go调度: 第二部分-go调度器
前言
这个博客是三部分中提供go调度器的语义和机制的部分.
博客三部分的顺序:
1) go调度: 第一部分-操作系统调度
2) go调度: 第二部分-go调度器
3) go调度: 第三部分-并发
介绍
在博客三部分中的第一部分, 我解释了操作系统调度器中对理解go调度器机制重要的方面. 在博客的这部分, 我将在语义上解释go调度器如何工作, 并且关注于上层行为. go调度器是一个复杂的系统, 那些小的机制的细节不是很重要. 重要的是对事情是如何运行和表现有个好的模型. 这将允许你做出更好的决定.
启动你的程序
当你的go应用程序启动时, 它会被相对于机器上的每一个虚拟核分配一个逻辑处理器(P). 如果你有一个处理器, 这个处理器对应于每个物理核有多个硬件线程(超线程技术), 那么每个硬件线程在go程序中都会当做是一个虚拟的核. 为了更好的理解这个概念, 看一下我的MacBook Pro的系统报告.

你可以看到我有一个4个物理核的处理器. 这个报告中没有报告每个物理核对应于多少个硬件线程. 这个英特尔Core i7处理器有超线程技术, 每个物理核对应于两个硬件线程. 在go程序中, 会报告有8个可用的虚拟核来并行执行操作系统线程.
为了验证这一点, 我们来看一下下面的程序:
Listing 1
package main import (
"fmt"
"runtime"
) func main() { // NumCPU returns the number of logical
// CPUs usable by the current process.
fmt.Println(runtime.NumCPU())
}
在我的本机上运行这个程序, 调用NumCPU()函数的返回值是8. 任何运行在我的本机上的go程序都会被给予8个P(逻辑处理器).
每一个P被赋予一个操作系统线程(“M”). “M”代表机器. 这个线程由操作系统管理, 操作系统负责将线程放入核中执行. 这意味着当我在本机运行一个go程序时, 我将会有8个线程来执行我的工作, 每个线程对应一个P.
每一个go程序会被给予一个最初的go程(“G”), 这个是go程序运行的方式. 一个go程本质是一个协程, 在go中, 我们使用”G”取代了”C”, 然后我们得到了单词go程(Goroutine). 你可以认为go程是一个应用级别的线程, 它们在很多方面与操作系统线程很相似. 就像操作系统线程可以上下文切换来使用和不使用一个核, go程进行上下文切换, 来使用或者不使用一个M.
最后一个难点是运行队列. go调度器中有两种不同的运行队列: 全局运行队列 (GRQ)和本地运行队列(LRQ). 每一个P被给予一个LRQ, 这个LRQ用来管理在P中执行的go程. GRQ里面放的是没有被赋予P的go程. 有一个将go程从GRQ转到LRQ的过程, 这个我们在之后讨论.
图片2包含所有这些讨论的组件.
图片2
协同调度器
就像我们在博客第一部分所讲的, 操作系统调度器是抢占式的调度器. 从根本上来说, 你不能够预测在特定时间调度器会做什么. 内核做各种决定, 所有的东西都是不确定的. 运行在操作系统上层的应用不能控制操作系统中会发生的事情, 除非使用各种同步机制, 例如原子指令和mutex调用.
go调度器是go运行时(runtime)的一部分, go运行时构建在你的应用中. 这个意味着go调度器运行在内核之上的用户空间. 当前实现的go调度器不是抢占式调度器, 而是协同式调度器. 作为一个协同式调度器意味着, 需要在代码的安全点使用定义好的用户事件来做调度决策.
让人觉得不可思议的是, go的协同式调度器看起来像是抢占式的. 你不能够预测go调度器打算做什么. 这个是因为协同调度器的决策不依赖于开发者, 而在于go运行时. 既然go的调度器是非确定性的, 我们应该认为go调度器是抢占式的调度器, 这个不难理解.
go程状态
就像线程一样, go程也有三个状态. 这些意味着go调度器对一个给定go程采取的行为. 一个go程可以处于下面三个状态: 等待状态(Waiting), 可运行状态(Runnable)和正在执行状态(Executing).
等待状态: 这意味着go程被停止, 等待一些东西从而能够继续运行. 原因包括等待操作系统(系统调用), 同步调用(原子操作和mutex操作). 这些类型的延迟是性能糟糕的一个根本原因.
可运行状态: 这意味着go程想要在M上的时间, 从而能够执行指令. 如果你有很多go程需要执行, 那么go程可能需要等待更长的时间才能够执行. 同时, 随着可运行状态go程的增加, 每个go程被分配的时间也会变短. 这种类型的调度延迟也会导致性能变糟.
正在执行状态: 这意味着go程被放在一个M上, 正在执行它的指令. 应用所需要做的工作正在得到处理. 这个是所有go程都想要的.
上下文切换
go调度器在代码中的安全点需要定义了的用户空间事件, 从而进行上下文切换. 这些事件和安全点位于函数调用中. 函数调用对于go调度器的正常运行很重要. 现在(go1.11或者更早版本), 如果你运行一个没有调用函数的很长的循环, 你可能会导致调度器和垃圾回收出现延迟. 每隔一定的时间调用一次函数是非常重要的.
注意: 在1.12中, 有一个提议, 打算在go调度器中添加一个非协作式的抢占技术, 来允许对很长的循环进行抢占.
go程序中有4种类型的事件会发生, 从而运行调度器进行各种调度决策. 这个不意味着发生这些事件, 调度器一定进行调度, 只是说调度器可以进行调度.
1) 使用go关键字
2) 垃圾回收
3) 系统调用
4) 同步和编配
使用go关键字
go关键字用来创建一个go程. 当一个go程被创建, 它给调度器一个机会来做调度决定.
垃圾回收
因为GC使用自己的一组go程, 这些go程需要运行在M上. 因此GC会造成一定的调度波动. 然而, 调度器很清楚go程打算做什么, 它会利用这些信息做合理的决定. 其中一个合理的决定是, 让使用这段heap的go程暂时不执行, 执行不会使用这段heap的go程. 当GC运行时, 会做很多的调度决定.
系统调用
当一个go程要做一个会让M阻塞的系统调用时, 调度器能够将这个go程移出M, 上下文切换, 在这个M上放入一个新的go程. 可是, 有时候需要一个新的M, 从而能够继续执行P队列中的其他go程. 关于这个执行的细节, 将会在下一节详细介绍.
同步和编配
如果一个atomic, 锁, 或者channel操作会导致go程阻塞, 调度器就会上下文切换一个新的go程进行执行. 当这个go程再次进入可运行状态, 它将会被放入队列中, 最终通过上下文切换在一个M中得到执行.
异步系统调用
当你的操作系统可以处理异步系统调用时, network poller可以被用来更高效地处理系统调用. MacOS使用kqueue, Linux使用epoll, Windows使用iocp来实现network poller.
基于网络的系统调用, 当今我们使用的很多操作系统可以异步处理. network poller主要用来处理网络操作, 所以叫这个名字. 通过使用network poller来处理网络系统调用, 调度器可以使用go程进行相关的调用, 而不用阻塞M. 这样, 这个M就可以用来处理P的本地运行队列(LRQ)中的其他go程, 而不用新建M, 从而可以减少操作系统的调度负担.
查看这种工作方式的最好方法是通过如下的一个例子.
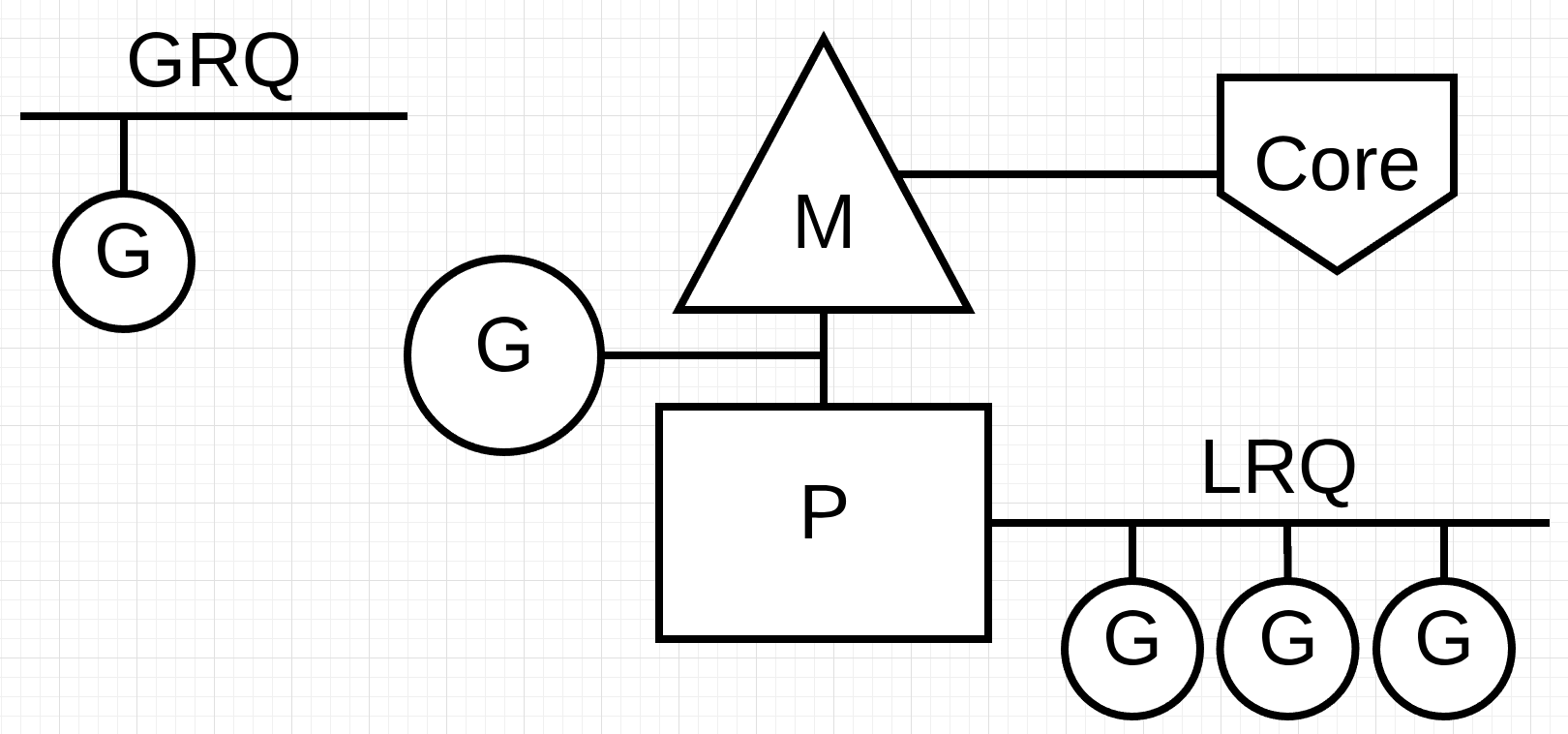
图片3
图片3显示了我们基本的调度图. go程1正在M上执行, P的本地运行队列(LRQ)中还有三个go程等待在M上执行. 当前network poller处于空闲状态.
