Python_爬虫小实例
爬虫小实例
一、问题描述与分析
Q:查询某一只股票,在百度搜索页面的结果的个数以及搜索结果的变化。
分析:
搜索结果个数如下图: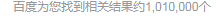
搜索结果的变化:通过观察可以看到,每个一段时间搜索结果的个数是有所变化的,因为百度的搜索结果是听过关
键字来提供搜索结果的。对此我们从以下结果方面考虑:1、该只股票在近期内有较为明显的波动,对此,含有
该股票代码的相关信息增多;2、通过观察搜索结果,存在很多以下标识的网站: ,
,
此类标识的网站为广告网站,在考虑分析时,我们可以将其排除。
A:通过前面“Python爬虫”这一文章,我们也分别从以下:抓取页面、分析页面和存储数据三方面来解决本实例的一些
技术的实现问题。
二、一些问题
1、完成的可运行的程序源码,放在个人的Github的Hazy-star这个库中,以下是Github链接:Hazy-star_Python
2、程序中一些调用的库的使用,具体参考相关库的官方文档
3、程序中可能仍然存在较多的纰漏以及值得完善的地方,有待大家指正
4、实例中不涉及具体的数据的分析研究,只关心如何实现数据的获取。以及需要的一些有效数据的提取。
三、爬虫实例的实现
百度搜索规则语法:
http://www.baidu.com/s?wd=' 关键字 '+&pn=' + str(搜索页面数)
抓取页面
查询功能:baiduText(code, num) 实现输入code(股票代码),num(搜索页面的页数),返回相应的搜索页面
#coding=utf-8
import socket
import urllib.request
import urllib.error def baiduText(code, num):
url = 'http://www.baidu.com/s?wd=' + code + '&pn=' + str(num)
try:
response = urllib.request.urlopen(url, timeout = 10)#下载页面,设定延迟10s
return response.read().decode('gbk', ‘ignore’).encode('utf-8')
except urllib.error.URLError as e: #抛出异常
if isinstance(e.reason, socket.timeout):
print('TIME OUT')
分析页面
通过对页面的抓取,我们可以将相应股票代码和搜索页面的HTML文档下载下来,接下来是对页面的分析,我们研究的是,为什么每个一段时间,搜索结果会发生变化,所以,我们考虑将每个搜索页面中搜索结果的标题以及url提取出来,存放在地点数据中,供后续的分析使用。
首先查找页面搜索结果
#coding=utf-8
from bs4 import BeautifulSoup
#全部的收缩结果
def parseHtml(text):
soup = BeautifulSoup( text, features="lxml" )
tags = soup.find_all( 'span' )
#寻找所有的span标签
for tag in tags:
cont = tag.string
if( cont is not None and cont.startswith( '百度为您找到相关结果约' )):
#此处可进行查询优化
cont = cont.lstrip( '百度为您找到相关结果约' )
cont = cont.rstrip( '个' )
cont = cont.replace( ',', '' )
return eval(cont)
打印搜索结果标题以及URL,对此我们使用字典进行存储提取后的数据
#coding=utf-8
from bs4 import BeautifulSoup
def printurl(text):
#打印出所有搜索结果中网站的URl以及网站名字
soupurl = BeautifulSoup( text, features="lxml" )
#通过分析,搜索结果的标题都是存放在h3中的
tagsurl = soupurl.find_all( 'h3' )
#使用循环将网站以及对应的url传入到字典中
dicturl = {}
for tagurl in tagsurl:
url = [x['href'] for x in tagurl.select('a')][0]
#使用列表生成式子,以及select方法提取搜索结果的url
dicturl.update({tagurl.get_text():url})
return dicturl
考虑到前面分析时,存在着广告搜索结果的影响,我们对含有广告标识的页面数量进行分析
#coding=utf-8
from bs4 import BeautifulSoup
def printurl(text):
#打印出所有搜索结果中网站的URl以及网站名字
soupurl = BeautifulSoup( text, features="lxml" )
#通过分析,搜索结果的标题都是存放在h3中的
tagsurl = soupurl.find_all( 'h3' )
#使用循环将网站以及对应的url传入到字典中
dicturl = {}
for tagurl in tagsurl:
url = [x['href'] for x in tagurl.select('a')][0]
#使用列表生成式子,以及select方法提取搜索结果的url
dicturl.update({tagurl.get_text():url})
return dicturl
然后对定义函数,用于判断是否搜索到结果的最后一面
#coding=utf-8
from bs4 import BeautifulSoup
def EndSel(text):
#用于结束搜索的函数
flag = True
temp = []
soupEnd = BeautifulSoup( text, features="lxml" )
#通过分析,搜索结果的标题都是存放在h3中的
tagsEnd = soupEnd.find_all( 'a' )
for tagEnd in tagsEnd:
temp.append(tagEnd.string)
if('下一页>' not in temp):
flag = False
return flag
下载页面
通过对下载的页面数据的分析,使用SaveDict(Dict) 实现将抓取的信息存在在的字典再存储到txt文件中,dict相当于我们使用的关系型的数据库。
def saveDict(dict):
# 将字典保存问txt文件
file = open('dict.txt', 'a')
for k,v in dict.items():
file.write(k+'\n'+v+'\n')
file.close()
四、总结
对于小型的爬虫的创建,我们基本依照上面的基本进行构建即可。示例总未展出主函数,完整的代码见 Github ,主函数主要编写对这些模块的调用,以及逻辑的构建。对于大型的爬虫,在每一部分可能遇到的问题有:
1、在抓取页面时,有些网站可能有反爬机制,会对爬虫进行拦截,这时我们可能需要使用到代理,避免同一IP反复高频率访问网站被拦截
2、在分析页面时,有写网站会对HTML页面进行JS加密等,进行计算机爬虫自动爬取,此些页面需要仔细分析其内在逻辑,才能抓取到真正的数据
3、数据存储,小规模的爬取我们可以使用文件存储,当遇到大规模的数据爬取,我们就需要进行数据库的存储,方便我们或许分析处理数据
4、对于单一爬虫,即便使用个人PC也可以运行,但是对于大规模的爬虫,我们可能需要考虑分布式布置爬虫进行数据的爬取,以提高数据搜集的效率
5、对于爬虫中一些高级的运用,后续会再更新,包括一些常见的页面加密解析以及使用代理,模拟分布式、爬取App数据等。
2019-05-16
Python_爬虫小实例的更多相关文章
- python爬虫小实例
1.python爬取贴吧壁纸 1.1.获取整个页面数据 #coding=utf-8 import urllib def getHtml(url): page = urllib.urlopen(url) ...
