AUC(Area Under roc Curve )计算及其与ROC的关系
转载: http://blog.csdn.net/chjjunking/article/details/5933105
让我们从头说起,首先AUC是一种用来度量分类模型好坏的一个标准。这样的标准其实有很多,例如:大约10年前在machine learning文献中一统天下的标准:分类精度;在信息检索(IR)领域中常用的recall和precision,等等。其实,度量反应了人们对” 好”的分类结果的追求,同一时期的不同的度量反映了人们对什么是”好”这个最根本问题的不同认识,而不同时期流行的度量则反映了人们认识事物的深度的变 化。近年来,随着machine learning的相关技术从实验室走向实际应用,一些实际的问题对度量标准提出了新的需求。特别的,现实中样本在不同类别上的不均衡分布(class distribution imbalance problem)。使得accuracy这样的传统的度量标准不能恰当的反应分类器的performance。举个例子:测试样本中有A类样本90个,B 类样本10个。分类器C1把所有的测试样本都分成了A类,分类器C2把A类的90个样本分对了70个,B类的10个样本分对了5个。则C1的分类精度为 90%,C2的分类精度为75%。但是,显然C2更有用些。另外,在一些分类问题中犯不同的错误代价是不同的(cost sensitive learning)。这样,默认0.5为分类阈值的传统做法也显得不恰当了。
为了解决上述问题,人们从医疗分析领域引入了一种新的分类模型performance评判方法——ROC分析。ROC分析本身就是一个很丰富的内容,有兴趣的读者可以自行Google。由于我自己对ROC分析的内容了解还不深刻,所以这里只做些简单的概念性的介绍。
ROC的全名叫做Receiver Operating Characteristic,其主要分析工具是一个画在二维平面上的曲线——ROC curve。平面的横坐标是false positive rate(FPR),纵坐标是true positive rate(TPR)。对某个分类器而言,我们可以根据其在测试样本上的表现得到一个TPR和FPR点对。这样,此分类器就可以映射成ROC平面上的一个点。调整这个分类器分类时候使用的阈值,我们就可以得到一个经过(0, 0),(1, 1)的曲线,这就是此分类器的ROC曲线。一般情况下,这个曲线都应该处于(0, 0)和(1, 1)连线的上方。因为(0, 0)和(1, 1)连线形成的ROC曲线实际上代表的是一个随机分类器。如果很不幸,你得到一个位于此直线下方的分类器的话,一个直观的补救办法就是把所有的预测结果反向,即:分类器输出结果为正类,则最终分类的结果为负类,反之,则为正类。虽然,用ROC curve来表示分类器的performance很直观好用。可是,人们总是希望能有一个数值来标志分类器的好坏。于是Area Under roc Curve(AUC)就出现了。顾名思义,AUC的值就是处于ROC curve下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的performance。
好了,到此为止,所有的 前续介绍部分结束,下面进入本篇帖子的主题:AUC的计算方法总结。
最直观的,根据AUC这个名称,我们知道,计算出ROC曲线下面的面积,就是AUC的值。事实上,这也是在早期Machine Learning文献中常见的AUC计算方法。由于我们的测试样本是有限的。我们得到的AUC曲线必然是一个阶梯状的。因此,计算的AUC也就是这些阶梯下面的面积之和。这样,我们先把score排序(假设score越大,此样本属于正类的概率越大),然后一边扫描就可以得到我们想要的AUC。但是,这么 做有个缺点,就是当多个测试样本的score相等的时候,我们调整一下阈值,得到的不是曲线一个阶梯往上或者往右的延展,而是斜着向上形成一个梯形。此时,我们就需要计算这个梯形的面积。由此,我们可以看到,用这种方法计算AUC实际上是比较麻烦的。
一个关于AUC的很有趣的性质是,它和Wilcoxon-Mann-Witney Test是等价的。这个等价关系的证明留在下篇帖子中给出。而Wilcoxon-Mann-Witney Test就是测试任意给一个正类样本和一个负类样本,正类样本的score有多大的概率大于负类样本的score。有了这个定义,我们就得到了另外一中计算AUC的办法:得到这个概率。我们知道,在有限样本中我们常用的得到概率的办法就是通过频率来估计之。这种估计随着样本规模的扩大而逐渐逼近真实值。这 和上面的方法中,样本数越多,计算的AUC越准确类似,也和计算积分的时候,小区间划分的越细,计算的越准确是同样的道理。具体来说就是统计一下所有的 M×N(M为正类样本的数目,N为负类样本的数目)个正负样本对中,有多少个组中的正样本的score大于负样本的score。当二元组中正负样本的 score相等的时候,按照0.5计算。然后除以MN。实现这个方法的复杂度为O(n^2)。n为样本数(即n=M+N)
第三种方法实际上和上述第二种方法是一样的,但是复杂度减小了。它也是首先对score从大到小排序,然后令最大score对应的sample 的rank为n,第二大score对应sample的rank为n-1,以此类推。然后把所有的正类样本的rank相加,再减去正类样本的score为最 小的那M个值的情况。得到的就是所有的样本中有多少对正类样本的score大于负类样本的score。然后再除以M×N。即
AUC=((所有的正例位置相加)-M*(M+1))/(M*N)
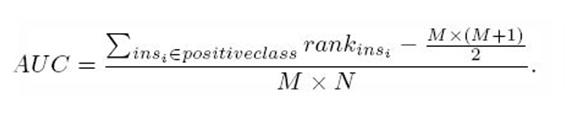
另外,特别需要注意的是,再存在score相等的情况时,对相等score的样本,需要 赋予相同的rank(无论这个相等的score是出现在同类样本还是不同类的样本之间,都需要这样处理)。具体操作就是再把所有这些score相等的样本 的rank取平均。然后再使用上述公式。
AUC(Area Under roc Curve )计算及其与ROC的关系的更多相关文章
- 【转】AUC(Area Under roc Curve )计算及其与ROC的关系
让我们从头说起,首先AUC是一种用来度量分类模型好坏的一个标准.这样的标准其实有很多,例如:大约10年前在machine learning文献中一统天下的标准:分类精度:在信息检索(IR)领域中常用的 ...