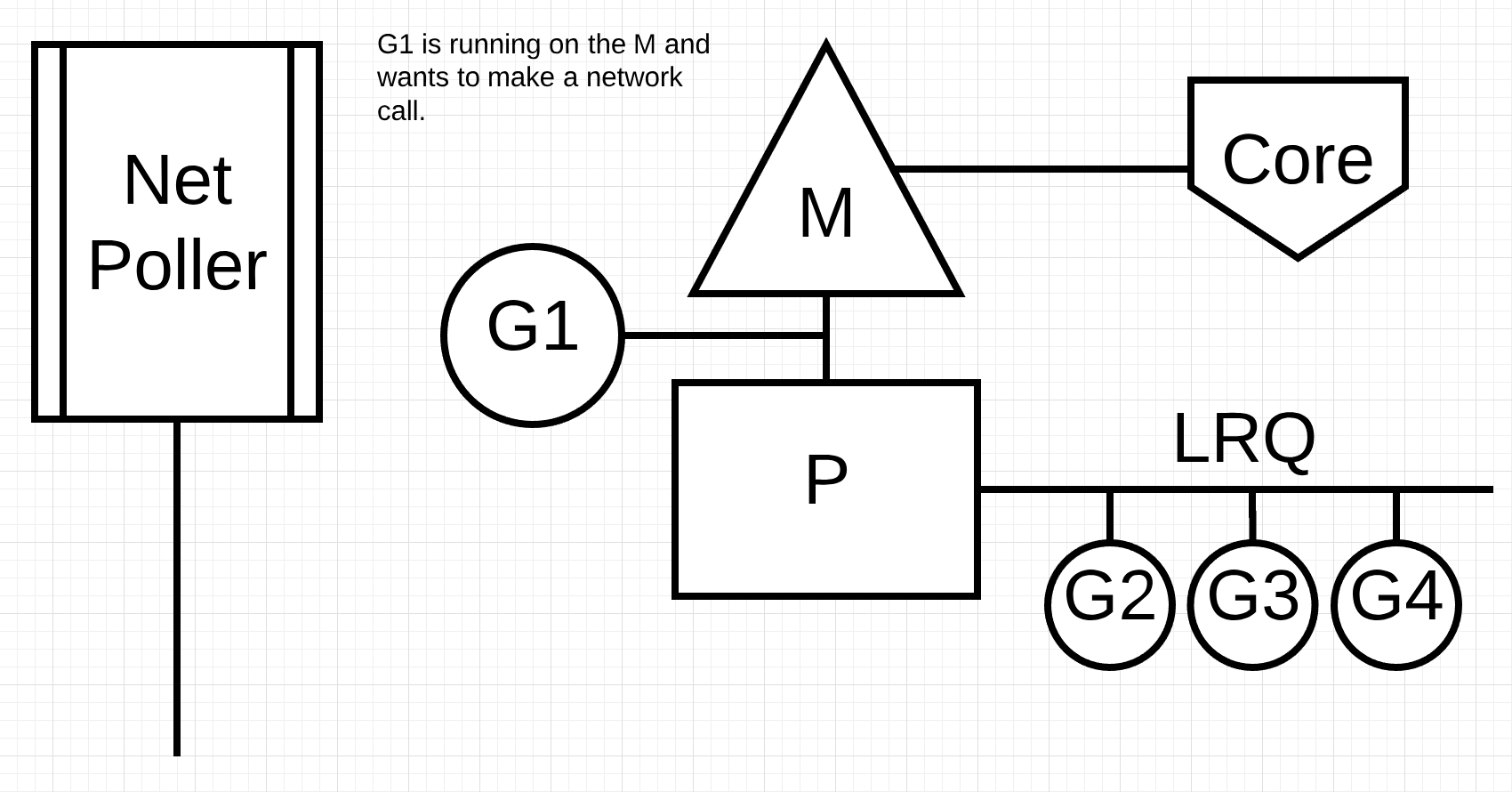
图片4
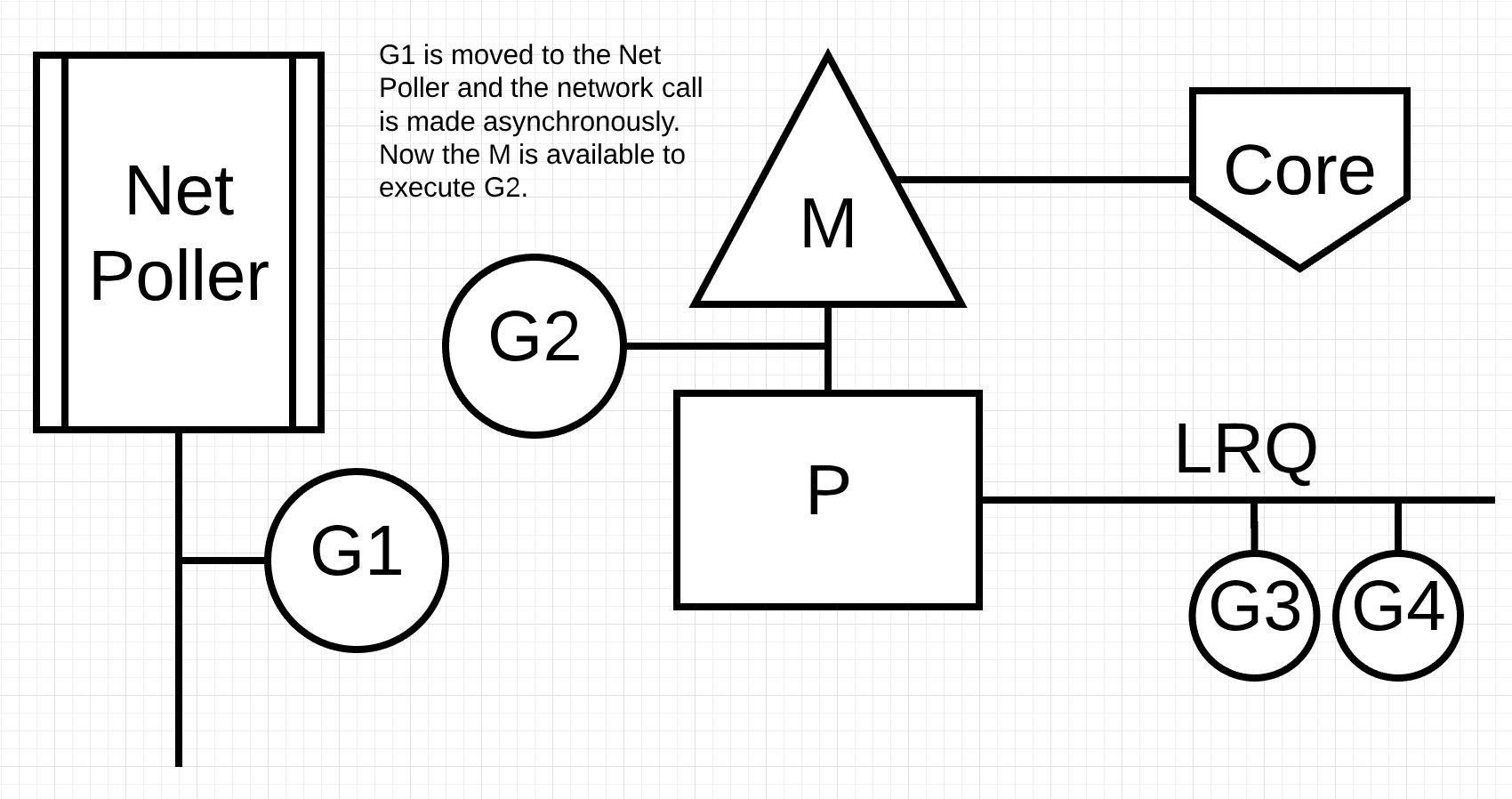
在图片4中, go程1想要进行一个网络请求, 通过将go程1移动到network poller, 这个异步网络调用被处理. go程1被移动到network poller之后, M可以执行本地运行队列(LRQ)中的其他go程. 在这个情况下, go程2会在M上运行.
