hadoop安装教程,分布式配置 CentOS7 Hadoop3.1.2
安装前的准备
1、 准备4台机器、或虚拟机
4台机器的名称和IP对应如下
master:192.168.199.128
slave1:192.168.199.129
slave2:192.168.199.130
slave3:192.168.199.131
2、分别为4台机器安装JDK8
步骤详细请参考: CentOS7卸载 OpenJDK 安装Sun的JDK8
3、为4台机器配置host name
192.168.199.128配置hostname为master
192.168.199.129配置hostname为slave1
192.168.199.130配置hostname为slave2
192.168.199.131配置hostname为slave3
具体操作为:
执行如下命令修改自己所用节点的IP映射:
$ sudo vim /etc/hosts
我们在 /etc/hosts 中将该映射关系填写上去即可,如下图所示(一般该文件中只有一个 127.0.0.1,其对应名为 localhost,如果有多余的应删除,特别是不能有 “127.0.0.1 Master” 这样的记录)
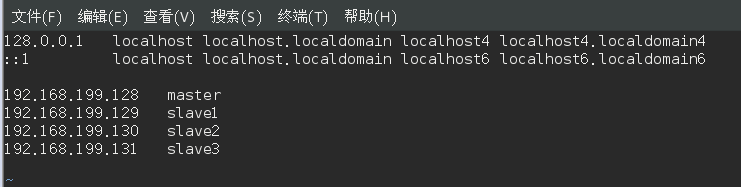
4台机器执行上面同样操作,全部配置相同的hostname
4、为master机器配置 slave1、slave2、slave3的SSH免密登录
这个操作是要让 Master 节点可以无密码 SSH 登陆到各个 Slave 节点上。
首先生成 Master 节点的公匙,在 Master 节点的终端中执行(因为改过主机名,所以还需要删掉原有的再重新生成一次)
$ cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost
$ rm ./id_rsa* # 删除之前生成的公匙(如果有)
$ ssh-keygen -t rsa # 一直按回车就可以
让 Master 节点需能无密码 SSH 本机,在 Master 节点上执行:
cat ./id_rsa.pub >> ./authorized_keys
完成后可执行 ssh Master 验证一下(可能需要输入 yes,成功后执行 exit 返回原来的终端)。接着在 Master 节点将上公匙传输到 Slave1 节点:
$ scp ~/.ssh/id_rsa.pub root@slave1:/home
scp 是 secure copy 的简写,用于在 Linux 下进行远程拷贝文件,类似于 cp 命令,不过 cp 只能在本机中拷贝。执行 scp 时会要求输入 Slave1 上 hadoop 用户的密码(hadoop),输入完成后会提示传输完毕,如下图所示:

接着在 Slave1 节点上,将 ssh 公匙加入授权:
$ mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略
$ cat id_rsa.pub >> ~/.ssh/authorized_keys
$ rm id_rsa.pub # 用完就可以删掉了
如果有其他 Slave 节点,也要执行将 Master 公匙传输到 Slave 节点、在 Slave 节点上加入授权这两步。
这样,在 Master 节点上就可以无密码 SSH 到各个 Slave 节点了,可在 Master 节点上执行如下命令进行检验,如下图所示:
$ ssh slave1
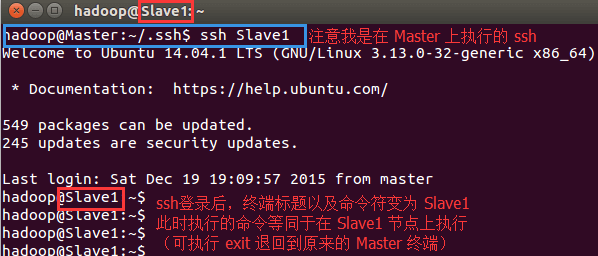
slave2、slave3 执行以上同样操作,将maser的公钥文件导入到自己的authorized_keys文件中,然后测试master的免密登录
Hadoop安装教程分布式配置 CentOS7 Hadoop3.1.2
3 安装hadoop
1、在linux根路径创建目录cloud:sudo mkdir cloud
2、解压hadoop到cloud目录中:tar -zxvf hadoop-2.2.0.tar.gz -C /cloud/
3、进入目录:/cloud/hadoop/etc/hadoop
三、修改配置文件
1、修改hadoop-env.sh,配置java jdk路径,大概在27行配置,如下:
export JAVA_HOME=/home/software/jdk1.7
2、修改core-site.xml,配置内容如下
|
1
2
3
4
5
6
7
8
9
10
11
12
|
<configuration> <!-- 指定HDFS老大(namenode)的通信地址 --><property> <name>fs.defaultFS</name> <value>hdfs://locahost:9000</value></property> <!-- 指定hadoop运行时产生文件的存储路径 --><property> <name>hadoop.tmp.dir</name> <value>/cloud/hadoop/tmp</value></property></configuration> |
3、修改hdfs-site.xml,修改配置如下
|
1
2
3
4
5
|
<!-- 设置hdfs副本数量 --><property> <name>dfs.replication</name> <value>1</value></property> |
4、修改mapred-site.xml 由于在配置文件目录下没有,需要修改名称:mv mapred-site.xml.template mapred-site.xml

<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5、修改yarn-site.xml,修改内容如下