- Area Under roc Curve(AUC)
AUC是一种用来度量分类模型好坏的一个标准. ROC分析是从医疗分析领域引入了一种新的分类模型performance评判方法. ROC的全名叫做Receiver Operating Character ...
- AUC(Area Under roc Curve)学习笔记
AUC是一种用来度量分类模型好坏的一个标准. ROC分析是从医疗分析领域引入了一种新的分类模型performance评判方法. ROC的全名叫做Receiver Operating Character ...
- 【AUC】二分类模型的评价指标ROC Curve
AUC是指:从一堆样本中随机抽一个,抽到正样本的概率比抽到负样本的概率大的可能性! AUC是一个模型评价指标,只能用于二分类模型的评价,对于二分类模型,还有很多其他评价指标,比如logloss,acc ...
- 机器学习-TensorFlow应用之classification和ROC curve
概述 前面几节讲的是linear regression的内容,这里咱们再讲一个非常常用的一种模型那就是classification,classification顾名思义就是分类的意思,在实际的情况是非 ...
- ROCR包中ROC曲线计算是取大于cutoff还是大于等于cutoff
找到对应的代码如下 .compute.unnormalized.roc.curve function (predictions, labels) { pos.label <- levels(la ...
- hadoop计算二度人脉关系推荐好友
https://www.jianshu.com/p/8707cd015ba1 问题描述: 以下是qq好友关系,进行好友推荐,比如:老王和二狗是好友 , 二狗和春子以及花朵是好友,那么老王和花朵 或者老 ...
- 机器学习之类别不平衡问题 (2) —— ROC和PR曲线
机器学习之类别不平衡问题 (1) -- 各种评估指标 机器学习之类别不平衡问题 (2) -- ROC和PR曲线 完整代码 ROC曲线和PR(Precision - Recall)曲线皆为类别不平衡问题 ...
- 为什么CTR预估使用AUC来评估模型?
ctr预估简单的解释就是预测用户的点击item的概率.为什么一个回归的问题需要使用分类的方法来评估,这真是一个好问题,尝试从下面几个关键问题去回答. 1.ctr预估是特殊的回归问题 ctr预估的目标函 ...
随机推荐
- WebView的截屏实现
WebView的截屏主要有两种实现方式: 方式1: bitmap = webView.getDrawingCache(); 可是,webView必需要mWebView.setDrawingCacheE ...
- ORACLE遞歸查詢
ORACLE支持常規的用CTE遞歸的方式實現遞歸查詢,也有自己特有的查詢方式,ORACLE文檔中叫層次數據查詢. 這裏通過一個簡單的样例來介紹這兩種查詢方式. 數據準備: CREATE TABLE T ...
- IOCP模型总结(总结回想)
IOCP旧代码重提.近期一直在玩其它方面的东东.时不时回想一下,收益多多. IOCP(I/O Completion Port,I/O完毕port)是性能最好的一种I/O模型.它是应用程序使用线程池处理 ...
- Cocos2dx 小技巧(十二) 一种可行的系列动画播放方式
今早发生了一件事让我感觉特气愤!去年的这个时候,我和小伙伴们一起在操场上拍毕业照,之后有个当地报纸的记者来我们学校取材,看到我们后打算给我们拍几张创意张扬点的毕业照.之后呢,照片出来了,拍的效果大伙都 ...
- 位运算(&、|、^)与逻辑运算(&&、 ||)差别
刚无意在一篇文章中看到了位运算(&.|)和逻辑运算(&&.||)的介绍.想起了自己薄弱的基础知识.于是百度了几把总结了下. 首先从概念上区分下,位运算是将运算符两边的数字换算成 ...
- C语言-常量指针与指针常量
最近倪健问我一个问题,他说:什么是常指针?什么是指向常变量的指针?请举例说明 我查阅资料后这么回答他了, 指针常量(常指针):int * const p : 指针是一个常量,也就是说它始终指向那个地址 ...
- 关于MySQL utf8mb4 字符集中字符串长度的问题
MySQL之前推出的utf8字符集中,一个汉字占3个字节,新的utf8mb4字符集中一个汉字占4个字节. 那么我们平时建表的时候输入的varchar=16这种,到底指的是字符长度还是字节长度? 如果是 ...
- asp.net core系列 39 Razor 介绍与详细示例
原文:asp.net core系列 39 Razor 介绍与详细示例 一. Razor介绍 在使用ASP.NET Core Web开发时, ASP.NET Core MVC 提供了一个新特性Razor ...
- 【习题 8-2 UVA-1610】Party Games
[链接] 我是链接,点我呀:) [题意] 在这里输入题意 [题解] 字符串排序后 显然是n/2-1和n/2这两个字符串进行比较. 设为a,b 找到第一个不相同的位置. 即0..i-1是相同的前缀,然后 ...
- 【CS Round #39 (Div. 2 only) C】Reconstruct Sum
[Link]:https://csacademy.com/contest/round-39/task/reconstruct-sum/ [Description] 给你一个数字S; 让你找有多少对A, ...