图片5
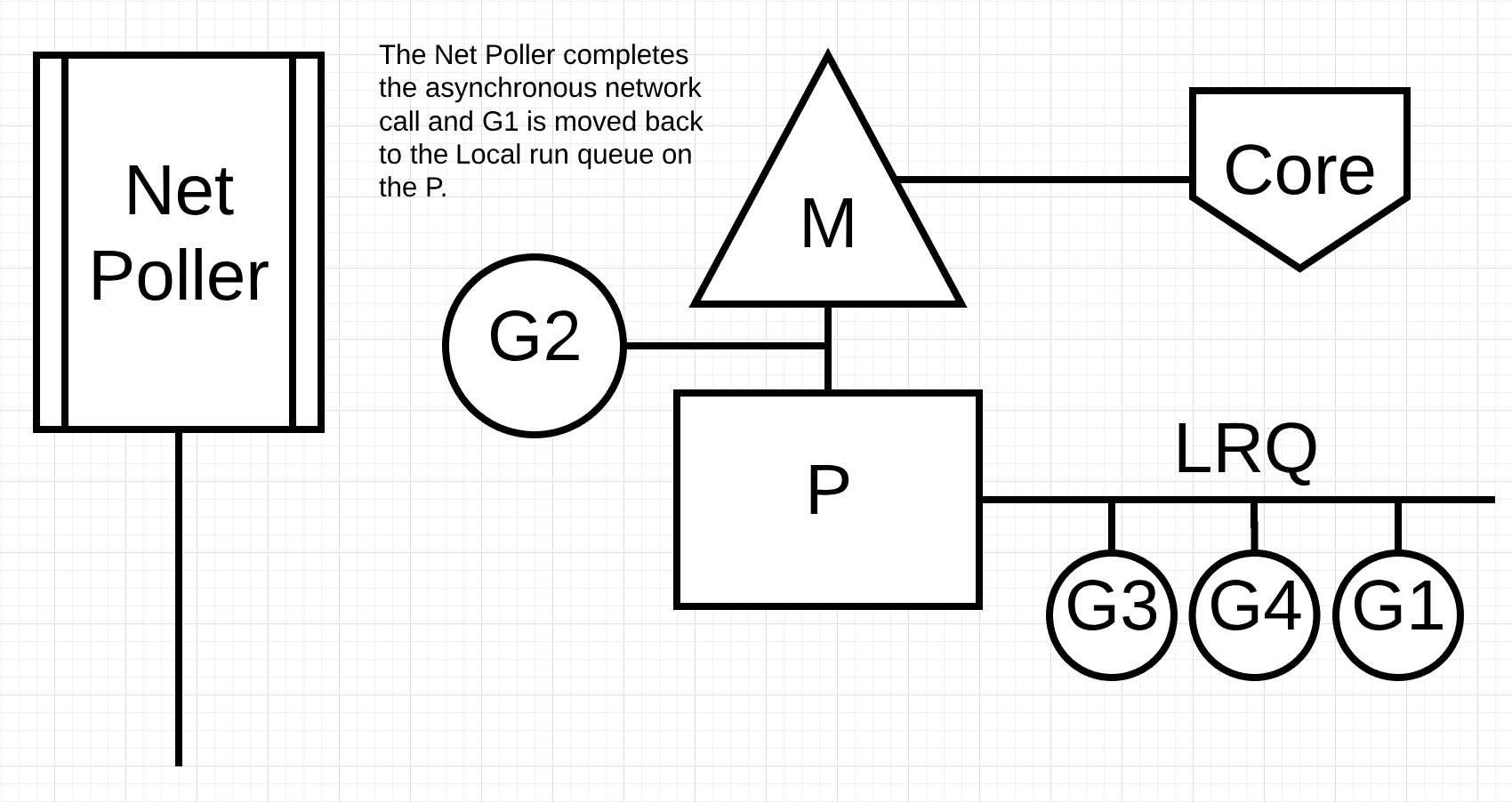
在图片5, network poller处理完异步网络调用, 然后go程1被放入P的本地运行队列(LRQ). 当go程1被放入M中继续执行, go相关的代码就可以被再次执行. 这里面最大的好处时, 为了执行网络调用, 不需要新建M. network poller有一个操作系统线程, 可以很高效地处理事件循环.
同步系统调用
当go程要做一个同步系统调用, 会发生什么? 在这种情况下, network poller不能够使用, 调用系统调用的go程会阻塞M. 很不幸, 没有办法可以阻塞这种情况发生. 这种同步系统调用的一个例子是文件系统调用. 如果你使用cgo, 会有别的C语言调用场景会阻塞M.
注意: Windows操作系统可以使文件系统调用变成异步操作, 在这种情况下, network poller会被使用.
让我们看一下使用会造成M阻塞的同步系统调用 (例如文件I/O) 时, 会发生什么.
图片6
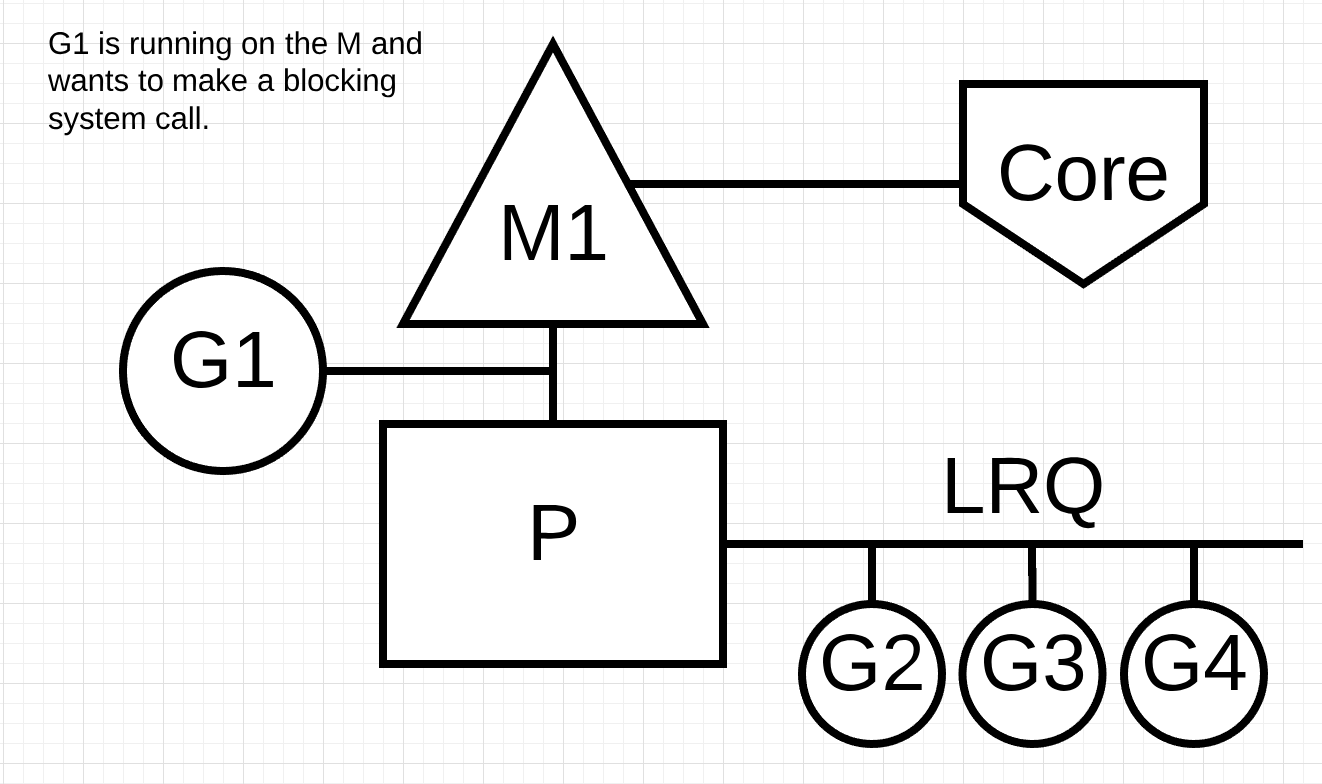
图片6显示我们的调度场景, 但是这次, go程1将进行会阻塞M1的同步系统调用.
