Jmeter多业务混合场景如何设置各业务所占并发比例
在进行多业务混合场景测试中,需要分配每个场景占比。
具体有两种方式:
1.多线程组方式;
2.逻辑控制器控制;
第一种:
jmeter一个测试计划可以添加多个线程组,我们把不同的业务放在不同的线程组中,通过控制线程数来控制业务占比。比如实际业务中需要线程组A、线程组B和线程组C的比例为:3:2:1,那么我们可以设置线程组A的线程数为90,线程组B的线程数为60,线程组C的线程数为30,这样就可以粗略的达到要求的比例。但是如果三个事务的响应时间不一样,最终完成的业务数也会有所差异。假设当前线程数的响应时间是完全一致的,才会有3:2:1的业务占比,当然这个是理想状态。
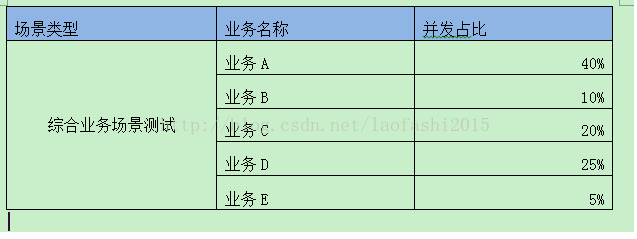
例如测试需求如下:对业务A、业务B、业务C、业务D、业务E,5个业务按并发比例要求进行100个用户并发的压力测试;
JMeter是可以实现上述需求的,测试方案如下:
1.创建一个测试计划;
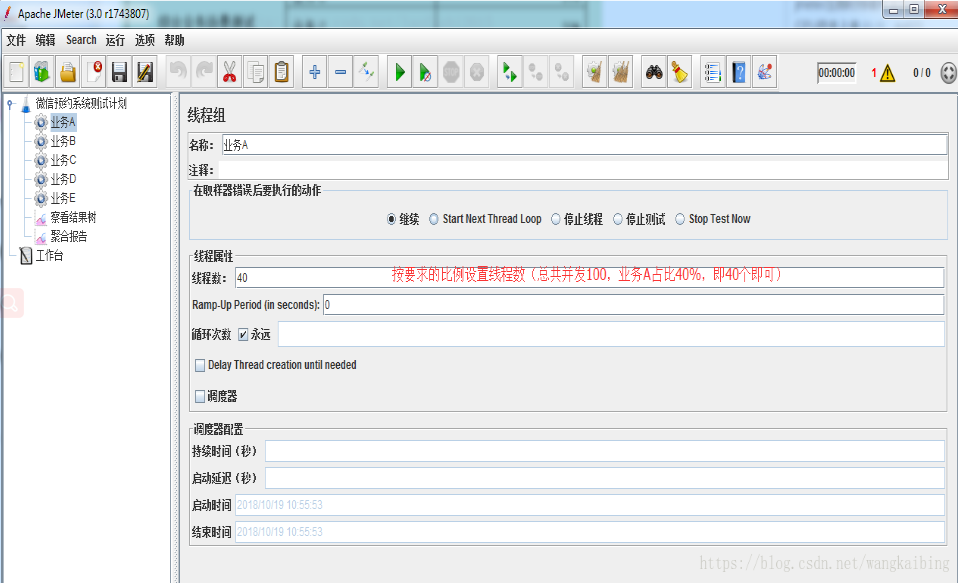
2.在该计划下添加5个线程组,分别是对业务A、业务B、业务C、业务D、业务E;
3.分别设置线程组业务A、业务B、业务C、业务D、业务E的线程数为:40、10、20、25、5(总并发量为100,按并发比例设置并发用户数)
第二种方式:
jmeter的函数对话框中${__counter(True,)}函数获取当前迭代的次数。迭代次数也能获取到,那如何保持3:2的比例呢?这就是一个数学问题了。不卖观子,直接上代码:${__counter(true,)}%2==1||${__counter(true,)}%3==0上面_counter(true,)是获取当前迭代次数,%是取余,也就是是除2余1与3,整除时执行开新帖。以9次迭代为例:回帖9次,1,3,5,6,7,9次迭代时都会开新帖,回帖刚好是6次。9:6=3:2基本上达到了3:2的比例。
方案二:采用jmeter本身自带的计算器,不失为一个好的方法。但是针对一些复杂的场景,这个计算式有点难写,
比如:3:2这个比例,我看到网上的实现都是${__counter(true,)}%2==1||${__counter(true,)}%3==0,
这种计算方式就比较复杂了,那有没有简单一点实现方式呢?
其实是有的。
当参数为true时,每个用户有自己的计数器,比如10个线程组,100个loop,这是计数器的值为1-100.
当选择false,全局计算器,10个线程组,100个loop,计数器值为1-10000
比如下面场景:

那么表达式应该怎么写呢?
上面有3的倍数,5的倍数,那么取其最小公倍数15,按照15分割。
均使用If控制器,表达式分别为:
a: ${__counter(false,)}%15 <=5
b: ${__counter(false,)}%15 >5
c: ${__counter(false,)}%15==1
d: ${__counter(false,)}%15>1&& ${__counter(false,)}%15<=5
总结规律:
按照最小的公倍数分割,每个控制器取他们应占的份数。
上面的3:2的实现手段,就更容易了,一个占2/5,一个占3/5
Jmeter多业务混合场景如何设置各业务所占并发比例的更多相关文章
- jmeter混合场景的多种实现方式比较
性能测试设计混合场景,一般有几种方式,分别是每个场景设置一个线程组,使用if控制器,使用吞吐量控制器.不同的方式实现机制不一样,哪种方式相比而言更好呢?下面做一比较. 下面以混合访问百度首页和必应首页 ...