|
1
2
3
4
5
6
7
8
9
10
11
|
<configuration><!-- reducer取数据的方式是mapreduce_shuffle --><property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value></property><property> <name>yarn.resourcemanager.hostname</name> <value>localhost</value></property></configuration> |
6、讲hadoop添加到环境变量,然后更新一下环境变量:source /etc/profile
export JAVA_HOME=//home/software/jdk1.7
export HADOOP_HOME=/cloud/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
- slave1
- slave2
- slave3
四、启动hadoop
1、格式化hadoop,进入目录:/cloud/hadoop/etc/hadoo,执行下列之一命令即可
hdfs namenode -format
2、启动hdfs和yarn
先启动HDFS
sbin/start-dfs.sh 再启动YARN
sbin/start-yarn.sh
3、验证是否成功,使用命令:jps,输出如下即表示配置成功。
|
1
2
3
4
5
6
7
|
12272 Jps4135 JobTracker9500 SecondaryNameNode9943 NodeManager9664 ResourceManager8898 NameNode9174 DataNode |
4、可以在浏览器中查看hdfs和mr的状态.hdfs管理界面:http://localhost:50070 MR的管理界面:http://localhost:8088
五、hdfs基本操作和wordcount程序
1、进入hadoop安装目录中的share:/cloud/hadoop/share/hadoop/mapreduce
2、ls列出当前路径下的文件,内容如下,其中带有example字样的为样例程序
|
1
2
3
4
5
6
7
8
9
10
11
12
|
hadoop-mapreduce-client-app-2.2.0.jarhadoop-mapreduce-client-common-2.2.0.jarhadoop-mapreduce-client-core-2.2.0.jarhadoop-mapreduce-client-hs-2.2.0.jarhadoop-mapreduce-client-hs-plugins-2.2.0.jarhadoop-mapreduce-client-jobclient-2.2.0.jarhadoop-mapreduce-client-jobclient-2.2.0-tests.jarhadoop-mapreduce-client-shuffle-2.2.0.jarhadoop-mapreduce-examples-2.2.0.jarliblib-examplessources |