图片7
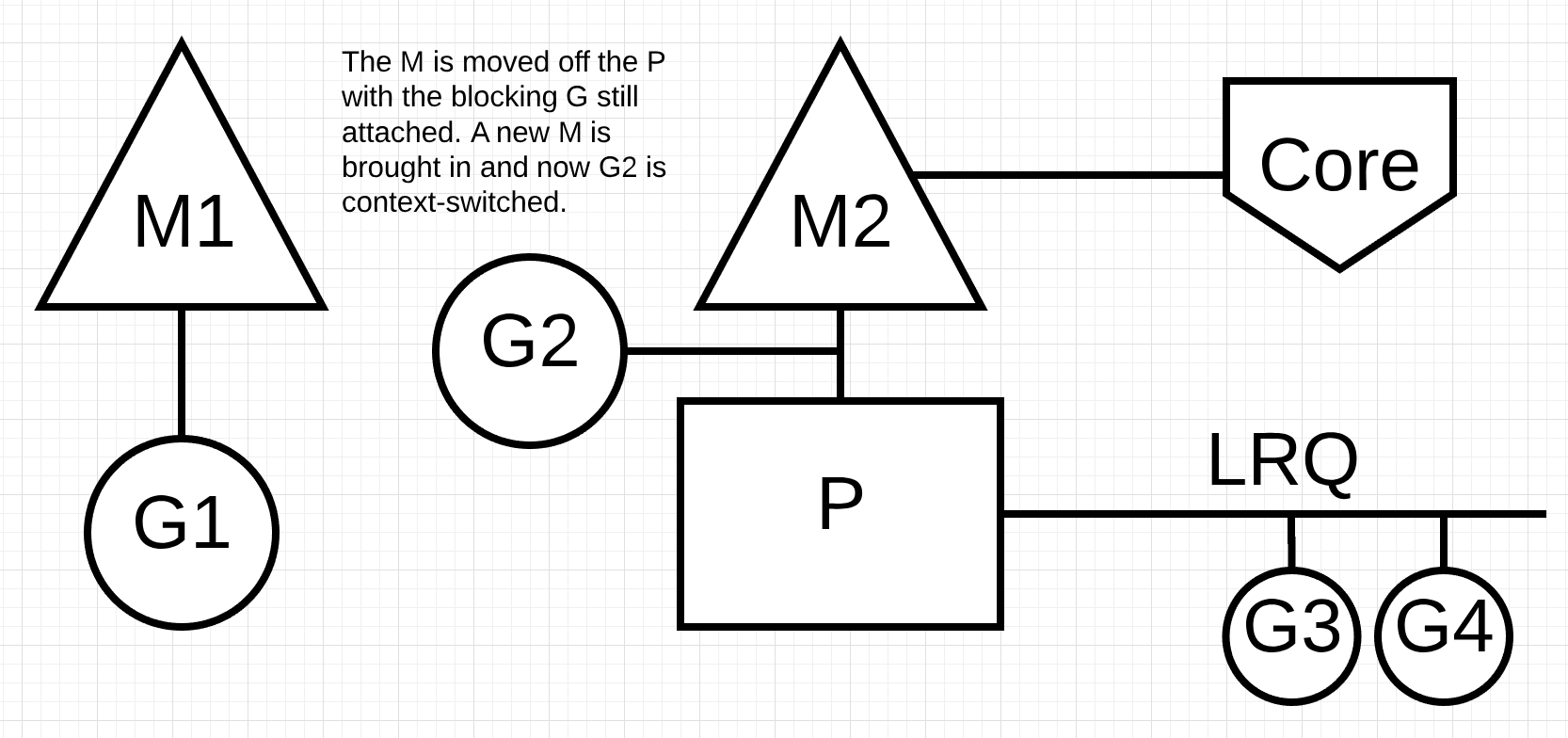
在图片7, 调度器有能力看出go程1会导致M阻塞. 在这种情况下, 调度器会将M1与P分离, 但是M1仍然会和go程1关联. 调度器会引入新的M2来处理P中的go程. 在这种情况下, go程2会从本地运行队列(LRQ)中被选择, 然后在M2中执行. 如果有现有的M可以使用, 那么这个处理会比创建新的M要快.
图片8
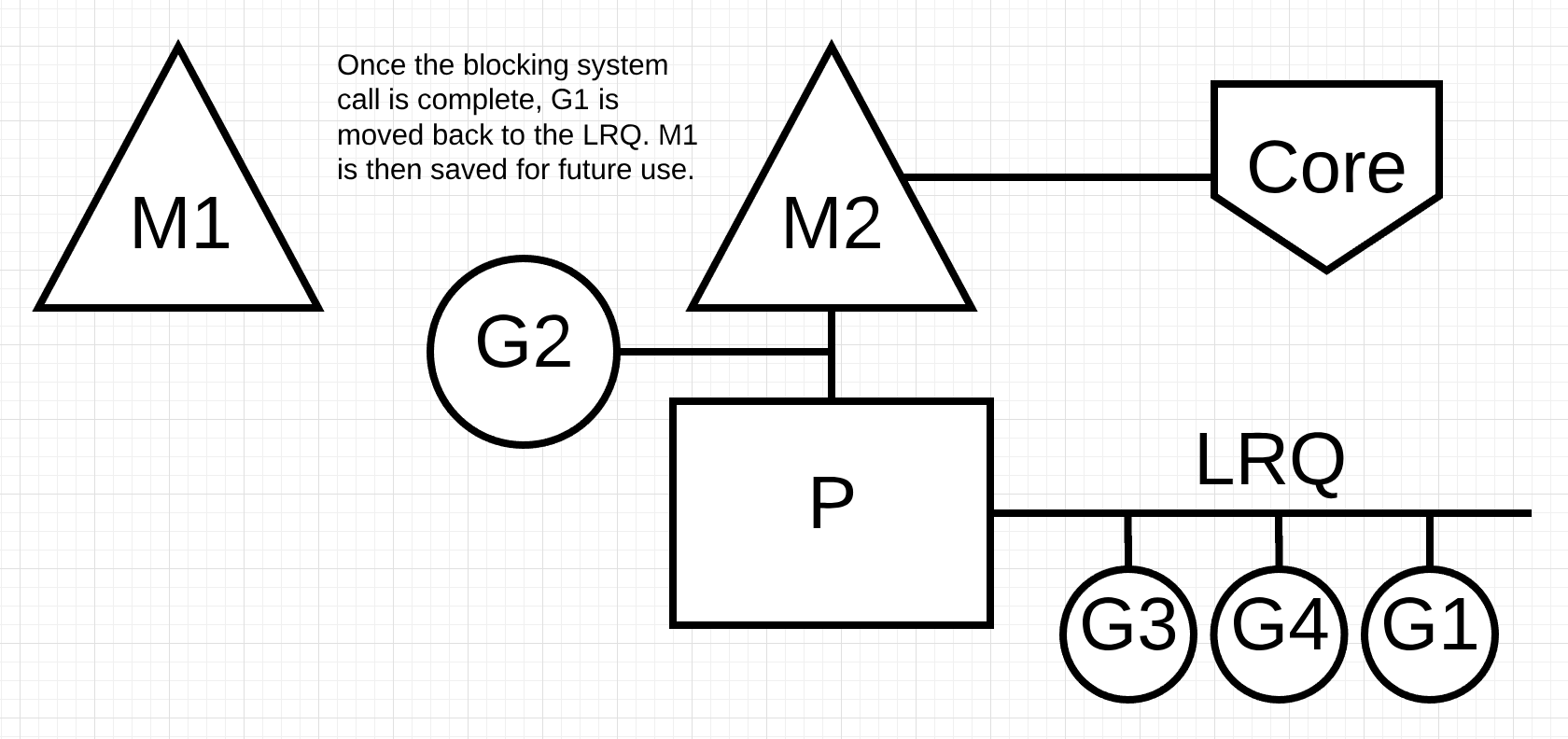
图片8中, go程1的阻塞系统调用结束了. 这时, go程1将会被移动到P中的本地运行队列中. M1会被用来等到以后使用.
工作窃取
go调度器的另一个方面是工作窃取. 这个在一些领域用来使调度更加高效. 你最不想M出现的情况是进入等待状态, 因为一旦发生这种情况, 操作系统就会进行上下文切换, 将M从核上移出. 这意味着, 即使当前有go程处于可执行状态,, P也不能够做任何工作, 直到M被放入一个核中执行. 工作窃取可以用来平衡P中的go程, 从而使工作更好地分布并且更高效地得到执行.
让我们看一个例子.