- Python(五)编程小实例
Python(五)编程小实例 抓取网页信息,并生成txt文件内容! Python抓取网页技能--Python抓取网页就是我们常看见的网络爬虫,我们今天所要用到的就是我们Python中自带的模块,用这些 ...
- winform 异步读取数据 小实例
这几天对突然对委托事件,异步编程产生了兴趣,大量阅读前辈们的代码后自己总结了一下. 主要是实现 DataTable的导入导出,当然可以模拟从数据库读取大量数据,这可能需要一定的时间,然后 再把数据导入 ...
- 基于webmagic的爬虫小应用--爬取知乎用户信息
听到“爬虫”,是不是第一时间想到Python/php ? 多少想玩爬虫的Java学习者就因为语言不通而止步.Java是真的不能做爬虫吗? 当然不是. 只不过python的3行代码能解决的问题,而Jav ...
- 一个python爬虫小程序
起因 深夜忽然想下载一点电子书来扩充一下kindle,就想起来python学得太浅,什么“装饰器”啊.“多线程”啊都没有学到. 想到廖雪峰大神的python教程很经典.很著名.就想找找有木有pdf版的 ...
- CSS应用内容补充及小实例
一.clear 清除浮动 <!DOCTYPE html> <html lang="en"> <head> <meta charset=&q ...
- Objective-C之代理设计模式小实例
*:first-child { margin-top: 0 !important; } body > *:last-child { margin-bottom: 0 !important; } ...
- Objective-C之@类别小实例
*:first-child { margin-top: 0 !important; } body > *:last-child { margin-bottom: 0 !important; } ...
- OC小实例关于init方法不小心的错误
*:first-child { margin-top: 0 !important; } body > *:last-child { margin-bottom: 0 !important; } ...
随机推荐
- Edusoho之X-Auth-Token
昨天这篇文章Edusoho之Basic Authentication提到了X-Auth-Token.今天我主要讲的是Edusoho之X-Auth-Token的请求API方式. 至于为什么建议不要用HT ...
- maven工程中MENIFEST.MF中属性作用
Manifest-Version: 版本号 Bundle-ManifestVersion: bundle的版本号 Bundle-Name: bundle的名称,主要是对bundle的作用的说明 Bun ...
- GWAS Catalog数据库简介
GWAS Catalog The NHGRI-EBI Catalog of published genome-wide association studies EBI负责维护的一个收集已发表的GWAS ...
- 单细胞数据整合方法 | Comprehensive Integration of Single-Cell Data
操作代码:https://satijalab.org/seurat/ 依赖的算法 CCA CANONICAL CORRELATION ANALYSIS | R DATA ANALYSIS EXAMPL ...
- Python Selenium Webdriver常用方法总结
Python Selenium Webdriver常用方法总结 常用方法函数 加载浏览器驱动: webdriver.Firefox() 打开页面:get() 关闭浏览器:quit() 最大化窗口: m ...
- java正则表达式备忘
最近框架和爬虫上常要处理字符串匹配和替换的场景,备忘. 非贪婪模式 比如要匹配html文本中的连接,例如a href="www.abc.com/xyz/o"需要替换为a href= ...
- PostgreSQL中的The Oversized-Attribute Storage Technique(TOAST:超大属性存储技术)
PostgreSQL使用固定的页面大小(通常为8kB),并且不允许元组跨越多个页面.因此,不可能直接存储非常大的字段值.为了克服这种限制,将大字段值压缩和/或分解成多个物理行.这对用户来说是透明的,对 ...
- Python3基础 函数 函数名赋值操作
Python : 3.7.3 OS : Ubuntu 18.04.2 LTS IDE : pycharm-community-2019.1.3 ...
- egg.js 相关
egg sequelize 建表规范 CREATE TABLE `wx_member` ( `id` ) NOT NULL AUTO_INCREMENT COMMENT 'primary key' ...
- Laravel 使用自己的类库三种方式
虽然Composer使得我们可以重用很多现有的类库(例如packagist.org中的),但是我们仍然可能用到一些不兼容composer的包或者类库.另外在某一项目中,我们也可能会创建某一类库,而且可 ...