hive中function函数查询
1. desc function [函数名]
desc function xpath;
查询用法:

2. desc function extended [函数名]
desc function extended xpath;
查询使用举例:
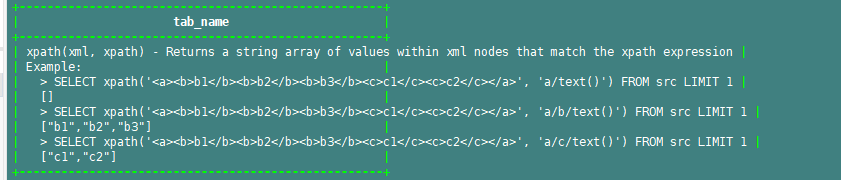
3. 自定义函数添加说明:
使用@Description注解
name: 指定函数名
value: 函数说明
extended:函数的例子
/**
* 解密udf
*/
@Description(
name="decrypt_all",
value=" decrypt_all(decryptType, args ... ) - Returns default value if value is null else returns value",
extended = "Example:\n> "
+ " decrypt_all('AES', '123456','password') --password长度16位 \n "
+ " decrypt_all('AES16', '123456','password') --password长度16位 \n "
+ " decrypt_all('DES', '123456','key') --key长度16位 \n "
+ " decrypt_all('3DES', '123456','key') \n "
+ "\n"
)
public class DecryptAll extends GenericUDF { private static final String[] decryptType = {"AES","AES16","DES","3DES"}; //这个方法只调用一次,并且在evaluate()方法之前调用。该方法接受的参数是一个ObjectInspectors数组。该方法检查接受正确的参数类型和参数个数。
@Override
public ObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException {
if(args.length < 2){
throw new UDFArgumentLengthException(" args length must be greater than or equal to 2");
}
String encryptValue = args[0].toString();
if(!Arrays.asList(decryptType).contains(encryptValue)){
throw new UDFArgumentLengthException("decrypt type error, only support 'AES','AES16','DES','3DES'");
}
return null;
} //这个方法类似UDF的evaluate()方法。它处理真实的参数,并返回最终结果。
@Override
public Object evaluate(DeferredObject[] args) throws HiveException {
int length = args.length;
String encryptValue = args[0].get().toString();
String arg1 = args[1].get().toString();
String arg2 = length > 2 ? args[2].get().toString() : null;
int index = Arrays.binarySearch(decryptType, encryptValue.toUpperCase());
if(index > 0){
switch (index){
case 0: //aes
return SecurityUtil.aesDecrypt(arg1,arg2);
case 1: //aes16
return SecurityUtil.aesDecryptKey16(arg1,arg2);
case 2: //des
return SecurityUtil.desDecrypt(arg1,arg2);
case 3: //3des
return SecurityUtil.threeDesDecrypt(arg1,arg2);
}
}
return null;
} //这个方法用于当实现的GenericUDF出错的时候,打印出提示信息。而提示信息就是你实现该方法最后返回的字符串。
@Override
public String getDisplayString(String[] strings) {
return null;
}
}
4. 添加udf三部曲
编写java程序,并打包jar
添加jar文件:
# 直接放本地, 需要每个节点都布置一套
add jar /opt/local/hive/udf/encryptAll-1.0.jar; # 最好将文件放到hdfs上,只需要一次性部署
add jar hdfs://nameservice1/udf/encryptAll-1.0.jar;
创建函数:
create temporary function encrypt_all as 'com.xxx.udf.EncryptAll';
5. udf中如何使用hdfs上的文件
下面偶然看到别人写的,未测试
hive -e "
add jar ../../jar/bigdata_mxhz.jar ../../jar/BigDataUdf-1.1.jar;
set mapred.cache.files=/data/index/tv_model.csv#tv_model.csv;
" 在udf中可以直接读取该文件 new FileReader("tv_model.csv")
hive中function函数查询的更多相关文章
- Hive中日期函数总结
--Hive中日期函数总结: --1.时间戳函数 --日期转时间戳:从1970-01-01 00:00:00 UTC到指定时间的秒数 select unix_timestamp(); --获得当前时区 ...
- hive中标准偏差函数stddev()详细讲解
1.标准偏差概念 标准偏差(Std Dev,Standard Deviation) -统计学名词.一种度量数据分布的分散程度之标准,用以衡量数据值偏离算术平均值的程度.标准偏差越小,这些值偏离平均值就 ...