图片9
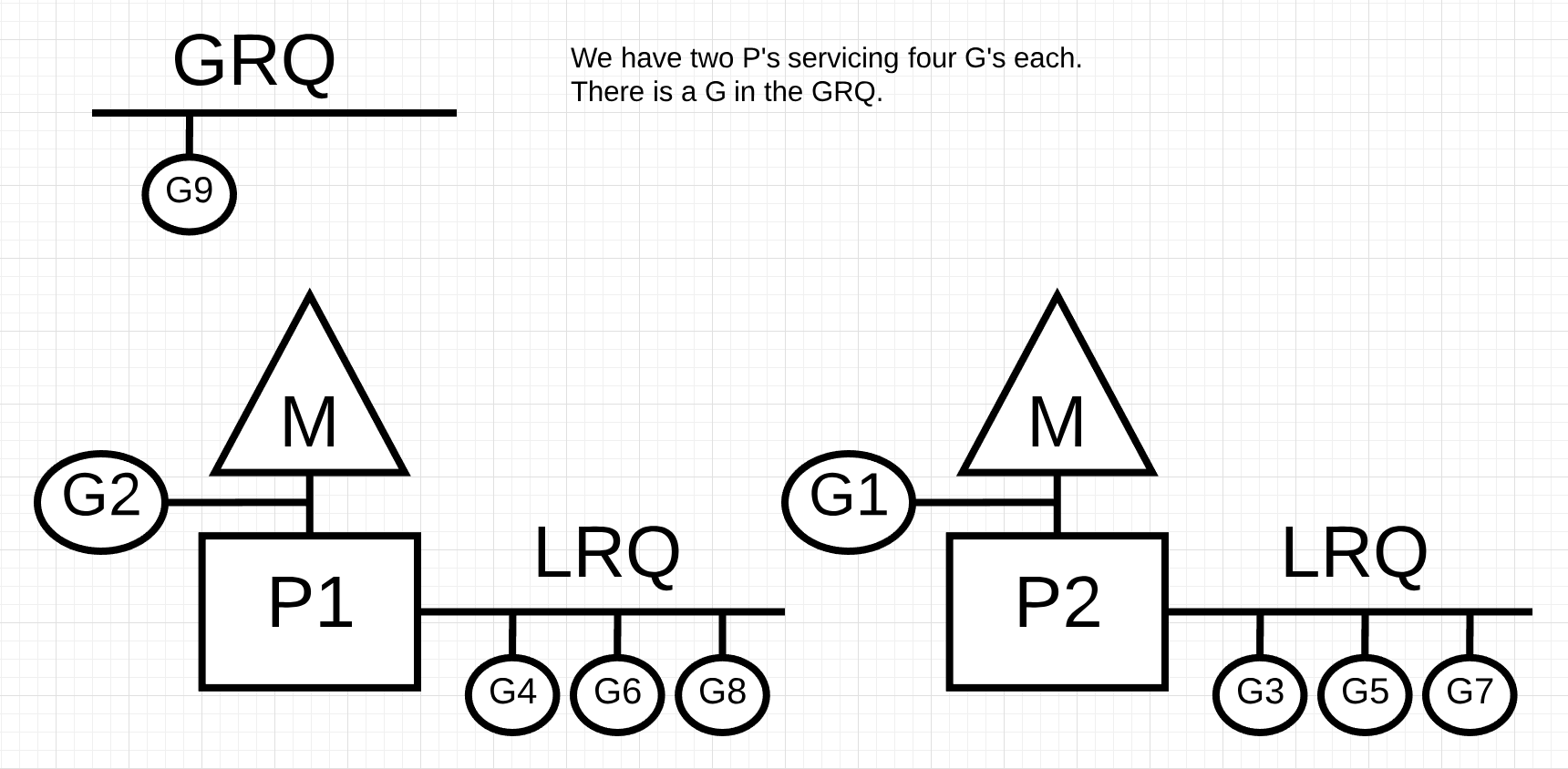
图片9中, 我们有一个多线程的go程序, 这个程序有两个P, 每个P上面有4个go程, 在全局运行队列(GRQ)中有一个go程. 如果其中一个P很快执行完所有的go程, 会发生什么?
图片10

图10中, P1没有go程可以执行. 但是在P2的本地运行队列(LRQ)和全局运行队列(GRQ)有go程处于可执行状态. 这种状态下, P1需要窃取工作. 工作窃取的规则如下:
Listing 2
runtime.schedule() {
// only 1/61 of the time, check the global runnable queue for a G.
// if not found, check the local queue.
// if not found,
// try to steal from other Ps.
// if not, check the global runnable queue.
// if not found, poll network.
}
所以, 根据Listing 2中的这些规则, P1需要在P2的本地运行队列中查看是否有可执行的go程, 然后从其中取走一半.
图片11
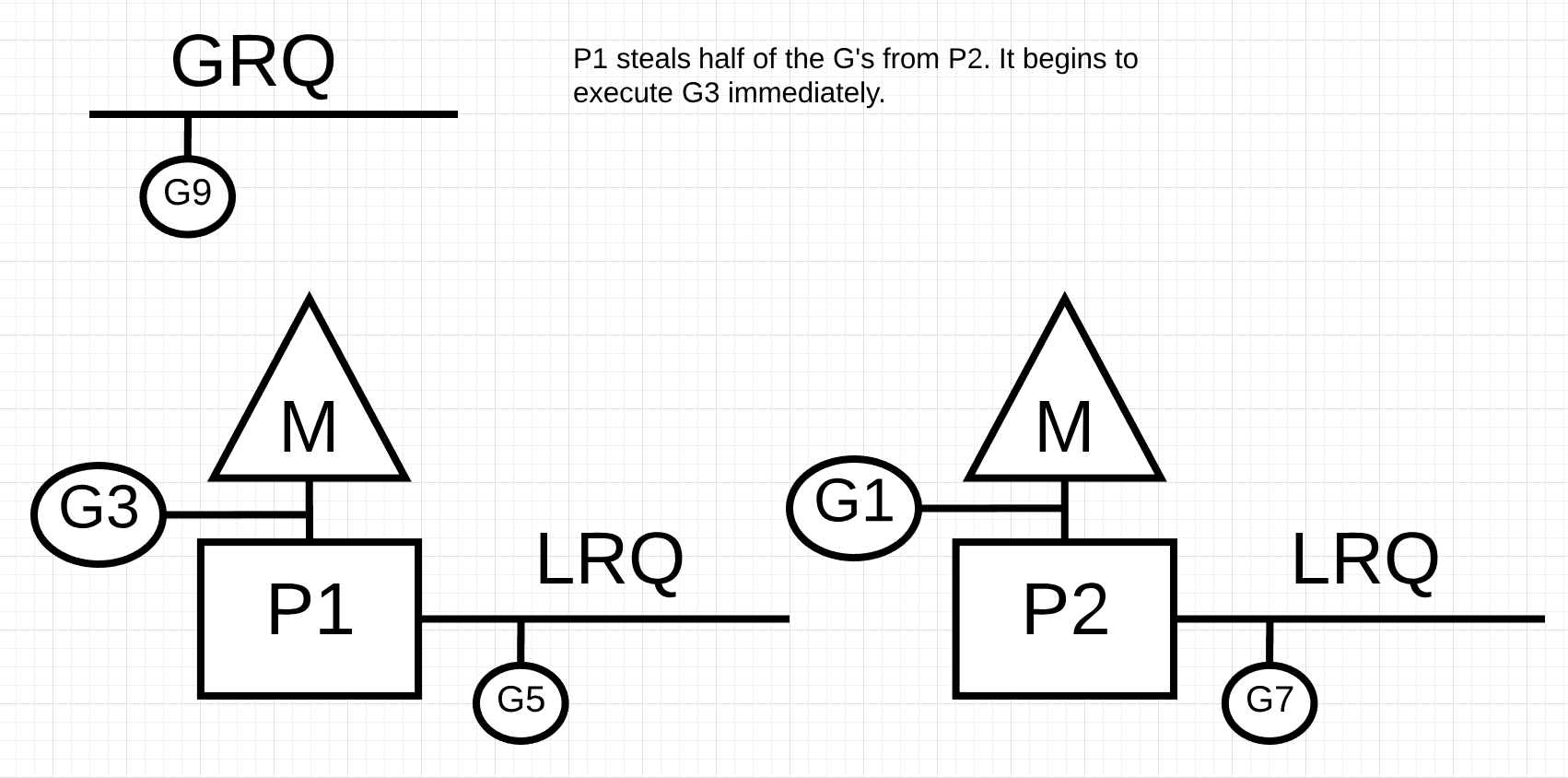
在图11中, P1取走了P2中的一半go程, 然后P1就可以执行这些go程.
如果P2处理了所有的go程, 但是P1的本地运行队列中没有go程, 会发生什么?
图12
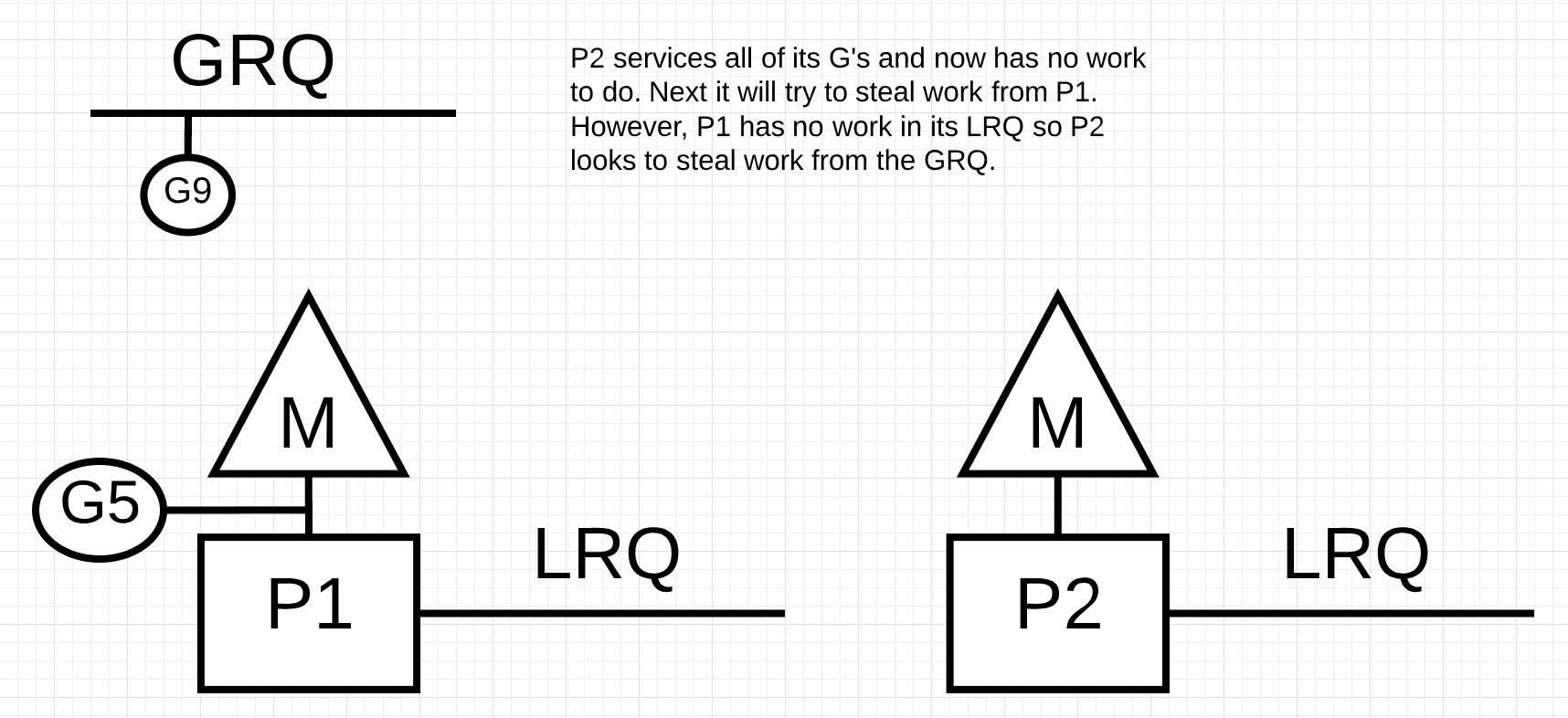
在图12中, P2运行完了它的所有go程, 现在, 它需要从其他地方窃取一些. 首先, 它查看P1的本地运行队列(LRQ), 但是它没有看到任何go程. 然后, 它会查看全局运行队列(GRQ). 这里它发现了go程9.