3、新建words文件,内容输入如下,然后使用命令上传到hdfs目录下:hadoop fs -put words hdfs://localhost:9000/words
|
1
2
3
4
|
hello tomhello kittyhello worldhello tom |
4、在命令行中敲入:hadoop jar hadoop-mapreduce-examples-2.2.0.jar wordcounthdfs://localhost:9000/wordshdfs://localhost:9000/out
5、打开页面:http://192.168.199.128:9870
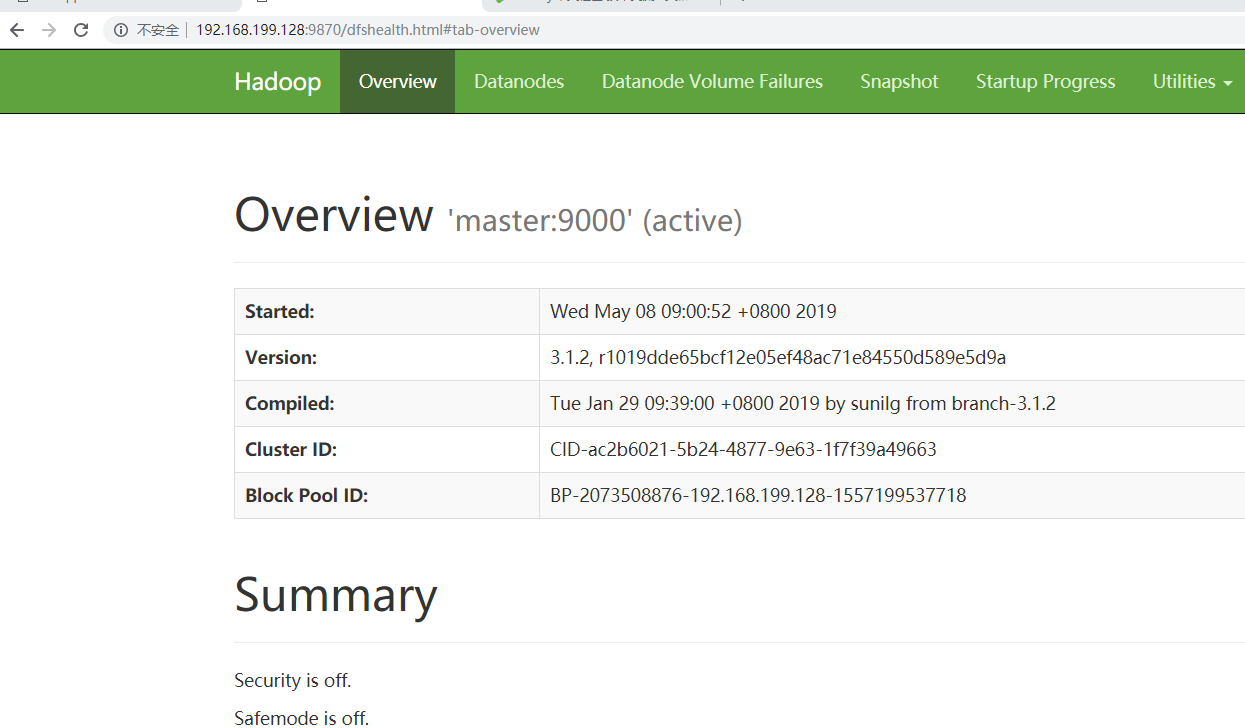
6、点击上图中的Browse the filesystem,跳转到文件系统界面,如下所示:
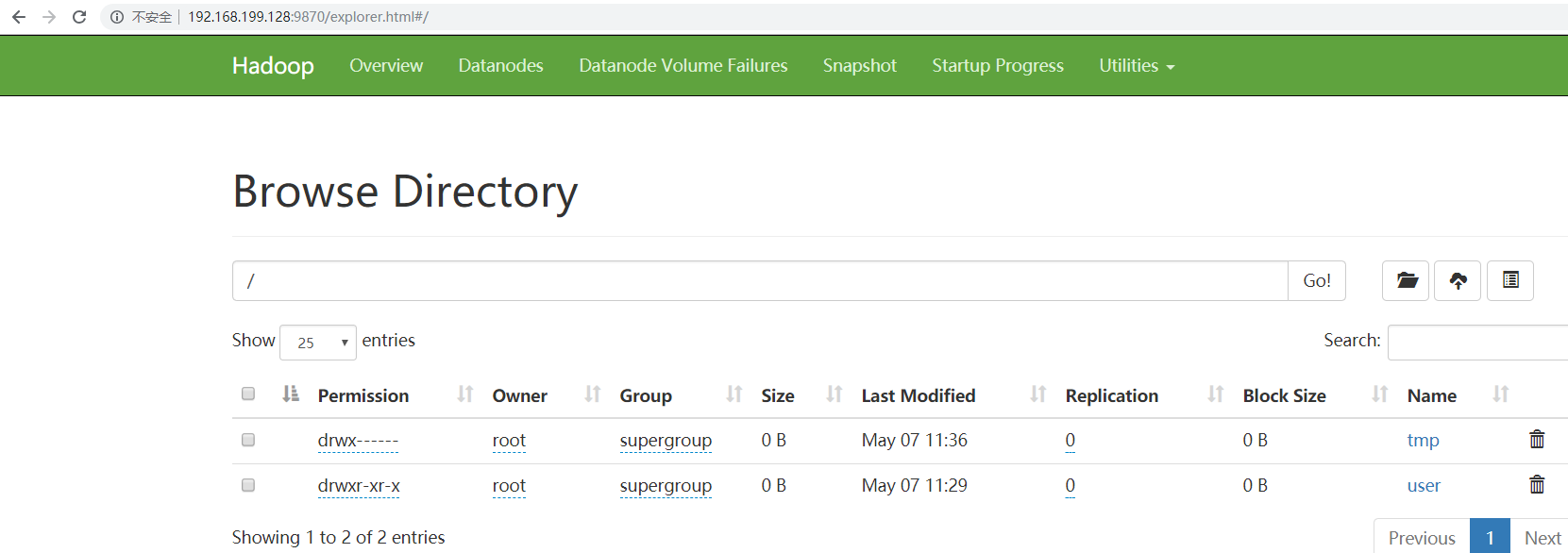
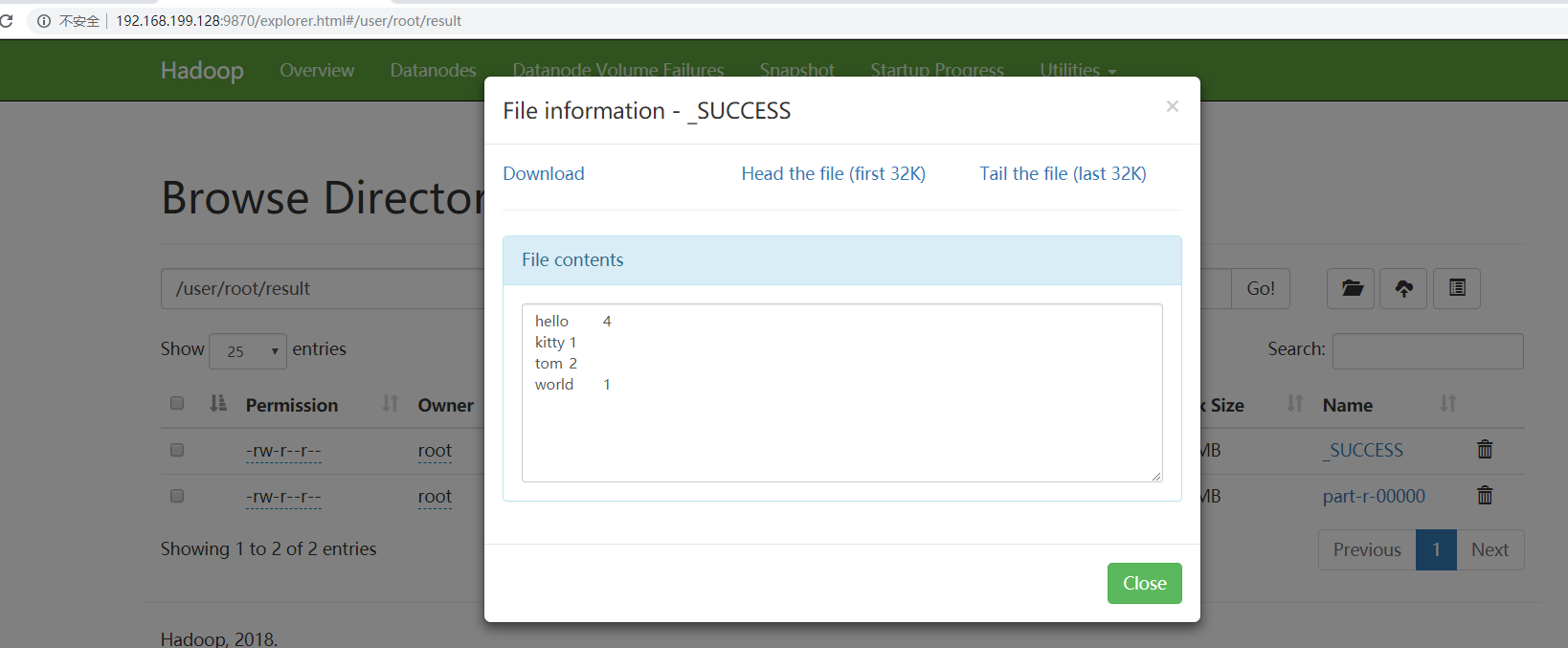
7、继续点击上图的out/part-r-00000,wordcount程序最终运行的结果如图所示:
5可能出现的错误提示
there is no YARN_RESOURCEMANAGER_USER defined
there is no HDFS_NAMENODE_USER defined
解决办法:
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
start-yarn.sh,stop-yarn.sh顶部也需添加以下
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
hadoop安装教程,分布式配置 CentOS7 Hadoop3.1.2的更多相关文章
- Hadoop安装教程_单机/伪分布式配置_CentOS6.4/Hadoop2.6.0
Hadoop安装教程_单机/伪分布式配置_CentOS6.4/Hadoop2.6.0 环境 本教程使用 CentOS 6.4 32位 作为系统环境,请自行安装系统.如果用的是 Ubuntu 系统,请查 ...
- Hadoop安装教程_伪分布式
文章更新于:2020-04-09 注1:hadoop 的安装及单机配置参见:Hadoop安装教程_单机(含Java.ssh安装配置) 注2:hadoop 的完全分布式配置参见:Hadoop安装教程_分 ...