- Hive中自定义函数
Hive的自定义的函数的步骤: 1°.自定义UDF extends org.apache.hadoop.hive.ql.exec.UDF 2°.需要实现evaluate函数,evaluate函数支持重 ...
- 2019-2-14SQLserver中function函数和存储过程、触发器、CURSOR
Sqlserver 自定义函数 Function使用介绍 前言: 在SQL server中不仅可以可以使用系统自带的函数(时间函数.聚合函数.字符串函数等等),还可以根据需要自定义函数 ...
- hive中的子查询改join操作(转)
这些子查询在oracle和mysql等数据库中都能执行,但是在hive中却不支持,但是我们可以把这些查询语句改为join操作: -- 1.子查询 select * from A a where a.u ...
- VC中function函数解析
C++标准库是日常应用中非常重要的库,我们会用到C++标准库的很多组件,C++标准库的作用,不单单是一种可以很方便使用的组件,也是我们学习很多实现技巧的重要宝库.我一直对C++很多组件的实现拥有比较强 ...
- JavaScript中Function函数与Object对象的关系
函数对象和其他内部对象的关系 除了函数对象,还有很多内部对象,比如:Object.Array.Date.RegExp.Math.Error.这些名称实际上表示一个 类型,可以通过new操作符返回一个对 ...
- js中function函数
function:是具备某个功能的方法,方法本身没有意义,只有执行方法才有价值. function: 1 创建一个函数: 2 执行这个方法: 例: 创建 function 方法名(){ 存放某个功能的 ...
- Python中function(函数)和methon(方法)的区别
在Python中,对这两个东西有明确的规定: 函数function —— A series of statements which returns some value to a caller. It ...
随机推荐
- tac命令以及各种linux文件查看命令
有许多命令都可以查看文件,不同的命令有不同的优点,可以针对不同的需要分别选择命令以提高效率: cat 由第一行开始显示内容,并将所有内容输出 tac 从最后一行倒序显示内容 ...
- FreeBSD安装后使用su命令显示sorry的解决办法
FreeBSD中,可以使用su命令成为root用户,但FreeBSD对执行su命令的用户进行了更严格的限制,能使用su命令的用户必须属于wheel组(root的基本属组,组ID为0),否则就不能通过 ...
- C语言强、弱符号,强、弱引用
C语言强.弱符号,强.弱引用 符号定义 在编程中我们经常碰到符号重复定义的情况,当我们在同一个作用域内重复定义同一个变量时,有时是因为误写,有时是文件之间的冲突,编译器的处理方式就是报错: redef ...
- Kali下的内网劫持(四)
在前面我都演示的是在Kali下用命令行的形式将在目标主机上操作的用户的信息捕获的过程,那么接下来我将演示在Kali中用图形界面的ettercap对目标主机的用户进行会话劫持: 首先启动图形界面的ett ...
- 关于ssh_config和sshd_config
转载:https://www.cnblogs.com/panda2046/p/5933498.html 在远程管理linux系统基本上都要使用到ssh,原因很简单:telnet.FTP等传输方式是 ...
- root用户ssh可以登录,xftp通过sftp不能登录链接CentOS解决办法
xftp显示无法连接到xx.xx.xx(服务器地址) 解决办法: 把/etc/ssh/sshd_config文件中的Subsystem sftp /usr/libexec/openssh/sftp-s ...
- 讨论---MySQL数据库中null、''、' '区别
今天在写代码的时候,遇到了一个关于MySQL数据库的问题,发现在表中插入‘’数据的时候插入不进去.发现这张表中的数据没有数据的时候,默认显示的null,当时自己又重复的额试了几次,但是始终没有成功,从 ...
- KMP + BZOJ 4974 [Lydsy1708月赛]字符串大师
KMP 重点:失配nxtnxtnxt数组 意义:nxt[i]nxt[i]nxt[i]表示在[0,i−1][0,i-1][0,i−1]内最长相同前后缀的长度 图示: 此时nxt[i]=jnxt[i]=j ...
- C#线程池 ThreadPool
什么是线程池 大家都知道,我们在打开一个应用的时候,操作系统是要做很多的事情的,动态链接.装载.分配虚拟空间.等等等等,其实一个应用的打开同时也伴随着一个进程的建立. 进程的建立是需要时间的,在进程上 ...
- 深入解析pure virtual function call
在本文中,我们将不解释为什么会提示“纯虚拟函数调用”和如何提示“纯虚拟函数调用”,而是详细解释在win32平台的构造函数/析构函数中直接/间接调用纯虚拟函数时程序本身.在开始时,将显示一个经典示例,在 ...