图片13
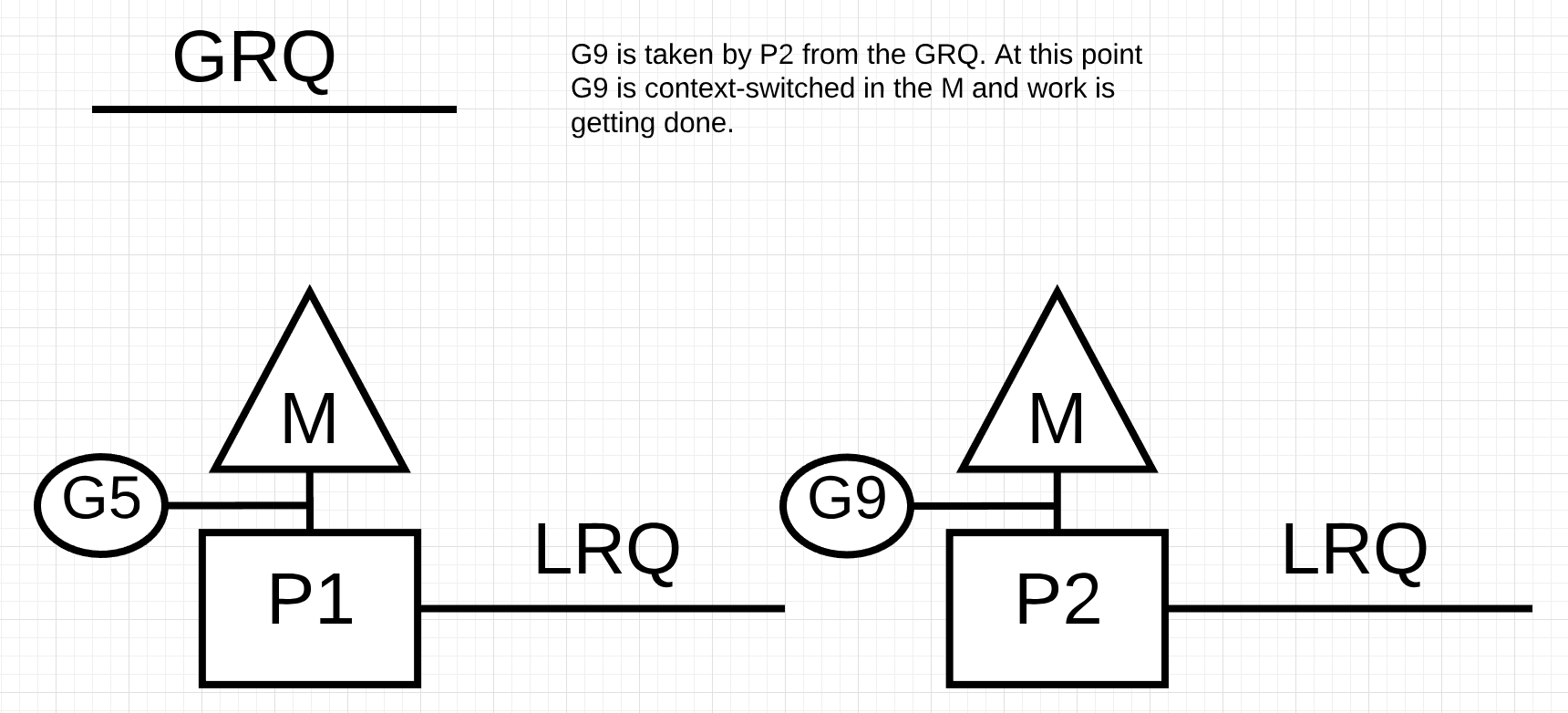
在图片13中, P2从全局运行队列中窃取了go程9, 然后开始执行. 工作窃取的好处是, 它能够让M继续保持运行, 而不进入空闲状态. 工作窃取被认为是一种M的自旋. JBD在她的博客中解释了M自旋的另外一种好处(https://rakyll.org/scheduler/).
实例
讲了go调度器调度的原理和特性, 我想把这些放在一起讲述, 使go调度器在一定时间内做更多的工作. 假设有一个C语言写的多线程应用, 这个应用管理着两个互发消息的操作系统线程.
图片14
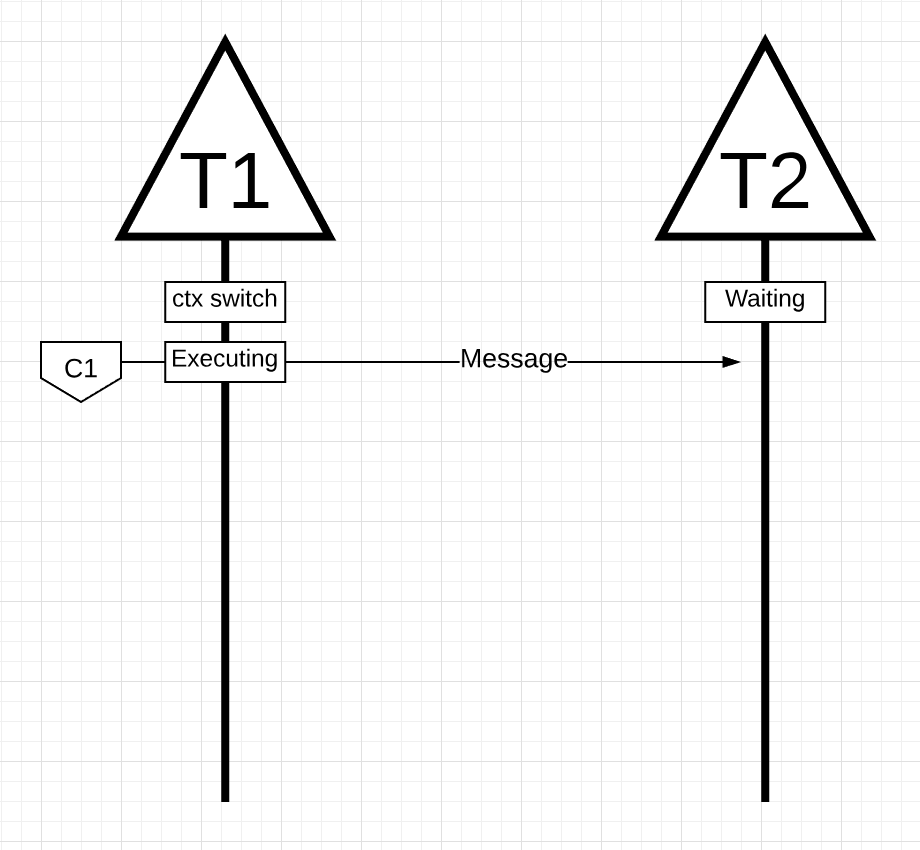
在图片14中, 有两个线程在互发消息. 线程1进行上下文切换运行在核1上, 然后线程1发送消息给线程2.
注意: 消息如何发送在这里不重要. 重要的是在程序运行过程中, 线程状态的变化.