- Jmeter混合场景压力测试
性能测试设计混合场景,一般有几种方式 分别是:1:每个场景设置一个线程组:2:使用if控制器:3:使用吞吐量控制器. 不同的方式实现机制不一样,个人觉得"使用吞吐量控制器"比较方便 ...
- 使用jmeter做简单的场景设计
使用jmeter做简单的场景设计 Jmeter: Apache JMeter是Apache组织开发的基于Java的压力测试工具.用于对软件做压力测试.我之所以选择它,最重要的一点就是----开源 个人 ...
- 【NS2】有线和无线混合场景 (转载)
1. 创建简单的有线-无线混合场景 上一节建立的无线仿真可以支持多跳adhoc网络或wirelesslan.但是,我们可能需要对经过有线网络连接的多个无线网络进行仿真,或者说我们需要对有线-无线混合网 ...
- mariadb 10 多源复制(Multi-source replication) 业务使用场景分析,及使用方法
mariadb 10 多源复制(Multi-source replication) 业务使用场景分析,及使用方法 官方mysql一个slave只能对应一个master,mariadb 10开始支持多源 ...
- loadrunner 场景设计-设置结果文件保存路径
场景设计-设置结果文件保存路径 by:授客 QQ:1033553122 Results->Results settings Results Name 结果文件夹名称 Directory 指定结果 ...
- LoadRunner中Action的迭代次数的设置和运行场景中设置
LoadRunner中Action的迭代次数的设置和运行场景中设置 LoadRunner是怎么重复迭代和怎么增加并发运行的呢? 另外,在参数化时,对于一次压力测试中均只能用一次的资源应该怎么参数化呢? ...
- iOS Sprite Kit教程之场景的设置
iOS Sprite Kit教程之场景的设置 Sprite Kit中设置场景 在图2.8所示的效果中,可以看到新增的场景是没有任何内容的,本节将讲解对场景的三个设置,即颜色的设置.显示模式的设置以及测 ...
- jmeter ---单个server最大连接数的设置
为了模拟浏览器关于建立多少并行的链接设置,在jmeter中也有相关的设置 在HTTP请求设置页面,勾选“Use concurrent pool" 选型,并将pool size设置为所需的并发 ...
随机推荐
- 「资料分享」理解uboot要看哪些书
最开始是看的韦东山老师的视频,确实很不错,不过总感觉是不够深入扎实,还是想自己看看书,就总结搜罗下,以供参考 学习交流可以添加 微信读者交流①群 (添加微信:coderAllen) 程序员技术交流①群 ...
- ACAG 0x02-8 非递归实现组合型枚举
ACAG 0x02-8 非递归实现组合型枚举 之所以专门来写这道题的博客,是因为感觉从最根本处了解到了递归的机器实现. 主要的就是两个指令--Call和Ret. Call指令会将返回地址入栈(系统栈) ...
- Kotlin函数与Lambda表达式深入
Kotlin函数: 关于Kotlin函数在之前也一直在用,用fun来声明,回忆下: 下面再来整体对Kotlin的函数进行一个学习. 默认参数(default arguments): 先来定义一个函数: ...
- BZOJ1485: [HNOI2009]有趣的数列(卡特兰数+快速幂)
题目链接 传送门 题面 思路 打表可以发现前六项分别为1,2,5,12,42,132,加上\(n=0\)时的1构成了卡特兰数的前几项. 看别人的题解说把每一个数扫一遍,奇数项当成入栈,偶数项当成出栈, ...
- 在命令行中执行kms命令激活Microsoft Office 2010
激活office2010的命令是什么?激活office2010除了使用office2010激活工具之外,还可以使用kms命令来激活office2010,但是office2010激活命令还需考虑32位或 ...
- kafka没配置好,导致服务器重启之后,topic丢失,topic里面的消息也丢失
转,原文:https://blog.csdn.net/zfszhangyuan/article/details/53389916 ----------------------------------- ...
- test20190925 老L
100+0+0=100.概率题套路见的太少了,做题策略不是最优的. 排列 给出 n 个二元组,第 i 个二元组为(ai,bi). 将 n 个二元组按照一定顺序排成一列,可以得到一个排列.显然,这样的排 ...
- 日常SQL总结
THEN '理财帐户' ELSE '其他' end case后可以加入条件在写when,length(String) 为string的字符长度 length(),括号里不仅可以是string的字符串, ...
- 学习Spring-Data-Jpa(十五)---Auditing与@MappedSuperclass
1.Auditing 一般我们针对一张表的操作需要记录下来,是谁修改的,修改时间是什么,Spring-Data为我们提供了支持. 1.1.在实体类中使用Spring-Data为我们提供的四个注解(也可 ...
- arduino adc数模放大器
http://ardui.co/archives/833 http://henrysbench.capnfatz.com/henrys-bench/arduino-voltage-measuremen ...