- Hadoop安装教程_分布式
Hadoop的分布式安装 hadoop安装伪分布式以后就可以进行启动和停止操作了. 首先需要格式化HDFS分布式文件系统.hadoop namenode -format 然后就可以启动了.start- ...
- phpmyadmin安装教程及配置设置
phpmyadmin安装教程及配置设置 | 浏览:20304 | 更新:2013-11-07 09:50 1.一般网上下载到的phpmyadmin是一个压缩包,我们将其释放到htdocs目录中,例如h ...
- 转载:Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
原文 http://www.powerxing.com/install-hadoop/ 当开始着手实践 Hadoop 时,安装 Hadoop 往往会成为新手的一道门槛.尽管安装其实很简单,书上有写到, ...
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
摘自: http://www.cnblogs.com/kinglau/p/3796164.html http://www.powerxing.com/install-hadoop/ 当开始着手实践 H ...
- Hadoop安装教程_单机/伪分布式配置
环境 本教程使用 CentOS 6.4 32位 作为系统环境,请自行安装系统(可参考使用VirtualBox安装CentOS).如果用的是 Ubuntu 系统,请查看相应的 Ubuntu安装Hadoo ...
- 新手推荐:Hadoop安装教程_单机/伪分布式配置_Hadoop-2.7.1/Ubuntu14.04
下述教程本人在最新版的-jre openjdk-7-jdk OpenJDK 默认的安装位置为: /usr/lib/jvm/java-7-openjdk-amd64 (32位系统则是 /usr/lib/ ...
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04(转)
http://www.powerxing.com/install-hadoop/ http://blog.csdn.net/beginner_lee/article/details/6429146 h ...
随机推荐
- 数据分析,R语言
数据结构 创建向量和矩阵 1 函数c(), length(), mode(), rbind(), cbind() 求平均值,和,连乘,最值,方差,标准差 1 函数mean(), sum(), min( ...
- 避免因为Arcgis Server服务设置不当导致Oracle Process溢出的方法
我之前写过一篇文章<arcsoc进程无限增长导致oracle processes溢出>(见链接:https://www.cnblogs.com/6yuhang/p/9379086.html ...
- 适合 ASP.NET Core 的超级-DRY开发
作者 Thomas Hansen DRY 是那些非常重要的软件体系结构缩写之一.它的意思是“不要自我重复”,并向维护旧源代码项目的任何用户阐明了一个重要原则.也就是说,如果你在代码中自我重复,会发现每 ...
- JMeter分布式测试环境搭建(禁用SSL)
JMeter分布式环境,一台Master,一到多台Slave,Master和Slave可以是同一台机器. 前提条件: 所有机器,包括master和slave的机器: 1.运行相同版本的JMeter 2 ...
- cmdb知识总结
cmdb面试 1.paramiko模块的作用与原理 2.cmdb是什么 3.为什么要开发CMDB? 4.你们公司有多少台服务器?物理机?虚拟机? 5.你的CMDB是如何实现的? 6.CMDB都用到了哪 ...
- Java学习:运算符的使用与注意事项
运算符的使用与注意事项 四则运算当中的加号“+”有常见的三种用法: 对于数值来,那就是加法. 对于字符char类型来说,在计算之前,char会被提升成为int,然后再计算.char类型字符,和int类 ...
- SQL系列(十三)—— 关于表的DDL
前面的文章一直都在讲述关于DML方面的SQL Statement.这篇文章来说说表方面的DDL: CREATE 创建表 ALTER 修改表 DROP 删除表 CREATE 1.语法 CREATE TA ...
- Quartz.net使用笔记
一.需求场景:每天固定时间执行某个行为/动作. 一开始想用定时器,后来无意间发现了这个插件,感觉功能太强大了,完美解决了我的问题. 二.下载地址:https://www.quartz-schedule ...
- 详细的Hadoop的入门教程-伪分布模式Pseudo-Distributed Operation
一. 伪分布模式Pseudo-Distributed Operation 这里关于VM虚拟机的安装就不再介绍了,详细请看<VMware虚拟机的三种网络管理模式>一章介绍.这章只介绍hado ...
- 2019 满帮java面试笔试题 (含面试题解析)
本人5年开发经验.18年年底开始跑路找工作,在互联网寒冬下成功拿到阿里巴巴.今日头条.满帮等公司offer,岗位是Java后端开发,因为发展原因最终选择去了满帮,入职一年时间了,也成为了面试官,之 ...