图片15
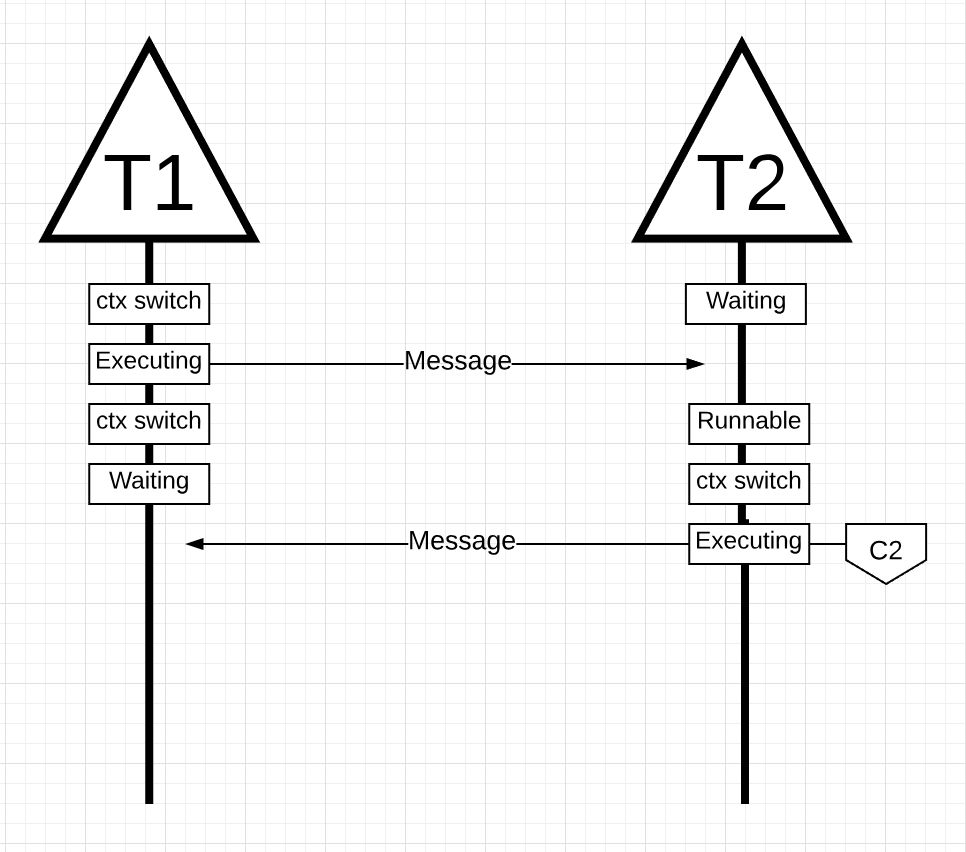
在图片15中, 当线程1发送完它的消息, 这时它需要等待回应. 这会导致线程1上下文切换, 从核1中移出, 进入等待状态. 当线程2接收到消息时, 它进入可运行状态. 这时候, 操作系统进行上下文切换, 让线程2在一个核上运行, 这时候恰巧是核2. 然后, 线程2处理消息, 再向线程1回应一个新的消息.
图片16
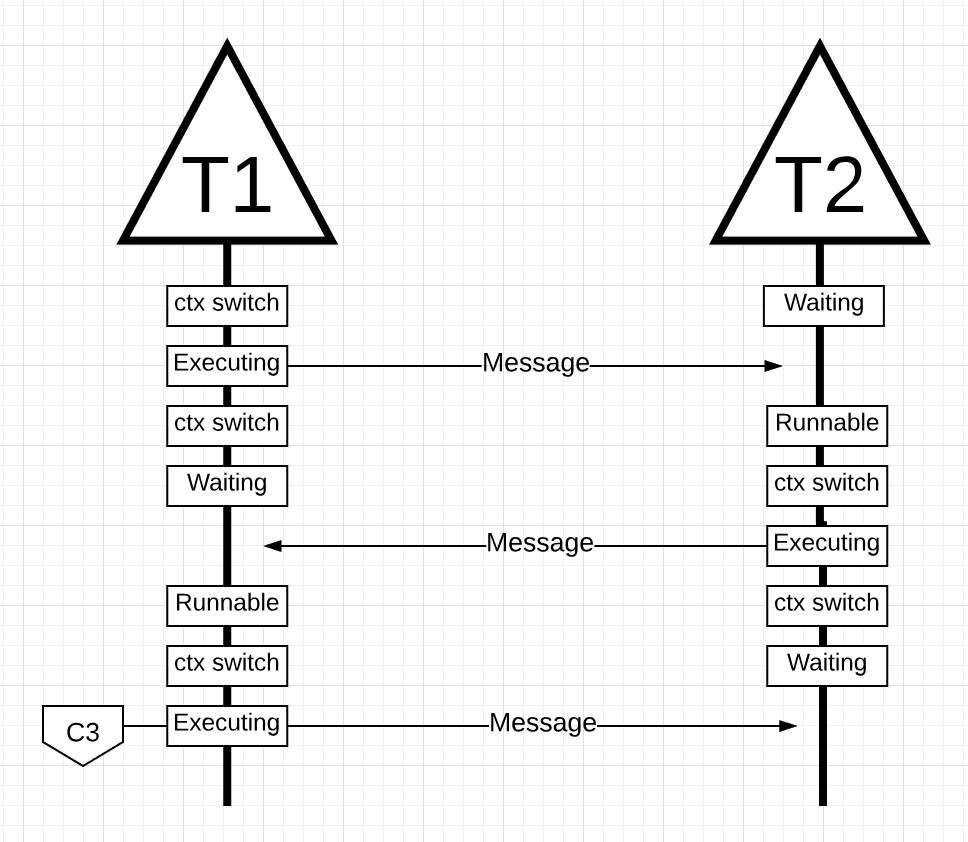
在图片16中, 当线程2的消息被线程1接收, 会再次进行上下文切换. 这时, 线程2由正在执行状态进入等待状态, 线程1从等待状态进入可运行状态, 最终进入正在执行状态, 从而可以处理消息, 并回复一个新的消息.
所有的这些上下文切换和状态改变需要的时间限制了这个工作执行的速度. 每个上下文切换可能需要50纳秒的延迟, 硬件很有可能每纳秒执行12条指令, 那么在这些上下文切换的过程中, 你将少执行大约600条指令. 因为这些线程还会在不同核上跳动, 这些跳动会导致cache-line失效, 从而增加了额外的延迟.
下面我们看这个相同的例子, 这次, 我们改用go调度器和go程.
图片17
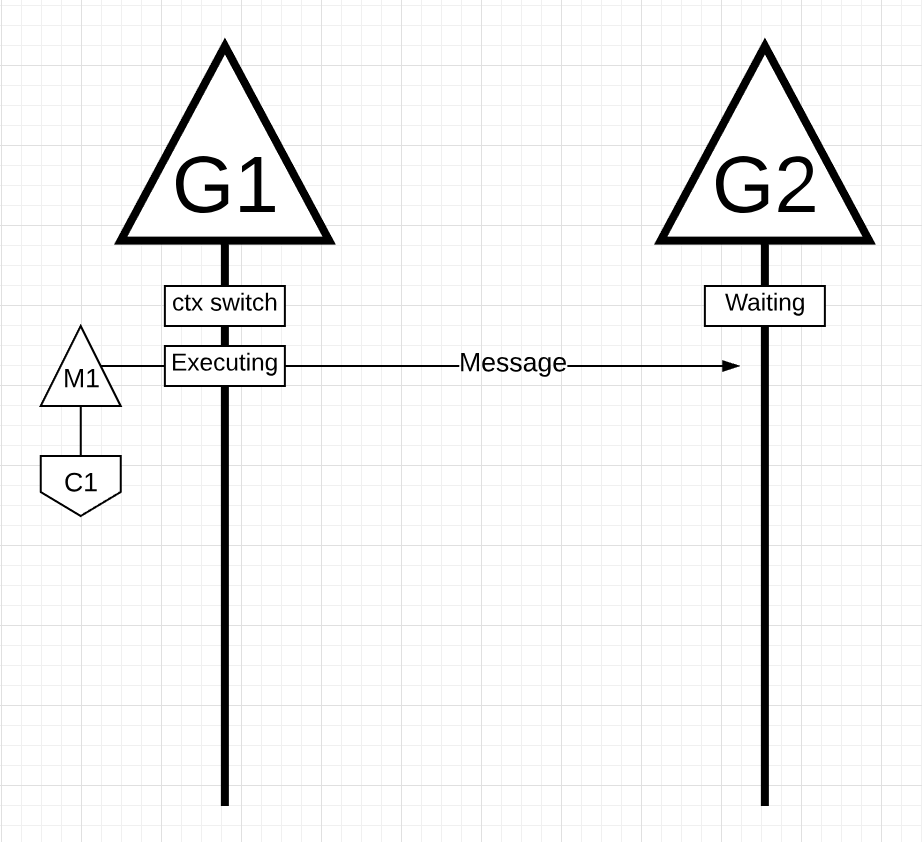
在图片17中, 应用中有两个go程, 这两个go程在相互发送消息. go程1上下文切换到M1上, M1恰巧在核1上执行, 这时go程1可以执行它的工作. go程1向go程2发送了消息.
图片18

在图片18中, 当go程1发送完了它的消息, 它需要等待回应消息. 这个会导致go程1上下文切换出M1, 进入等待状态. 当go程2接收到消息提醒时, 它进入可运行状态. 这时候, go调度器进行上下文切换, 让go程2在M1上运行, 这时M1仍然运行在核1上. 然后, go程2处理消息, 并向go程1回复了一条新消息.
