签页,是由属性target=“_black”进行控制的.如果还有属 ...
- php dirname 的简单使用
dirname dirname-返回路径中的目录部分 说明 dirname(string$path) :string 给出一个包含有指向一个文件的全路径的字符串,本函数返回去掉文件名后的目录名. 参数 ...
- 配置OEL7 YUM源
用于其他发行版如rhel.centos有时候要用到oracle linux的源来装软件比如oracle.mysql等 配置oel7源 wget http://public-yum.oracle.com ...
- HTTP中分块编码(Transfer-Encoding: chunked)
转自: 妙音天女--分块传输编码~ 参考链接: HTTP MDN--HTTP协议 一.背景: 持续连接的问题:对于非持续连接,浏览器可以通过连接是否关闭来界定请求或响应实体的边界:而对于持续连接,这种 ...
- ubuntu 1804安装详解
我这边安装的是ubuntu server版本,大家安装时可以参考我这篇文件进行安装. 1.选择安装语言: 这里选择默认的"English"和“中文(简体)”都可以. 2.选择”安装 ...
- axios跨域处理
本质分析: 因为axios在vue中利用中间件http-proxy-middleware做了一个本地的代理服务A,相当于你的浏览器通过本地的代理服务A请求了服务端B,浏览器通过服务A并没有跨域,因此就 ...
- USB设备驱动程序1
目的:USB鼠标用作按键,左键相当于字母L,右键相当于字母S,中键相当于Enter.如何来实现?用到输入子系统:1)分配input_dev2)设置3)注册4)硬件相关操作对于USB鼠标来说,硬件操作应 ...
- logstash 监控日志文件时应对日志文件名改变的原理
开门见山先说结论:基于inode实现. 分析很简单,logstash是用一个filewatch去监视文件的.在logstash目录里搜索filewatch即可找到该目录 logstash/vendor ...
- vue watch 深度监听
watch 是vue 里非常有用的回调函数,监听数据变化,非常方便好用,但是,当监听的数据是个复杂型的数据里,里面的数据变化时普通的监听方式是监听不到的,必须使用深度监听: data() { retu ...