图片19
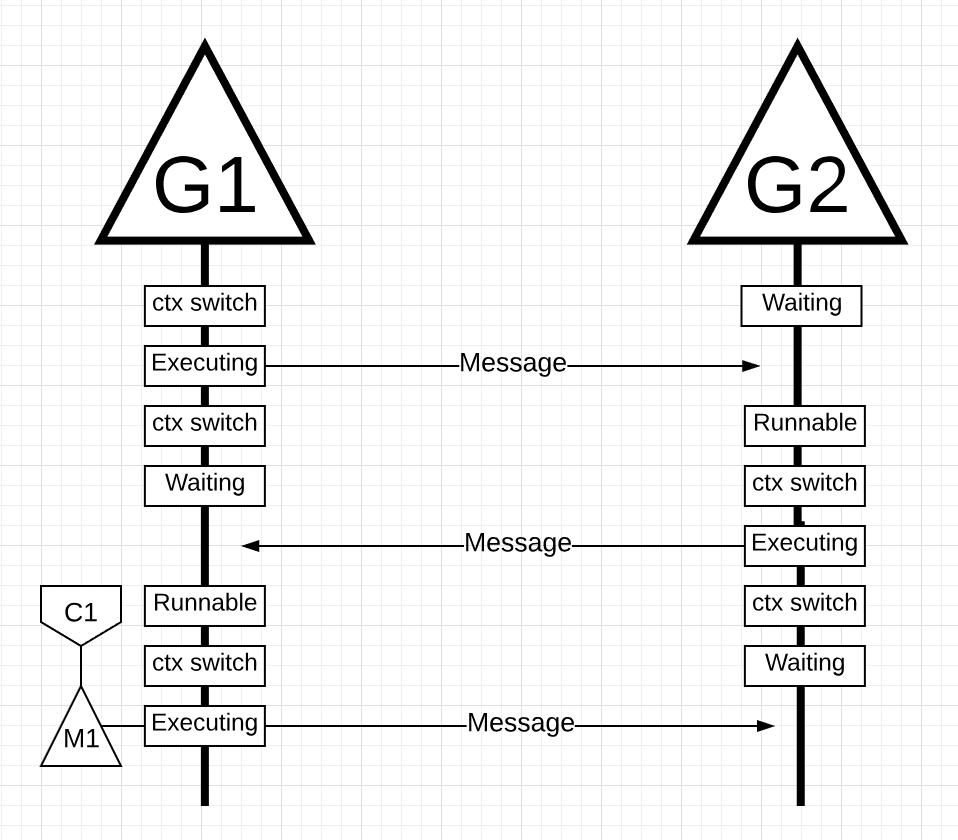
在图片19中, 当go程2发送的消息被go程1收到之后, 会再次进行上下文切换. 这时, go程2从执行状态进入等待状态, go程1从等待状态进行可执行状态, 最终进入执行状态, 继而处理消息, 回复消息.
从表面来看, 这两种方式并没有什么不同. 无论使用线程还是go程, 都会触发相同的上下文切换以及状态变化. 但是, 当使用线程和go程时, 有一个不容易一眼看出的很大的不同.
在使用go程的情况下, 同一个操作系统线程和核进行所有的处理. 这意味着, 从操作系统来看, 操作系统线程没有进入过等待状态, 一次也没有. 所以, 没有操作系统的上下文切换产生的指令执行的减少.
从本质来看, go将 IO/阻塞 工作转变成了操作系统级别的CPU密集型工作. 既然上下文切换发生在应用级别, 我们不用少执行操作系统调度对应的大约600条指令. 调度器也会帮忙提升cache-line的效率和非均匀访存模型. 这个就是为什么我们不需要超过虚拟核数的更多线程的原因. 在go中, go调度器通过使用较少的线程, 然后在每个线程中执行更多的工作来减少操作系统和硬件的负担, 从而可能使总的工作量增加.
总结
go调度器的令人惊讶之处在于它将操作系统和硬件工作的复杂逻辑考虑了进来. 通过将 IO/阻塞 工作变成操作系统级别的CPU密集型工作, 我们在利用CPU处理能力上得到了很多的提升. 这就是为什么你不需要比虚拟核数更多的操作系统线程的原因. 无论是CPU密集型的工作还是IO密集型的工作, 你都可以认为, 每个虚拟核对应一个虚拟线程, 你的所有工作就能够很好地做完. 对于网络app和不需要会阻塞操作系统线程的系统调用的app来说, 这样做都是可行的.
作为一个开发者, 你要理解你的app在做着什么类型的工作. 你不能够奢望创建无限个go程, 但是还可以得到令人满意的性能. 少意味着多, 通过理解go调度器的机制, 你可以做出更好的决策. 在博客的下一部分, 我们在不增加很多代码复杂性的情况下, 探索如何使用并发来获得更好的性能.
原文件参考: https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part2.html
go调度: 第二部分-go调度器的更多相关文章
- go调度: 第一部分-OS调度(操作系统调度)
开场白 这个是三篇博客中的第一篇, 用来提供go调度背后的机制和语法. 这篇博客主要关注操作系统调度. 三篇博客的顺序是: 1) go调度: 第一部分 - 操作系统调度 2) go调度: 第二部分 - ...
- 资源管理与调度系统-YARN的资源调度器
资源管理与调度系统-YARN的资源调度器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 资源调度器是Hadoop YARN中最核心的组件之一,它是ResourceManager中的 ...
- stl第二级空间配置器详解(1)
SGI STL考虑到小型内存区块的碎片问题,设计了双层级配置器,第一级配置直接使用malloc()和free():第二级配置器则视情况采用不同的策略,当配置区大于128bytes时,直接调用第一级配置 ...
- 北航OO第二单元——电梯调度
三次作业要求简介 特点:目的选层电梯 在电梯的每层入口,都有一个输入装置,让每个乘客输入自己的目的楼层.电梯基于这样的一个目的地选择系统进行调度,将乘客运送到指定的目标楼层. 第一次: 在任意时刻输入 ...
- [原创] Legato 8.1 oracle full backup skip 奇怪的问题处理过程 -- 非调度日期手工运行调度也不成功(skip)
转载请注明出处: http://www.cnblogs.com/fengaix6/p/4677024.html 作者:飄ぺ風 环境: a. Server: Legato 8.1.2, aix 6.1 ...
- STL源码分析读书笔记--第二章--空间配置器(allocator)
声明:侯捷先生的STL源码剖析第二章个人感觉讲得蛮乱的,而且跟第三章有关,建议看完第三章再看第二章,网上有人上传了一篇读书笔记,觉得这个读书笔记的内容和编排还不错,我的这篇总结基本就延续了该读书笔记的 ...
- STL源代码分析--第二级空间配置器
本文解说SGI STL空间配置器的第二级配置器. 相比第一级配置器,第二级配置器多了一些机制,避免小额区块造成内存的碎片.不不过碎片的问题,配置时的额外负担也是一个大问题.由于区块越小,额外负担所占的 ...
- 调度工具taskctl跨调度服务依赖实现
调度工具taskctl虽然支持分布式调度,但是有的时候,不同重要程度的调度服务还是要区分开来,在区分开后,不同调度服务之间怎么实现依赖啦, 其实有很多方式,比如写文件,写数据库之类的,这些都可以根据用 ...
- 我心中的核心组件(可插拔的AOP)~第二回 缓存拦截器
回到目录 AOP面向切面的编程,也称面向方面的编程,我更青睐于前面的叫法,将一个大系统切成多个独立的部分,而这个独立的部分又可以方便的插拔在其它领域的系统之中,这种编程的方式我们叫它面向切面,而这些独 ...
随机推荐
- Redis (error) NOAUTH Authentication required.
首先查看redis设置密码没 127.0.0.1:6379> config get requirepass 1) "requirepass" 2) "" ...
- dlib-android
https://travis-ci.org/tzutalin/dlib-android https://github.com/tzutalin/dlib-android-app https://git ...
- Qt开发经验小技巧51-60
在某些http post数据的时候,如果采用的是&字符串连接的数据发送,中文解析乱码的话,需要将中文进行URL转码. QString content = "测试中文"; Q ...
- OpenShift 4.2环境离线部署Operatorhub
缺省离线环境安装的ocp4的Operatorhub是没有内容的.详细离线文档参考官网文档 https://docs.openshift.com/container-platform/4.2/opera ...
- LeetCode_461. Hamming Distance
461. Hamming Distance Easy The Hamming distance between two integers is the number of positions at w ...
- [Python] 项目的配置覆盖与合并
参考来源: https://www.liaoxuefeng.com/wiki/1016959663602400/1018490750237280 代码稍微修改了一下 import os import ...
- ng2 空标签
<ng-container *ngIf="v.products"> <li class="clearfix" *ngFor="let ...
- Gerrit - 初始配置
1 - 插件管理 1.1 下载并安装插件 以reviewers插件为例. 在GerritForge(https://gerrit-ci.gerritforge.com/),找到对应gerrit 版本的 ...
- zabbix自动停用与开启agent
我们在升级环境时遇到了一个问题,那就是zabbix会自动发送邮件给领导,此时领导心里会嘎嘣一下,为了给领导营造一个良好的环境,减少不必要的告警邮件,减少嘎嘣次数,于是在升级之前,取消zabbix监控的 ...
- 【CUDA开发-并行计算】NVIDIA深度学习应用之五大杀器
来自吉浦迅科技 整理发布 http://mp.weixin.qq.com/s?__biz=MjM5NTE3Nzk4MQ==&mid=2651231163&idx=1&sn=d4 ...